介绍Wren引擎
趋势AI代理的出现彻底改变了商业智能和数据管理的格局。在不久的将来,将部署多个AI代理来利用和解释存储在数据库和数据仓库中的大量内部知识。为了实现这一点,语义引擎至关重要。该引擎将数据模式映射到相关的业务上下文,使AI代理能够理解数据的潜在语义。通过提供对业务上下文的结构化理解,语义引擎将使AI代理能够生成针对特定业务需求的准确SQL查询,确保精确且上下文感知的数据检索。
LLMs在数据结构方面的问题?
使AI代理能够直接与数据库对话。底层技术提供了一个将自然语言转换为SQL并查询数据库的接口。
然而,从数据库中映射带有上下文的模式并不是一项简单的任务。仅仅存储模式和元数据是不够的。我们需要更深入地理解和处理数据。
缺乏语义上下文
当您直接在数据库上启用LLMs时,您可以依赖数据库中已有的DDL信息来帮助LLMs学习您的数据库结构和类型。您还可以根据提供的DDL添加标题和描述,以帮助LLMs理解每个表和列的定义。
为了实现LLMs的最佳性能和准确性,仅仅拥有DDL和模式定义是不够的。LLMs需要理解各种实体之间的关系,并理解您组织内部使用的计算公式。提供额外的信息,如计算、指标和关系(连接路径),对于帮助LLMs理解这些方面至关重要。
LLMs与语义之间缺乏接口定义
正如前一节所提到的,拥有一个语义上下文非常重要,它可以让LLMs理解计算、指标、关系等的复杂性。我们需要定义来概括我们面临的如下主题。
计算
预训练的LLMs对每个术语都有自己的议程,这并不是每家公司定义自己的KPI或公式的方式。计算是我们提供定义的地方,例如毛利率等于(收入 - 销售成本) / 收入。LLMs可能已经足够强大,能够理解常见的KPI,例如毛利率、净利润率、CLTV等。
然而,在现实世界中,列名通常很混乱,收入可能被设置为列名 rev,我们可能还会看到 rev1、pre_rev_1、rev2 等等。如果没有语义上下文,LLMs 无法理解它们的含义。
指标
"切片和切块"是一种在数据分析中使用的技术,特别是在多维数据的背景下,用于分解并从不同角度查看数据。这种方法有助于更详细地探索和分析数据。
如下面的例子:
- 销售指标:
- 总销售额: 在特定时期内产生的总收入。
- 按地区销售: 按地理区域划分的销售数据。
- 按产品销售: 按单个产品或产品类别划分的销售数据。
- 按渠道销售: 按不同销售渠道(例如,在线、零售、批发)划分的销售数据。
- 客户指标:
- 客户人口统计: 按年龄、性别、地理位置等细分客户。
- 客户细分: 根据行为、购买历史和偏好对客户进行分类。
- 客户获取: 在特定时期内获得的新客户数量。
- 客户流失率: 停止与公司业务的客户百分比。
语义关系
语义关系与主键和外键不同,尽管它们在数据库和数据管理的上下文中是相关的概念。
语义关系指的是不同数据之间的有意义连接,通常基于它们在现实世界中的关系。这些关系描述了数据元素在概念上如何相互关联,而不仅仅是主键和外键提供的结构链接;例如,Customers 和 Orders 表之间的语义关系可以描述为“一个客户可以下多个订单”。这捕捉了关系在现实世界中的意义,而不仅仅是技术上的链接。
另一方面,主键和外键用于在数据库模式级别强制执行数据完整性并建立关系。语义关系用于描述和理解数据实体在更广泛的上下文中如何相关,您还可以定义一对多、多对多、一对一关系,这些关系在主键和外键设置中不可用。
整合LLMs与异构数据源的挑战
不稳定的SQL生成性能
连接多个数据源并期望LLMs无缝处理不同的SQL方言带来了一个重大挑战:确保跨不同数据源的性能一致性。随着数据源数量的增加,这一挑战变得更加明显。一致性是建立对AI系统信任的关键。确保稳定的性能直接关系到AI解决方案的整体可用性和可靠性。
不一致的访问控制
不同的数据源通常带有自己的访问控制机制。当这些源直接连接时,维护一致的数据策略变得困难,这对于大规模数据团队协作至关重要。为了解决这个问题,一个中央治理层对于管理所有LLM用例的访问控制是必不可少的。这一层确保数据策略得到统一执行,增强了整个组织的安全性和合规性。
语义层的出现
直接连接到多个数据源在一致性和性能方面带来了重大挑战。更有效的方法是为LLM用例实现一个语义层。
什么是语义层?
