Boosted Trees 简介
XGBoost 代表 “极限梯度提升”,其中术语 “梯度提升” 源自 Friedman 的论文 贪婪函数近似:梯度提升机。
梯度提升树 已经存在了一段时间,并且有很多关于这个主题的资料。本教程将使用监督学习的元素,以一种自包含和有原则的方式解释提升树。我们认为这种解释更清晰、更正式,并且能够激发在XGBoost中使用的模型公式的动机。
监督学习的要素
XGBoost 用于监督学习问题,其中我们使用训练数据(具有多个特征) \(x_i\) 来预测目标变量 \(y_i\)。在我们具体学习树之前,让我们先回顾一下监督学习中的基本元素。
模型与参数
监督学习中的**模型**通常指的是从输入 \(x_i\) 生成预测 \(y_i\) 的数学结构。一个常见的例子是*线性模型*,其中预测值表示为 \(\hat{y}_i = \sum_j \theta_j x_{ij}\),即加权输入特征的线性组合。预测值可以根据任务的不同有不同的解释,例如回归或分类。例如,在逻辑回归中,它可以经过逻辑变换以获得正类的概率,当我们需要对输出进行排序时,它也可以用作排序分数。
参数 是我们需要从数据中学习的不确定部分。在线性回归问题中,参数是系数 \(\theta\)。通常我们会使用 \(\theta\) 来表示参数(模型中有很多参数,我们这里的定义是粗略的)。
目标函数:训练损失 + 正则化
通过明智地选择 \(y_i\),我们可以表达各种任务,如回归、分类和排序。**训练**模型的任务在于找到最适合训练数据 \(x_i\) 和标签 \(y_i\) 的最佳参数 :math:` heta`。为了训练模型,我们需要定义**目标函数**来衡量模型对训练数据的拟合程度。
目标函数的一个显著特征是它们由两部分组成:训练损失 和 正则化项:
其中 \(L\) 是训练损失函数,而 \(\Omega\) 是正则化项。训练损失衡量了我们的模型对训练数据的 预测 能力。 \(L\) 的一个常见选择是 均方误差 ,其定义为
另一个常用的损失函数是逻辑损失,用于逻辑回归:
正则化项 是人们通常忘记添加的部分。正则化项控制模型的复杂度,这有助于我们避免过拟合。这听起来有点抽象,所以让我们考虑以下图片中的问题。你被要求 拟合 一个给定输入数据点的阶梯函数,这些数据点位于图片的左上角。在三种解决方案中,你认为哪一种是最佳拟合?
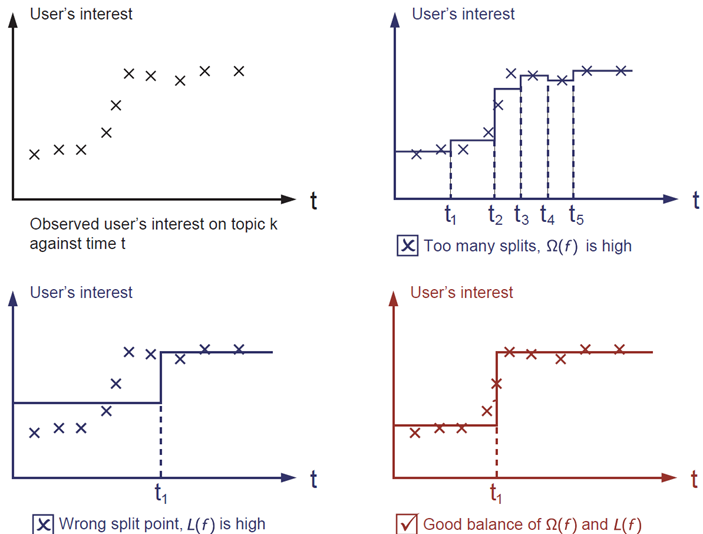
正确答案以红色标记。请考虑这在视觉上是否看起来合理。一般原则是我们既想要一个 简单 又 可预测 的模型。这两者之间的权衡在机器学习中也被称为 偏差-方差权衡。
为什么要介绍一般原则?
