常见问题解答
一般信息
模型
- 如何按某个指标对模型进行排序?
- Can I store more information on the model?
- Can I store model configuration files?
- 我正在同时训练多个模型,但我只看到其中一个。发生了什么?
- Can I manually record input and output models?
- 在我将ClearML Server迁移到新地址后,无法从UI访问模型。如何解决这个问题?
- 模型在移动后(不同的存储桶/服务器)无法从用户界面访问。我该如何解决这个问题?
实验
- 我注意到我一直收到消息“警告:未提交的代码”。这是什么意思?
- 我不使用argparse来处理超参数。你有解决方案吗?
- 我注意到我的所有实验都显示为“训练”。还有其他选项吗?
- 有时我看到实验显示为正在运行,但实际上它们并没有运行。这是怎么回事?
- 我的代码抛出了异常,但我的实验状态不是“失败”。发生了什么?
- CERTIFICATE_VERIFY_FAILED - 当我运行实验时,我遇到了SSL连接错误。你有解决方案吗?
- 创建实验名称后如何修改?
- 使用Conda和"typing"包时,我遇到了错误"AttributeError: type object 'Callable' has no attribute '_abc_registry'"。如何修复这个问题?
- 我的ClearML服务器磁盘空间使用率太高。我该怎么办?
- Can I change the random seed used in the experiment?
- 在Web UI中,我无法访问我的实验存储的文件。为什么?
- 我收到消息“ClearML Monitor: 无法检测到迭代报告,回退到以秒为单位的起始时间作为迭代”。这是什么意思?
- Can I control what ClearML automatically logs?
- Can I run ClearML tasks offline?
图表和日志
- 实验控制台选项卡中缺少前几行日志。它们去哪里了?
- 如何创建一个比较超参数与模型准确率的图表?
- 我想添加更多的图表,而不仅仅是使用TensorBoard。这支持吗?
- 如何在同一个图表上显示多个二维散点图系列?
GIT 和存储
- ClearML 能否处理未提交代码的运行问题?
- 我读到有一个集中模型存储的功能。我该如何使用它?
- When using PyCharm for remote debugging, no Git repository was detected. Do you have a solution?
- 在我将ClearML Server迁移到新地址后,UI中无法加载调试图像和/或工件。我该如何解决这个问题?
远程调试(ClearML PyCharm 插件)
Jupyter
scikit-learn
ClearML 配置
ClearML 托管服务
ClearML 服务器部署
- 如何在以下环境中部署ClearML Server:
- 如何重启ClearML服务器?
- Can I create a Helm Chart for ClearML Server Kubernetes deployment?
- 我的Docker无法在SELinux上加载本地主机目录?
ClearML 服务器配置
- 如何为子域名和负载均衡器配置ClearML服务器?
- Can I add web login authentication for the ClearML server?
- Can I modify non-responsive task settings?
ClearML 服务器故障排除
- 重新安装后,为什么我无法在WebApp(UI)中创建凭据?
- 如何修复Docker升级错误?
- 为什么网页登录认证不起作用?
- 如何绕过代理配置以访问我的本地ClearML服务器?
- Trains 无法更新 ClearML 服务器。我收到错误 500(或 400)。如何解决这个问题?
- 为什么我的Trains WebApp(UI)没有显示任何数据?
- 为什么我在虚拟机中运行代码时无法访问我的ClearML服务器?
ClearML 代理
ClearML API
一般信息
我怎么知道有新版本发布?
从ClearML v0.9.3开始,当运行Python实验脚本时,ClearML会发出一个新版本发布通知,该通知会出现在日志中并输出到控制台。
例如,当有新的ClearML Python包版本可用时,通知如下:
CLEARML new package available: UPGRADE to vX.Y.Z is recommended!
当有新版本的ClearML服务器可用时,通知如下:
CLEARML-SERVER new version available: upgrade to vX.Y is recommended!
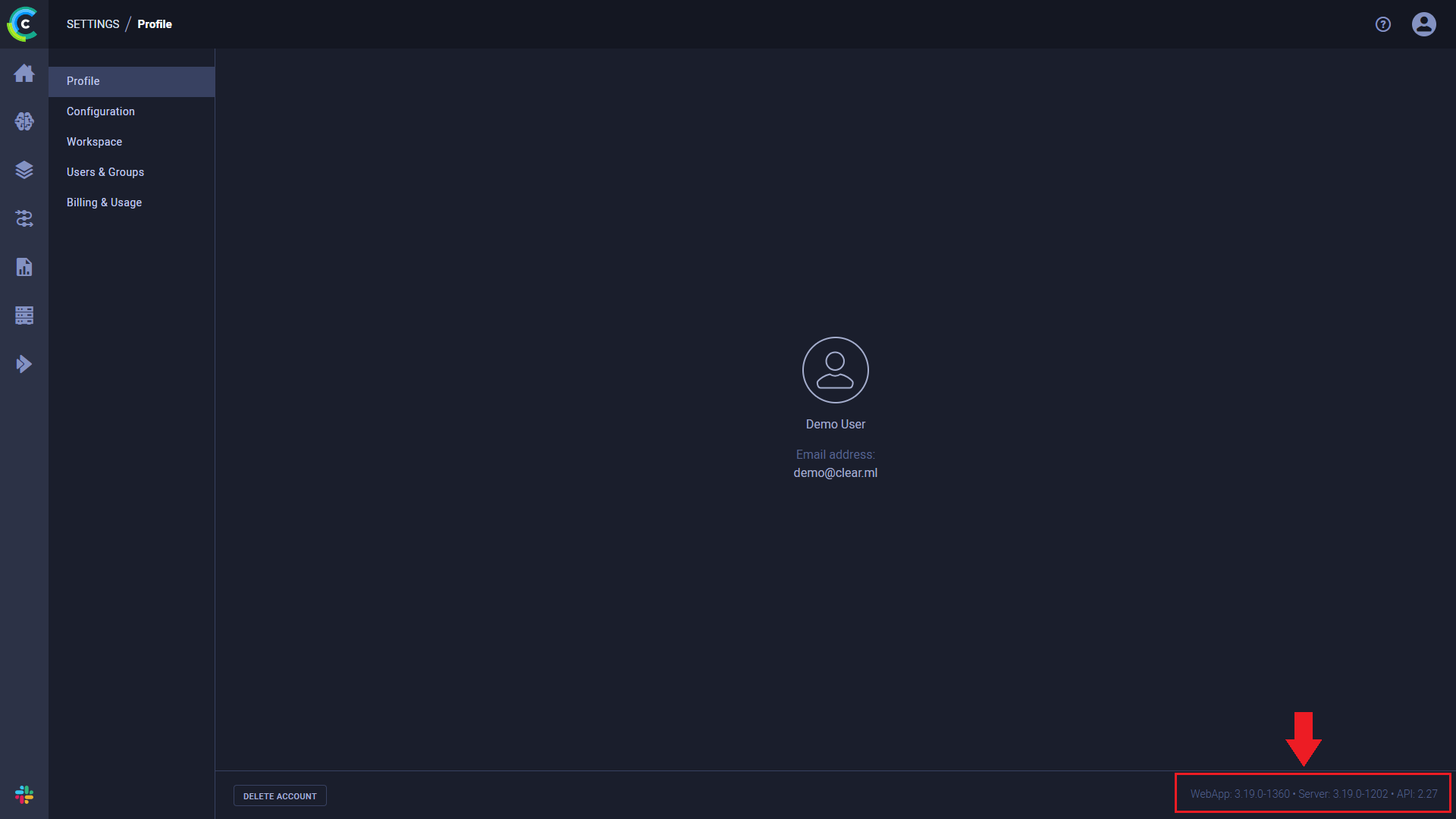
如何查找ClearML版本信息?
