连接到数据库
Superset 不随附数据库连接功能。将 Superset 连接到数据库的主要步骤是 在您的环境中安装适当的数据库驱动程序。
您需要为要使用的元数据数据库安装所需的软件包,以及通过 Superset 访问数据库所需的软件包。有关设置 Superset 元数据数据库的信息,请参阅安装文档(Docker Compose、Kubernetes)。
本文档尝试保持对常用数据库引擎的不同驱动程序的指针。
安装数据库驱动程序
Superset 需要为每个要连接的数据库引擎安装 Python DB-API 数据库驱动程序 和 SQLAlchemy 方言。
您可以阅读此处了解如何将新的数据库驱动程序安装到您的 Superset 配置中。
支持的数据库及其依赖项
以下是一些推荐的软件包。请参阅 pyproject.toml 以获取与 Superset 兼容的版本。
数据库 | PyPI 包 | 连接字符串 |
|---|---|---|
| AWS Athena | pip install pyathena[pandas] , pip install PyAthenaJDBC | awsathena+rest://{access_key_id}:{access_key}@athena.{region}.amazonaws.com/{schema}?s3_staging_dir={s3_staging_dir}&... |
| AWS DynamoDB | pip install pydynamodb | dynamodb://{access_key_id}:{secret_access_key}@dynamodb.{region_name}.amazonaws.com?connector=superset |
| AWS Redshift | pip install sqlalchemy-redshift | redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name> |
| Apache Doris | pip install pydoris | doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database> |
| Apache Drill | pip install sqlalchemy-drill | drill+sadrill:// For JDBC drill+jdbc:// |
| Apache Druid | pip install pydruid | druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql |
| Apache Hive | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Apache Impala | pip install impyla | impala://{hostname}:{port}/{database} |
| Apache Kylin | pip install kylinpy | kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2> |
| Apache Pinot | pip install pinotdb | pinot://BROKER:5436/query?server=http://CONTROLLER:5983/ |
| Apache Solr | pip install sqlalchemy-solr | solr://{username}:{password}@{hostname}:{port}/{server_path}/{collection} |
| Apache Spark SQL | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Ascend.io | pip install impyla | ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true |
| Azure MS SQL | pip install pymssql | mssql+pymssql://UserName@presetSQL:TestPassword@presetSQL.database.windows.net:1433/TestSchema |
| ClickHouse | pip install clickhouse-connect | clickhousedb://{username}:{password}@{hostname}:{port}/{database} |
| CockroachDB | pip install cockroachdb | cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable |
| Couchbase | pip install couchbase-sqlalchemy | couchbase://{username}:{password}@{hostname}:{port}?truststorepath={ssl certificate path} |
| Dremio | pip install sqlalchemy_dremio | dremio+flight://{username}:{password}@{host}:32010, 常用选项: ?UseEncryption=true/false. 对于旧版 ODBC: dremio+pyodbc://{username}:{password}@{host}:31010 |
| Elasticsearch | pip install elasticsearch-dbapi | elasticsearch+http://{user}:{password}@{host}:9200/ |
| Exasol | pip install sqlalchemy-exasol | exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC |
| Google BigQuery | pip install sqlalchemy-bigquery | bigquery://{project_id} |