语义架构背后的核心概念是本体。本体是一个领域的正式表示,包括表示实体和属性的类,以及它们与其他实体的关系。
通过为数据集领域提供一个本体,LLMs不仅能够理解如何呈现数据,还能理解数据所代表的内容。这使得系统能够处理甚至推断出数据集中未明确说明的新信息。

语义层的好处
语义层不仅仅帮助AI代理理解不同领域、实体和关系之间的语义。它还提供了一个框架,使AI代理能够:
- 使用正确的公式进行计算
- 为连接路径和指标提供上下文
- 提供一个标准化的SQL层,确保不同数据源之间的一致性。
- 在运行时应用封装的业务逻辑并管理实体之间的复杂关系。
因此,实施语义层通过弥合不同数据源和复杂业务环境之间的差距,增强了AI代理提供准确和一致见解的能力。
Wren引擎 - 用于LLMs的语义引擎
这就是我们设计Wren引擎的原因,这是一个为LLMs设计的语义引擎,旨在解决我们提出的挑战。
使用Wren引擎,我们定义了一种“建模定义语言”(MDL),为LLMs提供上下文和适当的语义元数据,引擎可以使用MDL根据不同的用户角色和语义数据建模方法重写SQL。通过该引擎,在其上构建解决方案,如访问控制、治理,这些通常位于语义层。
语义数据建模
本体论的基本概念涉及设计一个图结构的表示,用于表示元数据和数据,通常称为知识图谱。使用Wren Engine,您可以在这个基于图的架构中定义您的数据模型和指标。这使您能够指定不同模型中的列如何相关以及这些关系的含义。这种结构化的定义不仅澄清了数据关系,还增强了准确和高效重写SQL查询的能力。
语义命名和描述
在MDL中,您可以轻松地在任何模型、列、视图以及关系中定义语义命名和描述。通过语义定义,您可以帮助LLM理解数据结构的语义含义。
{
"name": "customers",
"columns": [
{
"name": "City",
"type": "VARCHAR",
"isCalculated": 0,
"notNull": 0,
"expression": "",
// semantic properties, such as description, display name, and alias, could be added here.
"properties": {
"description": "The Customer City, where the customer company is located. Also called \"customer segment\".",
"displayName": "City"
}
},
{
// semantic naming
"name": "UserId",
"type": "VARCHAR",
"isCalculated": 0,
"notNull": 0,
"expression": "Id",
"properties": {
"description": "A unique identifier for each customer in the data model.",
"displayName": "Id"
}
}
],
"refSql": "select * from main.customers",
"cached": 0,
"refreshTime": null,
// semantic properties, such as description, display name, and alias, could be added here.