ClearML 服务器版本信息可在 ClearML WebApp 的设置页面中找到。在页面的右下角,显示以下数字:
- Web应用程序版本
- API 服务器版本
- API 版本
可以通过使用pip freeze获取ClearML python包的信息。
例如:
pip freeze|grep clearml
应该返回类似这样的内容:
clearml==1.0.3rc1
clearml-agent==1.0.0
clearml-session==0.3.2
模型
如何按某个指标对模型进行排序?
要按指标对模型进行排序,在ClearML Web UI中, 在模型表中添加一个自定义列并按该指标列排序。可用的自定义列选项取决于表中的模型以及附加到它们的指标(参见记录指标和图表)。
ClearML 将模型与创建它们的实验关联起来,因此您还可以在实验表中添加一个自定义列,并按该指标列进行排序。
我可以在模型上存储更多信息吗?
是的!例如,您可以使用 Task.set_model_label_enumeration() 来存储标签枚举:
Task.current_task().set_model_label_enumeration( {"label": int(0), } )
有关Task类方法的更多信息,请参阅Task类参考页面。
我可以存储模型配置文件吗?
是的!使用 Task.connect_configuration():
Task.current_task().connect_configuration("a very long text with the configuration file's content")
我正在同时训练多个模型,但我只看到其中一个。发生了什么?
此问题已在ClearML Server v1.0.0中解决。
查看适用于任何可用格式的服务器升级说明:
我可以手动记录输入和输出模型吗?
是的!使用 InputModel.import_model() 和 Task.connect() 来连接一个输入模型。使用 OutputModel.update_weights() 来连接一个模型权重文件。
input_model = InputModel.import_model(link_to_initial_model_file)
Task.current_task().connect(input_model)
OutputModel(Task.current_task()).update_weights(link_to_new_model_file_here)
有关模型的更多信息,请参阅InputModel 和OutputModel类。
在我将ClearML Server迁移到新地址后,无法从UI访问模型。如何解决这个问题?
如果您的模型已上传到ClearML文件服务器,则可能会发生这种情况,因为注册时记录的值是它们的完整URL(例如https://files.)。
为了解决这个问题,每个模型的注册URL需要替换为其当前的URL。
要替换每个模型的URL,请执行以下命令:
-
在MongoDB Docker容器中打开bash:
sudo docker exec -it clearml-mongo /bin/bash -
在Docker shell 内创建以下脚本(如果不使用
s3,还包括 URL 协议)。 确保替换cat <<EOT >> script.js
db.model.find({uri:{$regex:/^s3/}}).forEach(function(e,i) {
e.uri = e.uri.replace("s3://<old-bucket-name>/","s3://<new-bucket-name>/");
db.model.save(e);});
EOT -
对后端数据库运行脚本:
mongo backend script.js
在我移动模型后(不同的存储桶/服务器),无法从UI访问模型。如何解决这个问题?
如果您的模型已上传到ClearML文件服务器,则可能会发生这种情况,因为注册时记录的值是它们的完整URL(例如https://files.)。
为了解决这个问题,每个模型的注册URL需要替换为其当前的URL:
-
在MongoDB Docker容器中打开bash:
sudo docker exec -it clearml-mongo /bin/bash -
在Docker shell中创建以下脚本(确保替换
cat <<EOT >> script.js
db.model.find({uri:{$regex:/^s3/}}).forEach(function(e,i) {
e.uri = e.uri.replace("s3://<old-bucket-name>/","s3://<new-bucket-name>/");
db.model.save(e);});
EOT -
对后端数据库运行脚本:
mongo backend script.js
实验
我注意到我不断收到消息“警告:未提交的代码”。这是什么意思?
此消息仅为警告。ClearML 不仅检测您当前的代码库和 git 提交,还会在您使用未提交的代码时发出警告。ClearML 这样做是因为未提交的代码意味着此实验将难以复现。您可以在 ClearML Web UI 的实验信息面板的 EXECUTION 选项卡中查看未提交的更改。
我不使用argparse来处理超参数。你有解决方案吗?
是的!ClearML 提供了多种方式来配置您的任务并跟踪您的参数!
