检索增强生成(RAG)
通用语言模型可以进行微调,以实现诸如情感分析和命名实体识别等几种常见任务。这些任务通常不需要额外的背景知识。
对于更复杂和知识密集的任务,可以构建基于语言模型的系统,访问外部知识源以完成任务。这样可以实现更多的事实一致性,提高生成响应的可靠性,并有助于缓解“幻觉”问题。
Meta AI 研究人员提出了一种称为检索增强生成(RAG)的方法来解决这类知识密集型任务。RAG将信息检索组件与文本生成模型结合起来。RAG可以进行微调,其内部知识可以高效修改,而无需重新训练整个模型。
RAG接受输入并在给定源(例如维基百科)的情况下检索一组相关/支持文档。这些文档与原始输入提示连接起来作为上下文,并��馈送给文本生成器,生成最终输出。这使得RAG适应了事实可能随时间演变的情况。这在 LLMs 的参数化知识是静态的情况下非常有用。RAG允许语言模型绕过重新训练,通过基于检索的生成访问最新信息以生成可靠输出。
Lewis 等人(2021)提出了一个适用于 RAG 的通用微调配方。预训练的 seq2seq 模型用作参数化内存,而维基百科的密集向量索引用作非参数化内存(通过使用神经预训练的检索器进行访问)。下面是该方法的工作概述:
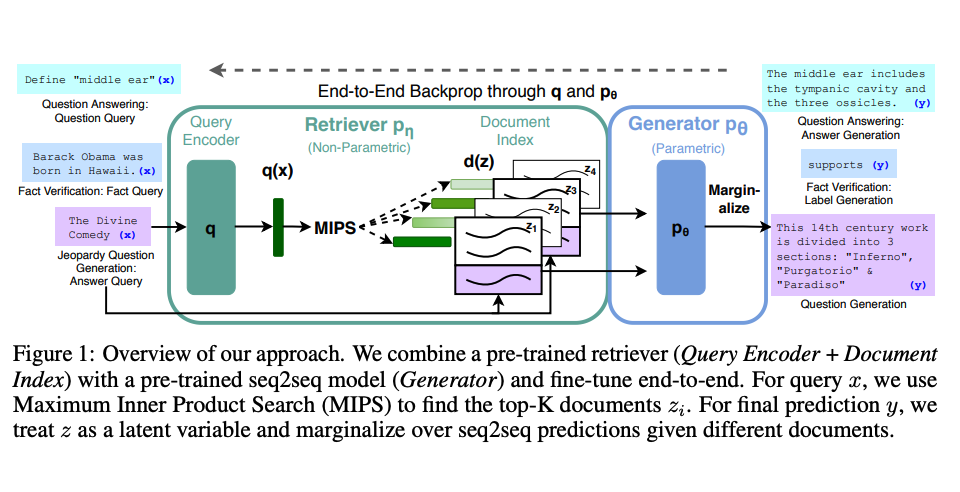
图片来源:Lewis et al. (2021)
RAG在诸如自然问题、WebQuestions和 CuratedTrec 等多个基准测试中表现出色。在 MS-MARCO 和 Jeopardy 问题上进行测试时,RAG生成的响应更具事实性、特定性和多样性。RAG还改善了 FEVER 事实验证的结果。
这显示了 RAG 作为增强语言模型在知识密集任务中输出的潜力。
最近,这些基于检索器的方法变得更加流行,并与流行的 LLMs(如 ChatGPT)结合,以提高能力和事实一致性。
RAG 应用案例:生成友好的机器学习论文标题
下面,我们准备了一个笔记本教程,展示如何使用开源 LLMs 构建一个 RAG 系统,用于生成简短而简洁的机器学习论文标题:
参考文献
- 大语言模型的检索增强生成:一项调查(2023 年 12 月)
- 检索增强生成:简化智能自然语言处理模型的创建(2020 年 9 月)