上述元素构成了监督学习的基本元素,它们是机器学习工具包的自然构建模块。例如,你应该能够描述梯度提升树和随机森林之间的差异和共性。以形式化的方式理解过程也有助于我们理解我们正在学习的目标以及诸如剪枝和平滑等启发式方法背后的原因。
决策树集成
既然我们已经介绍了监督学习的元素,让我们开始学习真正的树。首先,让我们先了解XGBoost的模型选择:决策树集成。树集成模型由一组分类和回归树(CART)组成。这里是一个简单的CART示例,它分类某人是否会喜欢一个假设的电脑游戏X。
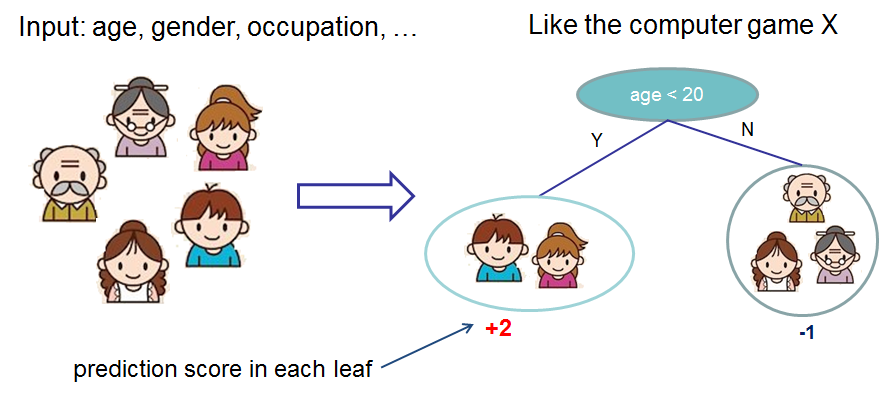
我们将一个家庭的成员分类到不同的叶子中,并根据相应的叶子给他们评分。CART 与决策树有些不同,在决策树中,叶子只包含决策值。在 CART 中,每个叶子都关联一个实际分数,这为我们提供了超越分类的更丰富的解释。这也允许我们采用一种有原则的、统一的方法进行优化,正如我们将在本教程的后面部分看到的那样。
通常,单棵树的强度不足以在实践中使用。实际使用的是集成模型,它将多棵树的预测结果相加。
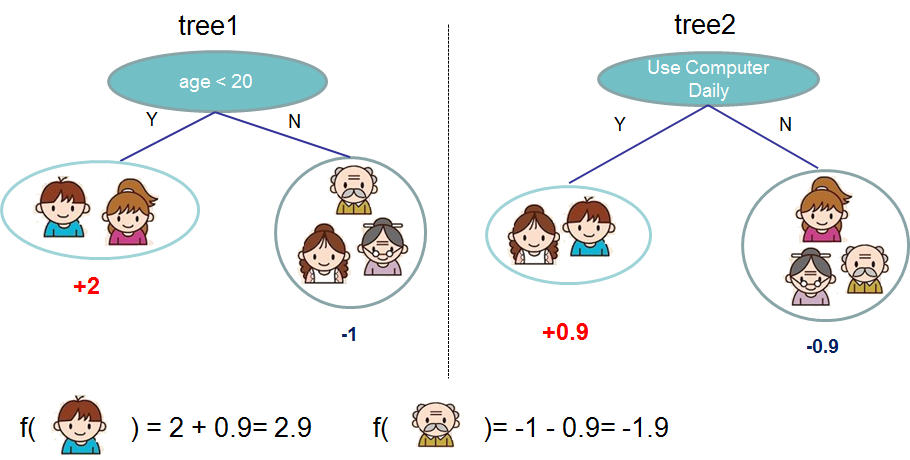
这里是一个包含两棵树的树集合的例子。每棵树的预测分数被加总以得到最终分数。如果你看这个例子,一个重要的事实是这两棵树试图*互补*。在数学上,我们可以将我们的模型写成以下形式
其中 \(K\) 是树的数量,\(f_k\) 是函数空间 \(\mathcal{F}\) 中的一个函数,而 \(\mathcal{F}\) 是所有可能的CART的集合。待优化的目标函数由以下公式给出
其中 \(\omega(f_k)\) 是树 \(f_k\) 的复杂度,详细定义见后文。
现在这里有一个技巧问题:随机森林中使用的*模型*是什么?树集成!所以随机森林和提升树实际上是相同的模型;区别在于我们如何训练它们。这意味着,如果你为树集成编写一个预测服务,你只需要编写一个,它应该适用于随机森林和梯度提升树。(参见 Treelite 的实际例子。)监督学习元素为何出色的一个例子。
树提升
既然我们已经介绍了模型,让我们转向训练:我们应该如何学习这些树?答案是,对于所有监督学习模型来说,总是如此:定义一个目标函数并优化它!
设以下为目标函数(记住它总是需要包含训练损失和正则化):
附加训练
我们首先要问的第一个问题是:树的**参数**是什么?你会发现,我们需要学习的是那些函数 \(f_i\),每个函数都包含树的结构和叶子分数。学习树的结构比传统的优化问题要困难得多,因为在传统问题中,你可以简单地取梯度。一次性学习所有的树是不可行的。相反,我们采用了一种加法策略:固定我们已经学到的内容,并一次添加一棵新树。我们将第 \(t\) 步的预测值记为 \(\hat{y}_i^{(t)}\)。然后我们有
剩下的问题是:在每一步我们想要哪棵树?一个自然的选择是添加那个能优化我们目标的树。
如果我们考虑使用均方误差(MSE)作为我们的损失函数,目标就变成了
MSE 的形式友好,包含一个一阶项(通常称为残差)和一个二次项。对于其他感兴趣的损失(例如,逻辑损失),要得到这样一个好的形式并不容易。因此,在一般情况下,我们取 损失函数的泰勒展开至二阶:
其中 \(g_i\) 和 \(h_i\) 定义为
在我们移除所有常量后,步骤 \(t\) 的具体目标变为
这成为我们新树的优化目标。这个定义的一个重要优势是目标函数的值仅依赖于 \(g_i\) 和 \(h_i\)。这就是 XGBoost 支持自定义损失函数的方式。我们可以使用完全相同的求解器来优化每一个损失函数,包括逻辑回归和成对排序,只需将 \(g_i\) 和 \(h_i\) 作为输入!
