在 GKE 上部署机器学习流水线
在 Google Kubernetes Engine 上部署机器学习流水线
作者:Moez Ali

回顾
在我们关于在云端部署机器学习流水线的上一篇文章中,我们演示了如何使用 PyCaret 开发机器学习流水线,将其与 Docker 容器化,并作为 Web 应用程序在 Microsoft Azure Web App Services 上提供服务。如果你之前没有听说过 PyCaret,请阅读这篇公告以了解更多信息。
在本教程中,我们将使用之前构建和部署的相同机器学习流水线和 Flask 应用程序。这次我们将演示如何在 Google Kubernetes Engine 上将机器学习流水线容器化并部署。
👉 本教程的学习目标
- 了解什么是容器,什么是 Docker,什么是 Kubernetes,以及什么是 Google Kubernetes Engine?
- 构建 Docker 镜像并将其上传至 Google Container Registry(GCR)。
- 创建集群并部署一个带有 Flask 应用程序的机器学习流水线作为 Web 服务。
- 查看一个 Web 应用程序的实际运行,该应用程序使用训练有素的机器学习流水线实时预测新数据点。
之前我们演示了如何在 Heroku PaaS 上部署机器学习流水线以及如何使用 Docker 容器在 Azure Web Services 上部署机器学习流水线。
本教程将覆盖从构建 Docker 镜像开始,将其上传到 Google Container Registry,然后部署预训练的机器学习流水线和 Flask 应用程序到 Google Kubernetes Engine(GKE)的整个工作流程。
💻 本教程的工具箱
PyCaret
PyCaret 是一个开源的、低代码的 Python 机器学习库,用于训练和部署机器学习流水线和模型到生产环境中。可以使用 pip 轻松安装 PyCaret。
pip install pycaret
Flask
Flask 是一个框架,允许你构建 Web 应用程序。Web 应用程序可以是商业网站、博客、电子商务系统,或者是使用训练模型实时提供数据预测的应用程序。如果你还没有安装 Flask,可以使用 pip 安装它。
Google Cloud Platform
Google Cloud Platform(GCP)由 Google 提供,是一套云计算服务,运行在 Google 用于其终端用户产品(如 Google 搜索、Gmail 和 YouTube)的相同基础架构上。如果你还没有 GCP 帐户,可以在这里注册。如果你是第一次注册,将获得为期 1 年的免费信用额度。
让我们开始吧。
在深入 Kubernetes 之前,让我们了解一下什么是容器,以及为什么我们需要它?

你是否曾经遇到这样的问题:你的代码在你的计算机上运行正常,但当朋友尝试运行完全相同的代码时,却无法正常工作?如果你的朋友重复了完全相同的步骤,他或她应该得到相同的结果,对吧?这个问题的答案是**环境**。你朋友的环境与你的不同。
环境包括什么?→ 编程语言,如 Python,以及构建和测试应用程序时使用的所有库和依赖项的确切版本。
如果我们可以创建一个可以转移到其他计算机(例如:你朋友的计算机或像 Google Cloud Platform 这样的云服务提供商)的环境,我们就可以在任何地方重现结果。因此,***一个****容器***是一种软件类型,它打包应用程序及其所有依赖项,使应用程序能够可靠地从一个计算环境运行到另一个计算环境。
那么 Docker 是什么呢?

Docker 是一家提供软件(也称为 Docker)的公司,允许用户构建、运行和管理容器。虽然 Docker 的容器是最常见的,但还有其他不那么出名的_替代方案_,如LXD和LXC提供容器解决方案。
现在你了解了容器和具体的 Docker,让我们了解一下 Kubernetes 是什么。 Kubernetes是由Google于2014年开发的一种强大的开源系统,用于管理容器化应用程序。简单来说,Kubernetes是一种在机群中运行和协调容器化应用程序的系统。它是一个旨在完全管理容器化应用程序的生命周期的平台。

特点
✔️ **负载均衡:**自动在容器之间分配负载。
✔️ **扩展:**根据需求的变化(如高峰时段、周末和假期)自动增加或删除容器。
✔️ **存储:**保持多个应用程序实例的存储一致。
✔️ **自愈:**自动重新启动失败的容器,并杀死不响应用户定义的健康检查的容器。
✔️ **自动化部署:**您可以自动化Kubernetes来为您的部署创建新的容器,删除现有的容器,并将所有资源转移到新的容器。
如果您已经使用Docker,为什么还需要Kubernetes?
想象一下这样的场景:您需要在多台机器上运行多个Docker容器,以支持一个企业级的机器学习应用程序,在白天和晚上的工作负载各不相同。尽管听起来很简单,但手动完成这项工作是非常繁琐的。
您需要在正确的时间启动正确的容器,弄清它们如何相互通信,处理存储考虑因素,并处理失败的容器或硬件。这正是Kubernetes通过允许大量容器协同工作来解决的问题,从而减轻了运营负担。
将Docker与Kubernetes进行比较是一个错误。这是两种不同的技术。Docker是一种软件,允许您将应用程序容器化,而Kubernetes是一个容器管理系统,允许创建、扩展和监控数百甚至数千个容器。
在任何应用程序的生命周期中,Docker用于在部署时打包应用程序,而Kubernetes用于管理应用程序的其余生命周期。

什么是Google Kubernetes Engine?
Google Kubernetes Engine是在Google Cloud Platform上实现Google开源Kubernetes的一种方式。简单!
GKE的其他热门替代品包括Amazon ECS和Microsoft Azure Kubernetes Service。
最后一次,你明白了吗?
