GPU 调优指南与性能比较
它是如何工作的?
在 LightGBM 中,训练期间的主要计算成本是构建特征直方图。我们使用高效的 GPU 算法来加速这一过程。该实现具有高度的模块化,适用于所有学习任务(分类、排序、回归等)。GPU 加速也适用于分布式学习环境。GPU 算法的实现基于 OpenCL,可以与广泛的 GPU 兼容。
支持的硬件
我们针对 AMD Graphics Core Next (GCN) 架构和 NVIDIA Maxwell 及 Pascal 架构。大多数在2012年后发布的AMD GPU和2014年后发布的NVIDIA GPU应该都支持。我们在以下GPU上测试了GPU实现:
在 Ubuntu 16.10 上使用 AMDGPU-pro 驱动 16.60 的 AMD RX 480
AMD R9 280X (又名 Radeon HD 7970) 在 Ubuntu 16.10 上使用 fglrx 驱动 15.302.2301
NVIDIA GTX 1080 搭载驱动 375.39 和 CUDA 8.0 在 Ubuntu 16.10 上
NVIDIA Titan X (Pascal) 在 Ubuntu 16.04 上使用驱动程序 367.48 和 CUDA 8.0
在Ubuntu 16.04上使用驱动375.39和CUDA 7.5的NVIDIA Tesla M40
不建议使用以下硬件:
NVIDIA Kepler (K80, K40, K20, 大多数 GeForce GTX 700 系列 GPU) 或更早的 NVIDIA GPU。它们不支持本地内存空间中的硬件原子操作,因此直方图构建将会很慢。
基于AMD VLIW4架构的GPU,包括Radeon HD 6xxx系列及更早的GPU。这些GPU已经停产多年,如今很少见到。
如何在GPU上实现良好的加速
您希望运行一些我们已经验证过具有良好加速效果的数据集(包括 Higgs、epsilon、Bosch 等),以确保您的设置是正确的。如果您有多个 GPU,请确保设置
gpu_platform_id和gpu_device_id以使用所需的 GPU。同时,请确保您的系统处于空闲状态(特别是在使用共享计算机时),以获得准确的性能测量。GPU 在大规模和密集数据集上表现最佳。如果数据集太小,在 GPU 上计算它可能效率低下,因为数据传输开销可能很大。如果你有分类特征,请使用
categorical_column选项并将它们直接输入到 LightGBM 中;不要将它们转换为一热变量。为了在GPU上获得良好的加速效果,建议使用较少的分箱数。推荐设置
max_bin=63,因为它通常不会显著影响大型数据集上的训练精度,但GPU训练速度可以显著快于使用默认的255个分箱大小。对于某些数据集,甚至使用15个分箱就足够了(max_bin=15);使用15个分箱将最大化GPU性能。请确保检查运行日志并验证使用了所需的分箱数。尽可能使用单精度训练(
gpu_use_dp=false),因为大多数GPU(尤其是NVIDIA消费级GPU)的双精度性能较差。
性能比较
我们评估了以下数据集上GPU加速的训练性能:
数据 |
任务 |
链接 |
#示例 |
#特性 |
注释 |
|---|---|---|---|---|---|
希格斯 |
二元分类 |
10,500,000 |
28 |
使用最后500,000个样本作为测试集 |
|
Epsilon |
二元分类 |
400,000 |
2,000 |
使用提供的测试集 |
|
博世 |
二元分类 |
1,000,000 |
968 |
使用提供的测试集 |
|