| Google Sheets | pip install shillelagh[gsheetsapi] | gsheets:// |
| Firebolt | pip install firebolt-sqlalchemy | firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name} |
| Hologres | pip install psycopg2 | postgresql+psycopg2://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| IBM Db2 | pip install ibm_db_sa | db2+ibm_db:// |
| IBM Netezza Performance Server | pip install nzalchemy | netezza+nzpy://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| MySQL | pip install mysqlclient | mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| OceanBase | pip install oceanbase_py | oceanbase://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Oracle | pip install cx_Oracle | oracle:// |
| PostgreSQL | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Presto | pip install pyhive | presto:// |
| Rockset | pip install rockset-sqlalchemy | rockset://<api_key>:@<api_server> |
| SAP Hana | pip install hdbcli sqlalchemy-hana or pip install apache-superset[hana] | hana://{username}:{password}@{host}:{port} |
| StarRocks | pip install starrocks | starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database> |
| Snowflake | pip install snowflake-sqlalchemy | snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse} |
| SQLite | 无需额外库 | sqlite://path/to/file.db?check_same_thread=false |
| SQL Server | pip install pymssql | mssql+pymssql:// |
| Teradata | pip install teradatasqlalchemy | teradatasql://{user}:{password}@{host} |
| TimescaleDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>:<Port>/<Database Name> |
| Trino | pip install trino | trino://{username}:{password}@{hostname}:{port}/{catalog} |
| Vertica | pip install sqlalchemy-vertica-python | vertica+vertica_python://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| YugabyteDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
请注意,许多其他数据库也受支持,主要标准是存在一个功能性的 SQLAlchemy 方言和 Python 驱动程序。搜索关键词 "sqlalchemy + (数据库名称)" 应该可以帮助您找到正确的位置。
如果您的数据库或数据引擎不在列表中但存在 SQL 接口,请在 Superset GitHub 仓库 上提交问题,以便我们着手记录和支持它。
如果您想为 Superset 集成构建数据库连接器,请阅读以下教程。
在 Docker 镜像中安装驱动程序
Superset 需要为每种您想要连接的额外数据库类型安装一个 Python 数据库驱动程序。
�在这个示例中,我们将介绍如何安装 MySQL 连接器库。连接器库的安装过程对于所有额外的库都是相同的。
1. 确定您需要的驱动程序
查阅数据库驱动程序列表并找到连接到您的数据库所需的 PyPI 包。在这个示例中,我们连接到 MySQL 数据库,因此我们需要 mysqlclient 连接器库。
2. 在容器中安装驱动程序
我们需要将 mysqlclient 库安装到 Superset Docker 容器中(无论它是否安装在主机机器上)。我们可以使用 docker exec -it <container_name> bash 进入正在运行的容器并在那里运行 pip install mysqlclient,但这不会永久保存。
为了解决这个问题,Superset 的 docker compose 部署使用了一个 requirements-local.txt 文件的约定。此文件中列出的所有包将在运行时从 PyPI 安装到容器中。出于本地开发的目的,此文件将被 Git 忽略。
在包含 docker-compose.yml 或 docker-compose-non-dev.yml 文件的目录中,创建一个名为 docker 的子目录,并在其中创建文件 requirements-local.txt。
# 从仓库根目录运行:
touch ./docker/requirements-local.txt
