dask.array.map_块
dask.array.map_块¶
- dask.array.map_blocks(func, *args, name=None, token=None, dtype=None, chunks=None, drop_axis=None, new_axis=None, enforce_ndim=False, meta=None, **kwargs)[源代码]¶
将一个函数映射到 dask 数组的所有块上。
请注意,
map_blocks将尝试通过在输入的0-d版本上调用func来自动确定输出数组类型。如果你预计该函数在操作0-d数组时不会成功,请参阅下面的meta关键字参数。- 参数
- 函数可调用
应用于数组中每个块的函数。如果
func接受block_info=或block_id=作为关键字参数,这些参数将被传递包含计算期间输入和输出块/数组信息的字典。详见示例。- 参数dask 数组或其他对象
- dtypenp.dtype, 可选
输出数组的
dtype。建议提供此项。如果未提供,将通过将函数应用于一小部分假数据来推断。- 块tuple, 可选
如果函数不保留形状,则结果块的块形状。如果未提供,则假定结果数组与第一个输入数组具有相同的块结构。
- drop_axis数字或可迭代对象,可选
函数丢失的维度。
- 新轴数字或可迭代对象,可选
函数创建的新维度。请注意,这些是在应用 ``drop_axis``(如果存在)之后应用的。
- enforce_ndimbool, 默认 False
是否在运行时强制要求
func生成的数组的维度实际上与map_blocks返回的数组的维度匹配。如果为 True,则在出现不匹配时将引发错误。- 令牌字符串,可选
用于输出数组的关键前缀。如果未提供,将根据函数名称确定。
- 名称字符串,可选
用于输出数组的键名。请注意,这完全指定了输出键名,并且必须是唯一的。如果未提供,将通过参数的哈希值确定。
- meta类似数组,可选
输出数组的
meta,当指定时,预期为与调用此函数返回的数组上调用.compute()时返回的类型和 dtype 相同的数组。如果未提供,meta将通过将函数应用于一小部分假数据(通常是 0-d 数组)来推断。确保func在传递 0-d 时能够成功完成计算而不引发异常非常重要,否则将需要提供meta。如果事先知道输出类型(例如,np.ndarray,cupy.ndarray),可以传递此类型的空数组,例如:meta=np.array((), dtype=np.int32)。- **kwargs
传递给函数的其他关键字参数。值必须是常量(不是 dask.arrays)
参见
dask.array.map_overlap与邻居之间存在重叠的广义操作。
dask.array.blockwise通过控制块对齐进行广义操作。
示例
>>> import dask.array as da >>> x = da.arange(6, chunks=3)
>>> x.map_blocks(lambda x: x * 2).compute() array([ 0, 2, 4, 6, 8, 10])
da.map_blocks函数也可以接受多个数组。>>> d = da.arange(5, chunks=2) >>> e = da.arange(5, chunks=2)
>>> f = da.map_blocks(lambda a, b: a + b**2, d, e) >>> f.compute() array([ 0, 2, 6, 12, 20])
如果函数改变了块的形状,那么你必须显式地提供块。
>>> y = x.map_blocks(lambda x: x[::2], chunks=((2, 2),))
