decision 图
目录
1 SHAP 决策图
1.1 加载数据集并训练模型
1.2 计算 SHAP 值
2 基本决策图功能
3 决策图何时有用?
3.1 清晰展示大量特征效果
3.2 可视化多输出预测
3.3 展示交互的累积效应
3.4 探索一系列特征值的特征效果
3.5 识别异常值
3.6 识别典型的预测路径
3.7 比较和对比多个模型的预测
4 SHAP 交互值
5 在图表之间保持顺序和比例
6 选择显示的特征
7 更改 SHAP 基值
SHAP 决策图
SHAP 决策图展示了复杂模型如何得出它们的预测(即模型如何做出决策)。本笔记本通过简单的示例说明了决策图的功能和用例。如需更详细的叙述,点击这里。
加载数据集并训练模型
在大多数示例中,我们使用在 UCI Adult Income 数据集上训练的 LightGBM 模型。目标:预测个人年收入是否超过 $50K。
[1]:
import pickle
import warnings
from pprint import pprint
import lightgbm as lgb
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import StratifiedKFold, train_test_split
import shap
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)
# create a train/test split
random_state = 7
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=random_state
)
d_train = lgb.Dataset(X_train, label=y_train)
d_test = lgb.Dataset(X_test, label=y_test)
params = {
"max_bin": 512,
"learning_rate": 0.05,
"boosting_type": "gbdt",
"objective": "binary",
"metric": "binary_logloss",
"num_leaves": 10,
"verbose": -1,
"min_data": 100,
"boost_from_average": True,
"random_state": random_state,
}
model = lgb.train(
params,
d_train,
10000,
valid_sets=[d_test],
early_stopping_rounds=50,
verbose_eval=1000,
)
Training until validation scores don't improve for 50 rounds.
Early stopping, best iteration is:
[683] valid_0's binary_logloss: 0.277144
计算 SHAP 值
计算前20个测试观测值的SHAP值和SHAP交互值。
[2]:
explainer = shap.TreeExplainer(model)
expected_value = explainer.expected_value
if isinstance(expected_value, list):
expected_value = expected_value[1]
print(f"Explainer expected value: {expected_value}")
select = range(20)
features = X_test.iloc[select]
features_display = X_display.loc[features.index]
with warnings.catch_warnings():
warnings.simplefilter("ignore")
shap_values = explainer.shap_values(features)[1]
shap_interaction_values = explainer.shap_interaction_values(features)
if isinstance(shap_interaction_values, list):
shap_interaction_values = shap_interaction_values[1]
Explainer expected value: -2.4296968952292404
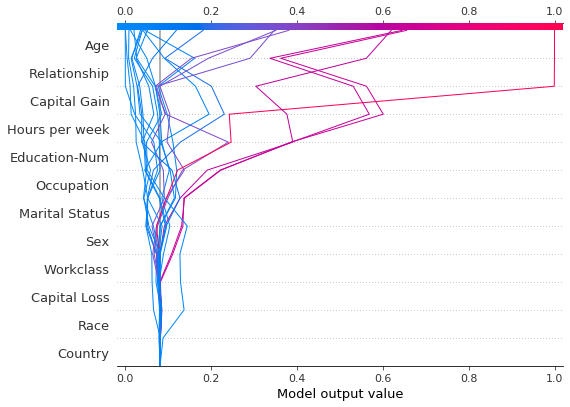
基本决策图特征
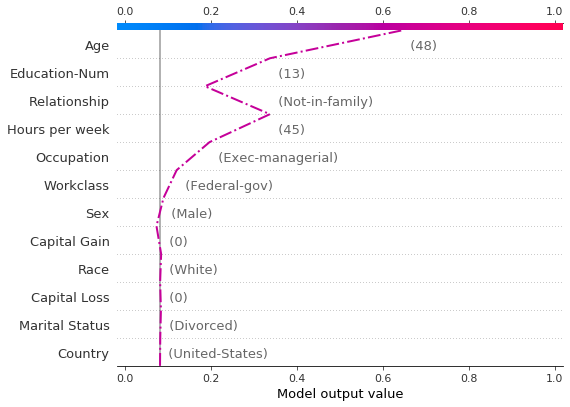
参考下面的20个测试观测值的决策图。注意:这个图本身并不具有信息量;我们仅用它来阐释主要概念。 * x轴表示模型的输出。在这种情况下,单位是log odds。 * 图在x轴上以``explainer.expected_value``为中心。所有SHAP值相对于模型的期望值,类似于线性模型的效应相对于截距。 * y轴列出了模型的特征。默认情况下,特征按重要性降序排列。重要性是根据图中绘制的观测值计算的。这通常与整个数据集的重要性排序不同。 除了特征重要性排序外,决策图还支持层次聚类特征排序和用户定义的特征排序。 * 每个观测值的预测由一条彩色线表示。在图的顶部,每条线在其对应观测值的预测值处击中x轴。该值决定了线在光谱上的颜色。 * 从图的底部到顶部,每个特征的SHAP值被添加到模型的基值中。这显示了每个特征如何对整体预测做出贡献。 * 在图的底部,观测值在``explainer.expected_value``处汇聚。
[3]:
shap.decision_plot(expected_value, shap_values, features_display)
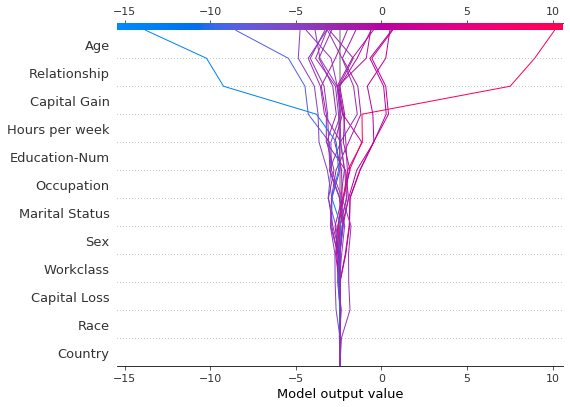
与力图类似,决策图支持 link='logit' 将对数几率转换为概率。
[4]:
shap.decision_plot(expected_value, shap_values, features_display, link="logit")
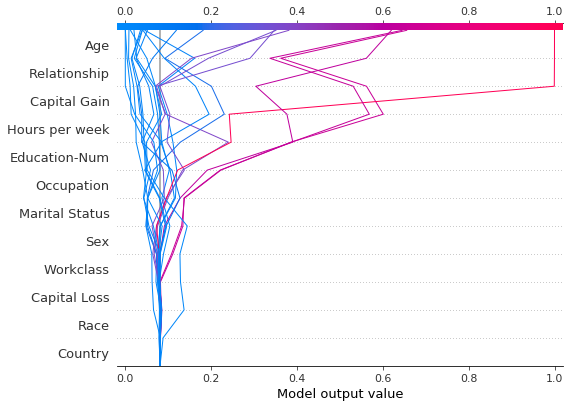
可以使用虚线样式突出显示观察结果。在这里,我们突出显示了一个被错误分类的观察结果。
[5]:
# Our naive cutoff point is zero log odds (probability 0.5).
y_pred = (shap_values.sum(1) + expected_value) > 0
misclassified = y_pred != y_test[select]
shap.decision_plot(
expected_value, shap_values, features_display, link="logit", highlight=misclassified
)
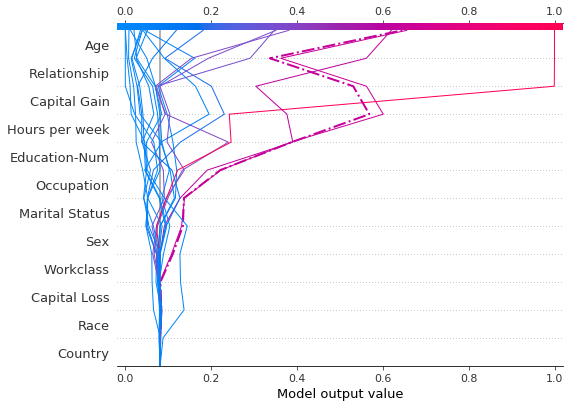
让我们通过单独绘制它来检查被错误分类的观察结果。当单独绘制一个观察结果时,其相应的特征值会被显示出来。注意线条的形状已经改变。为什么?特征顺序在y轴上根据这个单独观察的特征重要性发生了变化。章节“在多个图之间保持顺序和比例”展示了如何为多个图使用相同的特征顺序。
[6]:
shap.decision_plot(
expected_value,
shap_values[misclassified],
features_display[misclassified],
link="logit",
highlight=0,
)
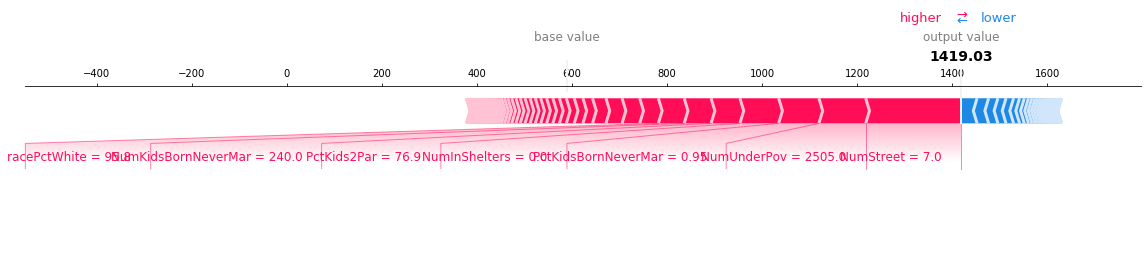
下面显示了错误分类观察的力图。在这种情况下,决策图和力图都能有效地展示模型是如何做出决策的。
[7]:
shap.force_plot(
expected_value,
shap_values[misclassified],
features_display[misclassified],
link="logit",
matplotlib=True,
)

决策图何时有用?
决策图有几种使用场景。我们在这里展示几个案例。1. 清晰展示大量特征效果。2. 可视化多输出预测。3. 展示交互作用的累积效果。4. 探索特征值范围内的特征效果。5. 识别异常值。6. 识别典型的预测路径。7. 比较和对比多个模型的预测。
清晰展示大量功能效果
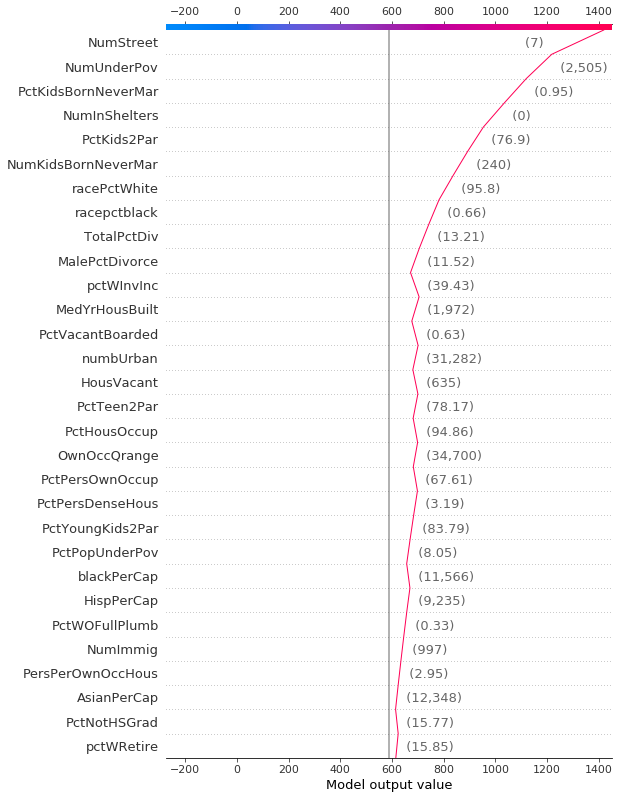
像力图一样,决策图显示了模型输出中涉及的重要特征。然而,当涉及大量重要特征时,决策图可能比力图更有帮助。为了演示,我们使用了一个基于 UCI Communities and Crime 数据集训练的模型。该模型使用了101个特征。下面的两个图描述了相同的预测。力图的水平格式使其无法清晰地显示所有重要特征。相比之下,决策图的垂直格式可以显示任意数量的特征的影响。
[8]:
# Load the prediction from disk to keep the example short.
with open("./data/crime.pickle", "rb") as fl:
a, b, c = pickle.load(fl)
shap.force_plot(a, b, c, matplotlib=True)
[9]:
shap.decision_plot(a, b, c, feature_display_range=slice(None, -31, -1))
可视化多输出预测
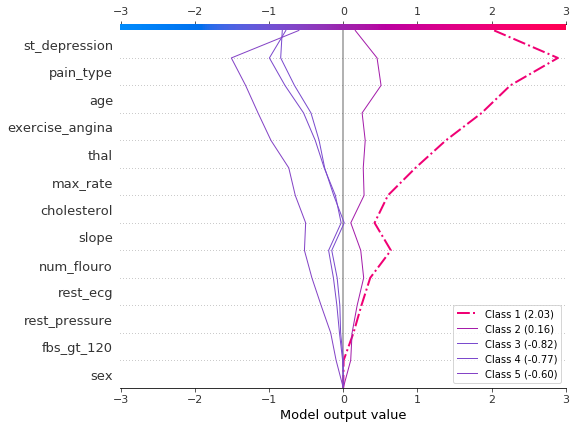
决策图可以展示多输出模型如何得出预测结果。在这个例子中,我们使用了一个在 UCI 心脏病数据集 上训练的 Catboost 模型的 SHAP 值。有五个类别表示疾病的严重程度:类别 1 表示没有疾病;类别 5 表示疾病晚期。
为了保持示例简短,SHAP 值从磁盘加载。变量 heart_base_values 是每个类别的 SHAP 期望值列表。同样,变量 heart_shap_values 是 SHAP 矩阵列表;每个类别对应一个矩阵。这是 shap.TreeExplainer 返回的多输出格式。
[10]:
# Load all from disk to keep the example short.
with open("./data/heart.pickle", "rb") as fl:
(
heart_feature_names,
heart_base_values,
heart_shap_values,
heart_predictions,
) = pickle.load(fl)
class_count = len(heart_base_values)
创建一个生成绘图图例标签的函数。提示:在图例标签中包含预测值,以帮助区分类别。
[11]:
def class_labels(row_index):
return [
f"Class {i + 1} ({heart_predictions[row_index, i].round(2):.2f})"
for i in range(class_count)
]
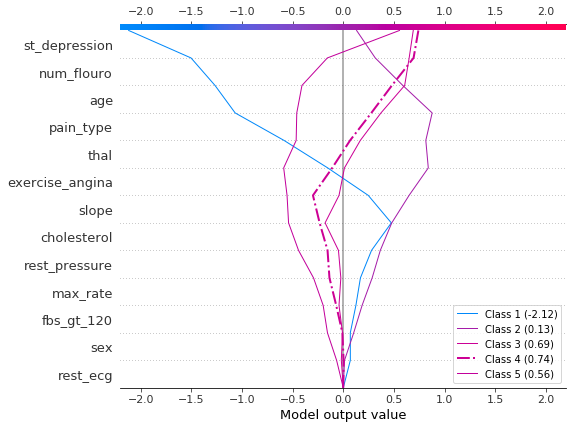
使用 shap.multioutput_decision_plot 绘制观察 #2 的 SHAP 值。图表的默认基值是多输出基值的平均值。SHAP 值相应地进行了调整,以产生准确的预测。虚线(高亮)表示模型的预测类别。对于此观察,模型确信疾病存在,但无法轻易区分类别 3、4 和 5。
[12]:
row_index = 2
shap.multioutput_decision_plot(
heart_base_values,
heart_shap_values,
row_index=row_index,
feature_names=heart_feature_names,
highlight=[np.argmax(heart_predictions[row_index])],
legend_labels=class_labels(row_index),
legend_location="lower right",
)
对于观察 #3,模型自信地预测疾病不存在。
[13]:
row_index = 3
shap.multioutput_decision_plot(
heart_base_values,
heart_shap_values,
row_index=row_index,
feature_names=heart_feature_names,
highlight=[np.argmax(heart_predictions[row_index])],
legend_labels=class_labels(row_index),
legend_location="lower right",
)
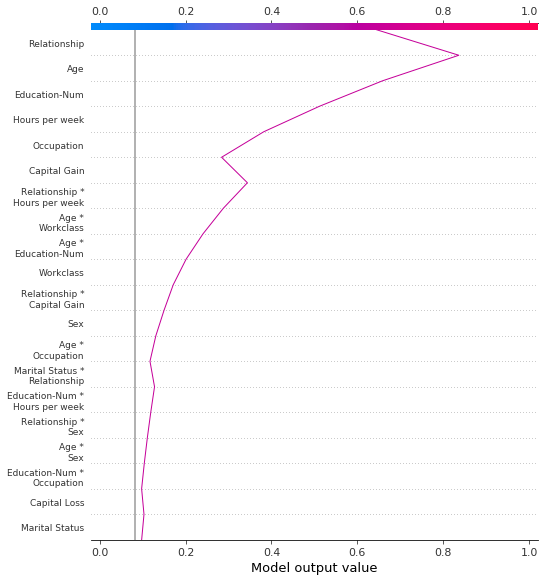
显示交互的累积效应
决策图支持 SHAP 交互值:从基于树的模型中估计的一阶交互。虽然 SHAP 依赖图是可视化个体交互的最佳方式,但决策图可以显示一个或多个观测值的主要效应和交互的累积效应。
这里的决策图解释了使用主效应和交互效应的 UCI Adult Income 数据集中的单个预测。显示了20个最重要的特征。有关对交互效应支持的更多详细信息,请参阅“SHAP交互值”部分。
[14]:
shap.decision_plot(
expected_value,