"properties": {
"schema": "main",
"catalog": "memory",
"description": "A table of customers who have made purchases, including their city",
"displayName": "customers"
},
"primaryKey": "Id"
},
支持运行时SQL重写与关系和计算
使用Wren引擎,您可以使用“建模定义语言”设计语义表示,我们还在我们的AI应用程序Wren AI中围绕它构建了一个用户界面,该界面也是开源的。在Wren AI背后,不同实体之间的关系,并声明为一对多,多对一,一对一都可以被定义。

下面是一个如何定义关系的简单示例
{
"name" : "CustomerOrders",
"models" : [ "Customer", "Orders" ],
"joinType" : "ONE_TO_MANY", // it's a one-to-many architecture
"condition" : "Customer.custkey = Orders.custkey"
}
关系由以下部分组成:
name: 关系的名称。models: 与此关系关联的模型。Wren Engine 在一个关系中只关联2个模型。joinType: 关系的类型。通常,我们有以下4种模型之间的关系类型:- ONE_TO_ONE (1-1)
- ONE_TO_MANY (1-M)
- MANY_TO_ONE (M-1)
- MANY_TO_MANY (M-M)
1-1,1-M和M-1对 Wren Engine 有意义。我们稍后再讨论。
condition: 两个模型之间的连接条件。Wren Engine 在 SQL 生成过程中充当连接条件。
您还可以在模型中的计算(表达式)中添加自定义计算。
{
"name": "Customer",
"refSql": "select * from tpch.customer",
"columns": [
{
"name": "custkey",
"type": "integer",
"expression": "c_orderkey"
},
{
"name": "name",
"type": "varchar",
"expression": "c_name"
},
{
"name": "orders",
"type": "Orders",
"relationship": "CustomerOrders"
},
{
"name": "consumption",
"type": "integer",
"isCalculated": true,
"expression": "sum(orders.totalprice)" // define expression
}
],
"primaryKey": "custkey"
},
支持可重用的计算和类似函数的宏
计算
Wren Engine 提供了计算字段来在模型中定义计算。计算可以使用同一模型中定义的列或通过关系使用另一个模型中的相关列。通常,一个常见的指标与许多不同的表相关。通过计算字段,可以轻松定义一个在不同模型之间交互的常见指标。
例如,下面是一个名为 orders 的模型,包含3列。为了增强模型,我们可能希望添加一个名为 customer_last_month_orders_price 的列,以了解每个客户的增长情况。我们可以定义一个计算字段,如下所示:
"columns": [
{
"name": "orderkey",
"type": "INTEGER"
},
{
"name": "custkey",
"type": "INTEGER"
}
{
"name": "price",
"type": "INTEGER"
},
{
"name": "purchasetimestamp",
"type": "TIMESTAMP"
},
{
"name": "customer_last_month_orders_price",
"type": "INTEGER",
"isCalculated": "true",
// column
"expression": "lag(price) over (partition by custkey order by date_trunc('YEAR', purchasetimestamp), 0, 0)"
}
]
宏函数
宏是建模定义语言(MDL)的一个模板功能。它对于简化您的MDL或集中一些关键概念非常有用。宏是通过JinJava实现的,这是一个遵循Jinja规范的JVM模板引擎。使用宏,您可以定义一个模板来使用某些参数,并在任何表达式中使用它。
在以下场景中,twdToUsd 代表了整个 MDL 中的一个通用概念。相反,revenue 和 totalpriceUsd 则体现了特定于个别模型的部分概念。
"macros": [
{
"name": "twdToUsd",
"definition": "(twd: Expression) => twd / 30" // Macro definition
}
],
"models": [
{
"name": "Orders",
"columns": [
{
"name": "totalprice",
"type": "double"
}
{
"name": "totalpriceUsd",
"expression": "{{ twdToUsd('totalprice') }}" // reuse Macro function
}
]
},
{
"name": "Customer",
