反思
反思(Reflexion)是一个通过语言反馈来加强基于语言的代理的框架。根据Shinn等人(2023)的说法,“反思是一个将策略参数化为代理的记忆编码和LLM参数选择的‘口头’强化的新范式。”
在高层次上,反思将来自环境的反馈(可以是自由形式的语言或标量)转换为语言反馈,也被称为自我反思,这作为上下文提供给下一集中的LLM代理。这有助于代理快速有效地从先前的错误中学习,从而提高在许多高级任务上的表现。
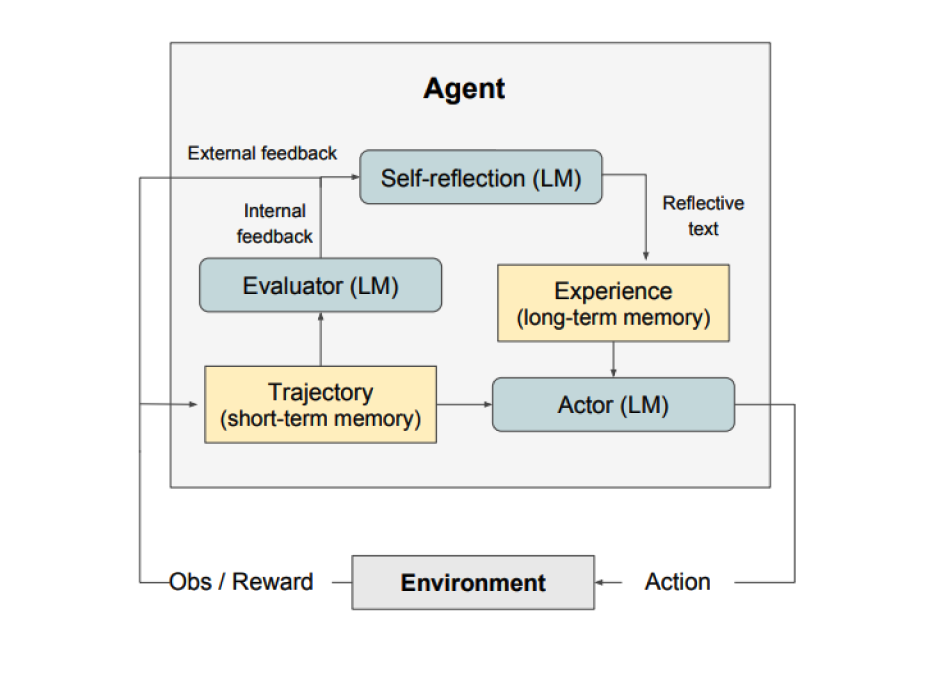
如上图所示,反思包括三个不同的模型:
- 执行者:根据状态观察生成文本和动作。执行者在环境中采取行动并接收观察结果,从而产生一个轨迹。思维链(CoT)和ReAct被用作执行者模型。还添加了一个记忆组件,以为代理提供额外的上下文。
- 评估者:对执行者产生的输出进行评分。具体来说,它以生成的轨迹(也称为短期记忆)作为输入,并输出一个奖励分数。根据任务使用不同的奖励函数(LLMs和基于规则的启发式用于决策任务)。
- 自我反思:生成口头强化线索,以帮助执行者自我改进。LLM扮演这一角色,并为未来的试验提供有价值的反馈。为了生成特定和相关的反馈,同时将其存储在记忆中,自我反思模型利用奖励信号、当前轨迹和其持久记忆。代理利用这些经验(存储在长期记忆中)来快速改进决策。
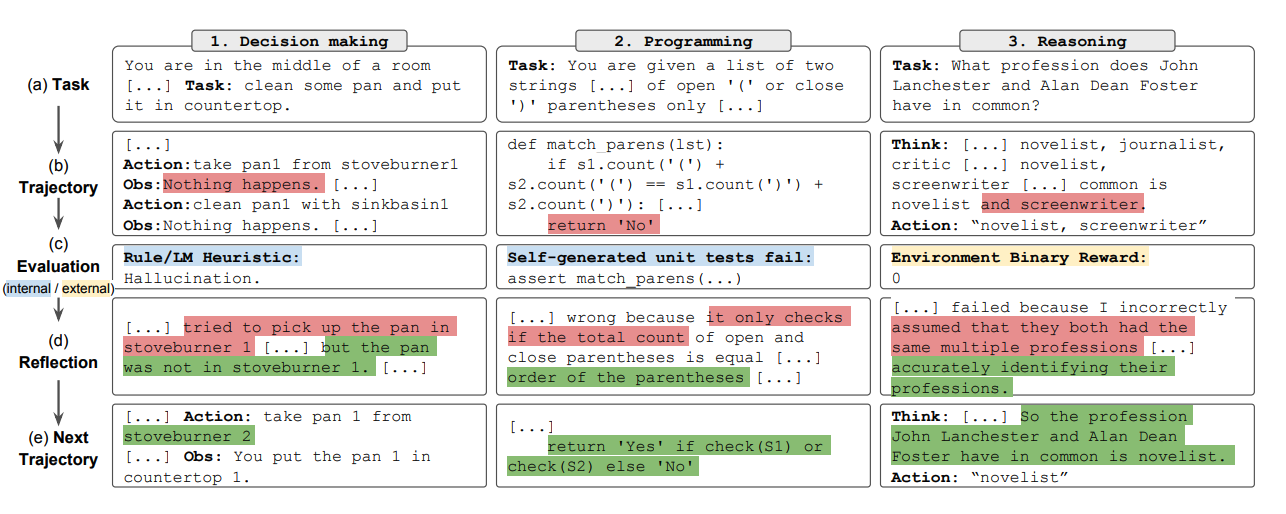
总之,反思过程的关键步骤是a)定义任务,b)生成轨迹,c)评估,d)进行反思,e)生成下一个轨迹。下图展示了反思代理如何学习以迭代优化其行为,从而解决决策、编程和推理等各种任务。反思通过引入自我评估、自我反思和记忆组件扩展了ReAct框架。
结果
实验结果表明,反思代理在AlfWorld决策任务、HotPotQA推理问题和HumanEval中的Python编程任务上显著提高了性能。
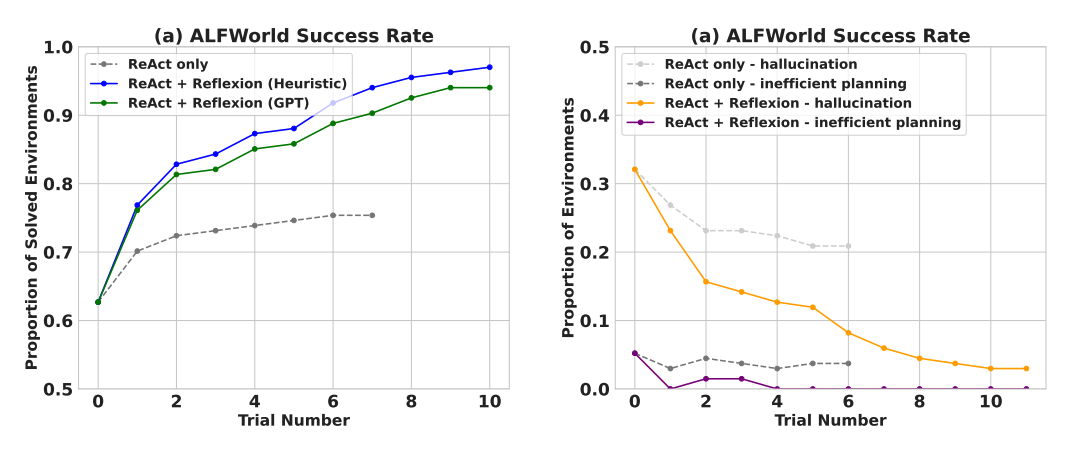
在顺序决策(AlfWorld)任务的评估中,ReAct + 反思通过使用启发式和GPT进行二元分类的自我评估技术,完成了130/134个任务,明显优于ReAct。
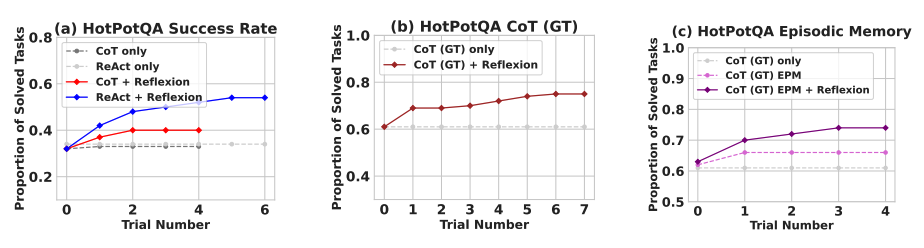
