计算统计数据¶
通常,人们希望在优化过程中编译统计数据。Statistics 能够编译任何指定对象的任意属性的数据。为此,需要使用与工具箱中相同的语法在 stats 对象中注册所需的统计函数。
stats = tools.Statistics(key=lambda ind: ind.fitness.values)
统计对象是使用一个键作为第一个参数创建的。这个键必须提供一个函数,该函数将在稍后应用于计算统计数据的数据。前面的代码示例使用了每个元素的 fitness.values 属性。
stats.register("avg", numpy.mean)
stats.register("std", numpy.std)
stats.register("min", numpy.min)
stats.register("max", numpy.max)
统计函数现已注册。register 函数期望第一个参数为别名,第二个参数为对向量进行操作的函数。任何后续参数在调用时都会传递给该函数。统计对象的创建现已完成。
预定义算法¶
在使用预定义算法如 eaSimple()、eaMuPlusLambda()、eaMuCommaLambda() 或 eaGenerateUpdate() 时,可以将其之前创建的统计对象作为参数传递给算法。
pop, logbook = algorithms.eaSimple(pop, toolbox, cxpb=0.5, mutpb=0.2, ngen=0,
stats=stats, verbose=True)
统计数据将在每一代自动计算。verbose 参数在优化过程中会在屏幕上打印统计数据。一旦算法返回,最终的种群和一个 Logbook 将被返回。更多信息请参见 下一节 或 Logbook 文档。
编写你自己的算法¶
在编写自己的算法时,包含统计数据非常简单。只需对所需对象进行统计编译即可。例如,对给定人口进行统计编译是通过调用 compile() 方法完成的。
record = stats.compile(pop)
compile 函数的参数必须是一个可迭代的元素,这些元素将调用键。在这里,我们的种群 (pop) 包含个体。统计对象将对每个个体调用键函数以检索其 fitness.values 属性。最终得到的值数组被传递给每个统计函数,结果被放入与函数关联的键下的 record 字典中。打印记录揭示了其本质。
>>> print(record)
{'std': 4.96, 'max': 63.0, 'avg': 50.2, 'min': 39.0}
如何保存和美化打印统计数据将在 下一节 中展示。
多目标统计¶
由于统计数据是直接使用 numpy 函数对值进行计算的,所有目标都是通过 numpy 的默认行为组合在一起的。因此,需要指定操作的轴。这是通过向注册函数提供轴作为附加参数来实现的。
stats = tools.Statistics(key=lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean, axis=0)
stats.register("std", numpy.std, axis=0)
stats.register("min", numpy.min, axis=0)
stats.register("max", numpy.max, axis=0)
即使在单目标的情况下,也可以始终指定轴。唯一的效果是产生不同的输出,因为对象是 numpy 数组。
>>> print(record)
{'std': array([ 4.96]), 'max': array([ 63.]), 'avg': array([ 50.2]),
'min': array([ 39.])}
多项统计¶
还可以对种群个体的不同属性进行统计计算。例如,在遗传编程中,除了适应度之外,对树的高度进行统计是很常见的。可以将多个 Statistics 对象组合在一个 MultiStatistics 中。
stats_fit = tools.Statistics(key=lambda ind: ind.fitness.values)
stats_size = tools.Statistics(key=len)
mstats = tools.MultiStatistics(fitness=stats_fit, size=stats_size)
两个统计对象以与之前相同的方式创建。第二个对象将通过在每个个体上调用 len() 来获取其大小。创建后,这些统计对象被赋予一个 MultiStatistics 对象,其中参数使用关键字给出。这些关键字将用于标识不同的统计数据。统计函数可以在多统计中只注册一次,如下所示,或者在每个统计中单独注册。
mstats.register("avg", numpy.mean)
mstats.register("std", numpy.std)
mstats.register("min", numpy.min)
mstats.register("max", numpy.max)
多统计对象可以提供给一个算法,或者它们可以使用与简单统计完全相同的程序进行编译。
record = mstats.compile(pop)
这次 record 是一个字典的字典。第一层包含统计对象已注册的关键字,第二层类似于之前的简单统计对象。
>>> print(record)
{'fitness': {'std': 1.64, 'max': 6.86, 'avg': 1.71, 'min': 0.166},
'size': {'std': 1.89, 'max': 7, 'avg': 4.54, 'min': 3}}
记录数据¶
一旦数据由统计(或多统计)生成,可以将其保存以供进一步使用在 Logbook 中。日志簿旨在成为按时间顺序排列的条目序列(以字典形式)。它直接符合统计对象返回的数据类型,但不限于此数据。事实上,任何内容都可以纳入日志簿的条目中。