shap_interaction_values[misclassified],
features_display[misclassified],
link="logit",
)
探索一系列特征值的特征效应
决策图可以揭示预测如何随一组特征值的变化而变化。这种方法对于展示假设情景和揭示模型行为非常有用。在这个例子中,我们创建了仅在资本收益上有所不同的假设观察。
从 UCI 成人收入 数据集的以下参考观察开始。
[15]:
idx = 25
X_display.loc[idx]
[15]:
Age 56
Workclass Local-gov
Education-Num 13
Marital Status Married-civ-spouse
Occupation Tech-support
Relationship Husband
Race White
Sex Male
Capital Gain 0
Capital Loss 0
Hours per week 40
Country United-States
Name: 25, dtype: object
使用参考观测的多个副本来创建一个合成数据集。将’资本收益’的值从$0-$10,000按$100的增量变化。检索相应的SHAP值。这种方法使我们能够评估和调试模型。分析师也可能发现这种方法在展示假设情景时很有用。请记住,本示例中显示的资本收益的影响是针对参考记录的,因此不能被普遍化。
[16]:
rg = range(0, 10100, 100)
R = X.iloc[np.repeat(idx, len(rg))].reset_index(drop=True)
R["Capital Gain"] = rg
with warnings.catch_warnings():
warnings.simplefilter("ignore")
hypothetical_shap_values = explainer.shap_values(R)[1]
hypothetical_predictions = expected_value + hypothetical_shap_values.sum(axis=1)
hypothetical_predictions = 1 / (1 + np.exp(-hypothetical_predictions))
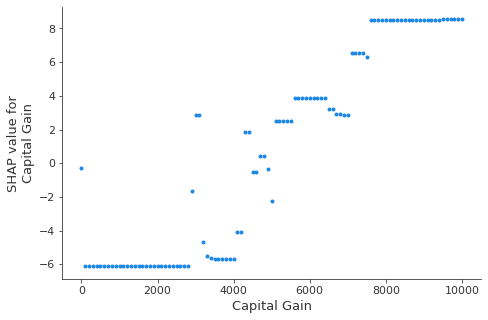
这个依赖图展示了SHAP值在一个特征值范围内的变化。这个模型的SHAP值代表了对数几率的变化。这个图显示在$5,000附近有显著的SHAP值变化。它还显示在$0和大约$3,000处有一些显著的异常值。
[17]:
shap.dependence_plot(
"Capital Gain", hypothetical_shap_values, R, interaction_index=None
)
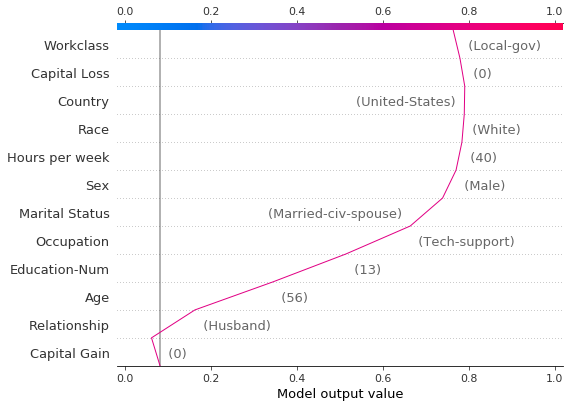
虽然依赖图很有帮助,但在上下文中很难辨别SHAP值的实际效果。为此,我们可以在概率尺度上绘制合成数据集的决策图。首先,我们绘制参考观测值以建立上下文。预测概率为0.76。资本收益为零,模型为此分配了一个小的负效应。特征已手动排序以匹配接下来的两个图。
[18]:
# The feature ordering was determined via 'hclust' on the synthetic data set. We specify the order here manually so
# the following two plots match up.
feature_idx = [8, 5, 0, 2, 4, 3, 7, 10, 6, 11, 9, 1]
shap.decision_plot(
expected_value,
hypothetical_shap_values[0],
X_display.iloc[idx],
feature_order=feature_idx,
link="logit",
)
现在,我们绘制合成数据。参考记录用虚线标记。特征通过层次聚类排序,以将相似的预测路径分组。我们看到,在实际应用中,资本收益的影响在很大程度上是两极分化的;只有少数预测值介于0.2和0.8之间。
[19]:
shap.decision_plot(
expected_value,
hypothetical_shap_values,
R,
link="logit",
feature_order="hclust",
highlight=0,
)
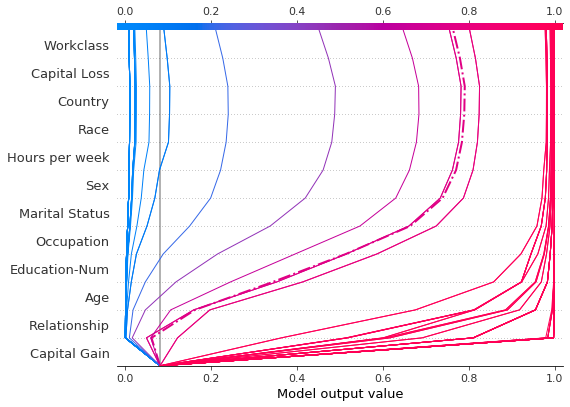