除了argparse,ClearML还自动捕获并跟踪使用以下方式创建的命令行参数:
ClearML 还支持使用 Task.connect() 来跟踪代码级别的配置字典。
例如,下面的代码将超参数(learning_rate、batch_size、display_step、model_path、n_hidden_1和n_hidden_2)连接到一个任务:
# Create a dictionary of parameters
parameters_dict = { 'learning_rate': 0.001, 'batch_size': 100, 'display_step': 1,
'model_path': "/tmp/model.ckpt", 'n_hidden_1': 256, 'n_hidden_2': 256 }
# Connect the dictionary to your CLEARML Task
parameters_dict = Task.current_task().connect(parameters_dict)
有关更多任务配置选项,请参阅超参数。
我注意到我的所有实验都显示为“训练”。还有其他选项吗?
是的!ClearML 支持 多种实验类型。在创建实验并调用 Task.init() 时,您可以提供实验类型。例如:
task = Task.init(project_name, task_name, Task.TaskTypes.testing)
有时我看到实验显示为正在运行,但实际上它们并没有运行。这是怎么回事?
ClearML 监控您的 Python 进程。当进程正常退出时,ClearML 会关闭实验。当进程崩溃并异常终止时,有时会错过停止信号。在这种情况下,您可以安全地在 WebApp 中右键单击实验并中止它。
我的代码抛出了异常,但我的实验状态不是“失败”。发生了什么?
此问题已在Trains v0.9.2中解决。通过执行以下命令升级到ClearML:
pip install -U clearml
当我运行我的实验时,我遇到了SSL连接错误CERTIFICATE_VERIFY_FAILED。你有解决方案吗?
您的防火墙可能阻止了连接。请尝试以下解决方案之一:
-
通过设置操作系统环境变量
CURL_CA_BUNDLE或REQUESTS_CA_BUNDLE,直接让Python的"requests"使用企业证书文件。关于此主题的详细讨论,请参见https://stackoverflow.com/questions/48391750/disable-python-requests-ssl-validation-for-an-imported-module。 -
禁用证书验证
warning出于安全原因,不建议禁用证书验证。
-
将ClearML升级到当前版本:
pip install -U clearml -
创建一个新的
clearml.conf配置文件(参见示例配置文件),包含:api { verify_certificate = False } -
将新的
clearml.conf文件复制到:- Linux -
~/clearml.conf - Mac -
$HOME/clearml.conf - Windows -
\User\<username>\clearml.conf``~/clearml.conf
- Linux -
-
创建后如何修改实验名称?
实验的名称是用户控制的属性,可以通过Task.name属性访问。这使您可以使用有意义的命名方案轻松过滤和比较实验。
例如,为了区分不同的实验,您可以将任务ID附加到任务名称中:
task = Task.init(project_name='examples', task_name='train')
task.name += ' {}'.format(task.id)
或者,在执行后附加任务ID:
tasks = Task.get_tasks(project_name='examples', task_name='train')
for t in tasks:
t.name += ' {}'.format(task.id)
另一个例子是将特定的超参数及其值附加到每个任务的名称中:
tasks = Task.get_tasks(project_name='examples', task_name='my_automl_experiment')
for t in tasks:
params = t.get_parameters()
if 'my_secret_parameter' in params:
t.name += ' my_secret_parameter={}'.format(params['my_secret_parameter'])
在使用命名约定创建自动化管道时,请使用此实验命名。
使用 Conda 和 "typing" 包时,我遇到错误 "AttributeError: type object 'Callable' has no attribute '_abc_registry'"。如何解决这个问题?
Conda 和 typing 包可能存在一些兼容性问题。
然而,自 Python 3.5 以来,typing 包已成为标准库的一部分。
要解决此错误,请卸载typing并重新运行您的脚本。如果这不能解决问题,请创建一个新的ClearML问题,包括完整的错误信息和您的环境详细信息。
我的ClearML服务器磁盘空间使用率过高。我该如何处理这个问题?
为了清理空间,您可以删除ClearML对象(例如实验、模型、数据集等)。
通过用户界面删除对象:
- 转到相关对象表(例如 Experiments Table, Models Table, 等)
- 归档对象 - 在表格中右键点击对象 > 点击 归档
- 点击表格顶部的打开存档
- 在存档表中,右键点击对象 > 点击 删除。
要以编程方式删除对象,请使用相关方法:
- 任务 -
Task.delete() - 模型
- 数据集 -
Dataset.delete()
您无法撤销对ClearML对象的删除。
我可以更改实验使用的随机种子吗?
是的!默认情况下,ClearML 使用初始种子 1337 初始化任务,以确保可重复性。要为您的任务设置不同的值,请在初始化任务之前使用 Task.set_random_seed() 类方法并提供新的种子值。
你可以通过传递Task.set_random_seed(None)来完全禁用确定性行为。
在Web UI中,我无法访问我的实验存储的文件。为什么?
ClearML 存储文件位置。运行浏览器的机器必须能够访问运行任务的机器存储文件的位置。这适用于调试样本和工件。例如,如果运行浏览器的机器无法访问,您可能会看到 无法加载图像,而不是图像。
我收到消息“CLEARML Monitor: 无法检测到迭代报告,回退到以秒为单位的迭代时间”。这是什么意思?
如果指标报告在前三分钟内开始,ClearML 会按迭代报告资源监控。否则,它会从开始按秒报告资源监控,并记录一条消息:
CLEARML Monitor: Could not detect iteration reporting, falling back to iterations as seconds-from-start.
然而,如果指标报告在三分钟后开始,并且在最多三十分钟内的任何时间开始,资源监控将恢复到按迭代进行,并且ClearML会记录一条消息
CLEARML Monitor: Reporting detected, reverting back to iteration based reporting.
三十分钟后,它保持不变。
我可以控制ClearML自动记录的内容吗?