雅虎 左到右 |
学习排序 |
473,134 |
700 |
set1.train 作为 train, set1.test 作为 test |
|
MS LTR |
学习排序 |
2,270,296 |
137 |
{S1,S2,S3} 作为训练集,{S5} 作为测试集 |
|
博览会 |
二元分类(分类) |
11,000,000 |
700 |
使用最后1,000,000作为测试集 |
我们使用了以下硬件来评估 LightGBM GPU 训练的性能。我们的 CPU 参考是 一台高端双插槽 Haswell-EP Xeon 服务器,配备 28 个核心;GPU 包括一块预算型 GPU(RX 480)和一块主流 GPU(GTX 1080),安装在同一台服务器上。值得一提的是,所使用的 GPU 并非市场上最好的 GPU;如果你使用的是更好的 GPU(如 AMD RX 580、NVIDIA GTX 1080 Ti、Titan X Pascal、Titan Xp、Tesla P100 等),你可能会获得更好的加速效果。
硬件 |
峰值FLOPS |
峰值内存带宽 |
成本(建议零售价) |
|---|---|---|---|
AMD Radeon RX 480 |
5,161 GFLOPS |
256 GB/s |
$199 |
NVIDIA GTX 1080 |
8,228 GFLOPS |
320 GB/s |
$499 |
2x Xeon E5-2683v3 (28 核心) |
1,792 GFLOPS |
133 GB/s |
$3,692 |
在CPU上进行基准测试时,我们仅使用了CPU的28个物理核心,并未使用超线程核心,因为我们发现使用过多线程实际上会降低性能。以下是我们使用的训练配置:
max_bin = 63
num_leaves = 255
num_iterations = 500
learning_rate = 0.1
tree_learner = serial
task = train
is_training_metric = false
min_data_in_leaf = 1
min_sum_hessian_in_leaf = 100
ndcg_eval_at = 1,3,5,10
device = gpu
gpu_platform_id = 0
gpu_device_id = 0
num_thread = 28
我们使用上述配置,除了 Bosch 数据集,我们使用较小的 learning_rate=0.015 并设置 min_sum_hessian_in_leaf=5。对于所有 GPU 训练,我们改变最大分箱数(255、63 和 15)。GPU 实现来自 LightGBM 的提交 0bb4a82,当时 GPU 支持刚刚合并。
下表列出了CPU和GPU学习者在500次迭代后在测试集上的准确度。尽管使用单精度算术,具有相同数量箱的GPU可以达到与CPU相似的准确度水平。对于大多数数据集,使用63个箱是足够的。
CPU 255 个区间 |
CPU 63 个箱子 |
CPU 15 个箱子 |
GPU 255 个区间 |
GPU 63 个箱子 |
GPU 15 个箱子 |
|
|---|---|---|---|---|---|---|
希格斯 AUC |
0.845612 |
0.845239 |
0.841066 |
0.845612 |
0.845209 |
0.840748 |
Epsilon AUC |
0.950243 |
0.949952 |
0.948365 |
0.950057 |
0.949876 |