添加在上一步中确定的驱动程序。您可以使用文本编辑器或通过命令行执行此操作,例如:
echo "mysqlclient" >> ./docker/requirements-local.txt
如果您正在运行一个标准的(非定制的)Superset 镜像,您已完成。使用 docker compose -f docker-compose-non-dev.yml up 启动 Superset,驱动程序应该存在。
您可以通过使用 docker exec -it <container_name> bash 进入正在运行的容器并运行 pip freeze 来检查其存在。PyPI 包应出现在打印的列表中。
如果您正在运行一个定制的 Docker 镜像,请使用新的驱动程序重新构建您的本地镜像:
docker compose build --force-rm
在 Docker 镜像重新构建完成后,通过运行 docker compose up 重新启动 Superset。
3. 连接到 MySQL
现在您已经在容器中安装了 MySQL 驱动程序,您应该能够通过 Superset 的 Web UI 连接到您的数据库。
作为管理员用户,转到设置 -> 数据:数据库连接并点击 +DATABASE 按钮。然后,按照使用数据库连接 UI 页面中的步骤操作。
查阅 Superset 文档中特定数据库类型的页面,以确定连接字符串和您需要输入的任何其他参数。例如,在MySQL 页面上,我们看到连接到本地 MySQL 数据库的连接字符串在 Linux 或 Mac 上的设置有所不同。
点击“测试连接”按钮,应该会弹出一条消息,显示“连接看起来不错!”。
4. 故障排除
如果测试失败,请查看您的 Docker 日志以获取错误消息。Superset 使用 SQLAlchemy 连接到数据库;为了排除数据库连接字符串的故障,您可能需要查阅相关文档或社区资源。 在Superset应用程序容器或主机环境中启动Python,并尝试直接连接到所需的数据库并获取数据。这样可以排除Superset在隔离问题中的作用。
对Superset需要连接的每种数据库重复此过程。
特定数据库的说明
Ascend.io
推荐的连接Ascend.io的库是impyla。
预期的连接字符串格式如下:
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true
Apache Doris
通过SQLAlchemy连接Apache Doris的推荐方式是使用sqlalchemy-doris库。
您需要以下设置值来形成连接字符串:
- 用户:用户名
- 密码:密码
- 主机:Doris FE主机
- 端口:Doris FE端口
- 目录:目录名称
- 数据库:数据库名��称
连接字符串如下所示:
doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
AWS Athena
PyAthenaJDBC
PyAthenaJDBC 是一个符合Python DB 2.0规范的包装器,用于Amazon Athena JDBC驱动程序。
Amazon Athena的连接字符串如下:
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
请注意,在形成连接字符串时需要转义和编码,如下所示:
s3://... -> s3%3A//...
PyAthena
您也可以使用PyAthena库(无需Java),连接字符串如下:
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
PyAthena库还允许假设特定的IAM角色,您可以在Superset的Athena数据库连接UI中的ADVANCED --> Other --> ENGINE PARAMETERS下添加以下参数来定义:
{
"connect_args": {
"role_arn": "<role arn>"
}
}
AWS DynamoDB
PyDynamoDB
PyDynamoDB 是一个适用于Amazon DynamoDB的Python DB API 2.0(PEP 249)客户端。
Amazon DynamoDB的连接字符串如下:
dynamodb://{aws_access_key_id}:{aws_secret_access_key}@dynamodb.{region_name}.amazonaws.com:443?connector=superset
要获取更多文档,请访问:PyDynamoDB WIKI。
AWS Redshift
通过SQLAlchemy连接Redshift的推荐方式是使用sqlalchemy-redshift库。
此方言需要redshift_connector或psycopg2才能正常工作。
您需要设置以下值来形成连接字符串:
- 用户名:用户名
- 密码:数据库密码
- 数据库主机:AWS端点
- 数据库名称:数据库名称
- 端口:默认5439
psycopg2
SQLALCHEMY URI如下所示:
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
redshift_connector
SQLALCHEMY URI如下所示:
redshift+redshift_connector://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
使用基于IAM的凭证与Redshift集群:
Amazon Redshift集群还支持生成基于IAM的临时数据库用户凭证。
��您的Superset应用程序的IAM角色应有权限调用redshift:GetClusterCredentials操作。
您必须在Superset的Redshift数据库连接UI中的ADVANCED --> Others --> ENGINE PARAMETERS下定义以下参数。
{"connect_args":{"iam":true,"database":"<database>","cluster_identifier":"<cluster_identifier>","db_user":"<db_user>"}}
SQLALCHEMY URI应设置为redshift+redshift_connector://
使用基于IAM的凭证与无服务器Redshift:
无服务器Redshift支持使用IAM角色进行连接。
您的Superset应用程序的IAM角色应在无服务器Redshift工作组上具有redshift-serverless:GetCredentials和redshift-serverless:GetWorkgroup权限。
您必须在Superset的Redshift数据库连接UI中的ADVANCED --> Others --> ENGINE PARAMETERS下定义以下参数。
{"connect_args":{"iam":true,"is_serverless":true,"serverless_acct_id":"<aws账户编号>","serverless_work_group":"<redshift工作组>","database":"<数据库>","user":"IAMR:<superset iam角色名称>"}}
ClickHouse
要使用 ClickHouse 与 Superset,您需要安装 clickhouse-connect Python 库:
如果使用 Docker Compose 运行 Superset,请将以下内容添加到您的 ./docker/requirements-local.txt 文件中:
clickhouse-connect>=0.6.8
推荐的 ClickHouse 连接器库是 clickhouse-connect。
预期的连接字符串格式如下:
clickhousedb://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
以下是一个具体的真实连接字符串示例:
clickhousedb://demo:demo@github.demo.trial.altinity.cloud/default?secure=true
如果您在本地计算机上使用 Clickhouse,可以使用不带密码的默认用户(且不加密连接)的 http 协议 URL:
clickhousedb://localhost/default
/Library/simba/spark/lib/libsparkodbc_sbu.dylib(Mac OS)/opt/simba/spark/lib/64/libsparkodbc_sb64.so(Linux)
要连接到SQL端点,您需要使用端点的HTTP路径:
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}
Dremio
推荐的Dremio连接器库是sqlalchemy_dremio。
ODBC的预期连接字符串格式如下(默认端口为31010):
dremio+pyodbc://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1
Arrow Flight的预期连接字符串格式如下(适用于Dremio 4.9.1+,默认端口为32010):
dremio+flight://{username}:{password}@{host}:{port}/dremio
Dremio的这篇博客文章提供了一些额外的有用说明,帮助您将Superset连接到Dremio。
Apache Drill
SQLAlchemy
连接到Apache Drill的推荐方式是通过SQLAlchemy。您可以使用sqlalchemy-drill包。
完成后,您可以通过REST接口或JDBC两种方式连接到Drill。如果通过JDBC连接,您必须安装Drill JDBC驱动程序。
Drill的基本连接字符串如下所示:
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
要连接到在本地机器上以嵌入模式运行的Drill,可以使用以下连接字符串:
drill+sadrill://localhost:8047/dfs?use_ssl=False
JDBC
通过JDBC连接到Drill更为复杂,我们建议您参考此教程。
连接字符串如下所示:
drill+jdbc://<username>:<password>@<host>:<port>
ODBC
我们建议您阅读Apache Drill文档并查看GitHub README,以了解如何通过ODBC使用Drill。
Apache Druid
Superset自带了一个Druid的原生连接器(在DRUID_IS_ACTIVE标志后面),但这个连接器正在逐步被弃用,取而代之的是pydruid库中提供的SQLAlchemy/DBAPI连接器。
连接字符串如下所示:
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql
以下是此连接字符串的关键组件的分解:
User:用于连接数据库的凭证的用户名部分Password:用于连接数据库的凭证的密码部分Host:运行数据库的主机的IP地址(或URL)Port:主机上暴露的特定端口,您的数据库在此端口上运行
自定义Druid连接
在添加Druid连接时,您可以在添加数据库表单中以几种不同的方式自定义连接。
自定义证书
在配置新的Druid数据库连接时,您可以在根证书字段中添加证书:
当使用自定义证书时,pydruid将自动使用https方案。
禁用SSL验证
要禁用SSL验证,请在Extras字段中添加以下内容:
engine_params:
{"connect_args":
{"scheme": "https", "ssl_verify_cert": false}}
聚合
常见的聚合或Druid指标可以在Superset中定义和使用。第一个更简单的用例是使用数据源编辑视图中暴露的复选框矩阵(Sources -> Druid Datasources -> [您的数据源] -> Edit -> [标签] List Druid Column)。
点击GroupBy和Filterable复选框将使该列出现在Explore视图中的相关下拉菜单中。勾选Count Distinct、Min、Max或Sum将创建新的指标,这些指标将在保存数据源后出现在List Druid Metric标签页中。
通过编辑这些指标,您会注意到它们的JSON元素对应于Druid聚合定义。您可以按照Druid文档从List Druid Metric标签页手动创建自己的聚合。
后聚合