"columns": [
{
"name": "revenue",
"isCalculated": true,
"expression": "{{ twdToUsd('sum(orders.totalprice)') }}" // reuse Macro function
},
{
"name": "orders",
"Type": "Orders",
"relationship": "OrdersCustomer",
}
]
}
]
支持标准SQL语法
Wren Engine 内置了 SQL 处理器和转换器,通过 Wren Engine,我们将解析查询到 Wren Engine 的 SQL,然后从符合标准 ANSI SQL 的 WrenSQL 语法中解包并翻译成不同的方言,如 BigQuery、PostgreSQL、Snowflake 等。
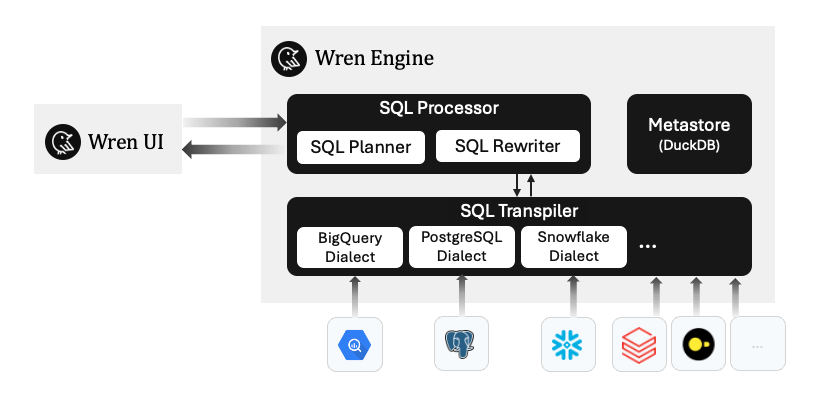
下面是一个简单的例子,在这里你定义了一个数据集的MDL,当你提交你的SQL时,所有的关系、计算、指标都将转换为目标方言特定的SQL。
这是一个MDL文件的示例(请在Gist上查看)
如果您提交如下查询
SELECT * FROM orders
Wren 引擎将根据 MDL 定义将 Wren SQL 转换为特定方言的 SQL,如下所示。
WITH
"order_items" AS (
SELECT
"order_items"."FreightValue" "FreightValue"
, "order_items"."ItemNumber" "ItemNumber"
, "order_items"."OrderId" "OrderId"
, "order_items"."Price" "Price"
, "order_items"."ProductId" "ProductId"
, "order_items"."ShippingLimitDate" "ShippingLimitDate"
FROM
(
SELECT
"order_items"."FreightValue" "FreightValue"
, "order_items"."ItemNumber" "ItemNumber"
, "order_items"."OrderId" "OrderId"
, "order_items"."Price" "Price"
, "order_items"."ProductId" "ProductId"
, "order_items"."ShippingLimitDate" "ShippingLimitDate"
FROM
(
SELECT
"FreightValue" "FreightValue"
, "ItemNumber" "ItemNumber"
, "OrderId" "OrderId"
, "Price" "Price"
, "ProductId" "ProductId"
, "ShippingLimitDate" "ShippingLimitDate"
FROM
(
SELECT *
FROM
main.order_items
) "order_items"
) "order_items"
) "order_items"
)
, "payments" AS (
SELECT
"payments"."Installments" "Installments"
, "payments"."OrderId" "OrderId"
, "payments"."Sequential" "Sequential"
, "payments"."Type" "Type"
, "payments"."Value" "Value"
FROM
(
SELECT
"payments"."Installments" "Installments"
, "payments"."OrderId" "OrderId"
, "payments"."Sequential" "Sequential"
, "payments"."Type" "Type"
, "payments"."Value" "Value"
FROM
(
SELECT
"Installments" "Installments"
, "OrderId" "OrderId"
, "Sequential" "Sequential"
, "Type" "Type"
, "Value" "Value"
FROM
(
SELECT *
FROM
main.payments
) "payments"
) "payments"
) "payments"
)
, "orders" AS (
SELECT
"orders"."ApprovedTimestamp" "ApprovedTimestamp"
, "orders"."CustomerId" "CustomerId"
, "orders"."DeliveredCarrierDate" "DeliveredCarrierDate"
, "orders"."DeliveredCustomerDate" "DeliveredCustomerDate"
, "orders"."EstimatedDeliveryDate" "EstimatedDeliveryDate"
, "orders"."OrderId" "OrderId"
, "orders"."PurchaseTimestamp" "PurchaseTimestamp"
, "orders"."Status" "Status"
, "RevenueA"."RevenueA" "RevenueA"
, "Sales"."Sales" "Sales"