0.948365 |
雅虎-LTR NDCG1 |
0.730824 |
0.730165 |
0.729647 |
0.730936 |
0.732257 |
0.73114 |
雅虎-LTR NDCG3 |
0.738687 |
0.737243 |
0.736445 |
0.73698 |
0.739474 |
0.735868 |
雅虎-LTR NDCG5 |
0.756609 |
0.755729 |
0.754607 |
0.756206 |
0.757007 |
0.754203 |
雅虎-LTR NDCG10 |
0.79655 |
0.795827 |
0.795273 |
0.795894 |
0.797302 |
0.795584 |
Expo AUC |
0.776217 |
0.771566 |
0.743329 |
0.776285 |
0.77098 |
0.744078 |
MS-LTR NDCG1 |
0.521265 |
0.521392 |
0.518653 |
0.521789 |
0.522163 |
0.516388 |
MS-LTR NDCG3 |
0.503153 |
0.505753 |
0.501697 |
0.503886 |
0.504089 |
0.501691 |
MS-LTR NDCG5 |
0.509236 |
0.510391 |
0.507193 |
0.509861 |
0.510095 |
0.50663 |
MS-LTR NDCG10 |
0.527835 |
0.527304 |
0.524603 |
0.528009 |
0.527059 |
0.524722 |
博世 AUC |
0.718115 |
0.721791 |
0.716677 |
0.717184 |
0.724761 |
0.717005 |
我们在500次迭代后记录了挂钟时间,如下图所示:
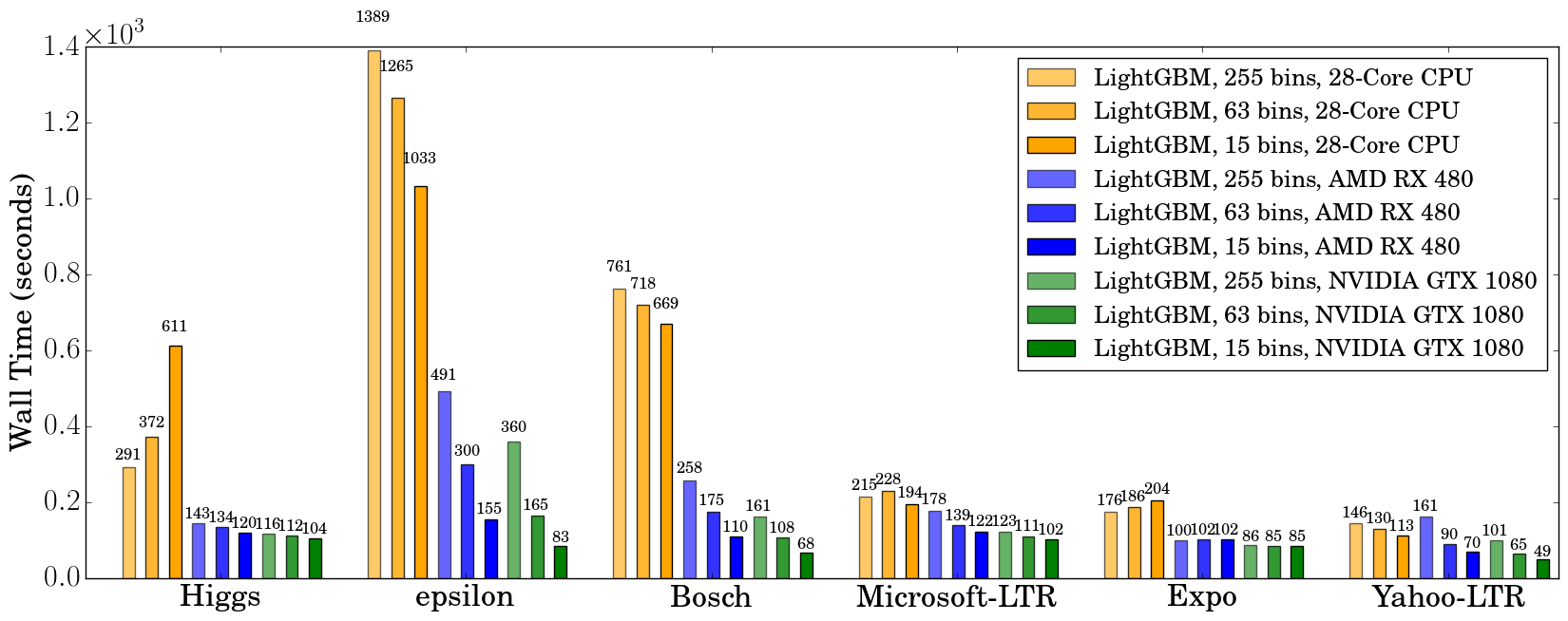
在使用GPU时,建议使用63的bin大小而不是255,因为它可以在不影响准确性的情况下显著加快训练速度。在CPU上,使用较小的bin大小只能略微提高性能,有时甚至会减慢训练速度,例如在Higgs数据集上(我们可以在两台不同机器上,使用不同版本的GCC重现同样的减速)。我们发现,GPU在大而密集的数据集如Higgs和Epsilon上可以实现令人印象深刻的加速。即使在较小和稀疏的数据集上,*预算*GPU仍然可以竞争,并且比28核Haswell服务器更快。
内存使用
下表显示了在使用63个bin进行训练期间,``nvidia-smi``报告的GPU内存使用情况。我们可以看到,即使是最大的数据集也仅使用了大约1 GB的GPU内存,这表明我们的GPU实现可以扩展到比Bosch或Epsilon大10倍以上的巨大数据集。此外,我们还可以观察到,通常较大的数据集(使用更多GPU内存,如Epsilon或Bosch)具有更好的加速效果,因为在数据集较小时,调用GPU函数的开销变得显著。
数据集 |
希格斯 |
Epsilon |
博世 |
MS-LTR |
博览会 |
Yahoo-LTR |
|---|---|---|---|---|---|---|
GPU 内存使用量 (MB) |
611 |
901 |
1067 |
413 |
405 |
291 |
进一步阅读
你可以在以下文章中找到更多关于GPU算法和基准测试的详细信息:
Huan Zhang, Si Si 和 Cho-Jui Hsieh。GPU 加速大规模树提升。SysML 会议,2018。