是的!ClearML 允许你在初始化任务时通过调用 Task.init() 来控制框架、参数解析器、stdout 和 stderr 的自动日志记录。
框架
要控制任务的框架日志记录,请使用auto_connect_frameworks参数。通过将该参数设置为False来关闭所有自动日志记录。为了更精细地控制记录的框架,可以输入一个包含框架-布尔对的字典。
例如:
auto_connect_frameworks={
'matplotlib': True, 'tensorflow': False, 'tensorboard': False, 'pytorch': True,
'xgboost': False, 'scikit': True, 'fastai': True, 'lightgbm': False,
'hydra': True, 'detect_repository': True, 'tfdefines': True, 'joblib': True,
'megengine': True, 'catboost': True
}
参数解析器
要控制任务从支持的参数解析器中记录参数,请使用auto_connect_arg_parser参数。
通过将参数设置为False来完全禁用所有自动记录。为了更精细地控制记录的参数,输入一个包含参数-布尔对的字典。False值将排除指定的参数。
未指定的参数默认为True。
例如,以下代码将不会记录Example_1参数,但会记录所有其他参数。
auto_connect_arg_parser={"Example_1": False}
要排除所有未指定的参数,请将*键设置为False。
例如,以下代码将仅记录Example_2参数。
auto_connect_arg_parser={"Example_2": True, "*": False}
一个空的字典完全禁用了从参数解析器自动记录所有参数的功能:
auto_connect_arg_parser={}
标准输出和标准错误
要控制stdout、stderr和标准日志记录,请使用auto_connect_streams参数。
要禁用所有三个日志记录,请将参数设置为False。为了更精细的控制,可以输入一个字典,其中键为stout、stderr,
和logging,值为布尔值。例如:
auto_connect_streams={'stdout': True, 'stderr': True, 'logging': False}
参见 Task.init。
我可以在离线状态下运行ClearML任务吗?
是的!您可以使用ClearML的离线模式,在这种模式下,任务从代码中捕获的所有数据和日志都存储在一个本地文件夹中。
您可以通过以下方式之一启用离线模式:
- 在初始化任务之前,使用
Task.set_offline()类方法并将offline_mode参数设置为True - 在运行任务之前,设置
CLEARML_OFFLINE_MODE=1
离线模式仅适用于使用Task.init()创建的任务,而不适用于使用Task.create()创建的任务。
任务的控制台输出显示任务ID和包含会话捕获信息的文件夹路径:
ClearML Task: created new task id=offline-372657bb04444c25a31bc6af86552cc9
...
...
ClearML Task: Offline session stored in /home/user/.clearml/cache/offline/b786845decb14eecadf2be24affc7418.zip
为了将任务离线捕获的执行数据上传到ClearML服务器,请执行以下操作之一:
- 使用clearml-task CLI的
import-offline-session选项 - 使用
Task.import_offline_session()方法。
参见离线存储任务数据。
图表和日志
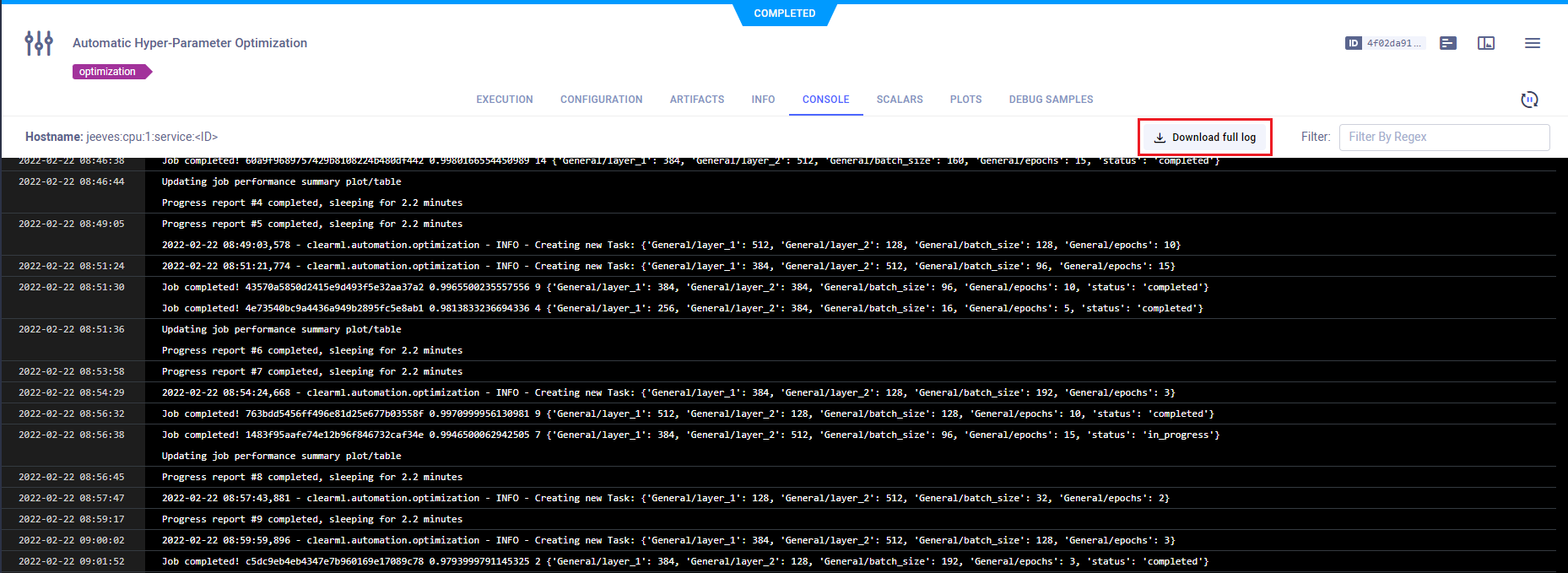
实验控制台标签中缺少了最初的日志行。它们去哪里了?
由于速度/优化问题,控制台仅显示最后几百条日志行。
您始终可以使用ClearML Web UI将完整日志下载为文件。在ClearML Web UI >实验的CONSOLE选项卡中,点击Download full log。
如何创建一个比较超参数与模型准确率的图表?
