GPUTree 解释器
本笔记本演示了如何在某些简单数据集上使用 GPUTree 解释器。与 Tree 解释器类似,GPUTree 解释器专门为基于树的机器学习模型设计,但它旨在使用 NVIDIA GPU 加速计算。
请注意,要使用 GPUTree 解释器,您需要拥有 NVIDIA GPU,并且 SHAP 需要编译以支持您系统上的当前 GPU 库。在最近的 Ubuntu 服务器上,实现这一点的步骤将是:
通过从终端运行
nvcc命令(CUDA 编译器)来检查是否已安装 NVIDIA CUDA 工具包。如果找不到此命令,则需要使用类似sudo apt install nvidia-cuda-toolkit的方式进行安装。安装 NVIDIA CUDA Toolkit 后,您需要设置 CUDA_PATH 环境变量。如果
which nvcc输出/usr/bin/nvcc,那么您可以运行export CUDA_PATH=/usr。通过使用
git clone https://github.com/shap/shap.git克隆 shap 仓库,然后运行python setup.py install --user来构建支持 CUDA 的 SHAP。
如果在执行上述指令时遇到问题,请确保在开始新安装之前,通过确保 import shap 失败来检查是否仍有旧版本的 SHAP。
下面我们演示如何在一个简单的成人收入分类数据集和模型上使用 GPUTree 解释器。
[1]:
import xgboost
import shap
# get a dataset on income prediction
X, y = shap.datasets.adult()
# train an XGBoost model (but any other model type would also work)
model = xgboost.XGBClassifier()
model.fit(X, y)
[1]:
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
带有独立(Shapley 值)掩码的表格数据
[2]:
# build a Permutation explainer and explain the model predictions on the given dataset
explainer = shap.explainers.GPUTree(model, X)
shap_values = explainer(X)