- 容器是一种软件类型,将应用程序及其所有依赖项打包,以便应用程序可以在不同的计算环境中可靠运行。
- Docker是用于构建和管理容器的软件。
- Kubernetes是一种在集群环境中管理容器化应用程序的开源系统。
- Google Kubernetes Engine是在Google Cloud Platform上实现开源Kubernetes框架的一种方式。
在本教程中,我们将使用Google Kubernetes Engine。为了跟进,请确保您拥有Google Cloud Platform帐户。点击这里免费注册。
设置业务背景
一家保险公司希望通过在入院时使用人口统计学和基本患者健康风险指标更好地预测患者费用,以改善现金流预测。
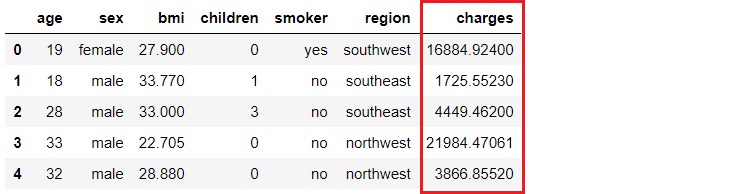
(数据来源)
目标
构建和部署一个Web应用程序,用户可以在基于Web的表单中输入患者的人口统计和健康信息,然后输出预测的费用金额。
任务
- 为部署训练和开发一个机器学习流水线。
- 使用Flask框架构建一个Web应用程序。它将使用训练好的机器学习流水线实时生成新数据点的预测结果。
- 构建一个Docker镜像,并将一个容器上传到Google容器注册表(GCR)。
- 在Google Kubernetes Engine上创建集群并部署应用程序。