Druid支持后聚合,这在Superset中也可以使用。您只需创建一个指标,就像手动创建聚合一样,但指定postagg作为Metric Type。然后,您必须在JSON字段中提供有效的json后聚合定义(如Druid文档中所述)。
Elasticsearch
推荐的Elasticsearch连接器库是elasticsearch-dbapi。
Elasticsearch的连接字符串如下所示:
elasticsearch+http://{用户}:{密码}@{主机}:9200/
使用HTTPS
elasticsearch+https://{user}:{password}@{host}:9200/
Elasticsearch 默认限制为 10000 行,因此您可以在集群上增加此限制或在配置中设置 Superset 的行限制
ROW_LIMIT = 10000
您可以在 SQL Lab 中查询多个索引,例如
SELECT timestamp, agent FROM "logstash"
但是,要为多个索引使用可视化,您需要在集群上创建一个别名索引
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
]
}
然后使用别名名称 logstash_all 注册您的表
时区
默认情况下,Superset 使用 UTC 时区进行 elasticsearch 查询。如果您需要指定时区,请编辑您的数据库并在其他 > 引擎参数中输入您指定的时区设置:
{
"connect_args": {
"time_zone": "Asia/Shanghai"
}
}
关于时区问题的另一个需要注意的问题是,在 elasticsearch7.8 之前,如果您想将字符串转换为 DATETIME 对象,您需要使用 CAST 函数,但此函数不支持我们的 time_zone 设置。因此建议升级到 elasticsearch7.8 之后的版本。在 elasticsearch7.8 之后,您可以使用 DATETIME_PARSE 函数来解决此问题。DATETIME_PARSE 函数支持我们的 time_zone 设置,在这里您需要在其他 > 版本设置中填写您的 elasticsearch 版本号。Superset 将使用 DATETIME_PARSE 函数进行转换。
禁用 SSL 验证
要禁用 SSL 验证,请将以下内容添加到 SQLALCHEMY URI 字段:
elasticsearch+https://{user}:{password}@{host}:9200/?verify_certs=False
Exasol
Exasol 推荐的连接器库是 sqlalchemy-exasol。
Exasol 的连接字符串如下所示:
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC
Firebird
Firebird 推荐的连接器库是 sqlalchemy-firebird。Superset 已在 sqlalchemy-firebird>=0.7.0, <0.8 上进行了测试。
推荐的连接字符串是:
firebird+fdb://{username}:{password}@{host}:{port}//{path_to_db_file}
以下是 Superset 连接到本地 Firebird 数据库的连接字符串示例:
firebird+fdb://SYSDBA:masterkey@192.168.86.38:3050//Library/Frameworks/Firebird.framework/Versions/A/Resources/examples/empbuild/employee.fdb
Firebolt
Firebolt 推荐的连接器库是 firebolt-sqlalchemy。
推荐的连接字符串是:
firebolt://{username}:{password}@{database}?account_name={name}
或
firebolt://{username}:{password}@{database}/{engine_name}?account_name={name}
也可以使用服务账户进行连接:
firebolt://{client_id}:{client_secret}@{database}?account_name={name}
或
firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name}
Google BigQuery
BigQuery 推荐的连接器库是 sqlalchemy-bigquery。
安装 BigQuery 驱动程序
按照此处的步骤,了解如何在通过 docker compose 本地设置 Superset 时安装新的数据库驱动程序。
echo "sqlalchemy-bigquery" >> ./docker/requirements-local.txt
连接到 BigQuery
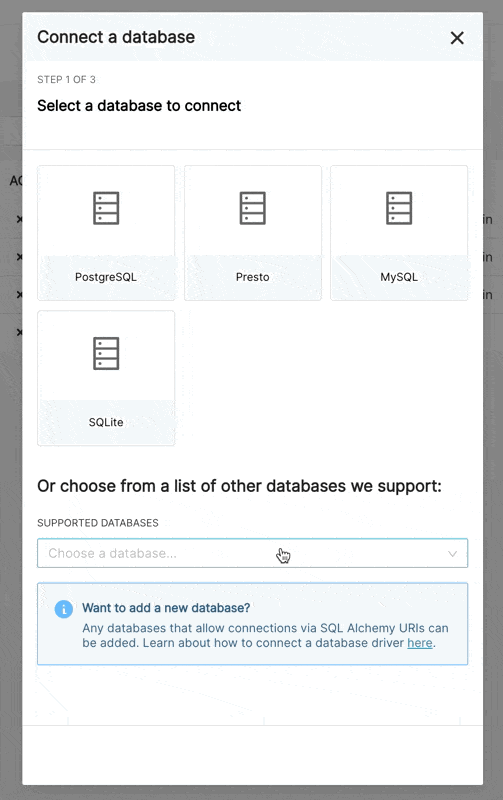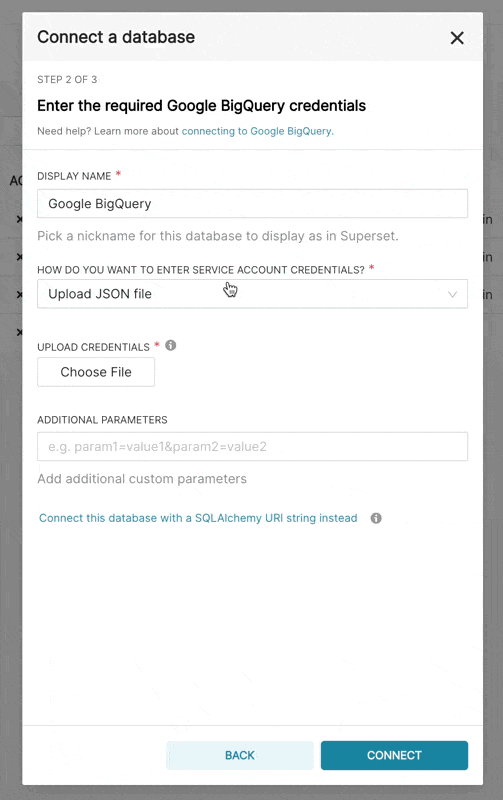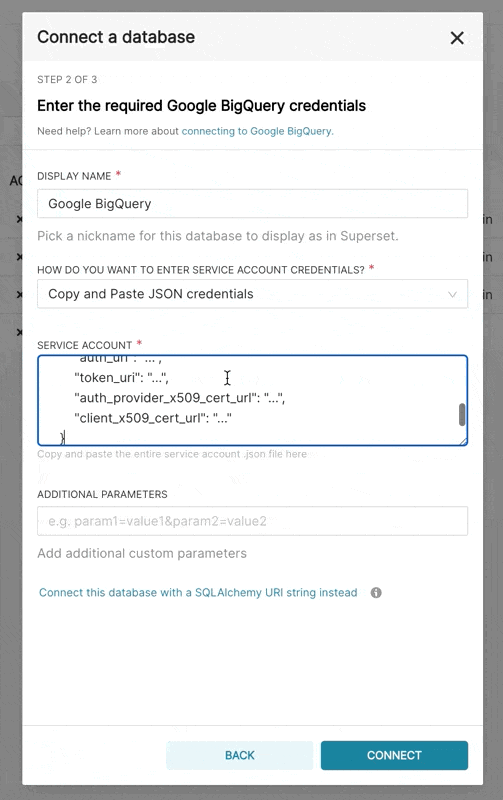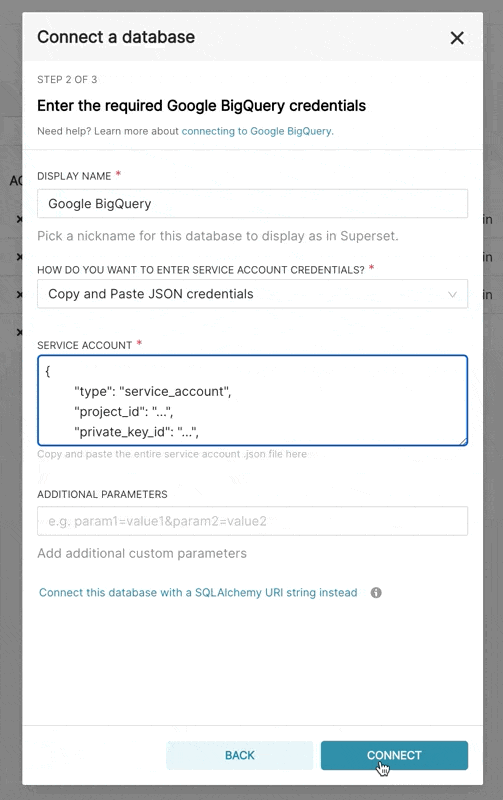
在 Superset 中添加新的 BigQuery 连接时,您需要添加 GCP 服务账户凭证文件(作为 JSON)。
- 通过 Google Cloud Platform 控制面板创建您的服务账户,为其提供对适当 BigQuery 数据集的访问权限,并下载服务账户的 JSON 配置文件。
- 在 Superset 中,您可以上传该 JSON 文件或以以下格式添加 JSON 内容(这应该是您的凭证 JSON 文件的内容):
{
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
-
此外,还可以通过 SQLAlchemy URI 进行连接
BigQuery 的连接字符串如下所示:
bigquery://{project_id}转到 高级 ��选项卡,在数据库配置表单的 安全额外 字段中添加一个 JSON 内容,格式如下:
{
"credentials_info": <credentials JSON file contents>
}
生成的文件应具有以下结构:
{
"credentials_info": {