您可以使用UI的实验比较功能来比较多个实验记录的超参数和准确率值。在实验比较页面中,HYPERPARAMETERS标签下,您可以通过散点图或平行坐标图可视化实验的超参数值与性能指标的关系:
-
散点图: 查看所选超参数与指标之间的相关性。例如,下图显示了一个散点图,展示了一些实验的性能指标(
epoch_accuracy)和超参数(epochs)的值: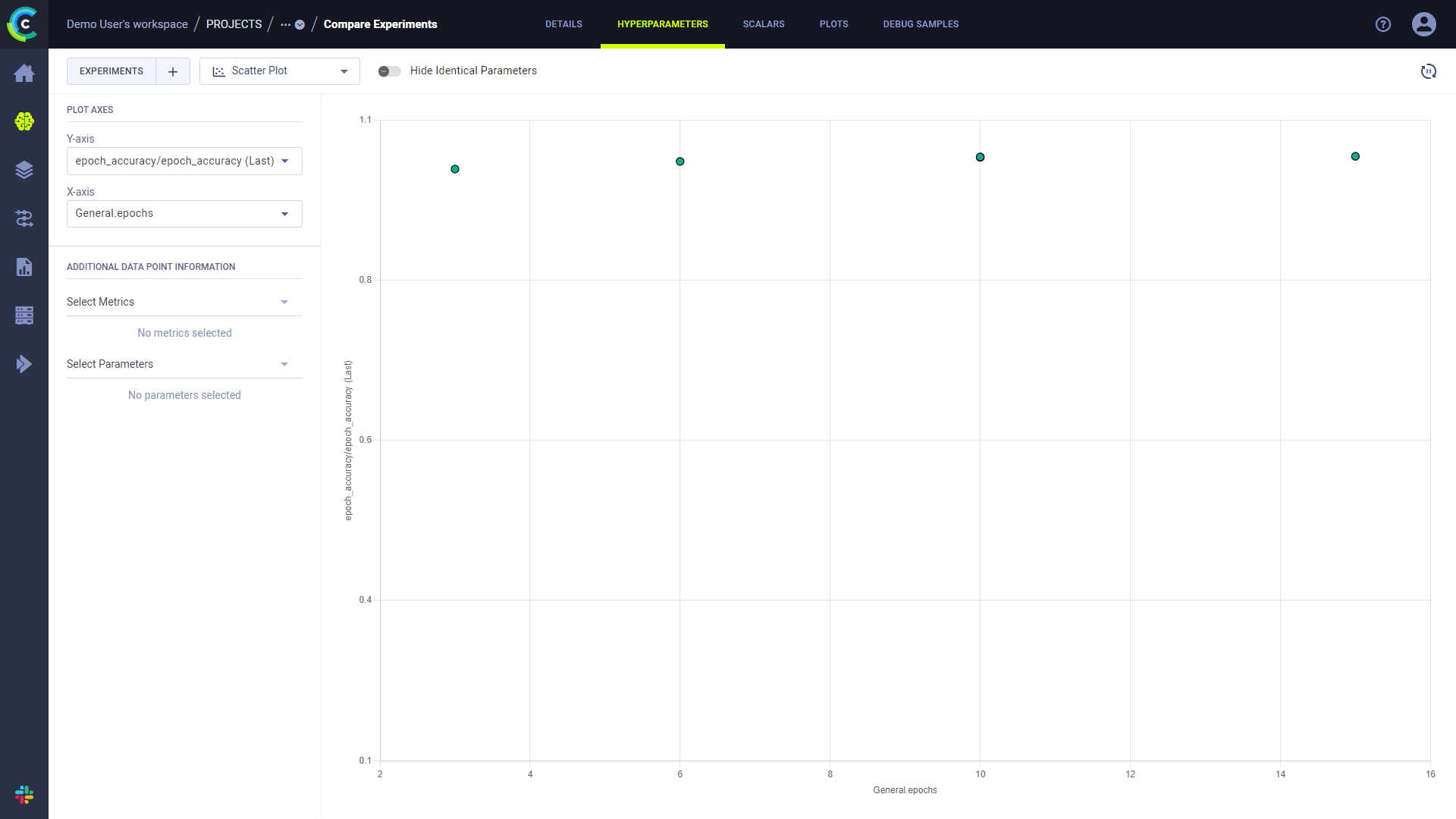
-
平行坐标图: 查看超参数对选定指标的影响。例如,下图显示了一个平行坐标图,该图展示了三个实验中选定的超参数(
base_lr、batch_size和number_of_epochs)以及一个性能指标(accuracy)的值: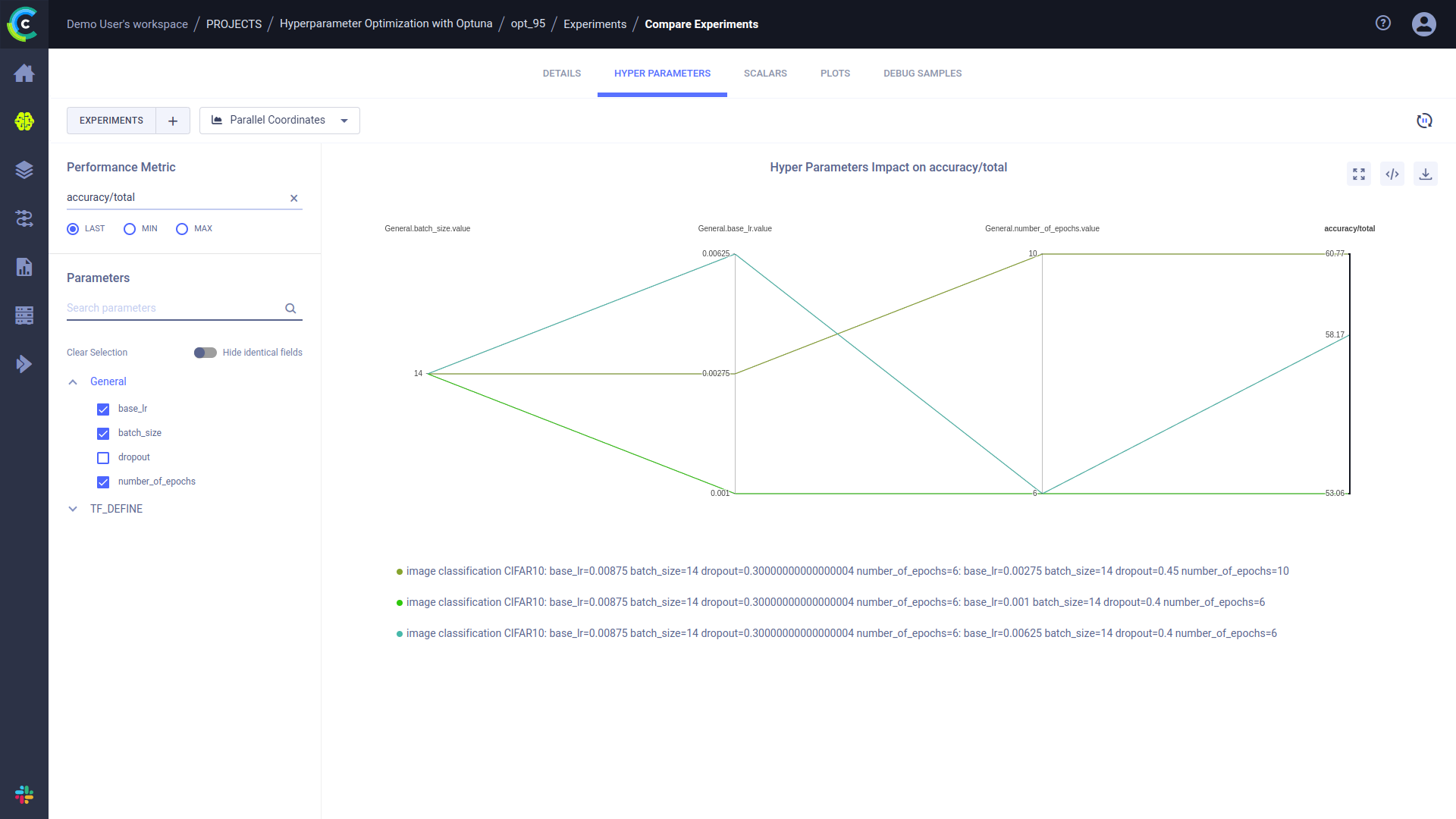
我想添加更多的图表,而不仅仅是使用TensorBoard。这是否支持?
是的!Logger 模块包含了用于显式报告的方法。有关显式报告的示例,请参阅显式报告教程。
如何在同一图表上报告多个二维散点系列?
Logger.report_scatter2d() 方法在同一图表上报告具有相同 title 和 iteration 参数值的所有系列。
例如,以下两个scatter2D系列在同一图表上报告,因为它们都有一个title为example_scatter和一个iteration为1:
scatter2d_1 = np.hstack((np.atleast_2d(np.arange(0, 10)).T, np.random.randint(10, size=(10, 1))))
logger.report_scatter2d(
title="example_scatter",
series="series_1",
iteration=1,
scatter=scatter2d_1,
xaxis="title x",
yaxis="title y"
)
scatter2d_2 = np.hstack((np.atleast_2d(np.arange(0, 10)).T, np.random.randint(10, size=(10, 1))))
logger.report_scatter2d(
title="example_scatter",
series="series_2",
iteration=1,
scatter=scatter2d_2,
xaxis="title x",
yaxis="title y"
)
GIT 和存储
ClearML 能否处理未提交代码的运行问题?
是的!ClearML 将 git diff 存储为实验信息的一部分。您可以在 ClearML Web UI > 实验的 EXECUTION 选项卡中查看 git diff。
我读到有一个集中式模型存储的功能。我该如何使用它?
当调用Task.init时,提供output_uri参数可以让你指定模型检查点(快照)存储的位置。
例如,要将模型检查点(快照)存储在 /mnt/shared/folder 中:
task = Task.init(project_name, task_name, output_uri="/mnt/shared/folder")
ClearML 会将所有存储的快照复制到 /mnt/shared/folder 下的一个子文件夹中。子文件夹的名称将包含实验的ID。如果实验的ID是 6ea4f0b56d994320a713aeaf13a86d9d,将使用以下文件夹:
/mnt/shared/folder/task.6ea4f0b56d994320a713aeaf13a86d9d/models/