# get just the explanations for the positive class
shap_values = shap_values
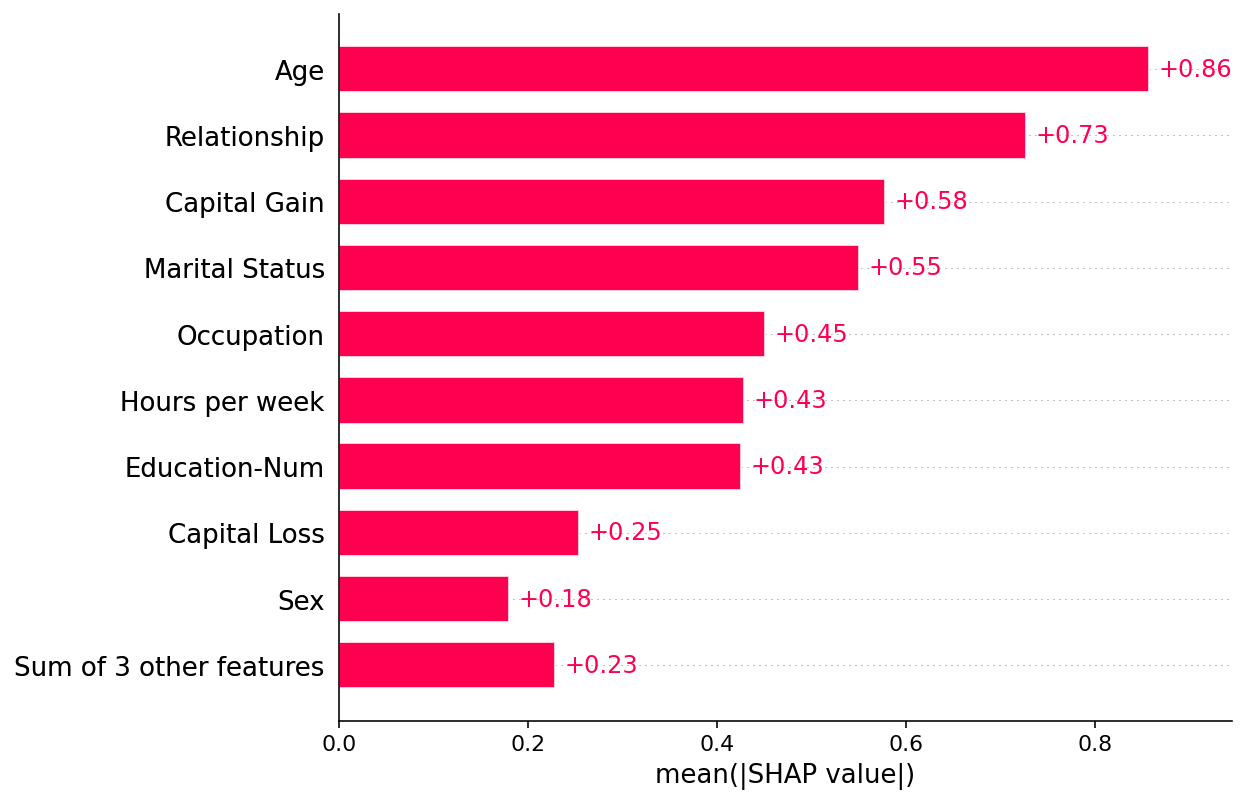
绘制全球概览
[3]:
shap.plots.bar(shap_values)
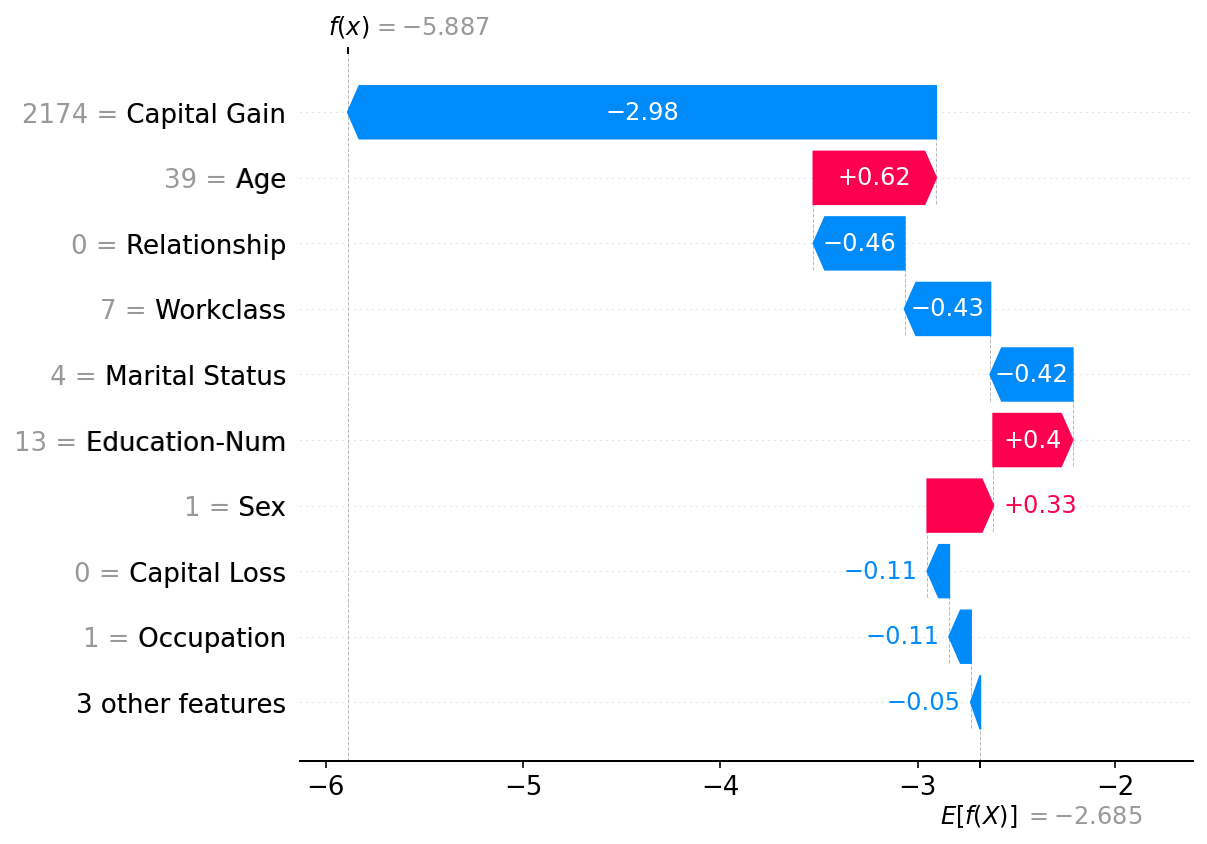
绘制单个实例
[4]:
shap.plots.waterfall(shap_values[0])
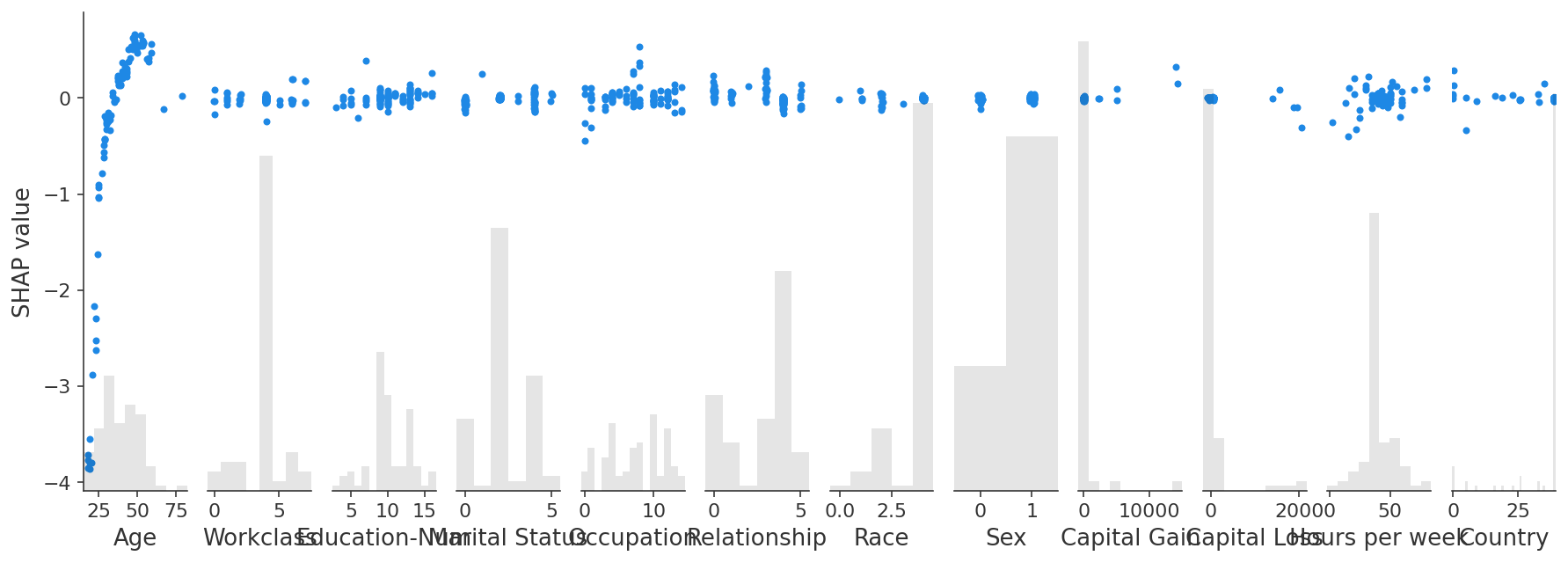
交互值
GPUTree 支持 Shapley Taylor 交互值(这是对 Tree explainer 原有所提供的改进)。
[5]:
explainer2 = shap.explainers.GPUTree(model, feature_perturbation="tree_path_dependent")
interaction_shap_values = explainer2(X[:100], interactions=True)
[6]:
shap.plots.scatter(interaction_shap_values[:, :, 0])
有更多有用示例的想法吗?我们鼓励提交增加此文档笔记本的拉取请求!