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
}
然后,您应该能够连接到您的 BigQuery 数据集。
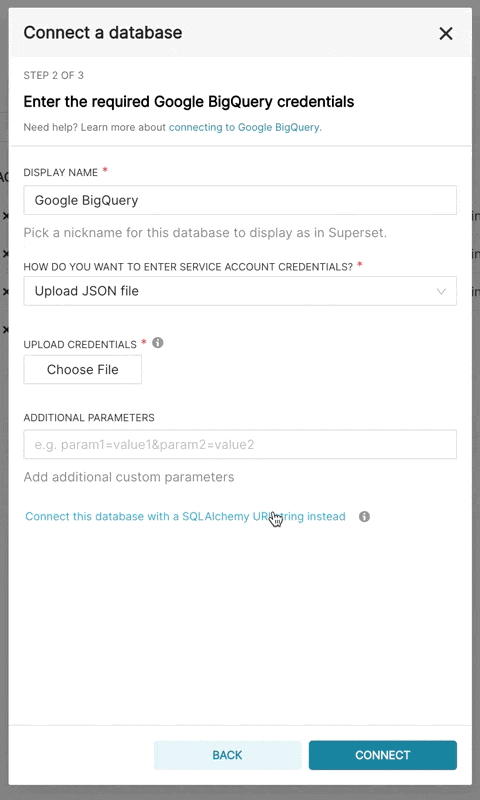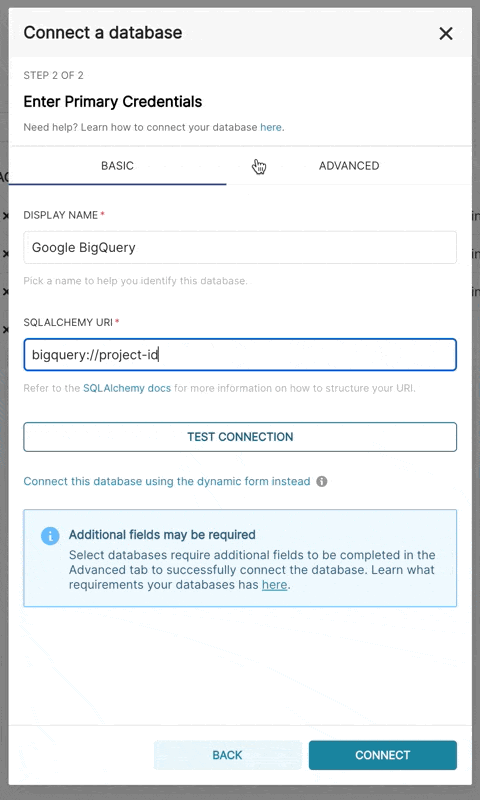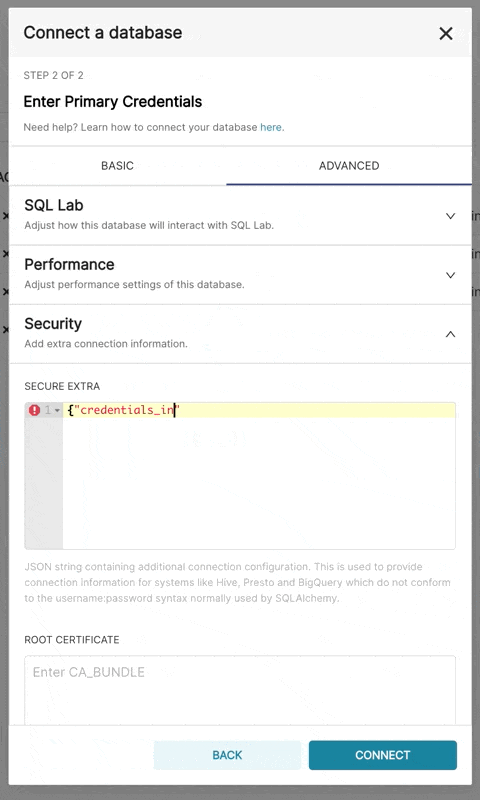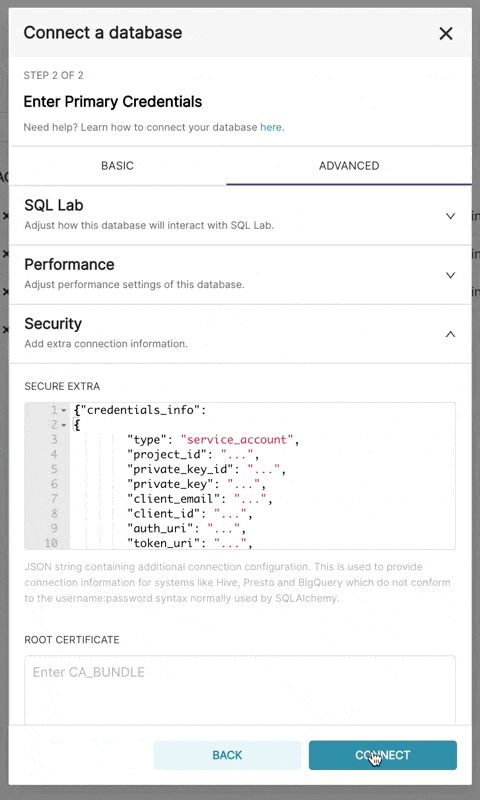
要在 Superset 中将 CSV 或 Excel 文件上传到 BigQuery,您还需要添加 pandas_gbq 库。
目前,Google BigQuery Python SDK 与 gevent 不兼容,因为 gevent 对 Python 核心库进行了一些动态的猴子补丁。因此,当您使用 gunicorn 服务器部署 Superset 时,必须使用除 gevent 以外的 worker 类型。
Google Sheets
Google Sheets 的 SQL API 非常有限。推荐用于 Google Sheets 的连接器库是 shillelagh。
将 Superset 连接到 Google Sheets 涉及几个步骤。此 教程 提供了设置此连接的最新说明。
Hana
推荐的连接器库是 sqlalchemy-hana。
连接字符串格式如下:
hana://{username}:{password}@{host}:{port}
Apache Hive
推荐使用 pyhive 库通过 SQLAlchemy 连接到 Hive。
预期的连接字符串格式如下:
hive://hive@{hostname}:{port}/{database}
Hologres
Hologres 是阿里云开发的一种实时交互式分析服务。它完全兼容 PostgreSQL 11,并与大数据生态系统无缝集成。
Hologres 示例连接参数:
- 用户名:您的阿里云账号的 AccessKey ID。
- 密码:您的阿里云账号的 AccessKey 密钥。
- 数据库主机:Hologres 实例的公网端点。
- 数据库名称:Hologres 数据库的名称。
- 端口:Hologres 实例的端口号。
连接字符串如下所示:
postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}
IBM DB2
IBM_DB_SA 库提供了 Python / SQLAlchemy 接口到 IBM 数据服务器。
推荐的连接字符串如下:
db2+ibm_db://{username}:{passport}@{hostname}:{port}/{database}
SQLAlchemy 中实现了两个 DB2 方言版本。如果您连接的 DB2 版本不支持 LIMIT [n] 语法,推荐的连接字符串以便能够使用 SQL Lab 是:
ibm_db_sa://{username}:{passport}@{hostname}:{port}/{database}
Apache Impala
推荐用于 Apache Impala 的连接器库是 impyla。
预期的连接字符串格式如下:
impala://{hostname}:{port}/{database}
Kusto
推荐用于 Kusto 的连接器库是 sqlalchemy-kusto>=2.0.0。
Kusto(SQL 方言)的连接字符串如下所示:
kustosql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
Kusto(KQL 方言)的连接字符串如下所示:
kustokql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
确保用户有权访问和使用所有必需的数据库/表/视图。
Apache Kylin
推荐用于 Apache Kylin 的连接器库是 kylinpy。
预期的连接字符串格式如下:
kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>
MySQL
推荐用于 MySQL 的连接器库是 mysqlclient。
连接字符串如下:
mysql://{username}:{password}@{host}/{database}
主机:
- 本地主机:
localhost或127.0.0.1 - 在 Linux 上运行的 Docker:
172.18.0.1 - 本地部署:IP 地址或主机名
- 在 OSX 上运行的 Docker:
docker.for.mac.host.internal端口:默认3306mysqlclient的一个问题是,由于客户端中未包含该插件,它将无法使用caching_sha2_password进行身份验证连接到较新的 MySQL 数据库。在这种情况下,您应该改用 mysql-connector-python:
mysql+mysqlconnector://{username}:{password}@{host}/{database}
IBM Netezza Performance Server
nzalchemy 库提供了 Python / SQLAlchemy 接口到 IBM Netezza Performance Server(又名 Netezza)。
推荐的连接字符串如下:
netezza+nzpy://{username}:{password}@{hostname}:{port}/{database}
OceanBase
推荐的通过 SQLAlchemy 连接到 OceanBase 的方式是使用 sqlalchemy-oceanbase 库。
OceanBase 的连接字符串如下所示:
oceanbase://<User>:<Password>@<Host>:<Port>/<Database>
Ocient DB
推荐的 Ocient 连接器库是 sqlalchemy-ocient。
安装 Ocient 驱动
pip install sqlalchemy-ocient
连接到 Ocient
Ocient DSN 的格式为:
ocient://user:password@[host][:port][/database][?param1=value1&...]