模型复杂度
我们已经介绍了训练步骤,但等等,还有一件重要的事情,即 正则化项!我们需要定义树的复杂度 \(\omega(f)\)。为此,让我们首先细化树 \(f(x)\) 的定义。
这里 \(w\) 是叶子上的分数向量,\(q\) 是一个将每个数据点分配到相应叶子的函数,而 \(T\) 是叶子的数量。在 XGBoost 中,我们将复杂度定义为
当然,定义复杂性的方法不止一种,但这种方法在实践中效果很好。正则化是大多数树包处理得不太仔细,或者干脆忽略的部分。这是因为传统的树学习处理只强调提高不纯度,而复杂性控制则留给启发式方法。通过正式定义它,我们可以更好地理解我们在学习什么,并获得在实际应用中表现良好的模型。
结构评分
这里是推导的神奇部分。在重新表述树模型后,我们可以将目标值写为第 \(t\) 棵树的形式:
其中 \(I_j = \{i|q(x_i)=j\}\) 是分配给第 \(j\) 个叶子的数据点索引集合。注意在第二行中,我们改变了求和的索引,因为同一叶子上的所有数据点获得相同的分数。我们可以通过定义 \(G_j = \sum_{i\in I_j} g_i\) 和 \(H_j = \sum_{i\in I_j} h_i\) 进一步压缩表达式:
在这个方程中,\(w_j\) 是相互独立的,形式 \(G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2\) 是二次的,对于给定的结构 \(q(x)\),我们能得到的最佳 \(w_j\) 和最佳目标减少量是:
最后一个方程衡量了树结构 \(q(x)\) 的 好坏 。

如果这一切听起来有点复杂,让我们看看图片,看看如何计算分数。基本上,对于给定的树结构,我们将统计数据 \(g_i\) 和 \(h_i\) 推送到它们所属的叶子,将统计数据相加,并使用公式计算树的好坏。这个分数类似于决策树中的不纯度度量,只不过它还考虑了模型复杂性。
学习树结构
既然我们有了一个衡量树好坏的方法,理想情况下我们会枚举所有可能的树并选择最好的一个。实际上这是不可行的,因此我们将尝试一次优化树的一个层次。具体来说,我们尝试将一个叶子分裂成两个叶子,并且它获得的分数是
这个公式可以分解为 1) 新左叶的分数 2) 新右叶的分数 3) 原始叶的分数 4) 对额外叶的正则化。我们可以看到一个重要的事实:如果增益小于 \(\gamma\),我们最好不要添加那个分支。这正是基于树模型的**剪枝**技术!通过使用监督学习的原理,我们可以自然地得出这些技术有效的原因 :)
对于实值数据,我们通常希望找到一个最佳分割。为了高效地进行分割,我们将所有实例按排序顺序排列,如下图所示。
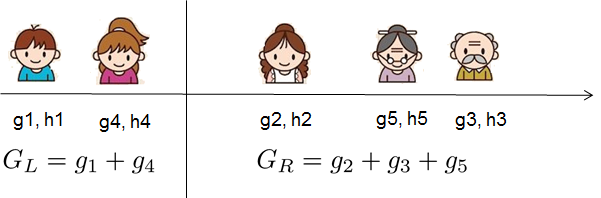
从左到右的扫描足以计算所有可能分割方案的结构得分,我们可以高效地找到最佳分割。
备注
加性树学习的局限性
由于枚举所有可能的树结构是不可行的,我们每次添加一个分割。这种方法在大多数情况下效果良好,但有些边缘情况会因此失败。对于这些边缘情况,训练结果会导致模型退化,因为我们每次只考虑一个特征维度。有关示例,请参见 梯度提升能学会简单的算术吗?。
关于 XGBoost 的总结
既然你已经理解了什么是提升树,你可能会问,XGBoost 的介绍在哪里?XGBoost 正是一个基于本教程中介绍的正式原理而启发的工具!更重要的是,它在 系统优化 和 机器学习原理 方面都经过了深思熟虑的开发。这个库的目标是推动机器计算极限,提供一个 可扩展、便携 和 准确 的库。确保你尝试一下,最重要的是,为社区贡献你的智慧(代码、示例、教程)!