ClearML 支持其他存储类型用于 output_uri:
- S3:
s3://bucket/folder - 非AWS S3类似服务(如MinIO):
s3://host_addr:port/bucket - Google Cloud Storage:
gs://bucket-name/folder - Azure 存储:
azure://.blob.core.windows.net/path/to/file
例如:
# AWS S3 bucket
task = Task.init(project_name, task_name, output_uri="s3://bucket-name/folder")
# Google Cloud Storage bucket
task = Task.init(project_name, task_name, output_uri="gs://bucket-name/folder")
要使用ClearML的云存储,请在您的~/clearml.conf中配置存储凭据。有关详细信息,请参阅ClearML配置参考。
使用 PyCharm 远程调试机器时,未检测到 Git 仓库。你有解决方案吗?
是的!ClearML 提供了一个 PyCharm 插件,允许远程调试器获取您的本地仓库 / 提交 ID。有关使用该插件的详细信息,请参阅 ClearML PyCharm 插件。
调试图像和/或工件在将ClearML Server迁移到新地址后未在UI中加载。如何解决这个问题?
如果您的调试图像和/或工件已上传到ClearML文件服务器,则可能会发生这种情况,因为注册时的值是它们的完整URL(例如https://files.)。
要解决这个问题,每个调试图像和/或工件的注册URL需要替换为其当前的URL。
-
对于调试图像,请使用以下命令。确保插入旧地址和将替换它的新地址:
important请注意,在以下命令中,
'\''序列以双单引号('')结尾,而不是双引号(")curl -XPOST -H "Content-Type: application/json" "localhost:9200/events-training_debug_image-*/_update_by_query?conflicts=proceed" -d'{
"script": {
"source": "ctx._source.url = ctx._source.url.replace('\''https://files.<OLD_ADDRESS>'\'', '\''https://files.<NEW_ADDRESS>'\'')",
"lang": "painless"
},
"query": {"prefix": {"url": {"value": "https://files.<OLD_ADDRESS>"}}}
}' -
对于工件,您可以执行以下操作:
-
在
apiserver容器中运行shell:sudo docker exec -it clearml-apiserver /bin/bash -
导航到
apiserver文件夹:cd /opt/clearml/apiserver -
运行
fix_mongo_urls.py脚本来修复工件。确保插入旧地址和将替换它的新地址:python3 fix_mongo_urls.py --host-source http://old_address_and_port --host-target http://new_address_and_port
-
Jupyter
我正在使用Jupyter Notebook。这支持吗?