Oracle
推荐的连接器库是 cx_Oracle。
连接字符串格式如下:
oracle://<username>:<password>@<hostname>:<port>
从API参考中找到您的API服务器。省略URL中的https://部分。
要针对特定的虚拟实例,请使用以下URI格式:
rockset://{api key}:@{api server}/{VI ID}
如需更完整的说明,我们推荐Rockset文档。
Snowflake
安装Snowflake驱动程序
按照此处的步骤,了解如何在通过docker compose本地设置Superset时安装新的数据库驱动程序。
echo "snowflake-sqlalchemy" >> ./docker/requirements-local.txt
推荐的Snowflake连接器库是snowflake-sqlalchemy。
Snowflake的连接字符串如下所示:
snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}
连接字符串中不需要模式,因为它是在每个表/查询中定义的。如果为用户定义了默认值,则可以省略角色和仓库,即:
snowflake://{user}:{password}@{account}.{region}/{database}
确保用户有权访问并使用所有必需的数据库/模式/表/视图/仓库,因为Snowflake SQLAlchemy引擎默认不会在引擎创建期间测试用户/角色权限。然而,在创建或编辑数据库对话框中按下“测试连接”按钮时,用户/角色凭据会通过在引擎创建期间传递“validate_default_parameters”: True到connect()方法来验证。如果用户/角色无权访问数据库,错误会记录在Superset日志中。
如果您想使用密钥对认证连接Snowflake,请确保您拥有密钥对,并且公钥已在Snowflake中注册。要使用密钥对认证连接Snowflake,您需要在“SECURE EXTRA”字段中添加以下参数。
请注意,您需要将多行私钥内容合并为一行,并在每行之间插入\n
{
"auth_method": "keypair",
"auth_params": {
"privatekey_body": "-----BEGIN ENCRYPTED PRIVATE KEY-----\n...\n...\n-----END ENCRYPTED PRIVATE KEY-----",
"privatekey_pass":"Your Private Key Password"
}
}
如果您的私钥存储在服务器上,您可以将参数中的“privatekey_body”替换为“privatekey_path”。
{
"auth_method": "keypair",
"auth_params": {
"privatekey_path":"Your Private Key Path",
"privatekey_pass":"Your Private Key Password"
}
}
Apache Solr
sqlalchemy-solr库提供了Python/SQLAlchemy接口到Apache Solr。
Solr的连接字符串如下所示:
solr://{username}:{password}@{host}:{port}/{server_path}/{collection}[/?use_ssl=true|false]
Apache Spark SQL
推荐的Apache Spark SQL连接器库是pyhive。
预期的连接字符串格式如下:
hive://hive@{hostname}:{port}/{database}
SQL Server
推荐的SQL Server连接器库是pymssql。
SQL Server的连接字符串如下所示:
mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name>/?Encrypt=yes
也�可以使用pyodbc连接,参数为odbc_connect。
SQL Server的连接字符串如下所示:
mssql+pyodbc:///?odbc_connect=Driver%3D%7BODBC+Driver+17+for+SQL+Server%7D%3BServer%3Dtcp%3A%3Cmy_server%3E%2C1433%3BDatabase%3Dmy_database%3BUid%3Dmy_user_name%3BPwd%3Dmy_password%3BEncrypt%3Dyes%3BConnection+Timeout%3D30
StarRocks
sqlalchemy-starrocks库是推荐的通过SQLAlchemy连接到StarRocks的方式。
您需要以下设置值来形成连接字符串:
- User: 用户名
- Password: 数据库密码
- Host: StarRocks FE主机
- Catalog: 目录名称
- Database: 数据库名称
- Port: StarRocks FE端口
连接字符串如下所示:
starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
Teradata
推荐的连接器库是teradatasqlalchemy。
Teradata的连接字符串如下所示:
teradatasql://{user}:{password}@{host}
ODBC驱动程序
还有一个较旧的连接器名为sqlalchemy-teradata。 需要安装ODBC驱动程序。Teradata ODBC驱动程序可在此处获取:https://downloads.teradata.com/download/connectivity/odbc-driver/linux
以下是所需的环境变量:
export ODBCINI=/.../teradata/client/ODBC_64/odbc.ini
export ODBCINST=/.../teradata/client/ODBC_64/odbcinst.ini
我们推荐使用第一个库,因为它不需要ODBC驱动程序,并且更新更为频繁。
TimescaleDB
TimescaleDB 是一个开源的关系型数据库,专为时间序列和分析而设计,用于构建强大的数据密集型应用程序。TimescaleDB是PostgreSQL的一个扩展,您可以使用标准的PostgreSQL连接库,psycopg2,来连接到数据库。
如果您使用的是docker compose,psycopg2会随Superset一起提供。
TimescaleDB示例连接参数:
- 用户名: 用户
- 密码: 密码
- 数据库主机:
- 对于本地主机: localhost 或 127.0.0.1
- 对于本地部署: IP地址或主机名
- 对于Timescale Cloud服务: 主机名
- 对于Managed Service for TimescaleDB服务: 主机名
- 数据库名称: 数据库名称
- 端口: 默认5432或服务的端口号
连接字符串如下所示:
postgresql://{username}:{password}@{host}:{port}/{database name}
您可以通过在末尾添加?sslmode=require来要求SSL(例如,如果您使用Timescale Cloud):
postgresql://{username}:{password}@{host}:{port}/{database name}?sslmode=require
Trino
支持的Trino版本为352及以上
连接字符串
连接字符串格式如下:
trino://{username}:{password}@{hostname}:{port}/{catalog}
如果您在本地机器上使用docker运行Trino,请使用以下连接URL
trino://trino@host.docker.internal:8080
认证方式
1. 基本认证
您可以在连接字符串中或在高级/安全中的安全额外字段中提供用户名/密码
-
在连接字符串中
trino://{username}:{password}@{hostname}:{port}/{catalog} -
在
安全额外字段中{
"auth_method": "basic",
"auth_params": {
"username": "<username>",
"password": "<password>"
}
}
注意:如果两者都提供,安全额外字段始终优先级更高。
2. Kerberos认证
在安全额外字段中,按以下示例配置:
{
"auth_method": "kerberos",
"auth_params": {
"service_name": "superset",
"config": "/path/to/krb5.config",
...
}
}
auth_params中的所有字段都直接传递给KerberosAuthentication类。
注意:Kerberos认证需要本地安装trino-python-client,并带有all或kerberos可选功能,即分别�安装trino[all]或trino[kerberos]。
3. 证书认证
在安全额外字段中,按以下示例配置:
{
"auth_method": "certificate",
"auth_params": {
"cert": "/path/to/cert.pem",
"key": "/path/to/key.pem"
}
}
auth_params中的所有字段都直接传递给CertificateAuthentication类。
4. JWT认证
在安全额外字段中配置auth_method并提供token
{
"auth_method": "jwt",
"auth_params": {
"token": "<your-jwt-token>"
}
}
5. 自定义认证
要使用自定义认证,首先需要在Superset配置文件中将它添加到ALLOWED_EXTRA_AUTHENTICATIONS允许列表中:
from your.module import AuthClass
from another.extra import auth_method
ALLOWED_EXTRA_AUTHENTICATIONS: Dict[str, Dict[str, Callable[..., Any]]] = {
"trino": {
"custom_auth": AuthClass,
"another_auth_method": auth_method,
},
}
然后在安全额外字段中:
{
"auth_method": "custom_auth",
"auth_params": {
...
