bar 图
本笔记本旨在演示(并记录)如何使用 shap.plots.bar 函数。它使用了一个在经典的 UCI 成人收入数据集上训练的 XGBoost 模型(这是一个预测90年代人们收入是否超过50k的分类任务)。
[1]:
import xgboost
import shap
# train XGBoost model
X, y = shap.datasets.adult(n_points=2000)
model = xgboost.XGBClassifier().fit(X, y)
# compute SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
全局条形图
将SHAP值矩阵传递给条形图函数会创建一个全局特征重要性图,其中每个特征的全局重要性被认为是该特征在所有给定样本中的平均绝对值。
[2]:
shap.plots.bar(shap_values)
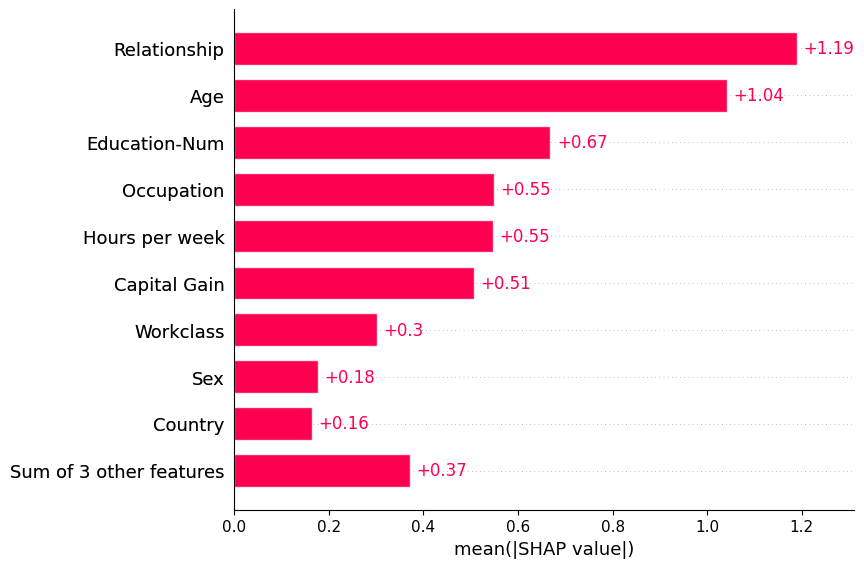
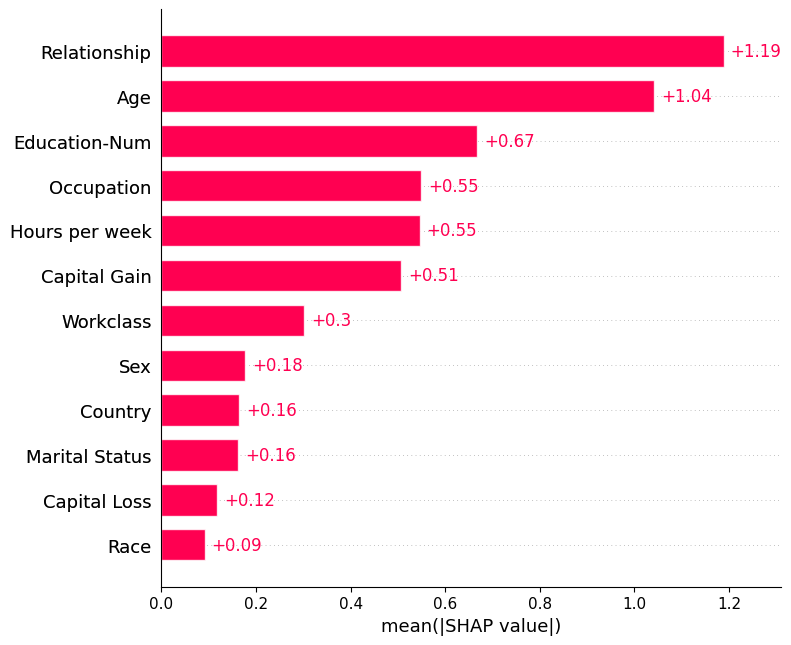