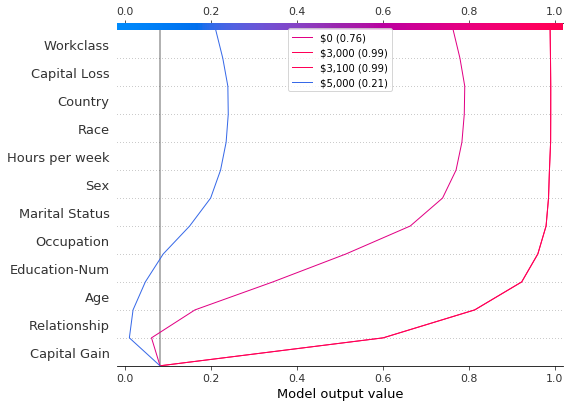
进一步检查预测后,我们发现了一个大约在 $4,300 的阈值,但存在异常。资本收益为 $0, $3,000 和 $3,100 的预测异常高;资本收益为 $5,000 的预测异常低。这些异常在这里用图例标出,以帮助识别每个预测。$3,000 和 $3,100 的预测路径相同。
[20]:
def legend_labels(idx):
return [rf"\${i * 100:,} ({hypothetical_predictions[i]:.2f})" for i in idx]
show_idx = [0, 30, 31, 50]
shap.decision_plot(
expected_value,
hypothetical_shap_values[show_idx],
X,
feature_order=feature_idx,
link="logit",
legend_labels=legend_labels(show_idx),
legend_location="upper center",
)
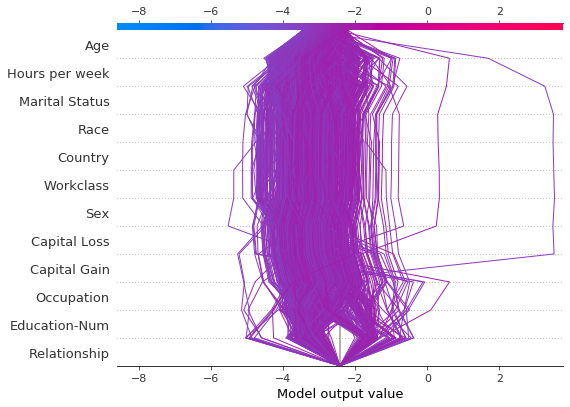
识别异常值
决策图可以帮助识别异常值。指定 feature_order='hclust' 以将具有相似预测路径的观察值分组。这通常使异常值更容易被发现。在绘制异常值时避免使用 link='logit',因为预测的幅度会被 sigmoid 函数扭曲。
下图显示了概率范围 [0.03, 0.1] 内的所有预测。(在此示例中排除了小于 0.03 的预测,因为它们代表大量观察结果。)有两个预测立即引人注目。’年龄’、’资本损失’ 和 ‘资本收益’ 的影响最为显著。
[21]:
y_pred = model.predict(X_test) # Get predictions on the probability scale.
T = X_test[(y_pred >= 0.03) & (y_pred <= 0.1)]
with warnings.catch_warnings():
warnings.simplefilter("ignore")
sh = explainer.shap_values(T)[1]
r = shap.decision_plot(
expected_value, sh, T, feature_order="hclust", return_objects=True
)
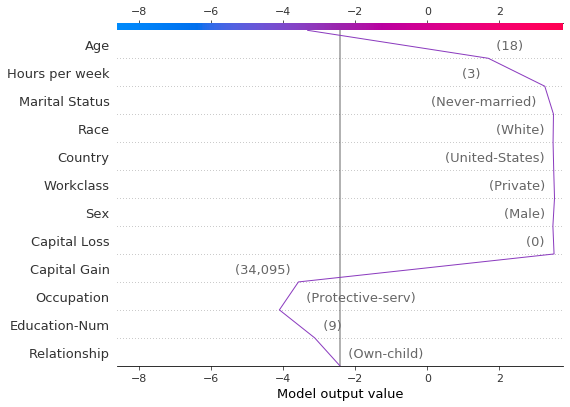
根据SHAP值定位异常值,并根据其特征值绘制它们。异常值的绘制使用与原始图相同的特征顺序和比例。更多详情请参见“在图之间保留顺序和比例”。
[22]:
# Find the two observations with the most negative 'Age' SHAP values.
idx = np.argpartition(sh[:, T.columns.get_loc("Age")], 2)[0:2]
# Plot the observations individually with their corresponding feature values. The plots use the same feature order
# as the original plot.
for i in idx:
shap.decision_plot(
expected_value,
sh[i],
X_display.loc[T.index[i]],
feature_order=r.feature_idx,
xlim=r.xlim,
)
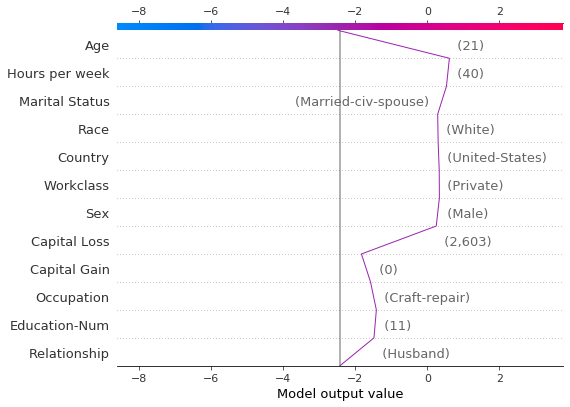
识别典型的预测路径
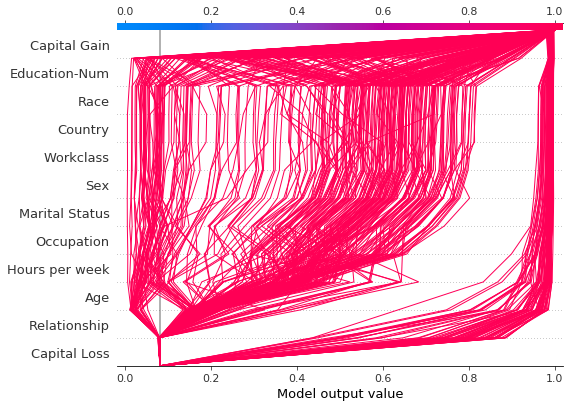
决策图可以揭示模型的典型预测路径。在这里,我们绘制了概率区间 [0.98, 1.0] 内的所有预测,以查看高分预测的共同点。我们使用 'hclust' 特征排序来分组相似的预测路径。该图显示了两条不同的路径:一条由 ‘Capital Gain’ 主导,而另一条由 ‘Capital Loss’ 主导。’Relationship’、’Age’ 和 ‘Education-Num’ 的影响也很显著。
[23]:
y_pred = model.predict(X_test) # Get predictions on the probability scale.