在指定块时,您有一定的自由度。如果所有输出块的大小相同,您可以仅提供该块大小作为一个单一的元组。
>>> a = da.arange(18, chunks=(6,)) >>> b = a.map_blocks(lambda x: x[:3], chunks=(3,))
如果函数改变了块的维度,您必须指定创建或销毁的维度。
>>> b = a.map_blocks(lambda x: x[None, :, None], chunks=(1, 6, 1), ... new_axis=[0, 2])
如果指定了
chunks但未指定new_axis,则会在左侧推断并添加必要数量的轴。注意,
map_blocks()会在应用函数之前,沿着由关键字参数drop_axis指定的轴连接块。这在下图中进行了说明: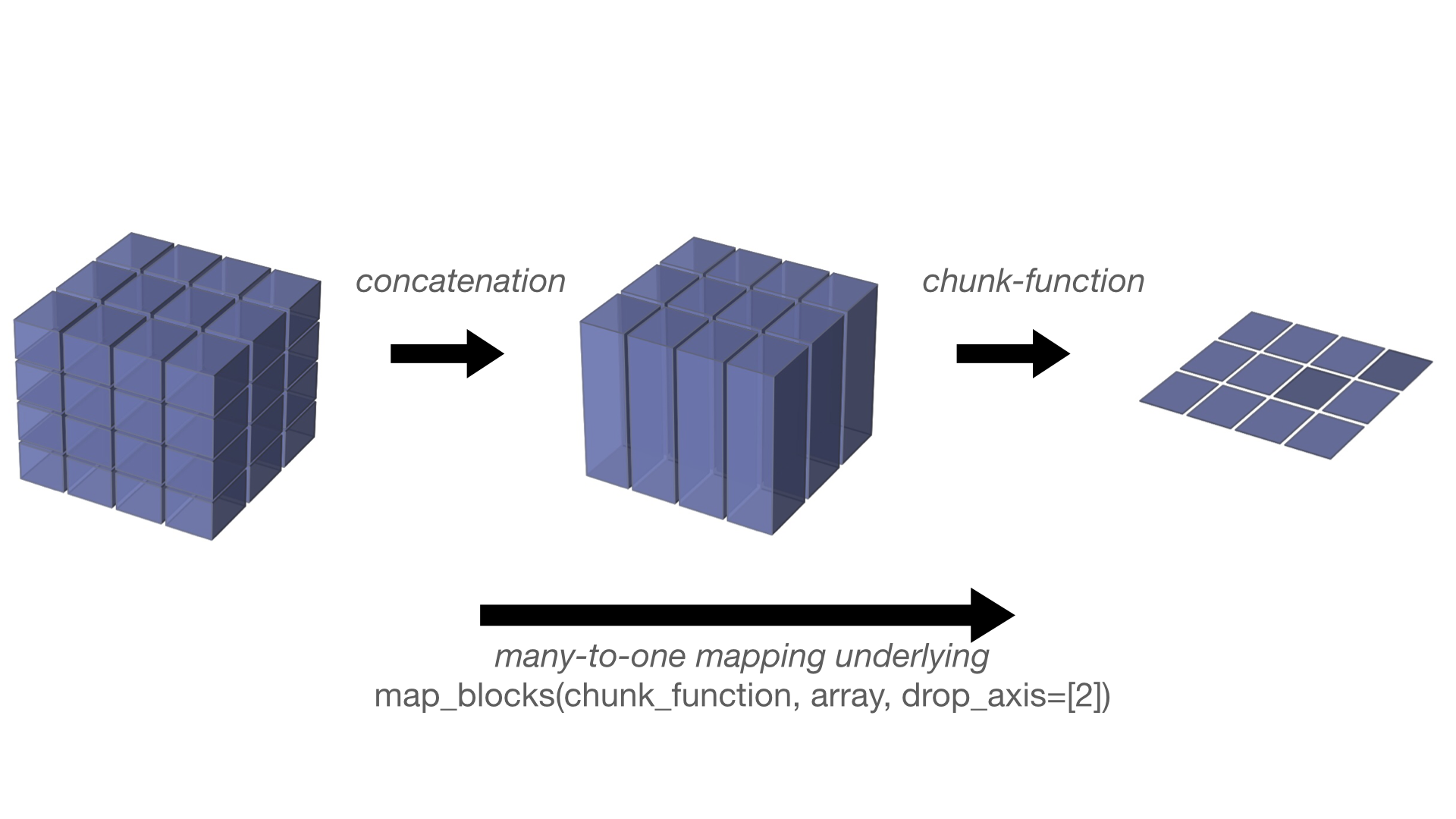
由于内存大小限制,通常不建议在已分块的轴上使用
drop_axis。在这种情况下,最好不要使用map_blocks,而是使用dask.array.reduction(..., axis=dropped_axes, concatenate=False),它在删除任何轴的同时保持了更小的内存占用。Map_blocks 通过块位置对齐块,而不考虑形状。在下面的示例中,我们有两个数组,它们具有相同数量的块,但形状和块大小不同。
>>> x = da.arange(1000, chunks=(100,)) >>> y = da.arange(100, chunks=(10,))
要匹配的相关属性是 numblocks。
>>> x.numblocks (10,) >>> y.numblocks (10,)
如果这些匹配(根据广播规则),那么我们可以在块上应用任意函数
>>> def func(a, b): ... return np.array([a.max(), b.max()])
>>> da.map_blocks(func, x, y, chunks=(2,), dtype='i8') dask.array<func, shape=(20,), dtype=int64, chunksize=(2,), chunktype=numpy.ndarray>
>>> _.compute() array([ 99, 9, 199, 19, 299, 29, 399, 39, 499, 49, 599, 59, 699, 69, 799, 79, 899, 89, 999, 99])
你的块函数可以通过接受一个特殊的
block_info或block_id关键字参数来获取它在数组中的位置信息。在计算过程中,它们将包含与每次调用func相关的每个输入和输出块(以及 dask 数组)的信息。>>> def func(block_info=None): ... pass
这将接收以下信息:
>>> block_info {0: {'shape': (1000,), 'num-chunks': (10,), 'chunk-location': (4,), 'array-location': [(400, 500)]}, None: {'shape': (1000,), 'num-chunks': (10,), 'chunk-location': (4,), 'array-location': [(400, 500)], 'chunk-shape': (100,), 'dtype': dtype('float64')}}
block_info字典的键指示哪个是输入和输出的 Dask 数组:输入 Dask 数组:
block_info[0]指的是第一个输入的 Dask 数组。字典键是0,因为这是对应于第一个输入 Dask 数组的参数索引。在多个 Dask 数组作为输入传递给函数的情况下,你可以通过对应于输入参数的数字来访问它们,例如:block_info[1],block_info[2]等。(注意,如果你将多个 Dask 数组作为输入传递给 map_blocks,这些数组必须通过在广播规则下对应维度上具有匹配的块数来相互匹配。)输出 Dask 数组:
block_info[None]指的是输出 Dask 数组,并包含有关输出块的信息。输出块的形状和数据类型可能与输入块不同。
对于每个dask数组,
block_info描述:shape: 完整 Dask 数组的形状,num-chunks: 每个维度中完整数组的块数,chunk-location: 块位置(例如在第一维度上的第四个块),以及array-location: 在完整 Dask 数组中的数组位置(例如对应于40:50的切片)。
除了这些,输出数组(在
block_info[None]中)还有两个由block_info描述的额外参数:chunk-shape: 输出块的形状,以及dtype: 输出数据类型。
这些功能可以结合起来从头合成一个数组,例如:
>>> def func(block_info=None): ... loc = block_info[None]['array-location'][0] ... return np.arange(loc[0], loc[1])
>>> da.map_blocks(func, chunks=((4, 4),), dtype=np.float64) dask.array<func, shape=(8,), dtype=float64, chunksize=(4,), chunktype=numpy.ndarray>
>>> _.compute() array([0, 1, 2, 3, 4, 5, 6, 7])
block_id类似于block_info,但仅包含chunk_location:>>> def func(block_id=None): ... pass
这将接收以下信息:
>>> block_id (4, 3)
您可以使用可选的
token关键字参数指定图表中生成的任务的键名前缀。>>> x.map_blocks(lambda x: x + 1, name='increment') dask.array<increment, shape=(1000,), dtype=int64, chunksize=(100,), chunktype=numpy.ndarray>
对于可能不处理 0-d 数组的函数,也可以使用与预期结果类型匹配的空数组来指定
meta。在下面的示例中,计算meta时func将导致IndexError:>>> rng = da.random.default_rng() >>> da.map_blocks(lambda x: x[2], rng.random(5), meta=np.array(())) dask.array<lambda, shape=(5,), dtype=float64, chunksize=(5,), chunktype=numpy.ndarray>
同样地,可以为
meta指定一个非 NumPy 数组,并提供一个dtype:>>> import cupy >>> rng = da.random.default_rng(cupy.random.default_rng()) >>> dt = np.float32 >>> da.map_blocks(lambda x: x[2], rng.random(5, dtype=dt), meta=cupy.array((), dtype=dt)) dask.array<lambda, shape=(5,), dtype=float32, chunksize=(5,), chunktype=cupy.ndarray>