FROM
(((
SELECT
"orders"."ApprovedTimestamp" "ApprovedTimestamp"
, "orders"."CustomerId" "CustomerId"
, "orders"."DeliveredCarrierDate" "DeliveredCarrierDate"
, "orders"."DeliveredCustomerDate" "DeliveredCustomerDate"
, "orders"."EstimatedDeliveryDate" "EstimatedDeliveryDate"
, "orders"."OrderId" "OrderId"
, "orders"."PurchaseTimestamp" "PurchaseTimestamp"
, "orders"."Status" "Status"
FROM
(
SELECT
"ApprovedTimestamp" "ApprovedTimestamp"
, "CustomerId" "CustomerId"
, "DeliveredCarrierDate" "DeliveredCarrierDate"
, "DeliveredCustomerDate" "DeliveredCustomerDate"
, "EstimatedDeliveryDate" "EstimatedDeliveryDate"
, "OrderId" "OrderId"
, "PurchaseTimestamp" "PurchaseTimestamp"
, "Status" "Status"
FROM
(
SELECT *
FROM
main.orders
) "orders"
) "orders"
) "orders"
LEFT JOIN (
SELECT
"orders"."OrderId"
, sum("order_items"."Price") "RevenueA"
FROM
((
SELECT
"ApprovedTimestamp" "ApprovedTimestamp"
, "CustomerId" "CustomerId"
, "DeliveredCarrierDate" "DeliveredCarrierDate"
, "DeliveredCustomerDate" "DeliveredCustomerDate"
, "EstimatedDeliveryDate" "EstimatedDeliveryDate"
, "OrderId" "OrderId"
, "PurchaseTimestamp" "PurchaseTimestamp"
, "Status" "Status"
FROM
(
SELECT *
FROM
main.orders
) "orders"
) "orders"
LEFT JOIN "order_items" ON ("orders"."OrderId" = "order_items"."OrderId"))
GROUP BY 1
) "RevenueA" ON ("orders"."OrderId" = "RevenueA"."OrderId"))
LEFT JOIN (
SELECT
"orders"."OrderId"
, sum("payments"."Value") "Sales"
FROM
((
SELECT
"ApprovedTimestamp" "ApprovedTimestamp"
, "CustomerId" "CustomerId"
, "DeliveredCarrierDate" "DeliveredCarrierDate"
, "DeliveredCustomerDate" "DeliveredCustomerDate"
, "EstimatedDeliveryDate" "EstimatedDeliveryDate"
, "OrderId" "OrderId"
, "PurchaseTimestamp" "PurchaseTimestamp"
, "Status" "Status"
FROM
(
SELECT *
FROM
main.orders
) "orders"
) "orders"
LEFT JOIN "payments" ON ("payments"."OrderId" = "orders"."OrderId"))
GROUP BY 1
) "Sales" ON ("orders"."OrderId" = "Sales"."OrderId"))
)
SELECT *
FROM
orders
跨来源的一致访问控制(规划中)
管理跨各种数据源的访问控制可能具有挑战性,因为访问控制机制各不相同。Wren Engine 也旨在解决这些问题,例如
-
定义数据策略: 确保所有数据源遵循相同的安全和访问协议。
-
统一认证和授权:通过将不同的数据源集成到一个引擎下,认证和授权过程变得简化。这种统一性降低了未经授权访问的风险,并确保用户在所有数据源上具有一致的访问权限。
-
基于角色的访问控制(RBAC):实施RBAC,其中访问权限基于角色而不是单个用户分配。
我们将在项目中实施时分享更多细节!
开放与独立架构
Wren Engine 已开源,它被设计为一个独立的语义引擎,您可以轻松地将其与任何 AI 代理一起实现,您可以将其用作语义层的通用语义引擎。

最终备注
Wren Engine 的使命是作为 LLMs 的语义引擎,为语义层提供支持,并向 BI 和 LLMs 提供业务上下文。我们相信建立一个开放的社区,以确保引擎与任何应用程序和数据源的兼容性。我们还旨在提供一种架构,使开发人员能够在其上自由构建 AI 代理。