T = X_test[y_pred >= 0.98]
with warnings.catch_warnings():
warnings.simplefilter("ignore")
sh = explainer.shap_values(T)[1]
shap.decision_plot(expected_value, sh, T, feature_order="hclust", link="logit")
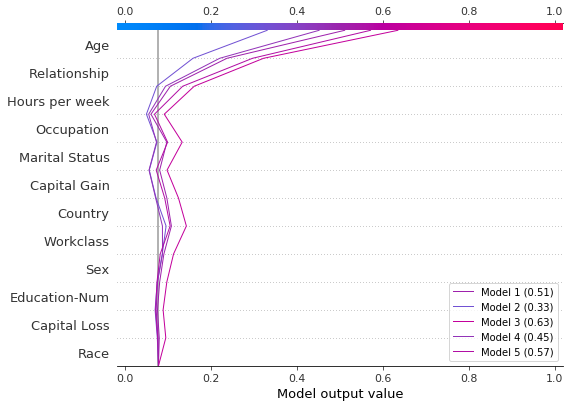
比较和对比几个模型的预测
决策图对于比较不同模型的预测,或解释模型集合的预测非常有用。在这个例子中,我们绘制了在 UCI Adult Income 数据集上训练的五个 LightGBM 模型的预测结果。在这个例子中,我们创建了一个包含五个模型的集合,并使用 shap.multioutput_decision_plot 绘制了这些模型的预测结果。
使用5折交叉验证训练五个LightGBM模型的集成。
[26]:
model_count = 5
skf = StratifiedKFold(model_count, True, random_state=random_state)
models = []
for t, v in skf.split(X, y):
m = lgb.LGBMClassifier(**params, n_estimators=1000)
m.fit(
X.iloc[t],
y[t],
eval_set=(X.iloc[v], y[v]),
early_stopping_rounds=50,
verbose=False,
)
score = m.best_score_["valid_0"]["binary_logloss"]
print(f"Best score: {score}")
models.append(m)
Best score: 0.28279460948508833
Best score: 0.2743920496745268
Best score: 0.2706647518976772
Best score: 0.2809048231217079
Best score: 0.2785044277595166
将模型的基础值和 SHAP 值组合成列表。这模拟了 shap 包对多输出模型的输出。
[27]:
def get_ensemble_shap_values(models, X):
base_values = [None] * model_count
shap_values = [None] * model_count
predictions = [None] * model_count
for i, m in enumerate(models):
a = m.predict(
X, pred_contrib=True
) # `pred_contrib=True` returns SHAP values for LightGBM
base_values[i] = a[0, -1] # The last column in the matrix is the base value.
shap_values[i] = a[:, 0:-1]
predictions[i] = 1 / (
1 + np.exp(-a.sum(axis=1)[0])
) # Predictions as probabilities
return base_values, shap_values, predictions
从集成模型中获取单个观测值的SHAP值。
[28]:
(
ensemble_base_values,
ensemble_shap_values,
ensemble_predictions,
) = get_ensemble_shap_values(models, X.iloc[[27]])
绘制 SHAP 值。图例标识每个模型的预测。提示:在图例标签中包含预测值,以帮助区分模型。
如果概率 0.5 是我们这个二分类任务的截断值,我们可以看到这个观测值很难分类。然而,模型 2 确信该个体每年的收入低于 $50K。如果这是一个典型的观测值,那么可能值得研究为什么这个模型的预测会有所不同。
[29]:
# Create labels for legend
labels = [
f"Model {i + 1} ({ensemble_predictions[i].round(2):.2f})"
for i in range(model_count)
]
# Plot
shap.multioutput_decision_plot(
ensemble_base_values,
ensemble_shap_values,
0,
feature_names=X.columns.to_list(),
link="logit",
legend_labels=labels,
legend_location="lower right",
)
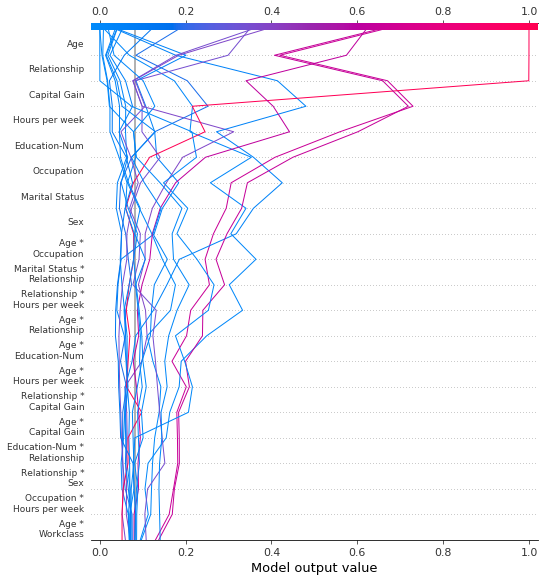
SHAP 交互值
决策图支持如这里所示的SHAP交互值。注意,线条并没有完全在图的底部收敛到 explainer.expected_value。这是因为包括交互和主要效应在内共有N(N + 1)/2 = 12(13)/2 = 78个特征,但决策图默认只显示20个最重要的特征。请参阅“选择要显示的特征”部分,了解如何显示更多特征。
[30]:
shap.decision_plot(expected_value, shap_interaction_values, features, link="logit")
决策图将三维的 SHAP 交互结构转换为标准的二维 SHAP 矩阵。它还会生成相应的特征标签。通过设置 return_objects=True,可以从决策图中检索这些结构。在这个例子中,我们通过设置 show=False 来省略绘图。
[31]:
r = shap.decision_plot(
expected_value,
shap_interaction_values,
features,
link="logit",
show=False,
return_objects=True,
)
plt.close()
print(f"SHAP dimensions: {r.shap_values.shape}", "\n")
pprint(r.feature_names[:-11:-1])
SHAP dimensions: (20, 78)
['Age',
'Relationship',
'Capital Gain',
'Hours per week',
'Education-Num',
'Occupation',
'Marital Status',
'Sex',
'Age *\nOccupation',
'Marital Status *\nRelationship']
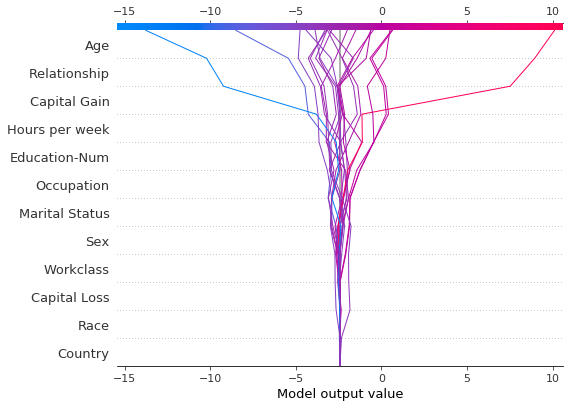
在图表之间保持顺序和比例
通常,使用相同的特征顺序和x轴刻度创建几个决策图有助于直接比较。当 return_objects=True 时,决策图返回可用于后续绘图的绘图结构。
[32]:
# Create the first plot, returning the plot structures.
r = shap.decision_plot(
expected_value, shap_values, features_display, return_objects=True
)
[33]:
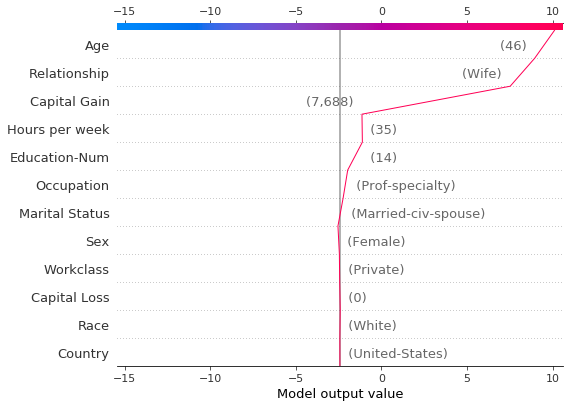
# Create another plot using the same feature order and x-axis extents.
idx = 9
shap.decision_plot(
expected_value,
shap_values[idx],
features_display.iloc[idx],
feature_order=r.feature_idx,
xlim=r.xlim,
)
选择要显示的特征
决策图中显示的特征由两个参数控制:feature_order 和 feature_display_range。feature_order 参数决定了特征在显示前的排序方式。feature_display_range 参数决定了哪些排序后的特征会被显示。它接受一个 slice 或 range 对象作为参数。feature_display_range 参数还控制特征是按升序还是降序绘制。
例如,如果 feature_order='importance'``(默认),决策图在显示前会按重要性*升序*排列特征。如果 ``feature_display_range=slice(-1, -21, -1)``(默认),图表会按降序显示最后(即最重要的)20个特征。对象 ``slice(-1, -21, -1) 被解释为“从最后一个特征开始,以-1为步长迭代到倒数第21个特征。”终点-21不包括在内。
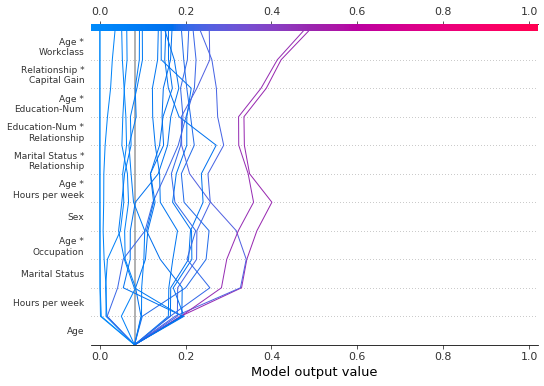
feature_display_range 参数在应用 'hclust' 排序时尤为重要。在这种情况下,许多重要特征位于特征范围的开始部分。然而,决策图默认显示特征范围的末尾。
以下图表展示了使用 'hclust' 排序的78个SHAP交互特征中的前10个。注意:因为我们只显示前10个特征,观察结果不会在其最终预测值处击中x轴。 代码片段 feature_display_range=range(10, -1, -1) 表示我们从特征10开始,以-1为步长计数到特征-1。范围的终点不包括在内。因此,我们看到了特征10到0。
[34]:
shap.decision_plot(
expected_value,
shap_interaction_values,
features,
link="logit",
feature_order="hclust",
feature_display_range=range(10, -1, -1),
)
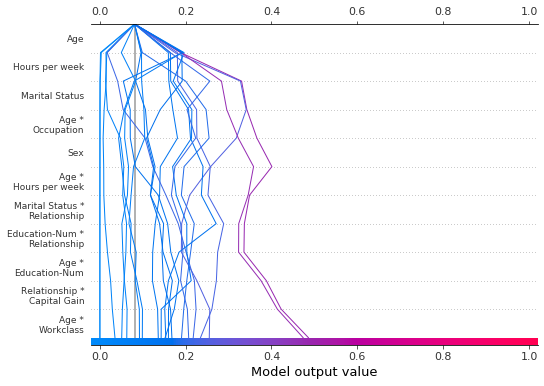
我们可以通过指定一个升序范围来生成相同的图:range(0, 11, 1)。
[35]:
shap.decision_plot(
expected_value,
shap_interaction_values,
features,
link="logit",
feature_order="hclust",
feature_display_range=range(0, 11, 1),
)
在选择范围内的最后几个特征时,使用切片更为方便,因为切片支持负索引。例如,索引 -20 表示从末尾开始的第 20 个项目。以下图表显示了按降序 'hclust' 排列的最后 10 个特征。
[36]:
shap.decision_plot(
expected_value,
shap_interaction_values,
features,
link="logit",