默认情况下,条形图最多显示十个条形,但可以通过 max_display 参数进行控制:
[3]:
shap.plots.bar(shap_values, max_display=12)
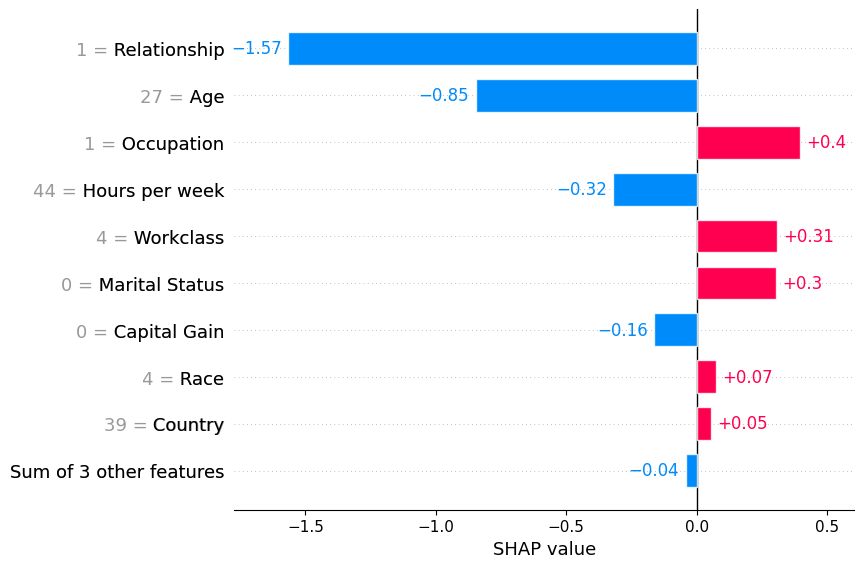
本地条形图
将一行 SHAP 值传递给条形图函数会创建一个局部特征重要性图,其中条形代表每个特征的 SHAP 值。请注意,特征值以灰色显示在特征名称的左侧。
[4]:
shap.plots.bar(shap_values[0])
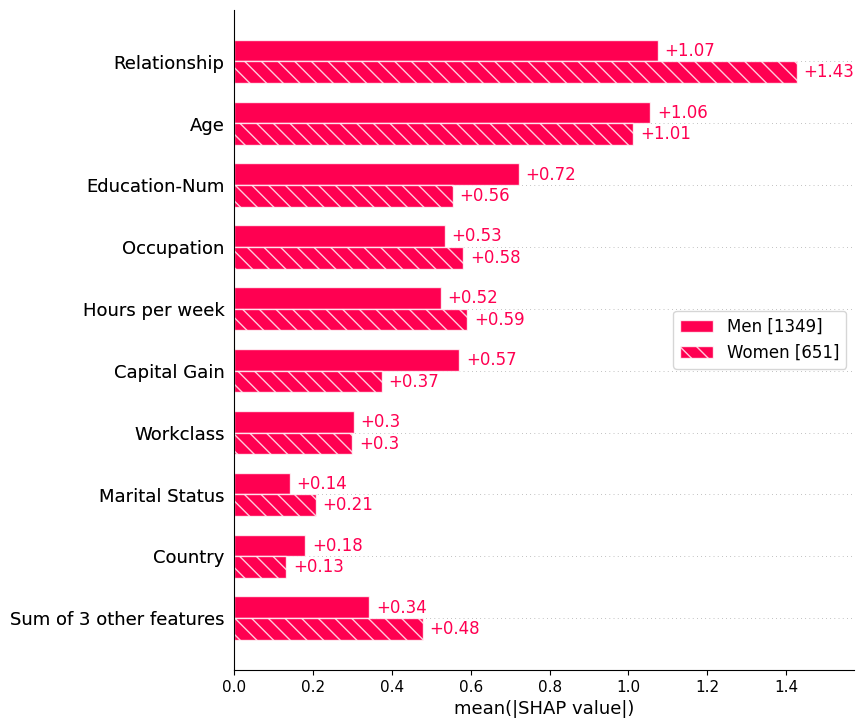
队列条形图
传递一个包含Explanation对象的字典将创建一个多条形图,每个条形代表由解释对象表示的每个队列。下面我们使用这个方法分别绘制男性和女性的特征重要性的全局总结。
[5]:
sex = [
"Women" if shap_values[i, "Sex"].data == 0 else "Men"
for i in range(shap_values.shape[0])
]
shap.plots.bar(shap_values.cohorts(sex).abs.mean(0))