反思在多个学习步骤上明显优于所有基准方法。仅针对推理任务以及在添加了包含最近轨迹的情节记忆时,反思 + CoT分别优于仅CoT和带有情节记忆的CoT。
如下表所示,反思通常在MBPP、HumanEval和Leetcode Hard上的Python和Rust代码编写方面优于先前的最新方法。

何时使用反思?
反思最适用于以下情况:
-
代理需要通过反复尝试学习:反思旨在帮助代理通过反思过去的错误并将这些知识纳入未来决策中来提高性能。这使其非常适合需要通过反复尝试学习的任务,例如决策、推理和编程。
-
传统强化学习方法不切实际:传统的强化学习(RL)方法通常需要大量的训练数据和昂贵的模型微调。反思提供了一个轻量级的替代方案,不需要微调基础语言模型,因此在数据和计算资源方面更加高效。
-
需要细致的反馈:反思利用口头反馈,相比传统RL中使用的标量奖励,口头反馈可以更加细致和具体,这使得代理能够更好地理解自己的错误,并在随后的试验中做出更有针对性的改进。
-
可解释性和显式记忆至关重要:相较于传统的强化学习方法,反思提供了更具解释性和显式形式的情节记忆。代理的自我反思被存储在其记忆中,使得对其学习过程进行更轻松的分析和理解成为可能。
反思在以下任务中表现出了有效性:
- 顺序决策制定:反思代理在 AlfWorld 任务中提高了其性能,该任务涉及在各种环境中导航并完成多步骤目标。
- 推理:反思提高了代理在 HotPotQA 上的表现,这是一个需要对多个文档进行推理的问答数据集。
- 编程:反思代理在 HumanEval 和 MBPP 等基准测试中编写了更好的代码,在某些情况下取得了最先进的结果。
以下是反思的一些局限性:
- 依赖自我评估能力:反思依赖于代理准确评估其表现并生成有用的自我反思的能力。这可能具有挑战性,特别是对于复杂的任务,但预计随着模型能力的不断提高,反思会随时间变得更加优秀。
- 长期记忆约束:反思利用具有最大容量的滑动窗口,但对于更复杂的任务,使用高级结构如向量嵌入或 SQL 数据库可能更有优势。
- 代码生成的局限性:在指定准确的输入-输出映射方面存在测试驱动开发的局限性(例如,非确定性生成函数和受硬件影响的函数输出)。
图片来源:反思:具有语言增强学习的语言代理