}
}
您还可以通过提供对您的trino.auth.Authentication类或工厂函数(返回一个Authentication实例)的引用来使用自定义认证。
auth_params中的所有字段都直接传递给您的类/函数。
参考:
Vertica
推荐的连接库是 sqlalchemy-vertica-python。 Vertica 连接参数如下:
- 用户名: UserName
- 密码: DBPassword
- 数据库主机:
- 本地主机: localhost 或 127.0.0.1
- 本地部署: IP 地址或主机名
- 云端: IP 地址或主机名
- 数据库名称: 数据库名称
- 端口: 默认 5433
连接字符串格式如下:
vertica+vertica_python://{username}:{password}@{host}/{database}
其他参数:
- 负载均衡器 - 备用主机
YugabyteDB
YugabyteDB 是一个基于 PostgreSQL 构建的分布式 SQL 数据库。
请注意,如果您使用的是 docker compose,Postgres 连接器库 psycopg2 会随 Superset 一起提供。
连接字符串如下所示:
postgresql://{username}:{password}@{host}:{port}/{database}
validate_parameters(cls, parameters): 此方法用于表单的onBlur验证。它应返回一个SupersetError列表,指示哪些参数缺失,哪些参数明显不正确(示例)。
对于使用标准格式 engine+driver://user:password@host:port/dbname 的数据库(如 MySQL 和 Postgres),您只需将 BasicParametersMixin 添加到数据库引擎规范中,然后定义参数 2-4(parameters_schema 已在 mixin 中存在)。
对于其他数据库,您需要自行实现这些方法。BigQuery 数据库引擎规范是一个很好的示例。
额外数据库设置
更深层次的 SQLAlchemy 集成
可以通过 SQLAlchemy 暴露的参数来调整数据库连接信息。在 数据库编辑 视图中,您可以将 额外 字段编辑为 JSON blob。
此 JSON 字符串包含额外的配置元素。engine_params 对象会被解包到 sqlalchemy.create_engine 调用中,而 metadata_params 会被解包到 sqlalchemy.MetaData 调用中。请参阅 SQLAlchemy 文档获取更多信息。
模式
像 Postgres 和 Redshift 这样的数据库使用 模式 作为逻辑实体,位于 数据库 之上。为�了让 Superset 连接到特定模式,您可以在 编辑表单 中设置 模式 参数(来源 > 表 > 编辑记录)。
SQLAlchemy 连接的外部密码存储
Superset 可以配置为使用外部存储来存储数据库密码。如果您运行的是自定义的秘密分发框架,并且不希望将秘密存储在 Superset 的元数据库中,这将非常有用。
示例:编写一个函数,该函数接受类型为 sqla.engine.url 的单个参数,并返回给定连接字符串的密码。然后在配置文件中将 SQLALCHEMY_CUSTOM_PASSWORD_STORE 设置为指向该函数。
def example_lookup_password(url):
secret = <<从外部框架获取密码>>
return 'secret'
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_lookup_password
一种常见的模式是使用环境变量来使秘密可用。SQLALCHEMY_CUSTOM_PASSWORD_STORE 也可以用于此目的。
def example_password_as_env_var(url):
# 假设 URI 看起来像
# mysql://localhost?superset_user:{SUPERSET_PASSWORD}
return url.password.format(**os.environ)
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_password_as_env_var
数据库的 SSL 访问
您可以在 编辑数据库 表单中使用 Extra 字段来配置 SSL:
{
"metadata_params": {},
"engine_params": {
"connect_args":{
"sslmode":"require",
"sslrootcert": "/path/to/my/pem"
}
}
}
杂项
跨数据库查询
Superset 提供了一个实验性功能,用于跨不同数据库进行查询。这是通过一个名为 "Superset 元数据库" 的特殊数据库完成的,该数据库使用 "superset://" SQLAlchemy URI。使用该数据库时,可以使用以下语法查询任何配置数据库中的任何表:
SELECT * FROM "数据库名称.[[目录.].模式].表名";
例如:
SELECT * FROM "examples.birth_names";
允许使用空格,但名称中�的句点必须替换为 %2E。例如:
SELECT * FROM "Superset meta database.examples%2Ebirth_names";
上面的查询返回与 SELECT * FROM "examples.birth_names" 相同的行,并且还表明元数据库可以查询任何表——甚至是它自己!
注意事项
在启用此功能之前,您应该考虑一些事项。首先,元数据库对查询的表强制执行权限,因此用户只能通过数据库访�问他们原本有权访问的表。尽管如此,元数据库是一个新的潜在攻击面,漏洞可能允许用户看到他们不应该看到的数据。
其次,存在性能方面的考虑。元数据库会将任何过滤、排序和限制推送到底层数据库,但任何聚合和连接将在运行查询的进程的内存中进行。因此,建议以异步模式运行数据库,以便查询在 Celery 工作进程中执行,而不是在 Web 工作进程中执行。此外,可以指定从底层数据库返回的行数的硬性限制。
启用元数据库
要启用 Superset 元数据库,首先需要将 ENABLE_SUPERSET_META_DB 功能标志设置为 true。然后,添加一个类型为 "Superset 元数据库" 的新数据库,并使用 SQLAlchemy URI "superset://"。
如果你在元数据库中启用了DML,用户将能够在底层数据库上运行DML查询,前提是这些数据库中也启用了DML。这允许用户运行跨数据库移动数据的查询。
其次,你可能想要更改SUPERSET_META_DB_LIMIT的值。默认值是1000,它定义了在执行任何聚合和连接之前从每个数据库中读取的记录数。如果你只有小表,也可以将此值设置为None。
此外,你可能希望限制元数据库可以访问的数据库。这可以在数据库配置中完成,在“高级” -> “其他” -> “引擎参数”下添加:
{"allowed_dbs":["Google Sheets","examples"]}