路线图#
本文档提供了核心贡献者希望在 Feature-engine 中看到开发内容的一般方向。由于资源有限,我们无法承诺何时或是否会包含此处列出的转换器。我们欢迎所有能够支持这一愿景的帮助。如果您有兴趣贡献,请联系我们。
目的#
Feature-engine 的使命是简化和优化端到端特征工程管道的实现。它的目标是帮助用户在研究阶段以及将模型投入生产时都能受益。
Feature-engine 通过允许在其转换器中直接选择特征子集,使数据工程变得简单。它还通过返回数据框以便于数据探索,与探索性数据分析(EDA)很好地结合。
Feature-engine 的转换器保留了 Scikit-learn 的功能,具有 fit() 和 transform() 方法,并且可以集成到 Pipeline 中,以简化将模型投入生产的过程。
Feature-engine 设计用于实际应用场景。每个转换器都有明确的目标,并且针对特定变量和数据进行了定制。转换器会引发错误和警告,以支持用户在给定数据的情况下使用合适的转换。这些错误有助于避免在开发的不希望阶段无意中将缺失值引入数据框。
愿景#
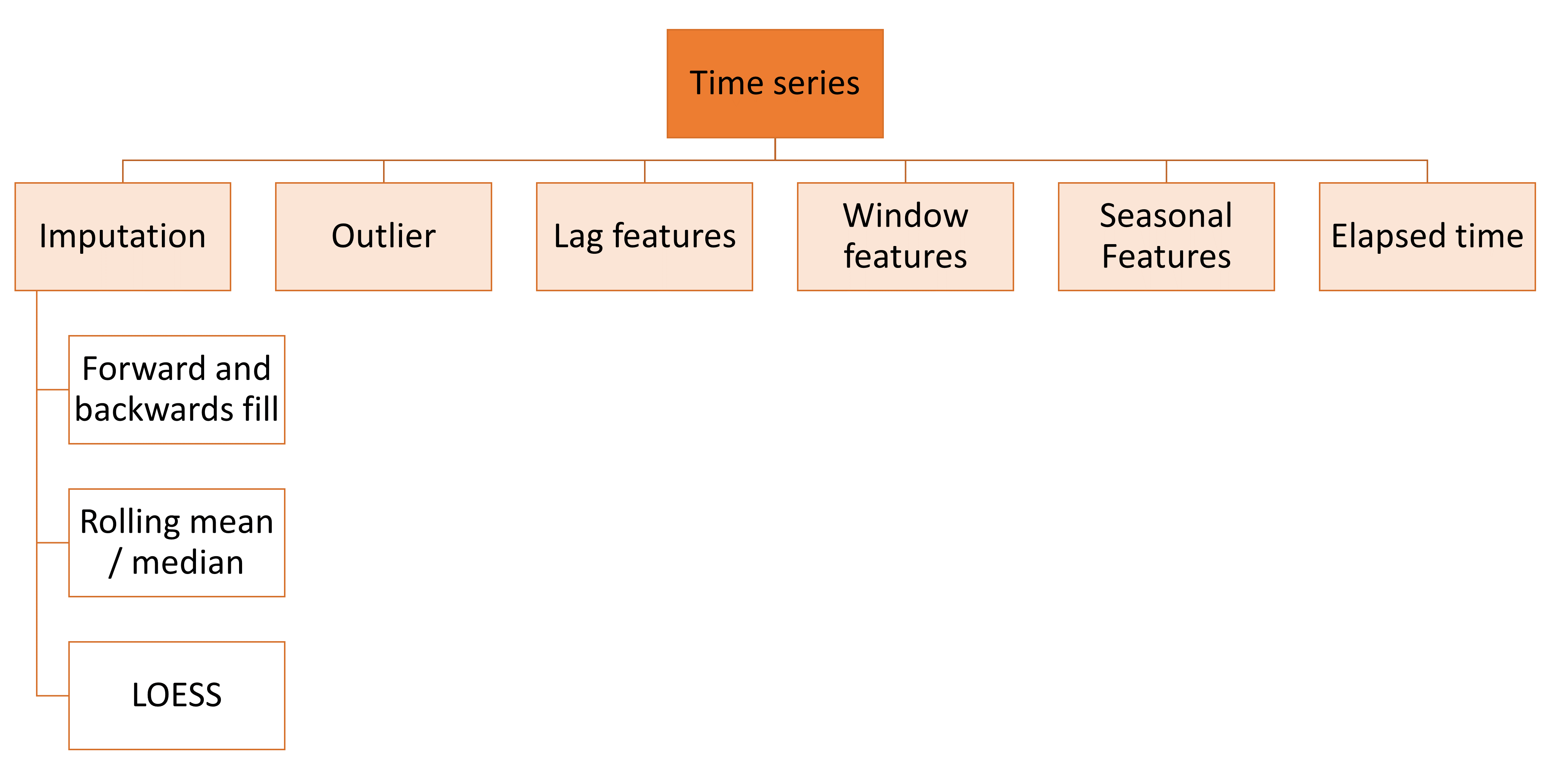
目前,Feature-engine 的功能主要针对表格数据,包括数值、分类或日期时间变量。我们从2022年开始支持时间序列预测的特征创建。
但我们希望扩展 Feature-engine 的功能,使其能够处理文本和时间序列数据,同时扩展其当前对表格数据的功能。
在下图中,我们展示了 Feature-engine 的总体结构和愿景:
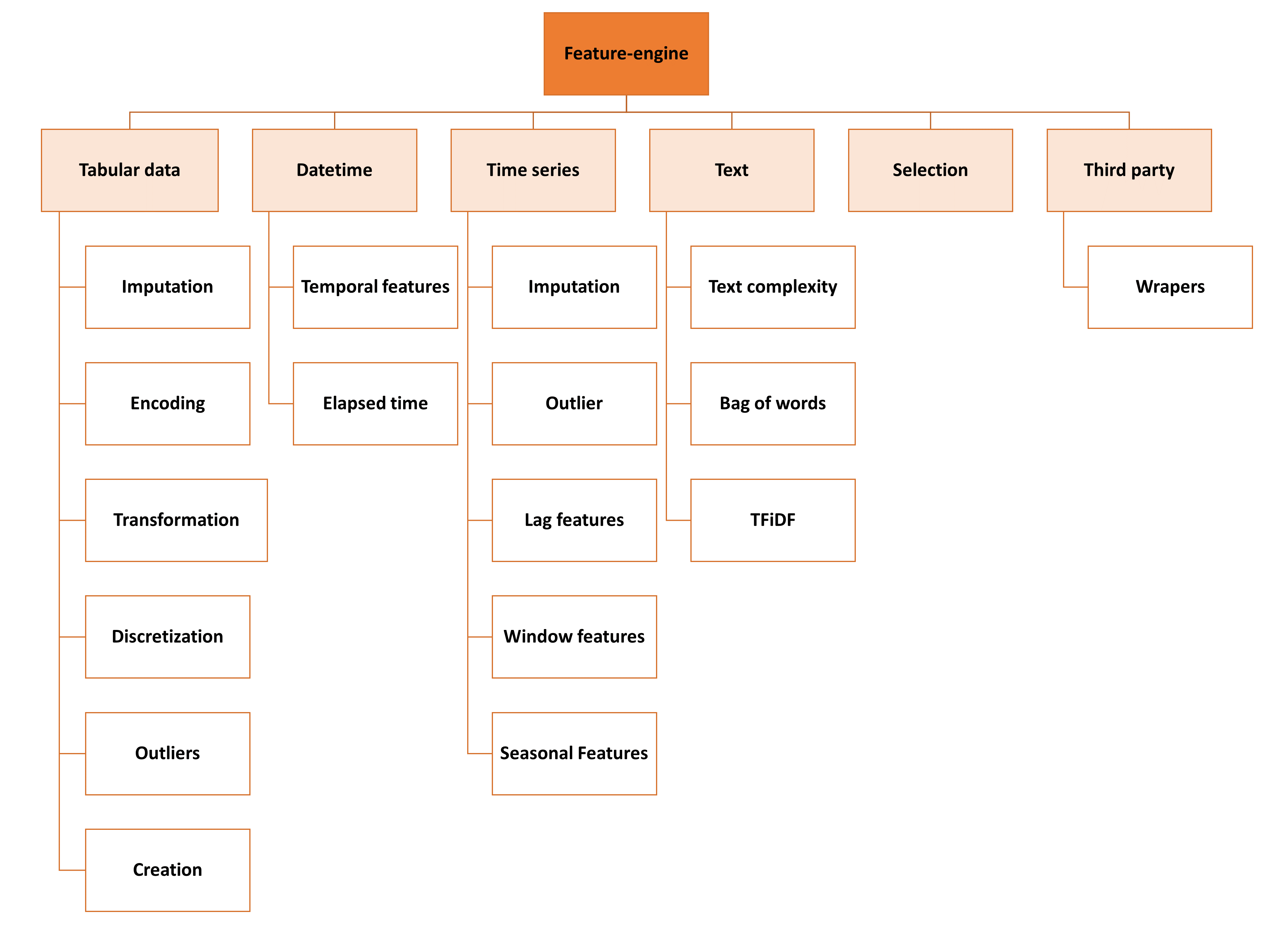
功能引擎结构#
当前功能#
表格数据的大部分功能已经包含在包中。我们根据用户反馈和建议,以及我们在这个领域的研究,扩展和更新了这一部分库。灰色部分是尚未包含在包中的转换器:
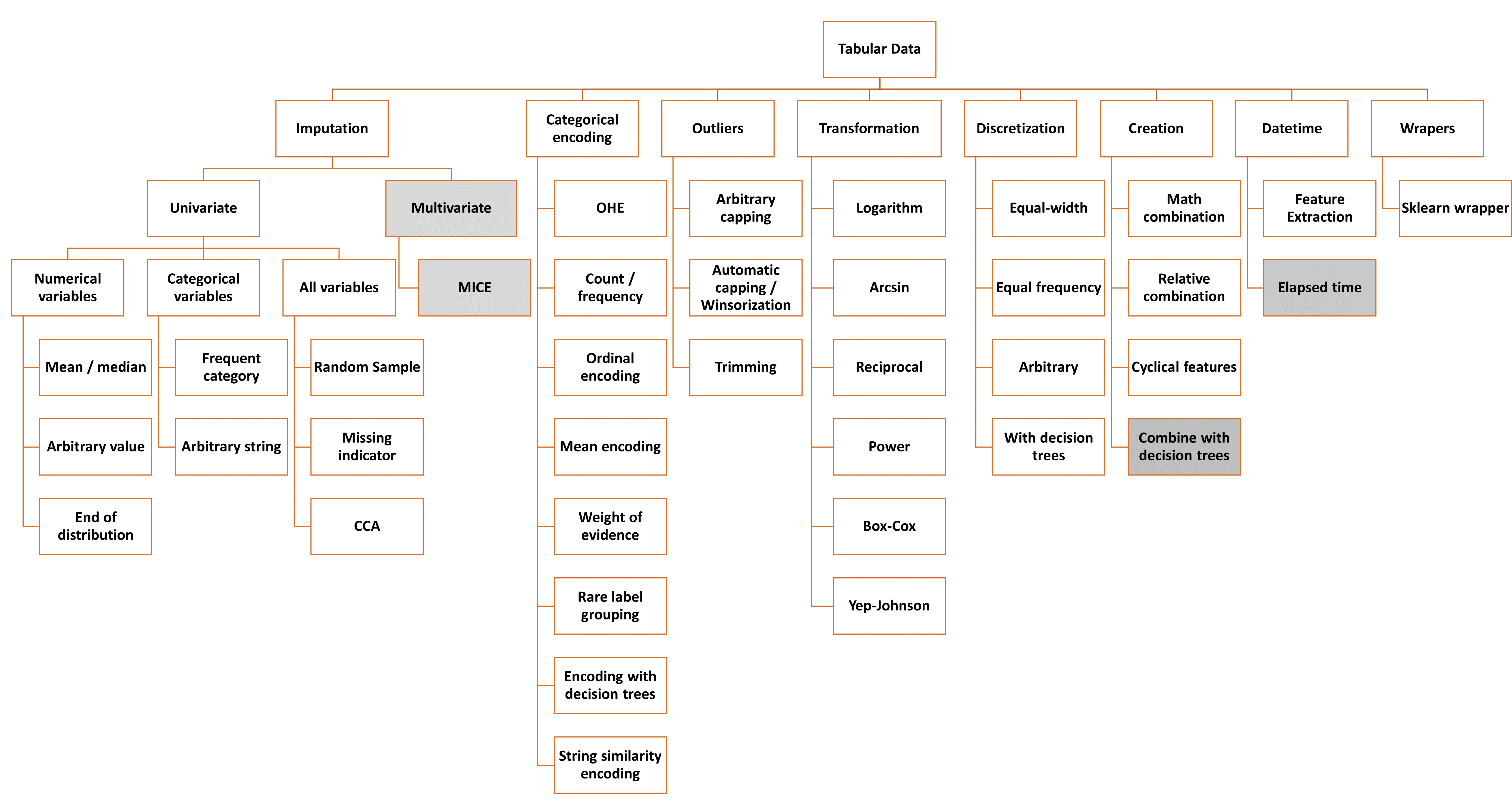
表格数据的转换器#
Feature-engine 目前支持的转换返回的特征易于解释,转换的效果清晰易懂。Feature-engine 的最初目的是提供适合在实际环境中创建模型并返回可理解变量的技术。
尽管如此,越来越多的用户正在请求功能,以组合或转换变量,从而返回非人类可读的特征,以试图提高模型性能,并在数据科学竞赛中获得优势。我们目前正在考虑将此功能纳入包中。