由于我们已经在初始教程中涵盖了前两个任务,我们将快速回顾它们,然后专注于上述列表中的剩余项目。如果您有兴趣了解如何使用PyCaret在Python中开发机器学习流水线,并使用Flask框架构建Web应用程序,请阅读本教程。 我们正在使用Python中的PyCaret进行训练和开发机器学习流水线,该流水线将作为我们Web应用的一部分使用。机器学习流水线可以在集成开发环境(IDE)或笔记本中开发。我们使用笔记本来运行下面的代码:
当您在PyCaret中保存模型时,将根据**setup() **函数中定义的配置创建整个转换流水线。所有相互依赖关系都会自动协调。请参见存储在“deployment_28042020”变量中的流水线和模型:

👉 构建Web应用程序
本教程不专注于构建Flask应用程序。这里只是为了完整性而讨论。现在我们的机器学习流水线已经准备好了,我们需要一个Web应用程序,可以连接到我们训练好的流水线,以便实时生成新数据点的预测。我们使用Python中的Flask框架创建了Web应用程序。该应用程序由两部分组成:
- 前端(使用HTML设计)
- 后端(使用Flask开发)
这是我们的Web应用程序的外观:
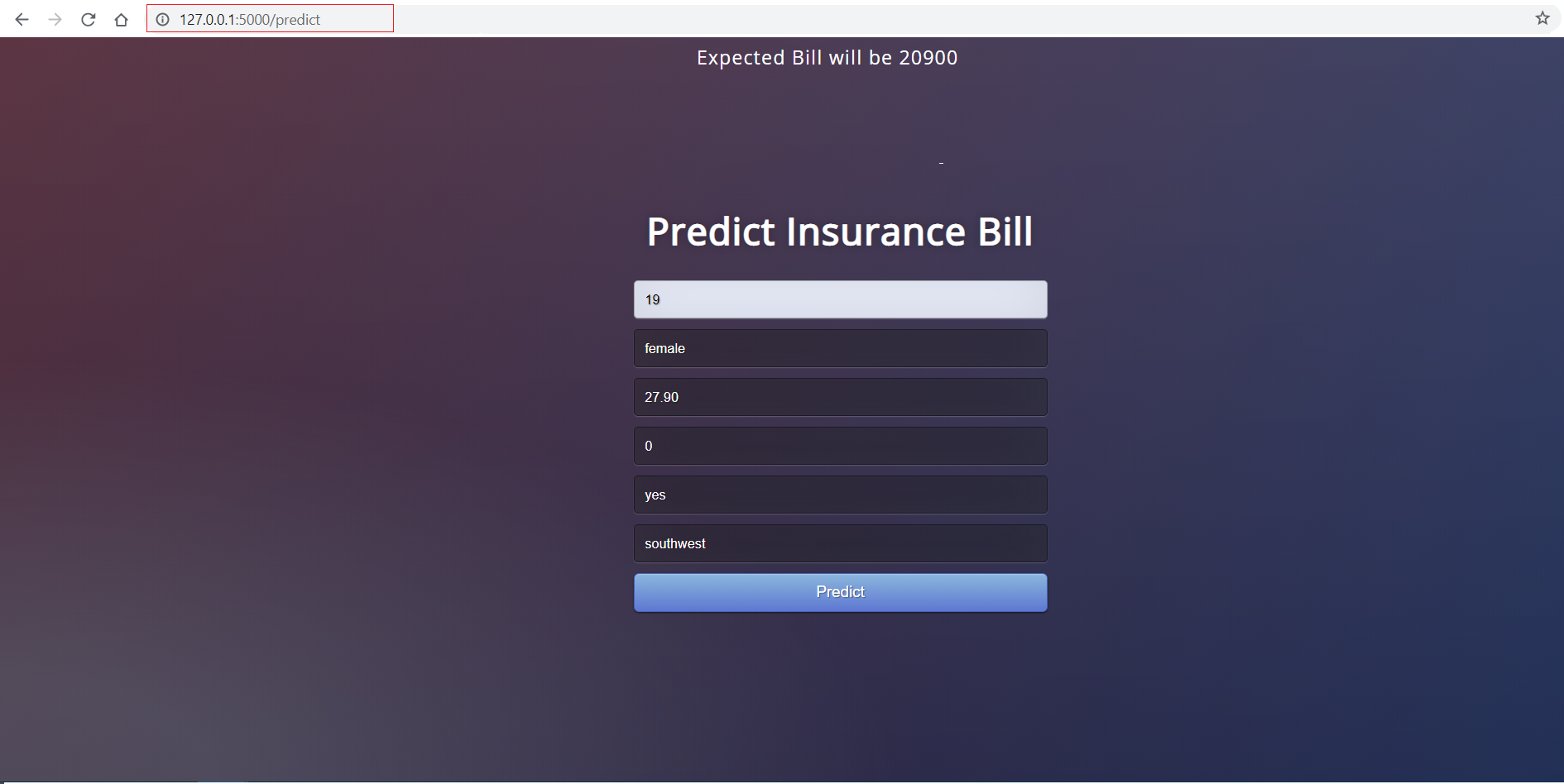
如果您到目前为止还没有跟随进行操作,没问题。您可以从GitHub上简单地fork这个存储库。此时,您的项目文件夹应如下所示:
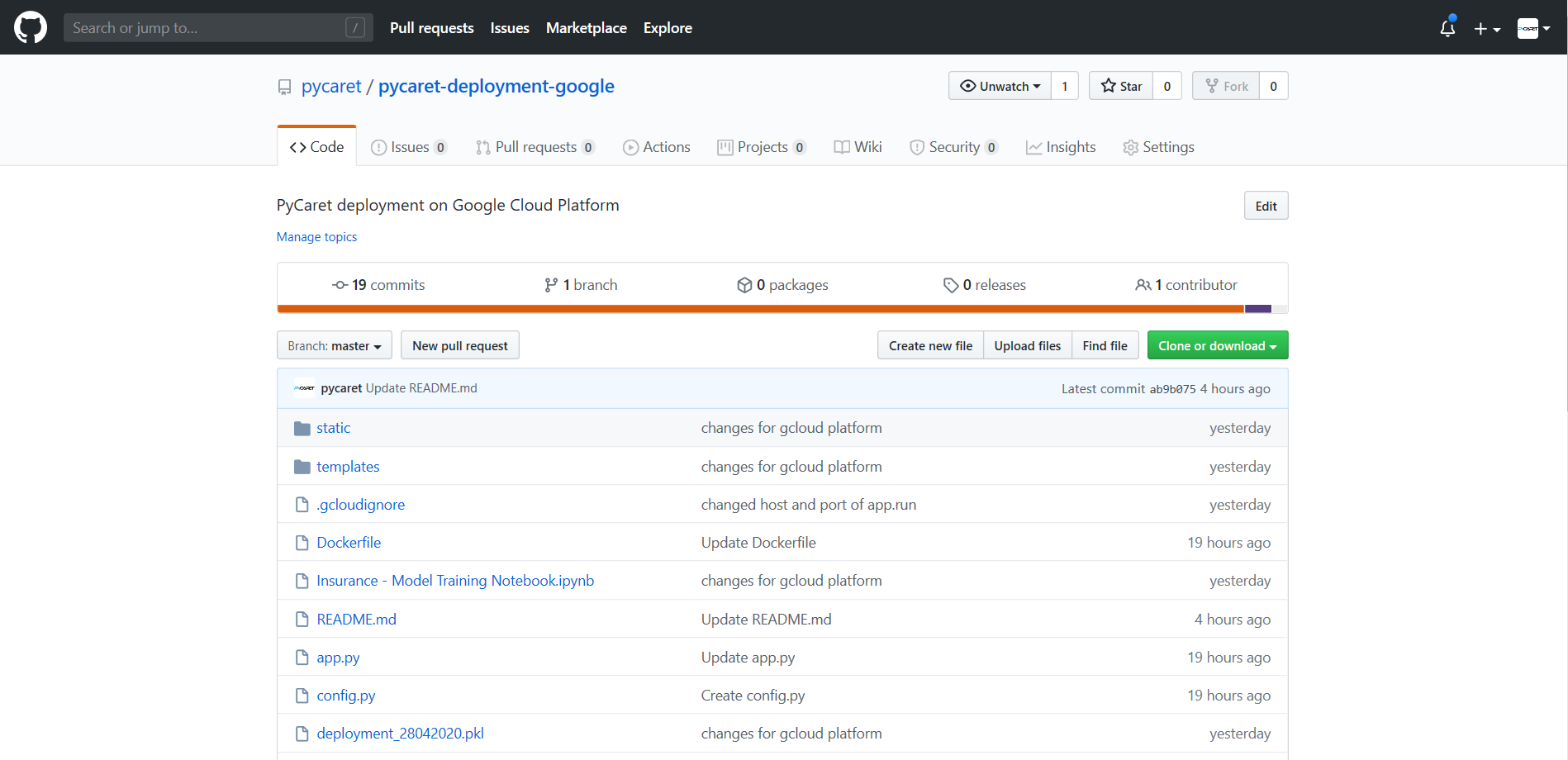
现在我们有了一个完全功能的Web应用程序,我们可以开始在Google Kubernetes Engine上进行容器化和部署应用程序的过程。