是的!您可以使用以下任一方式在Jupyter Notebooks中运行ClearML:
-
连接到您的Jupyter主机。
-
安装ClearML Python包:
pip install clearml -
运行ClearML设置向导:
clearml-init -
在您的 Jupyter Notebook 中,您现在可以使用 ClearML。
选项2:在您的Jupyter Notebook中安装ClearML
-
安装ClearML Python包:
pip install clearml -
获取ClearML凭据。在浏览器中打开ClearML Web UI。在设置 > 工作区页面上,点击创建新凭据。 JUPYTER NOTEBOOK标签页显示了配置笔记本所需的命令(悬停时可使用复制到剪贴板操作)
-
将这些命令添加到您的笔记本中
-
您现在可以在笔记本中使用ClearML了!
# create a task and start training
task = Task.init(project_name='jupyter project', task_name='my notebook')
远程调试 (ClearML PyCharm 插件)
我正在使用您的ClearML PyCharm插件进行远程调试。我收到消息“clearml.Task - INFO - 仓库和包分析超时(10.0秒),放弃”。我该怎么办?
ClearML 使用后台线程来分析脚本。这包括包需求。在脚本执行结束时,如果后台线程仍在运行,ClearML 允许线程再运行 10 秒以完成。如果线程未完成,则会超时。
这可能发生在不导入任何包的脚本中,例如简短的测试脚本。
要解决这个问题,你可以导入time包,并在脚本末尾添加一个time.sleep(20)语句。
scikit-learn
我可以在 scikit-learn 中使用 ClearML 吗?
是的!scikit-learn 是受支持的。ClearML 会自动记录使用 joblib 存储的模型。
更多信息,请参见 scikit-learn。
ClearML 配置
如何明确指定要使用的ClearML配置文件?
要覆盖默认的配置文件位置,请设置CLEARML_CONFIG_FILE操作系统环境变量。
例如:
export CLEARML_CONFIG_FILE="/home/user/myclearml.conf"
如何从操作系统环境中覆盖ClearML凭据?
要覆盖您的配置文件/默认值,请设置以下操作系统环境变量:
export CLEARML_API_ACCESS_KEY="key_here"
export CLEARML_API_SECRET_KEY="secret_here"
export CLEARML_API_HOST="http://localhost:8008"
如何通过实验跟踪操作系统环境变量?
您可以通过在clearml.conf文件的sdk.development.log_os_environments字段中指定环境变量来跟踪实验中的环境变量。
log_os_environments: ["AWS_*", "CUDA_VERSION"]
你也可以使用 CLEARML_LOG_ENVIRONMENT 变量来跟踪环境变量:
-
所有环境变量:
export CLEARML_LOG_ENVIRONMENT=* -
特定的环境变量,例如,日志
PWD和PYTHONPATH:export CLEARML_LOG_ENVIRONMENT=PWD,PYTHONPATH -
没有环境变量:
export CLEARML_LOG_ENVIRONMENT=
CLEARML_LOG_ENVIRONMENT 变量总是会覆盖 clearml.conf 文件。
ClearML 托管服务
我运行了我的脚本,但我的实验没有出现在ClearML托管服务Web UI中。我该如何解决这个问题?
如果您加入了ClearML托管服务并运行了一个脚本,但您的实验没有出现在Web UI中,您可能没有为托管服务配置ClearML。运行ClearML设置向导。它将请求您的托管服务ClearML凭据,并创建您需要的ClearML配置。
pip install clearml
clearml-init
ClearML 服务器部署
如何在独立的Linux Ubuntu或macOS系统上部署ClearML Server?
有关详细说明,请参阅部署ClearML服务器:Linux或macOS。
如何在Windows 10上部署ClearML服务器?
有关详细说明,请参阅部署ClearML服务器:Windows 10。
如何在AWS EC2 AMIs上部署ClearML Server?
有关详细说明,请参阅部署ClearML服务器:AWS EC2 AMIs。
如何在Google Cloud Platform上部署ClearML Server?
有关详细说明,请参阅部署ClearML服务器:Google云平台。
如何重启ClearML服务器?
有关详细说明,请参阅您部署格式的文档页面中的“重启”部分。例如,如果您部署到Linux,请参阅“部署ClearML服务器:Linux或macOS”页面上的重启。
我可以为ClearML Server Kubernetes部署创建一个Helm Chart吗?
是的!您可以创建一个ClearML Server Kubernetes部署的Helm Chart。有关详细说明,请参阅部署ClearML Server:使用Helm的Kubernetes。
我的Docker无法在SELinux上加载本地主机目录?
如果您正在使用SELinux,请运行以下命令(参见此讨论):
chcon -Rt svirt_sandbox_file_t /opt/clearml
ClearML 服务器配置
如何为子域名和负载均衡器配置ClearML服务器?
有关详细说明,请参阅配置子域名和负载均衡器。
我可以为ClearML Server添加网页登录认证吗?
默认情况下,任何人都可以登录到ClearML Server WebApp。您可以配置ClearML Server,只允许特定的一组用户访问系统。
有关详细说明,请参阅Web Login Authentication。
我可以修改非响应式任务设置吗?
非响应实验看门狗监控那些在指定时间间隔内未更新的实验,并将它们标记为aborted。看门狗始终处于活动状态。
您可以修改以下看门狗的设置:
- 任务不活动的时间阈值(以秒为单位)(默认值为7200秒,即2小时)。
- The time interval between watchdog cycles in seconds.