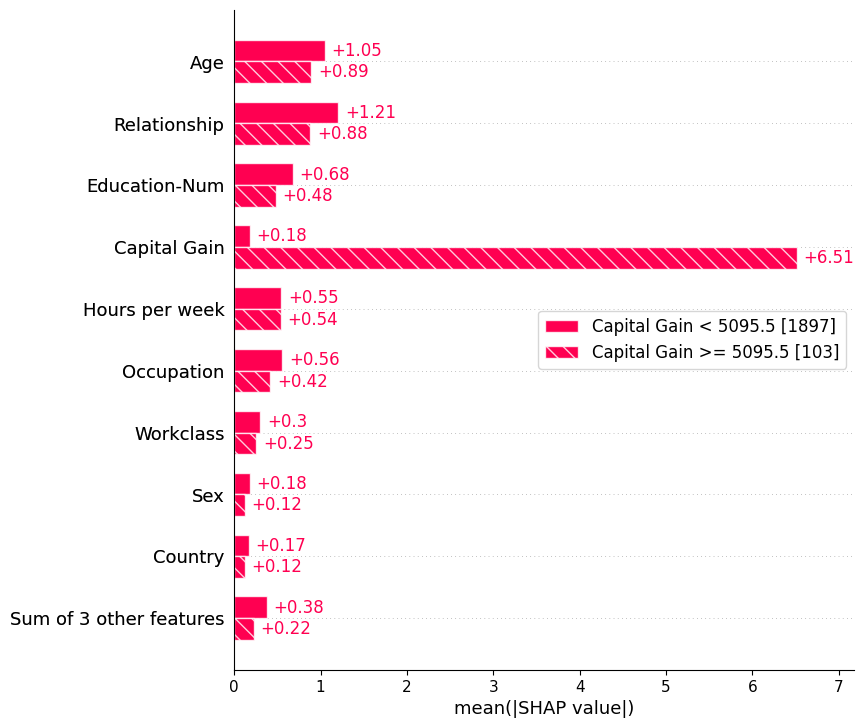
我们还可以使用 Explanation 对象的自动分组功能,通过决策树创建一组分组。调用 Explanation.cohorts(N) 将创建 N 个分组,这些分组使用 sklearn 的 DecisionTreeRegressor 最优地分离实例的 SHAP 值。如果我们对成人普查数据执行此操作,那么我们将看到低资本收益与高资本收益之间的明显分离。请注意,括号中的数字是每个分组中的实例数量。
[6]:
shap.plots.bar(shap_values.cohorts(2).abs.mean(0))
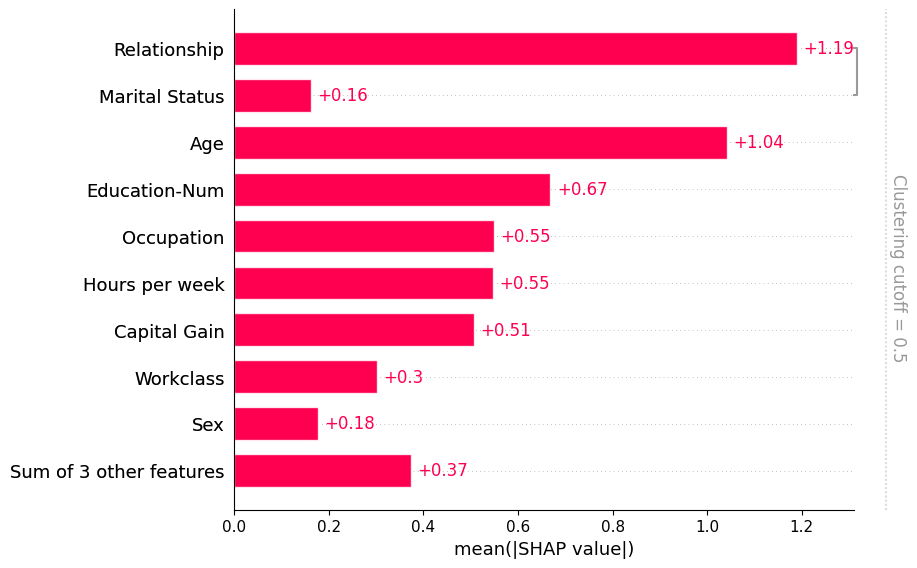
使用特征聚类
数据集中的特征通常部分或完全相互冗余。冗余意味着模型可以使用任一特征并仍能获得相同的准确性。为了找到这些特征,从业者通常会计算特征之间的相关矩阵,或使用某种聚类方法。在使用SHAP时,我们推荐一种更直接的方法,通过模型损失比较来衡量特征冗余。shap.utils.hclust 方法可以做到这一点,并通过训练XGBoost模型来预测每对输入特征的结果,构建特征的层次聚类。对于典型的表格数据集,这种方法比无监督方法(如相关性)得到更准确的特征冗余度量。