在Google Kubernetes Engine上部署ML流水线的10个步骤:
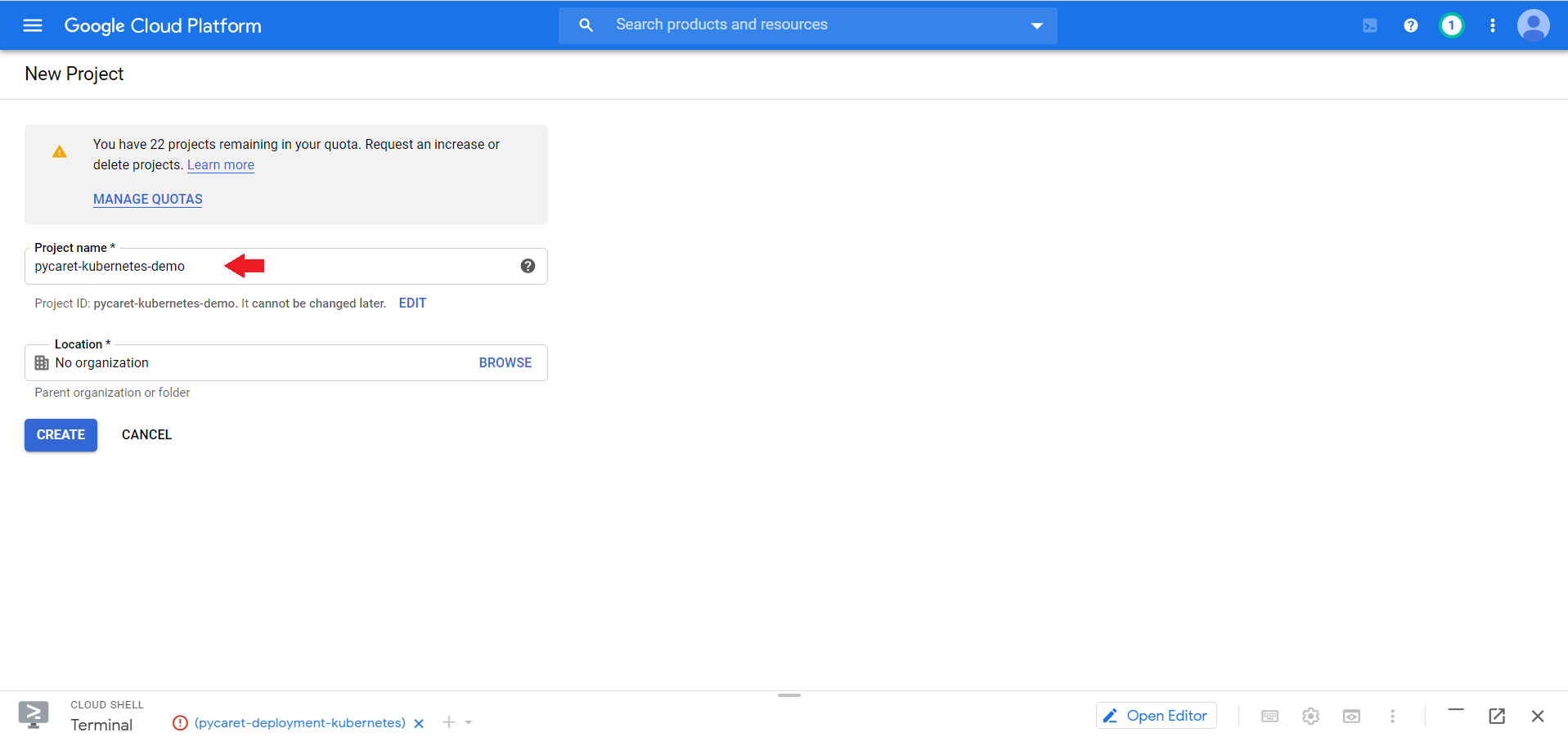
👉 第1步 - 在GCP控制台中创建一个新项目
登录到GCP控制台,然后转到“管理资源”
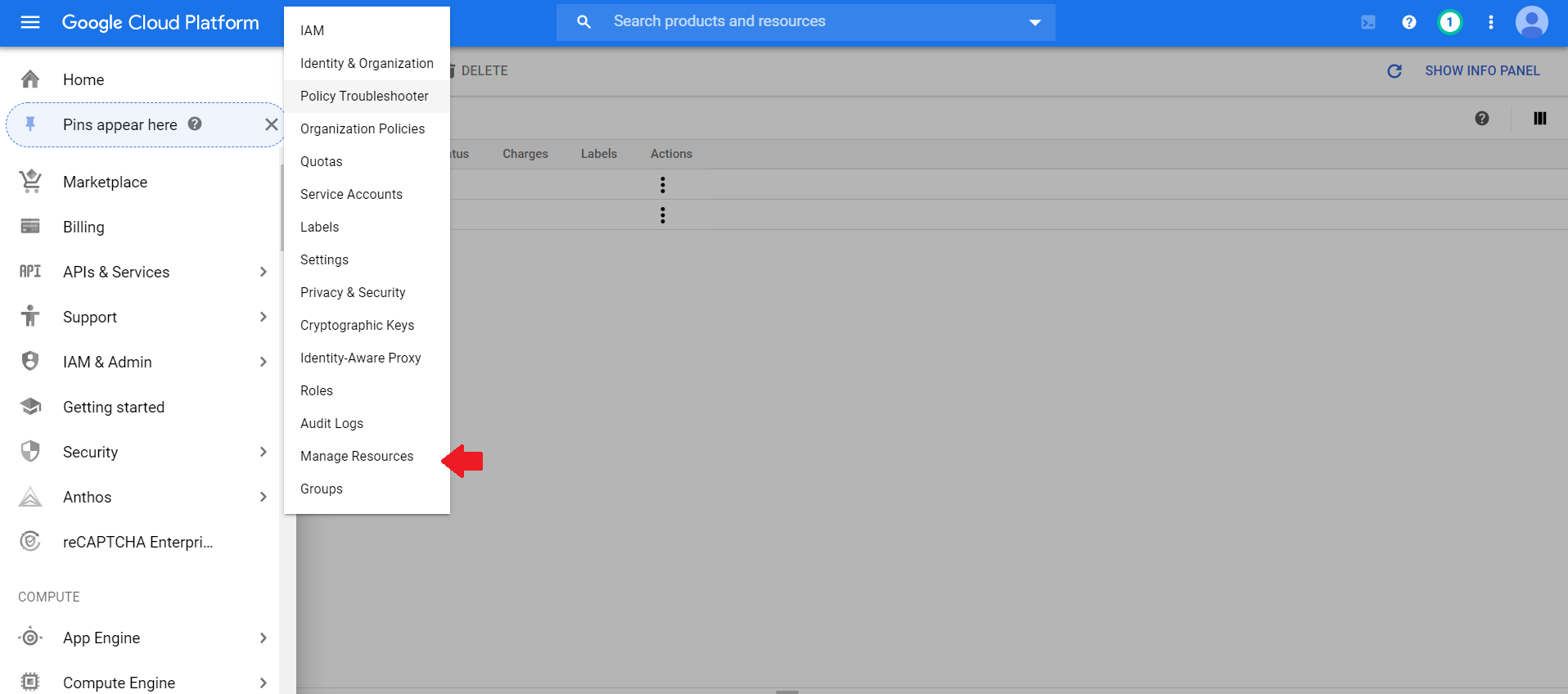
点击创建新项目
👉 第2步 - 导入项目代码
点击控制台窗口顶部的激活Cloud Shell按钮,以打开Cloud Shell。
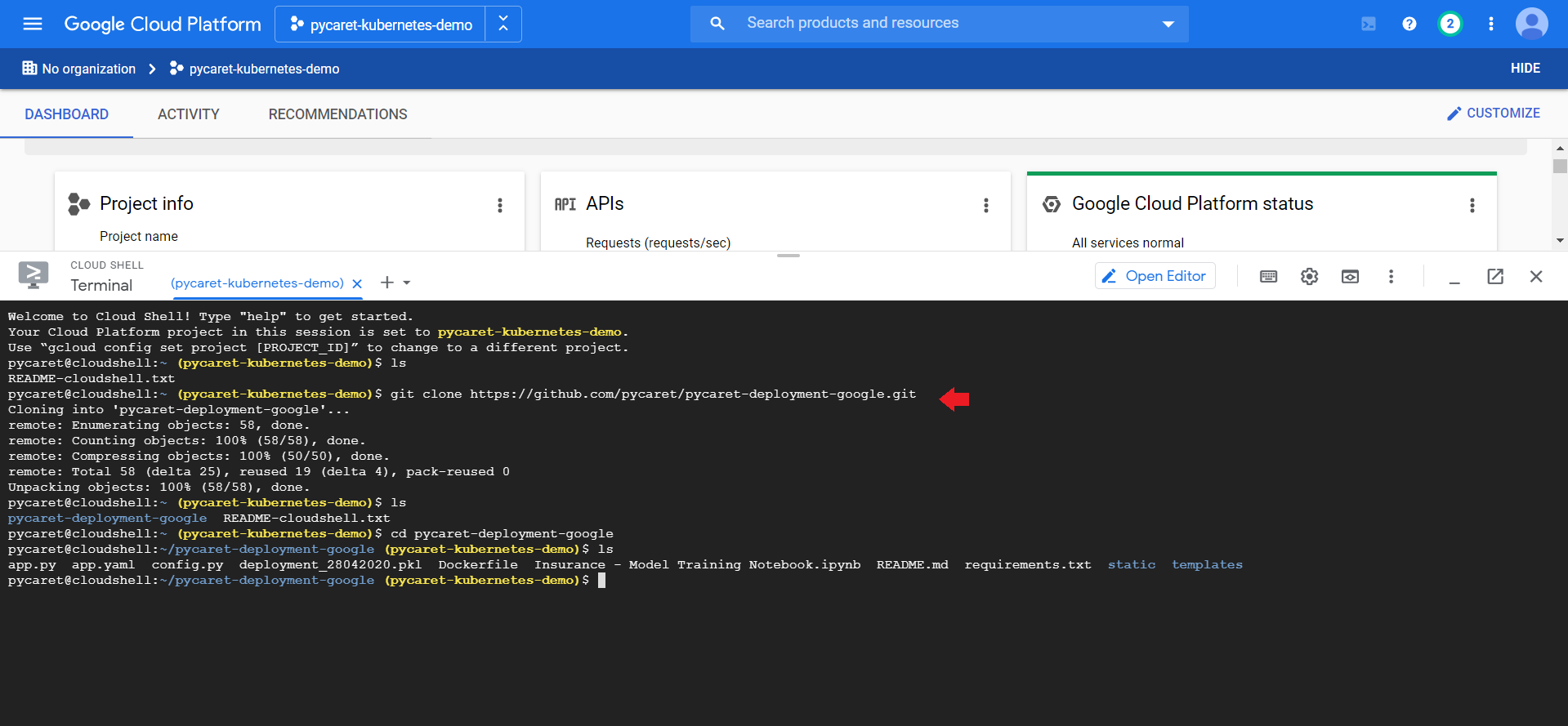
在Cloud Shell中执行以下代码,以克隆本教程中使用的GitHub存储库。
git clone https://github.com/pycaret/pycaret-deployment-google.git
👉 第3步 - 设置项目ID环境变量
执行以下代码以设置PROJECT_ID环境变量。
export PROJECT_ID=pycaret-kubernetes-demo
_pycaret-kubernetes-demo_是我们在上述第1步中选择的项目名称。
👉 第4步 - 构建Docker镜像
通过执行以下代码构建应用程序的Docker镜像并为其打标签,以便上传:
docker build -t gcr.io/${PROJECT_ID}/insurance-app:v1 .