logbook = tools.Logbook()
logbook.record(gen=0, evals=30, **record)
The record() 方法接受可变数量的参数,每个参数都是要记录的数据。在最后一个示例中,我们保存了代数、评估次数以及使用星号魔法从统计对象生成的 record 中包含的所有内容。所有记录将被保存在日志簿中,直到其销毁。
在记录了一定数量的条目后,人们可能希望检索日志簿中包含的信息。
gen, avg = logbook.select("gen", "avg")
The select() 方法提供了一种在所有记录中检索与关键字相关联的所有信息的方式。此方法接受可变数量的字符串参数,这些参数是记录或统计对象中使用的关键字。在这里,我们通过一次调用 select 检索了代数和平均适应度。
日志簿是一个可序列化的对象(只要所有插入的对象都是可序列化的),提供了一种非常方便的方式来将进化的统计数据保存到磁盘上。
import pickle
pickle.dump(logbook, lb_file)
备注
每个算法都会返回一个包含每一代统计数据和整个进化过程中评估次数的日志。
打印到屏幕¶
日志簿可以打印到屏幕或文件。它的 __str__() 方法返回每个键插入的第一个记录的标题以及这些键的完整日志簿。行按插入的时间顺序排列,而列的顺序未定义。指定顺序的最简单方法是设置 header 属性为一个字符串列表,指定列的顺序。
logbook.header = "gen", "avg", "spam"
结果是:
>>> print(logbook)
gen avg spam
0 [ 50.2]
在特定记录中不包含条目的列名将留空,如最后一个示例中的 spam 列。
日志簿还包含一个流属性,仅返回尚未打印的条目。:
>>> print(logbook.stream)
gen avg spam
0 [ 50.2]
>>> logbook.record(gen=1, evals=15, **record)
>>> print(logbook.stream)
1 [ 50.2]
处理多统计数据¶
logbook 能够处理由 MultiStatistics 对象返回的字典的字典。实际上,它会将数据记录在 chapters 中,用于记录中包含的每个子字典。因此,一个 multi 记录可以像一个记录一样使用。
logbook = tools.Logbook()
logbook.record(gen=0, evals=30, **record)
一个区别是列的排序,我们可以按照以下方式为章节及其内容指定顺序:
logbook.header = "gen", "evals", "fitness", "size"
logbook.chapters["fitness"].header = "min", "avg", "max"
logbook.chapters["size"].header = "min", "avg", "max"
生成的输出是:
>>> print(logbook)
fitness size
------------------------- ---------------
gen evals min avg max min avg max
0 30 0.165572 1.71136 6.85956 3 4.54 7
获取数据也是通过章节完成的。
gen = logbook.select("gen")
fit_mins = logbook.chapters["fitness"].select("min")
size_avgs = logbook.chapters["size"].select("avg")
按时间顺序获取代数、最小适应度和平均大小。如果某些数据不可用,向量中会出现 None。
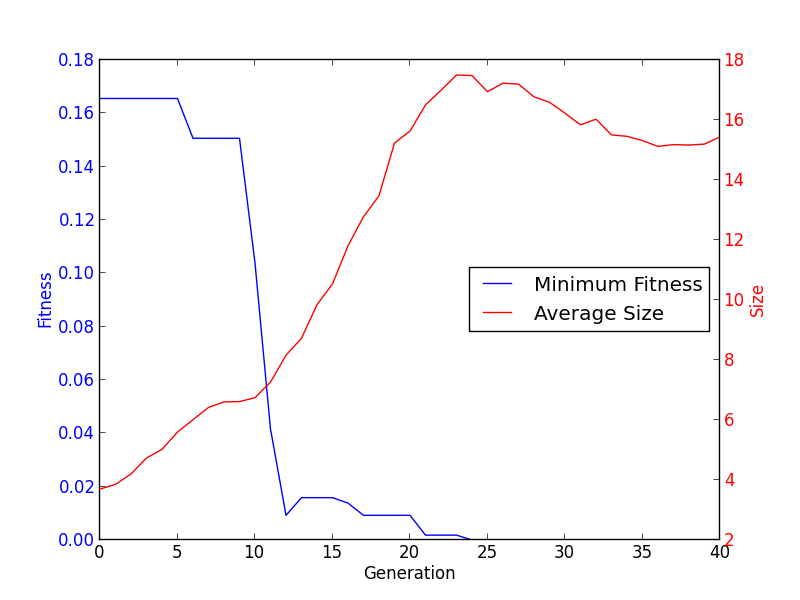
一些绘图糖¶
优化完成后,最常见的操作之一是绘制进化过程中的数据。Logbook 允许非常高效地完成这项工作。使用 select 方法,可以检索所需的数据并使用 matplotlib 绘制它。
gen = logbook.select("gen")
fit_mins = logbook.chapters["fitness"].select("min")
size_avgs = logbook.chapters["size"].select("avg")
import matplotlib.pyplot as plt
fig, ax1 = plt.subplots()
line1 = ax1.plot(gen, fit_mins, "b-", label="Minimum Fitness")
ax1.set_xlabel("Generation")
ax1.set_ylabel("Fitness", color="b")
for tl in ax1.get_yticklabels():
tl.set_color("b")
ax2 = ax1.twinx()
line2 = ax2.plot(gen, size_avgs, "r-", label="Average Size")
ax2.set_ylabel("Size", color="r")
for tl in ax2.get_yticklabels():
tl.set_color("r")
lns = line1 + line2
labs = [l.get_label() for l in lns]
ax1.legend(lns, labs, loc="center right")
plt.show()
当添加到符号回归示例中时,它会生成以下图形: