参数调整
本页面包含针对不同场景的参数调优指南。
其他有用链接列表
调整叶节点优先(最佳优先)树的参数
LightGBM 使用 leaf-wise 树生长算法,而许多其他流行的工具使用深度优先树生长。与深度优先生长相比,leaf-wise 算法可以更快地收敛。然而,如果不使用适当的参数,leaf-wise 生长可能会导致过拟合。
要使用叶向树获得良好结果,以下是一些重要参数:
num_leaves。这是控制树模型复杂度的主要参数。理论上,我们可以设置num_leaves = 2^(max_depth)以获得与深度优先树相同的叶子数量。然而,这种简单的转换在实践中并不理想。对于固定的叶子数量,叶子优先树通常比深度优先树更深。不受限制的深度可能会导致过拟合。因此,在尝试调整num_leaves时,我们应该让它小于2^(max_depth)。例如,当max_depth=7时,深度优先树可以获得良好的准确性,但将num_leaves设置为127可能会导致过拟合,而将其设置为70或80可能会获得比深度优先更好的准确性。min_data_in_leaf。这是一个非常重要的参数,用于防止在逐叶树中过拟合。其最佳值取决于训练样本的数量和num_leaves。将其设置为较大的值可以避免生成过深的树,但可能会导致欠拟合。在实践中,对于大型数据集,将其设置为数百或数千就足够了。max_depth。你也可以使用max_depth来明确限制树的深度。如果你设置了max_depth,也要明确地将num_leaves设置为一个<= 2^max_depth的值。
为了更快的速度
添加更多计算资源
在可用的系统上,LightGBM 使用 OpenMP 来并行化许多操作。LightGBM 使用的最大线程数由参数 num_threads 控制。默认情况下,这将遵循 OpenMP 的默认行为(每个物理 CPU 核心一个线程,或者如果设置了环境变量 OMP_NUM_THREADS,则为该变量的值)。为了获得最佳性能,请将其设置为可用的 物理 CPU 核心数。
通过转移到具有更多可用CPU核心的机器,您可能会实现更快的训练。
使用分布式(多机)训练也可能减少训练时间。详情请参阅 分布式学习指南。
使用启用了GPU的LightGBM版本
你可能会发现,使用启用了GPU的LightGBM构建进行训练会更快。详情请参阅 GPU教程 。
生长更浅的树
LightGBM 的总训练时间随着添加的树节点总数增加而增加。LightGBM 提供了几个参数,可以用来控制每棵树的节点数量。
以下建议将加快训练速度,但可能会影响训练的准确性。
减少 max_depth
此参数是一个整数,用于控制每棵树的根节点与叶节点之间的最大距离。减小 max_depth 以减少训练时间。
减少 num_leaves
LightGBM 根据添加该节点的增益来向树中添加节点,无论深度如何。来自 功能文档 的这张图说明了该过程。
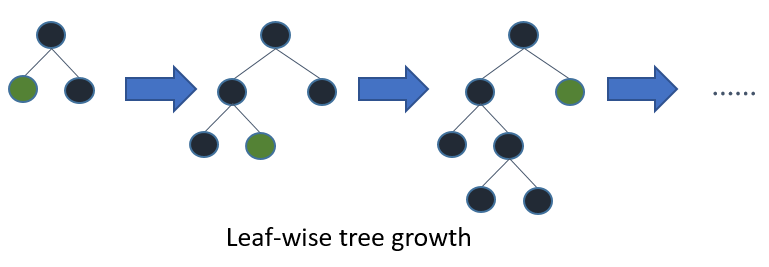
由于这种增长策略,单独使用 max_depth 来限制树的复杂性并不直接。num_leaves 参数设置每棵树的最大节点数。减少 num_leaves 以缩短训练时间。
增加 min_gain_to_split
当添加一个新的树节点时,LightGBM 选择具有最大增益的分割点。增益基本上是添加分割点导致的训练损失的减少。默认情况下,LightGBM 将 min_gain_to_split 设置为 0.0,这意味着“没有改进是太小”。然而,在实践中,您可能会发现训练损失的非常小的改进对模型的泛化误差没有显著影响。增加 min_gain_to_split 以减少训练时间。
增加 min_data_in_leaf 和 min_sum_hessian_in_leaf
根据训练数据的大小和特征的分布,LightGBM 可能会添加仅描述少量观测值的树节点。在最极端的情况下,考虑添加一个树节点,该节点仅有一个训练数据中的观测值落入。这不太可能很好地泛化,并且可能是过拟合的迹象。
这可以通过 max_depth 和 num_leaves 等参数间接预防,但 LightGBM 还提供了参数来帮助你直接避免添加这些过于具体的树节点。
min_data_in_leaf: 必须落入树节点的最小观测数,以便将其添加。min_sum_hessian_in_leaf: 叶节点中观测值的 Hessian 和(目标函数的二阶导数在每个观测值上的评估)的最小值。对于某些回归目标,这只是每个节点中必须落入的最小记录数。对于分类目标,它表示概率分布的总和。有关如何推理此参数值的良好描述,请参见 这个 Stack Overflow 回答。
少种树
减少 num_iterations
num_iterations 参数控制将执行的提升轮数。由于 LightGBM 使用决策树作为学习器,这也可以被认为是“树的数量”。
如果你尝试更改 num_iterations,也要相应地更改 learning_rate。learning_rate 不会对训练时间产生任何影响,但它会影响训练的准确性。一般来说,如果你减少了 num_iterations,你应该增加 learning_rate。
选择合适的 num_iterations 和 learning_rate 值高度依赖于数据和目标,因此这些参数通常通过超参数调整从一组可能的值中选择。
减少 num_iterations 以缩短训练时间。
使用早停法
如果启用了早停,在每次提升轮次后,模型的训练准确性会根据包含训练过程中不可用数据的验证集进行评估。然后将该准确性与前一次提升轮次的准确性进行比较。如果模型的准确性在若干连续轮次中未能提高,LightGBM 将停止训练过程。
那个“连续轮数”由参数 early_stopping_round 控制。例如,early_stopping_round=1 表示“验证集上的准确率首次没有提升时,停止训练”。
设置 early_stopping_round 并提供验证集以可能减少训练时间。
考虑减少分割
前几节中描述的参数控制构建多少棵树以及每棵树构建多少个节点。通过减少将树节点添加到模型所需的时间,可以进一步减少训练时间。
以下建议将加快训练速度,但可能会影响训练的准确性。
在创建数据集时启用特征预过滤
默认情况下,当构建一个 LightGBM Dataset 对象时,会根据 min_data_in_leaf 的值过滤掉一些特征。
作为一个简单的例子,考虑一个包含1000个观测值的数据集,其中有一个名为 feature_1 的特征。feature_1 只取两个值:25.0(995个观测值)和50.0(5个观测值)。如果 min_data_in_leaf = 10,则该特征没有分割会导致至少一个叶节点只有5个观测值,从而无法进行有效的分割。
与其在每次迭代中重新考虑此功能然后忽略它,LightGBM 在训练之前,当 Dataset 构建时,会过滤掉此功能。
如果默认行为已被设置 feature_pre_filter=False 覆盖,请设置 feature_pre_filter=True 以减少训练时间。
创建数据集时减少 max_bin 或 max_bin_by_feature
LightGBM 训练 将连续特征分桶为离散的箱子 以提高训练速度并减少训练的内存需求。这种分箱在 Dataset 构建期间进行一次。添加节点时考虑的分割数为 O(#feature * #bin),因此减少每个特征的箱子数量可以减少需要评估的分割数。
max_bin 控制特征将被分桶的最大桶数。也可以通过传递 max_bin_by_feature 来逐特征设置此最大值。
减少 max_bin 或 max_bin_by_feature 以缩短训练时间。
创建数据集时增加 min_data_in_bin
一些箱子可能包含少量观测值,这可能意味着评估该箱子的边界作为可能的分割点不太可能显著改变最终模型。您可以通过设置 min_data_in_bin 来控制箱子的粒度。
增加 min_data_in_bin 以减少训练时间。
减少 feature_fraction
默认情况下,LightGBM 在训练过程中会考虑 Dataset 中的所有特征。可以通过将 feature_fraction 设置为 > 0 且 <= 1.0 的值来改变此行为。例如,将 feature_fraction 设置为 0.5,会告诉 LightGBM 在构建每棵树的开始时随机选择 50% 的特征。这减少了为添加每个树节点而必须评估的分割总数。
减少 feature_fraction 以缩短训练时间。
减少 max_cat_threshold
LightGBM 使用一种 自定义方法来寻找分类特征的最佳分割。在这个过程中,LightGBM 探索将分类特征分成两组的分割。这些有时被称为“k-vs.-rest”分割。较高的 max_cat_threshold 值对应更多的分割点和更大的可能搜索组大小。
降低 max_cat_threshold 以减少训练时间。
使用更少的数据
使用Bagging
默认情况下,LightGBM 在每次迭代中使用训练数据中的所有观测值。也可以告诉 LightGBM 随机抽样训练数据。这种在不放回的情况下对多个随机样本进行训练的过程称为“装袋”。
将 bagging_freq 设置为一个大于 0 的整数,以控制新样本的抽取频率。将 bagging_fraction 设置为一个 > 0.0 且 < 1.0 的值,以控制样本的大小。例如,{"bagging_freq": 5, "bagging_fraction": 0.75} 告诉 LightGBM “每 5 次迭代重新抽样,且抽取训练数据的 75% 作为样本”。
减少 bagging_fraction 以缩短训练时间。
使用 save_binary 保存构建的数据集
这仅适用于 LightGBM CLI。如果你传递参数 save_binary,训练数据集和所有验证集将以 LightGBM 理解的二进制格式保存。这可以加快下一次的训练速度,因为构建 Dataset 时所做的分箱和其他工作不需要重新进行。
为了提高准确性
使用较大的
max_bin(可能会更慢)使用较小的
learning_rate和较大的num_iterations使用较大的 ``num_leaves``(可能会导致过拟合)
使用更大的训练数据
尝试
dart
处理过拟合
使用小的
max_bin使用较小的
num_leaves使用
min_data_in_leaf和min_sum_hessian_in_leaf通过设置
bagging_fraction和bagging_freq来使用bagging。通过设置
feature_fraction使用特征子采样使用更大的训练数据
尝试
lambda_l1、lambda_l2和min_gain_to_split以进行正则化尝试使用
max_depth以避免生成过深的树尝试
extra_trees尝试增加
path_smooth