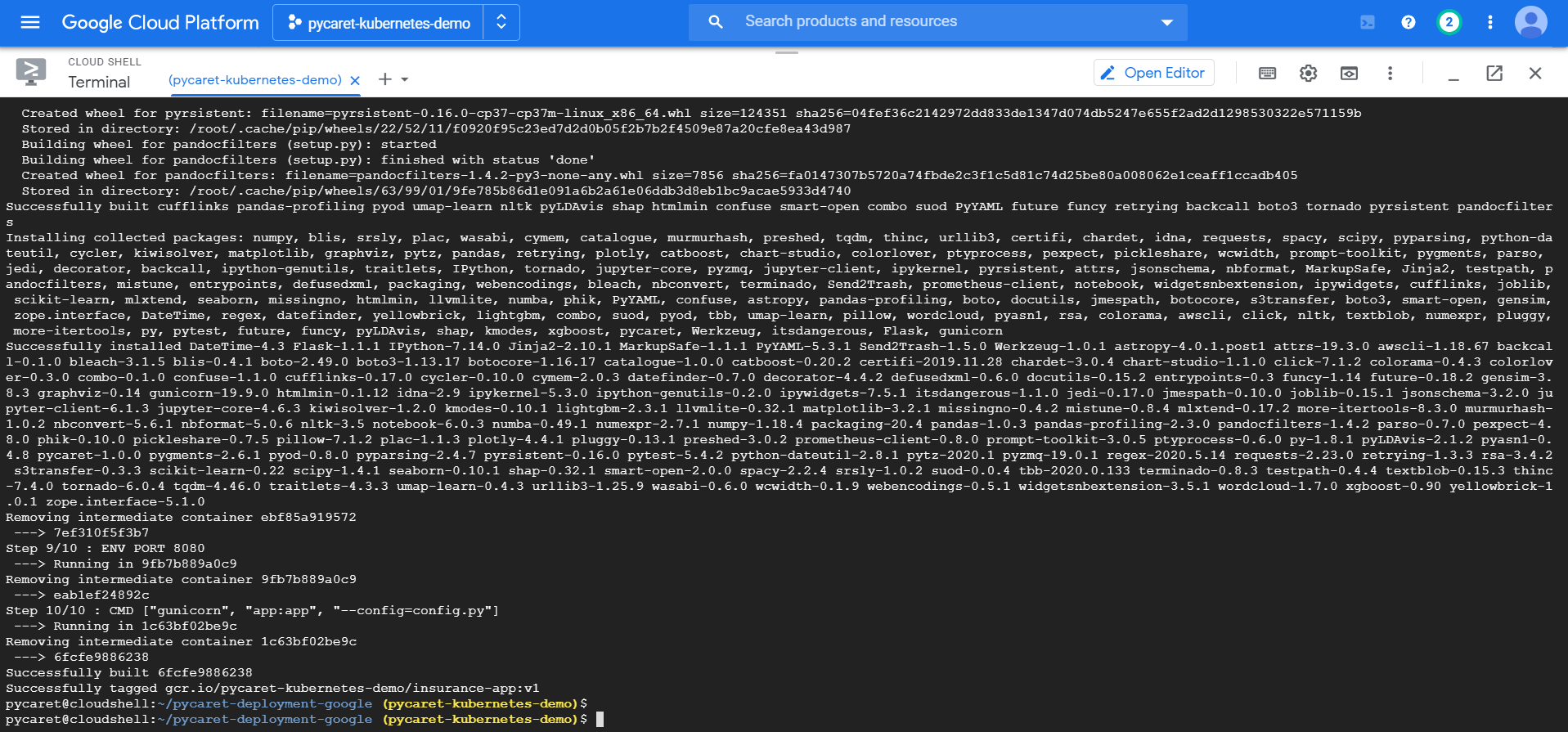
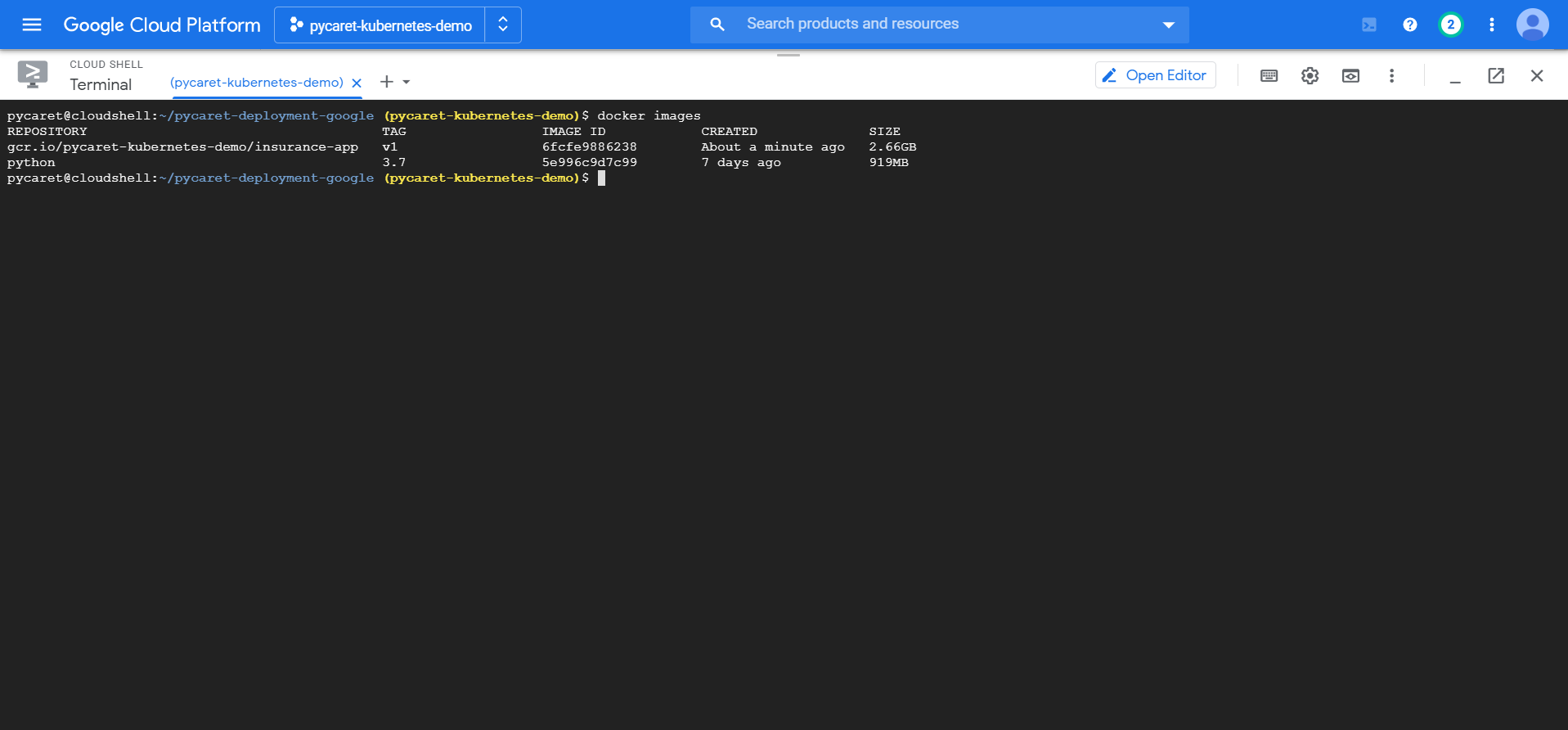
您可以通过运行以下代码来检查可用的镜像:
docker images
👉 第5步 - 上传容器镜像
-
验证容器注册表(只需运行一次):
gcloud auth configure-docker -
执行以下代码将Docker镜像上传到Google容器注册表:
docker push gcr.io/${PROJECT_ID}/insurance-app:v1
👉 第6步 - 创建集群
现在,已经上传了容器,您需要一个集群来运行容器。集群由一组运行Kubernetes的Compute Engine VM实例组成。
-
为gcloud工具设置项目ID和Compute Engine区域选项:
gcloud config set project $PROJECT\_ID gcloud config set compute/zone us-central1 -