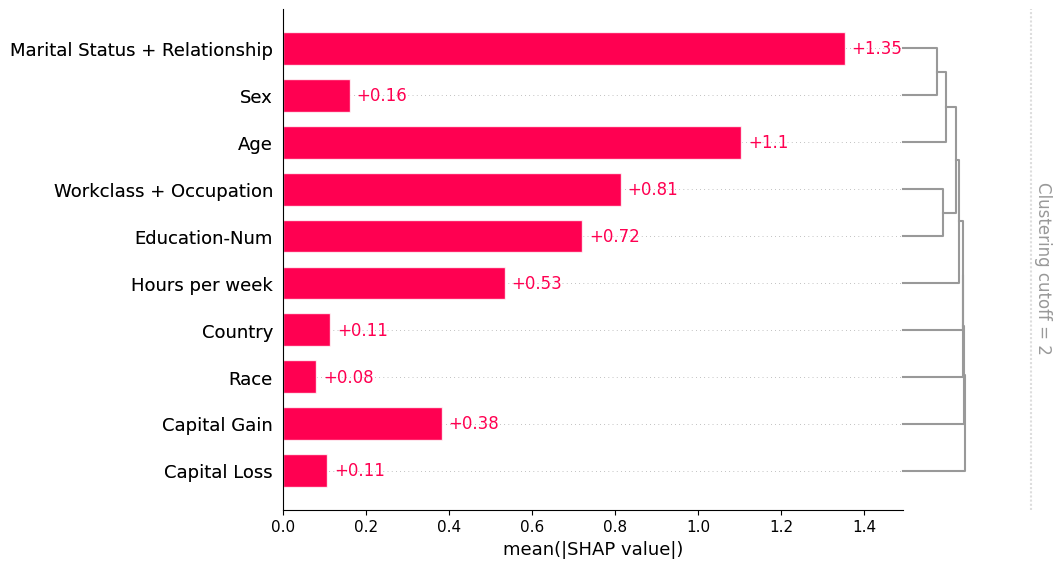
一旦我们计算出这样的聚类,我们就可以将其传递给条形图,以便同时可视化特征冗余结构和特征重要性。请注意,默认情况下我们不会显示所有的聚类结构,而只显示距离 < 0.5 的聚类部分。聚类中的距离假设在大约 0 到 1 之间缩放,其中 0 距离表示特征完全冗余,1 表示它们完全独立。在下图中,我们看到只有关系和婚姻状况的冗余度超过 50%,因此它们是条形图中唯一被分组的特征:
[7]:
# by default this trains (X.shape[1] choose 2) 2-feature XGBoost models
clustering = shap.utils.hclust(X, y)
shap.plots.bar(shap_values, clustering=clustering)
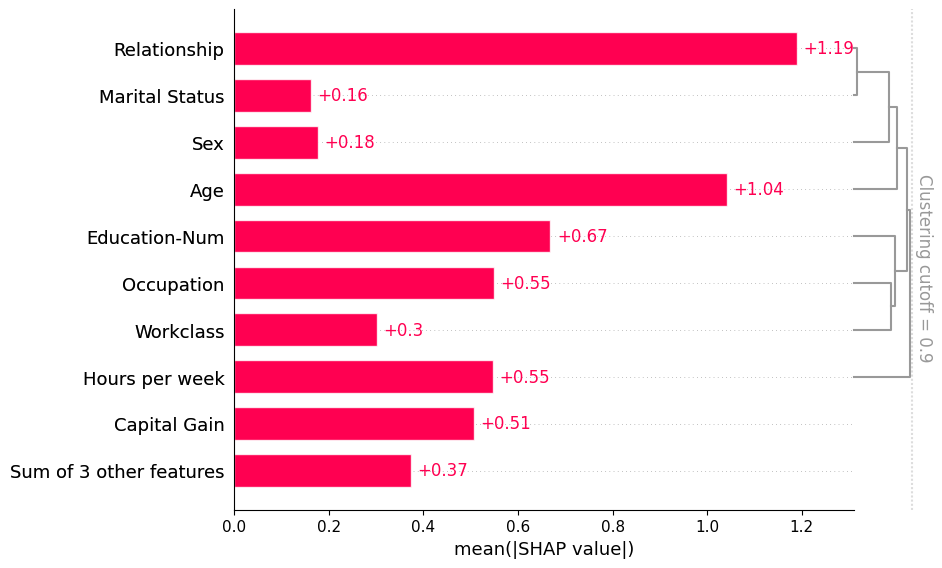