feature_order="hclust",
feature_display_range=slice(None, -11, -1),
)
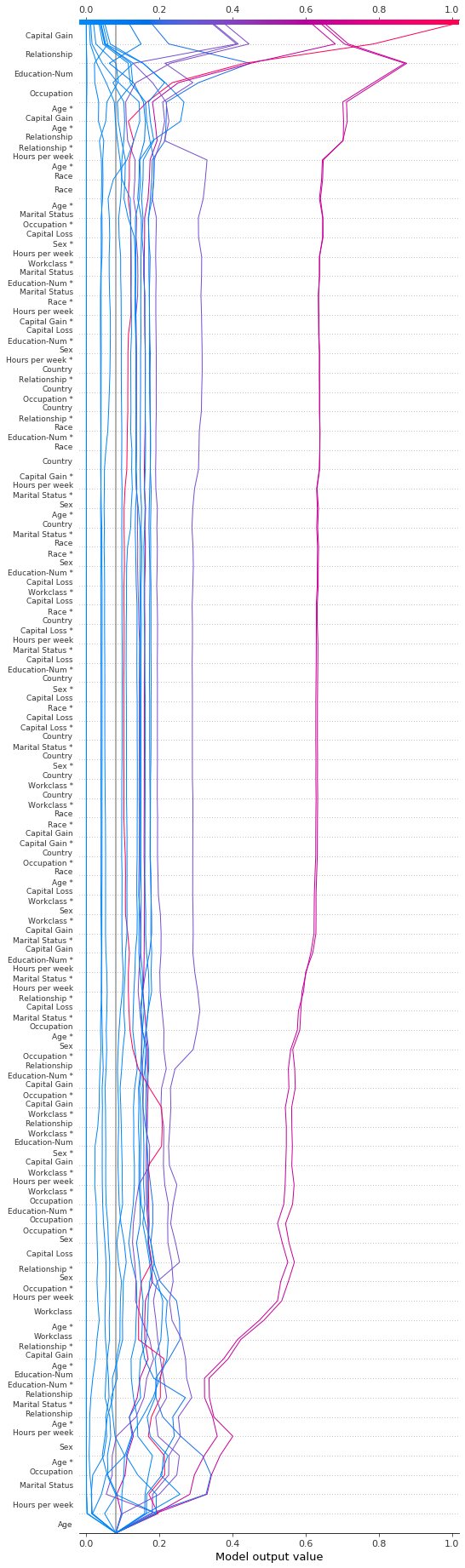
我们可以通过多种方式显示所有可用的功能。最简单的方式是 feature_display_range=slice(None, None, -1)。注意:如果你的数据集包含许多特征,这将生成非常大的图表。
[37]:
shap.decision_plot(
expected_value,
shap_interaction_values,
features,
link="logit",
feature_order="hclust",
feature_display_range=slice(None, None, -1),
)
更改 SHAP 基值
SHAP 值都是相对于某个基准值的。默认情况下,基准值是 explainer.expected_value:训练数据的原始模型预测的均值。
[38]:
# The model's training mean
print(model.predict(X_train, raw_score=True).mean().round(4))
# The explainer expected value
print(expected_value.round(4))
-2.4297
-2.4297
要获得原始预测值,将 explainer.expected_value 加上每个观测值的 SHAP 值之和。
[39]:
# The model's raw prediction for the first observation.
print(model.predict(features.iloc[[0]].values, raw_score=True)[0].round(4))
# The corresponding sum of the mean + shap values
print((expected_value + shap_values[0].sum()).round(4))
-3.1866
-3.1866
因此,必须向决策图提供 explainer.expected_value 以生成正确的预测。
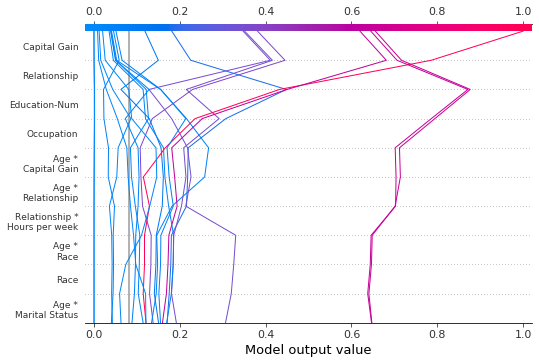
在决策图中,基值是每个预测在图底部的起始值。使用 explainer.expected_value 作为基值并不总是视觉上直观的。考虑一个逻辑分类问题。如果我们选择概率 0.4 作为我们的截止值,如果预测在截止点收敛而不是 explainer.expected_value,可能会更有意义。为此,决策图提供了 new_base_value 参数。它将 SHAP 基值移动到一个任意点,而不改变预测值。
在这个例子中,我们将概率 0.4 指定为新的基准值。因为我们的模型的 SHAP 值是以对数几率表示的,所以在传递给决策图之前,我们将概率转换为对数几率。link='logit' 参数将基准值和 SHAP 值转换为概率。
[40]:
p = 0.4 # Probability 0.4
new_base_value = np.log(p / (1 - p)) # the logit function
shap.decision_plot(
expected_value,
shap_values,
features_display,
link="logit",
new_base_value=new_base_value,
)
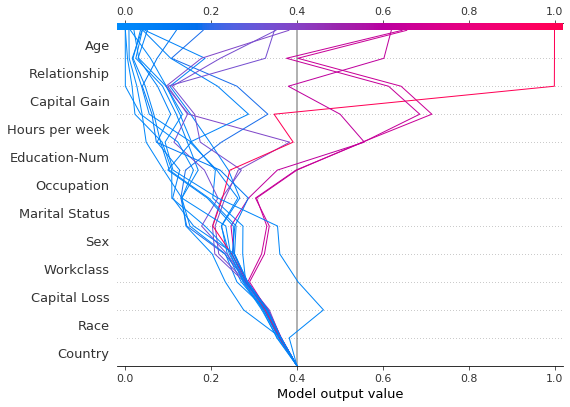
作为对比,这里展示了使用原始基准值的决策图。
[41]:
shap.decision_plot(expected_value, shap_values, features_display, link="logit")