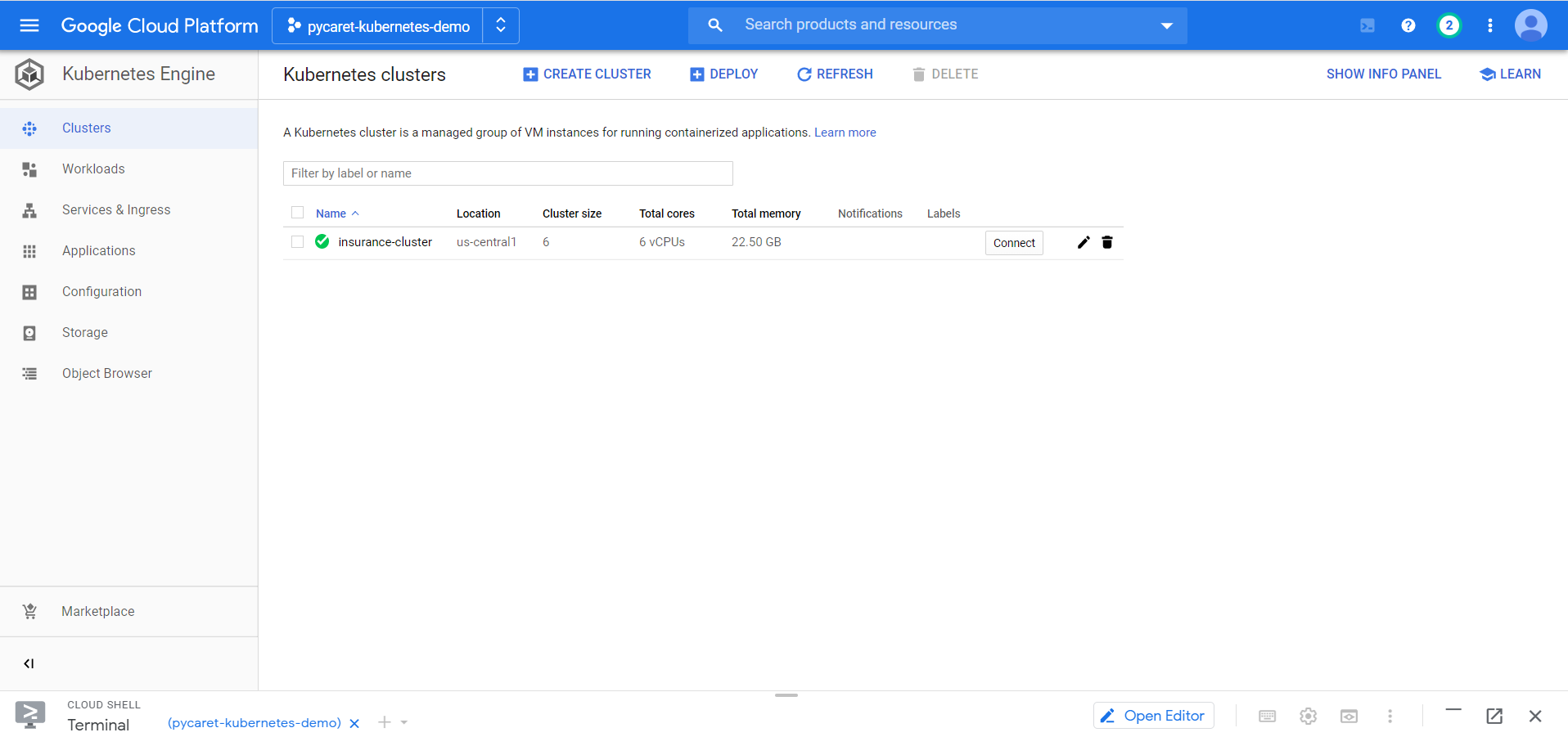
执行以下代码创建一个集群:
gcloud container clusters create insurance-cluster --num-nodes=2
👉 第7步 - 部署应用程序
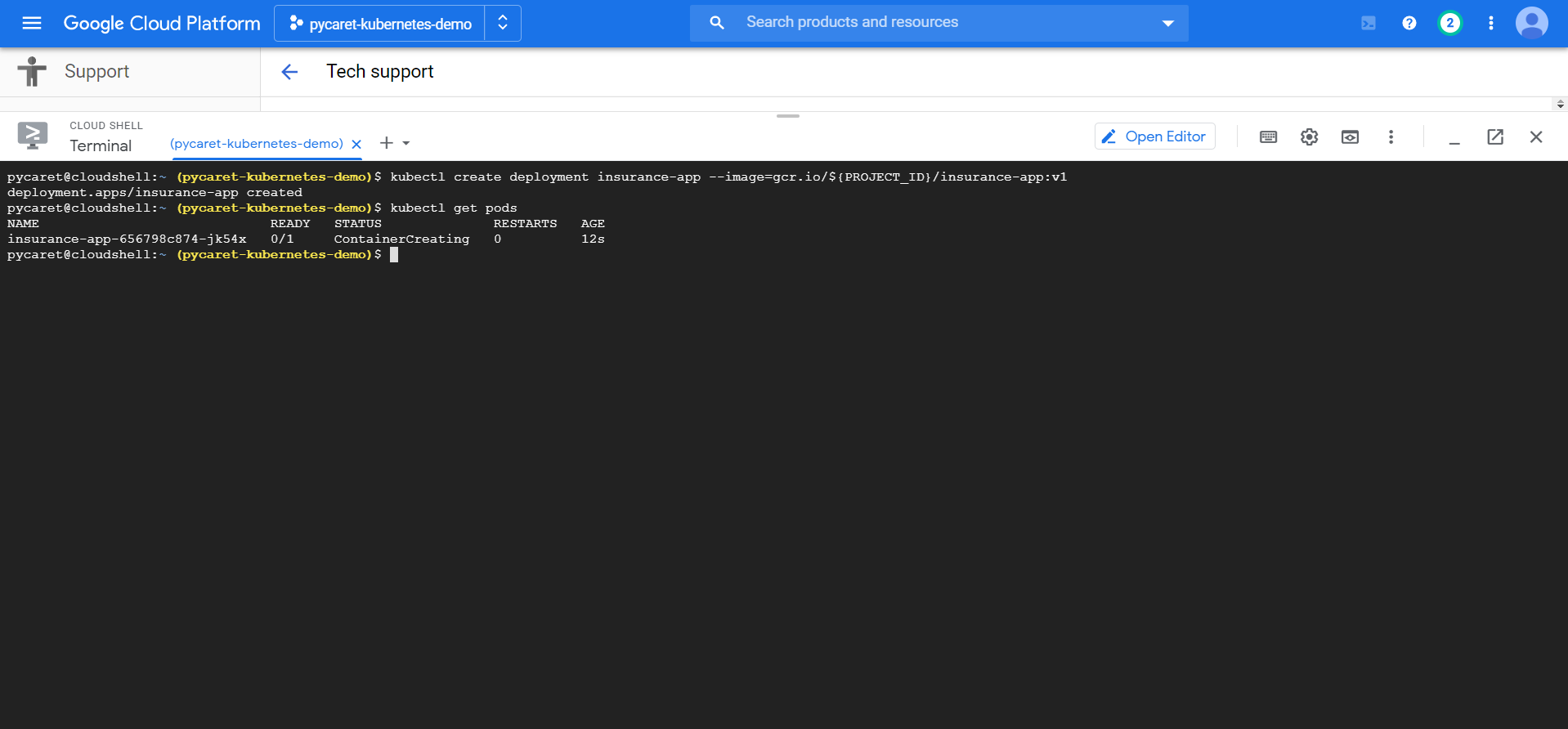
要在GKE集群上部署和管理应用程序,您必须与Kubernetes集群管理系统进行通信。执行以下命令部署应用程序:
kubectl create deployment insurance-app --image=gcr.io/${PROJECT_ID}/insurance-app:v1
👉 第 8 步— 将您的应用程序暴露给互联网
默认情况下,在 GKE 上运行的容器无法从互联网访问,因为它们没有外部 IP 地址。执行以下代码将应用程序暴露给互联网:
kubectl expose deployment insurance-app --type=LoadBalancer --port 80 --target-port 8080
👉 第 9 步— 检查服务
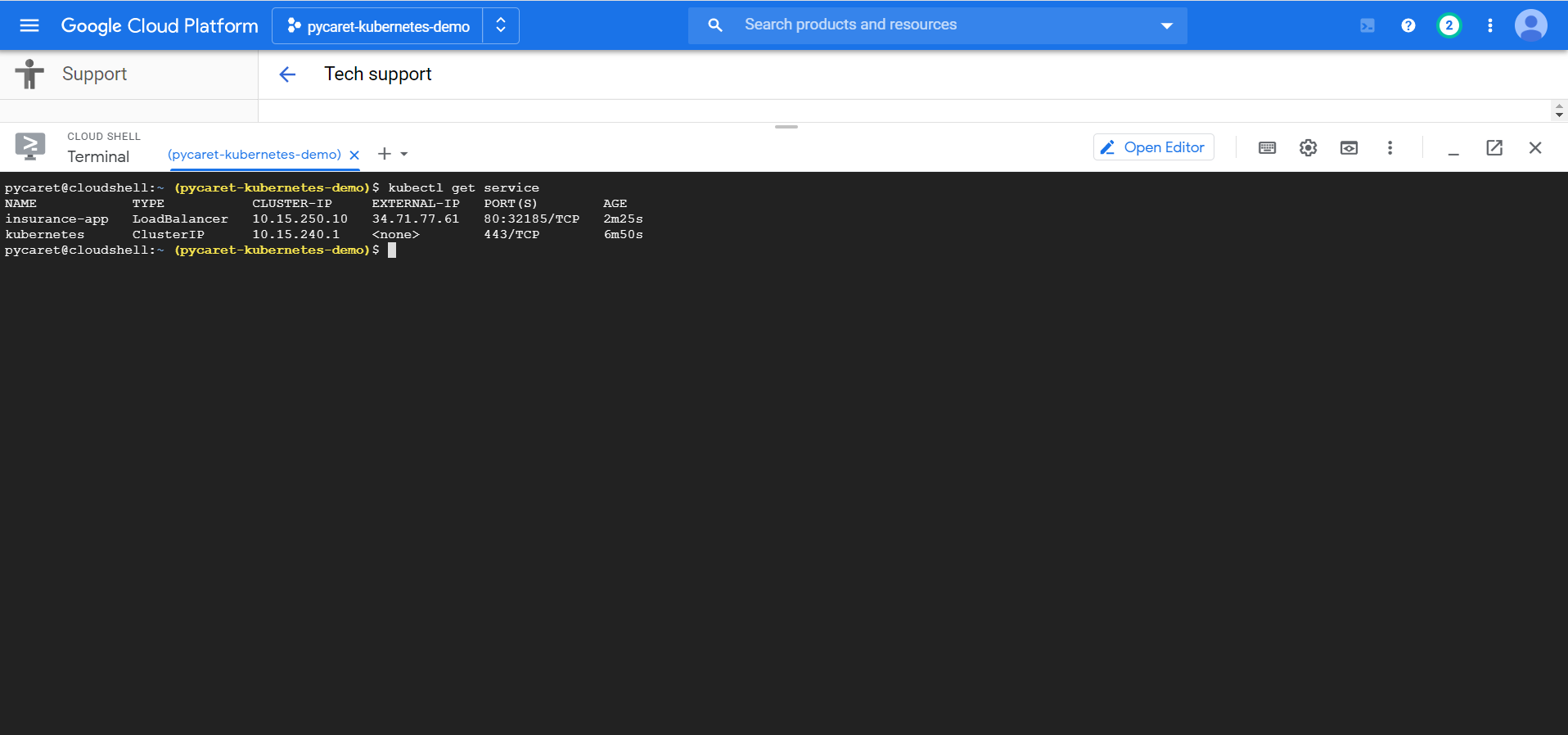
执行以下代码以获取服务的状态。EXTERNAL-IP 是您可以在浏览器中使用的 Web 地址,用于查看发布的应用程序。
kubectl get service
👉 第 10 步— 在 http://34.71.77.61:8080 上查看应用程序运行情况
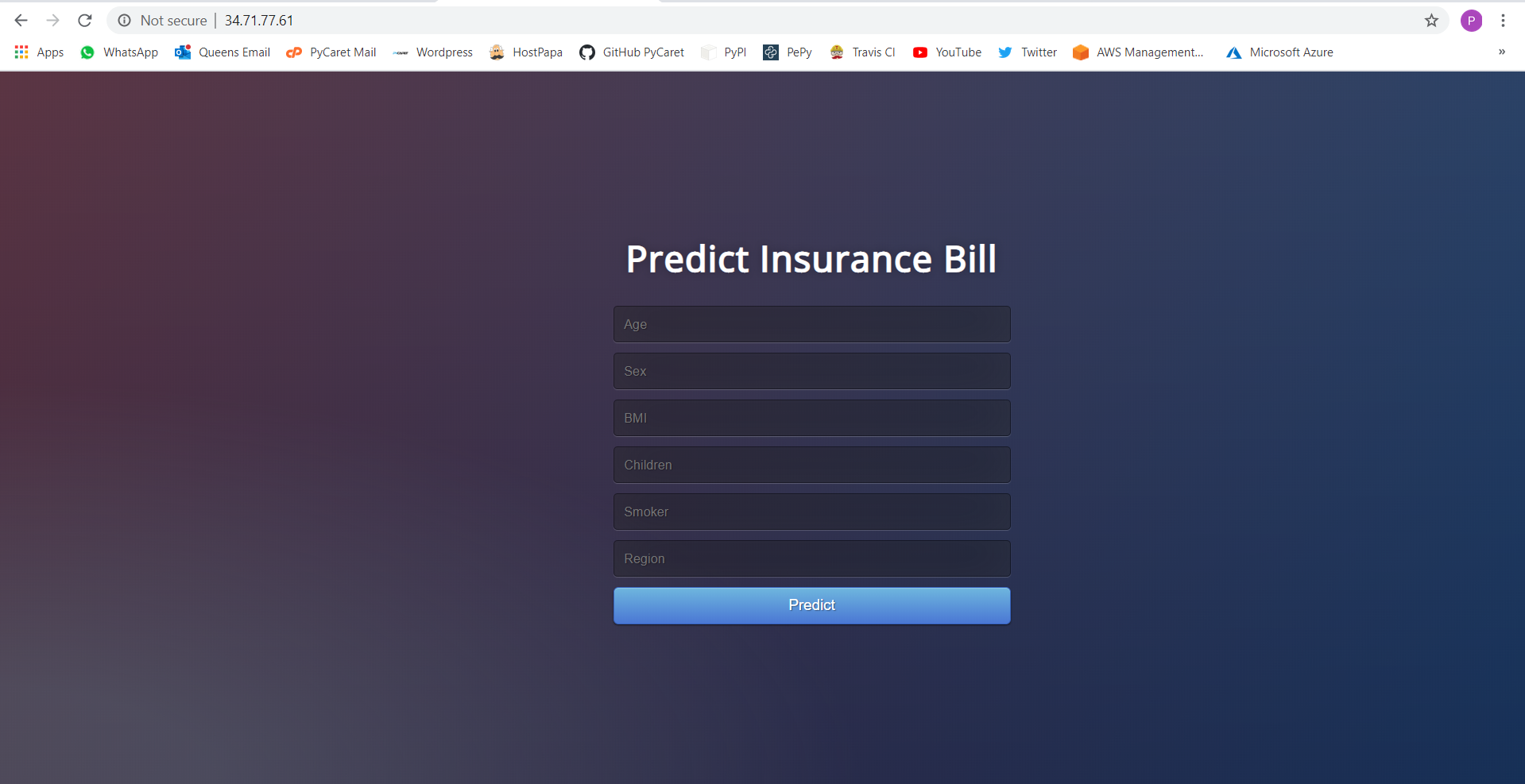
注意: 在发布本故事时,该应用程序将从公共地址中移除,以限制资源消耗。
Microsoft Azure 部署的 GitHub 仓库链接
PyCaret 1.0.1 即将发布!
我们收到了社区的大力支持和反馈。我们正在积极改进 PyCaret,并为下一个版本做准备。PyCaret 1.0.1 将更加强大和优秀。如果您想分享您的反馈并帮助我们进一步改进,您可以在网站上 填写此表格 或在我们的 GitHub 或 LinkedIn 页面上留言。
关注我们的 LinkedIn 并订阅我们的 YouTube 频道,了解更多关于 PyCaret 的信息。
想了解特定模块吗?
截至首次发布的 1.0.0 版本,PyCaret 提供以下可用模块。点击下面的链接查看 Python 中的文档和示例。
还可查看:
PyCaret 在 Notebook 中的入门教程:
想要贡献吗?
PyCaret 是一个开源项目。欢迎每个人贡献。如果您想贡献,请随时处理 开放问题。我们接受带有单元测试的拉取请求,分支为 dev-1.0.1。
如果您喜欢 PyCaret,请在我们的 GitHub 仓库 上给我们 ⭐️。
Medium:https://medium.com/@moez_62905/