有关详细说明,请参阅修改无响应任务监视器设置。
ClearML 服务器故障排除
重新安装后,为什么我无法在WebApp(UI)中创建凭据?
问题可能是您的ClearML服务器浏览器cookie。建议清除您的ClearML服务器浏览器cookie。 例如:
- 对于Firefox - 转到开发者工具 > 存储 > Cookies > 删除ClearML服务器URL下的所有cookies。
- 对于Chrome - 开发者工具 > 应用程序 > Cookies > 删除ClearML服务器URL下的所有cookies。
如何修复Docker升级错误?
解决Docker错误:
... The container name "/trains-???" is already in use by ...
尝试移除已弃用的镜像:
$ docker rm -f $(docker ps -a -q)
为什么网页登录认证不起作用?
ClearML 服务器的 MongoDB 和/或 Elastic 实例与系统上运行的其他实例之间的端口冲突可能会阻止网页登录认证正常工作。
ClearML 服务器使用以下默认端口,这些端口可能与其他实例冲突:
- MongoDB 端口
27017 - 弹性端口
9200
您可以在/opt/clearml/log中的日志中检查端口冲突。
如果发生端口冲突,请在docker-compose.yml中更改MongoDB和/或Elastic的端口,然后运行Docker compose命令以重新启动ClearML Server实例。
要更改您的ClearML服务器的MongoDB和/或Elastic端口,请执行以下操作:
-
编辑
docker-compose.yml文件。 -
在
services/trainsserver/environment部分添加以下环境变量:-
对于MongoDB:
MONGODB_SERVICE_PORT: -
对于Elastic:
ELASTIC_SERVICE_PORT: <new-elasticsearch-port>例如:
MONGODB_SERVICE_PORT: 27018
ELASTIC_SERVICE_PORT: 9201
-
-
对于MongoDB,在
services/mongo_4/ports部分,暴露新的MongoDB端口:<new-mongodb-port>:27017例如:
20718:27017 -
对于Elastic,在
services/elasticsearch/ports部分,暴露新的Elastic端口:<new-elasticsearch-port>:9200例如:
9201:9200 -
重启ClearML服务器,请参阅重启ClearML服务器。
如何绕过代理配置以访问我的本地ClearML服务器?
代理服务器可能会阻止访问配置为localhost的ClearML服务器。
要解决这个问题,您可以允许使用系统环境变量绕过代理服务器访问localhost,并使用它配置ClearML以连接ClearML服务器。
执行以下操作:
-
允许使用系统环境变量绕过代理服务器访问
localhost,例如:NO_PROXY = localhost -
如果存在ClearML配置文件(
clearml.conf),请删除它。 -
打开一个终端会话。
-
在终端会话中将系统环境变量设置为
127.0.0.1。例如:-
Linux:
no_proxy=127.0.0.1
NO_PROXY=127.0.0.1 -
Windows:
set no_proxy=127.0.0.1
set NO_PROXY=127.0.0.1
-
-
运行ClearML向导
clearml-init来为ClearML Server配置ClearML,这将提示您打开ClearML Web UI,http://127.0.0.1:8080/,并创建新的ClearML凭证。向导完成于:
Verifying credentials ...
Credentials verified!
New configuration stored in /home/<username>/clearml.conf
ClearML setup completed successfully.
ClearML 服务器不断返回 HTTP 500(或 400)错误。如何解决这个问题?
当某些后端组件出现故障时,ClearML 服务器将返回 HTTP 错误响应(5XX 或 4XX)。
此类故障的一个常见原因是可用磁盘空间不足,因为当服务器使用的Elasticsearch服务达到Elasticsearch洪水标记(默认设置为使用95%的磁盘空间)时,它将进入只读模式。
这可以通过为Elasticsearch服务提供更多的磁盘空间来轻松解决(要么释放磁盘空间,要么如果使用动态云存储,增加磁盘大小)。
这种情况的可能迹象可以通过在您的clearml日志中搜索"[FORBIDDEN/12/index read-only / allow delete (api)]"来确定。
为什么我的ClearML WebApp(UI)没有显示任何数据?
如果您的ClearML WebApp(UI)没有显示任何内容,可能是与服务器进行身份验证时出错。请尝试在浏览器的开发者工具中清除该站点的应用程序cookie。
为什么我在虚拟机中运行代码时无法访问我的ClearML服务器?
虚拟机(或容器)内部的网络定义与主机的不同。虚拟机的IP地址和服务器的IP地址是不同的,因此您必须确保执行实验的机器能够访问服务器的机器。
确保为运行实验的虚拟机拥有一个独立的配置文件。
编辑clearml.conf文件的api部分,并插入可从虚拟机访问的服务器机器的IP地址。它应该看起来像这样:
api {
web_server: http://192.168.1.2:8080
api_server: http://192.168.1.2:8008
credentials {
"access_key" = "KEY"
"secret_key" = "SECRET"
}
}
ClearML 代理
如何每次执行ClearML Agent而不需要安装包?
与其在由ClearML Agent创建的虚拟环境中安装Python包,您可以通过从全局site-packages目录继承包来优化执行时间。在ClearML配置文件中,将配置选项agent.package_manager.system_site_packages设置为true。
ClearML API
如何使用ClearML API获取数据?
你可以使用APIClient类,它提供了一个Pythonic接口来访问ClearML的后端REST API。通过一个APIClient实例,你可以访问ClearML的REST API服务和端点。
要使用APIClient,首先创建它的一个实例,然后调用与所需REST API端点对应的方法,并按照REST API参考页面中描述的相应参数进行操作。
例如,POST/ projects.get_all 调用返回您工作区中的所有项目。以下代码使用 APIClient 检索名称以 "example" 开头的所有项目列表。
from clearml.backend_api.session.client import APIClient
# Create an instance of APIClient
client = APIClient()
project_list = client.projects.get_all(name="example*")
print(project_list)
欲了解更多信息,请参阅APIClient。