如果我们想看到更多的聚类结构,我们可以将 clustering_cutoff 参数从 0.5 调整到 0.9。请注意,随着我们提高阈值,我们将特征的排序限制为遵循有效的聚类叶顺序。条形图会按照每个聚类和子聚类的特征重要性值对该聚类进行排序,试图将最重要的特征放在顶部。
[8]:
shap.plots.bar(shap_values, clustering=clustering, clustering_cutoff=0.9)
请注意,一些解释器在解释过程中使用聚类结构。他们这样做既是为了在解释模型时避免以不现实的方式扰动特征,也是为了计算性能的考虑。当你使用这些方法计算SHAP解释时,它们会附带一个聚类在Explanation对象中。当条形图发现这样的聚类时,它会使用它,而你不需要通过``clustering``参数显式传递它:
[9]:
# only model agnostic methods support shap.maskers.TabularPartitions right now so we wrap our model as a function
def f(x):
return model.predict(x, output_margin=True)
# define a partition masker that uses our clustering
masker = shap.maskers.Partition(X, clustering=clustering)
# explain the model again
explainer = shap.Explainer(f, masker)
shap_values_partition = explainer(X[:100])
[10]:
shap.plots.bar(shap_values_partition)
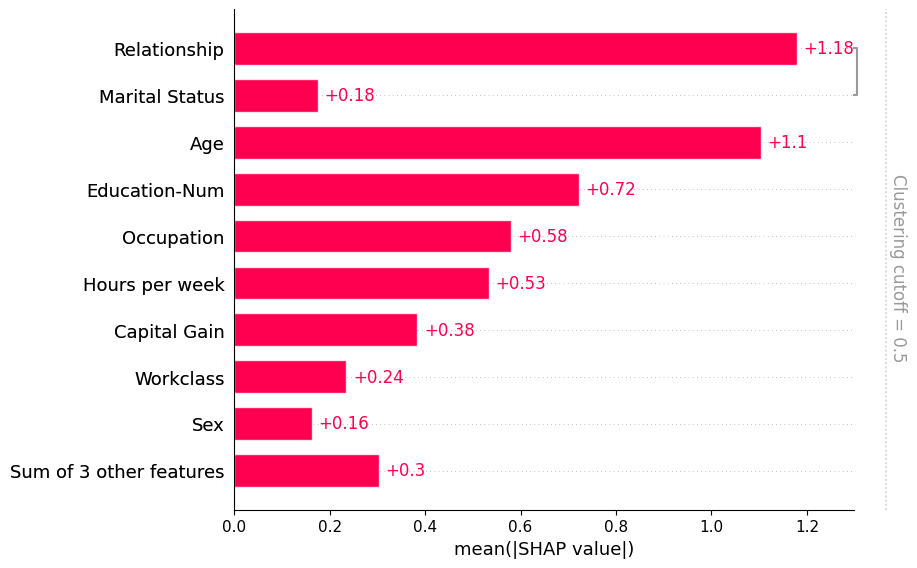
[11]:
shap.plots.bar(shap_values_partition, clustering_cutoff=2)
[12]:
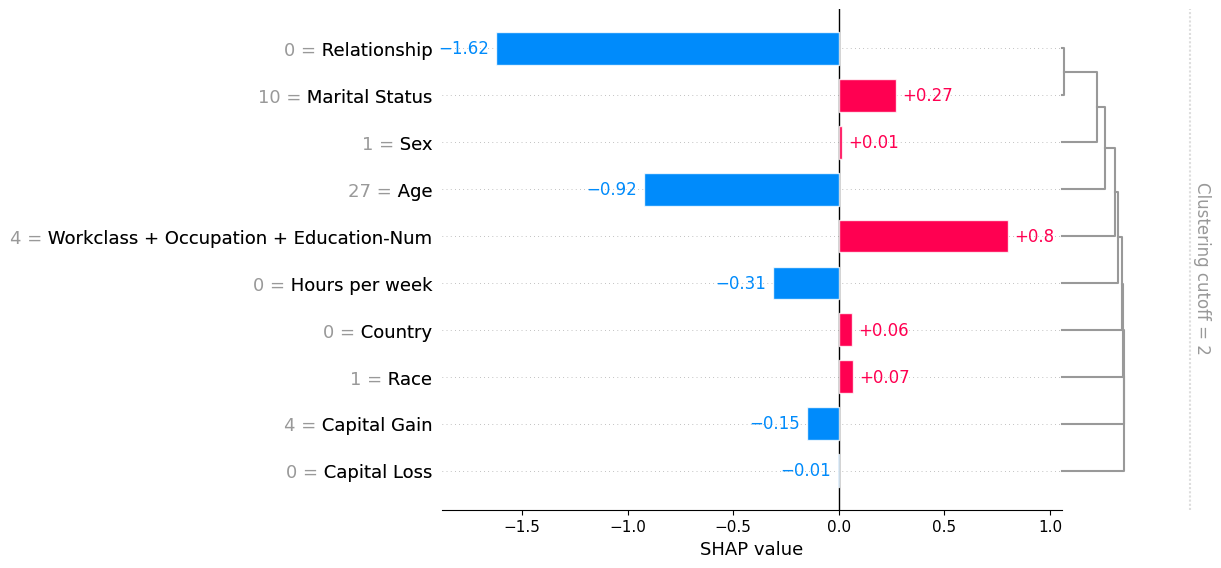
shap.plots.bar(shap_values_partition[0], clustering_cutoff=2)
有更多有用示例的想法吗?我们鼓励提交增加此文档笔记本的拉取请求!