violin 摘要图
本笔记本旨在演示(并记录)如何使用 shap.plots.violin 函数。
它使用了一个在 scikit-learn 库提供的玩具糖尿病数据集上训练的 XGBoost 模型(源 URL: https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html)。
更多信息请参见:https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset。
[10]:
import xgboost
import shap
# train xgboost model on diabetes data:
X, y = shap.datasets.diabetes()
bst = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)
# explain the model's prediction using SHAP values
shap_values = shap.TreeExplainer(bst).shap_values(X)
type(shap_values)
[10]:
numpy.ndarray
简单的提琴图摘要
小提琴摘要图提供了每个特征的SHAP值分布和变异性的紧凑表示。各个小提琴图按特定特征对模型输出的重要性(每个特征的SHAP值绝对值之和)堆叠。
小提琴图使用“小提琴形状”的图形来显示各自特征的SHAP值的分布和密度。因此,小提琴图可以提供关于特定特征的SHAP值分布的范围、变异性、偏度、对称性和多模态性的见解。
总体的小提琴摘要图允许对特征重要性进行比较。较宽的小提琴表示密度更高和更频繁的值,从而提供了关于每个特征相对于模型输出的相对重要性的见解。
[11]:
shap.plots.violin(shap_values)
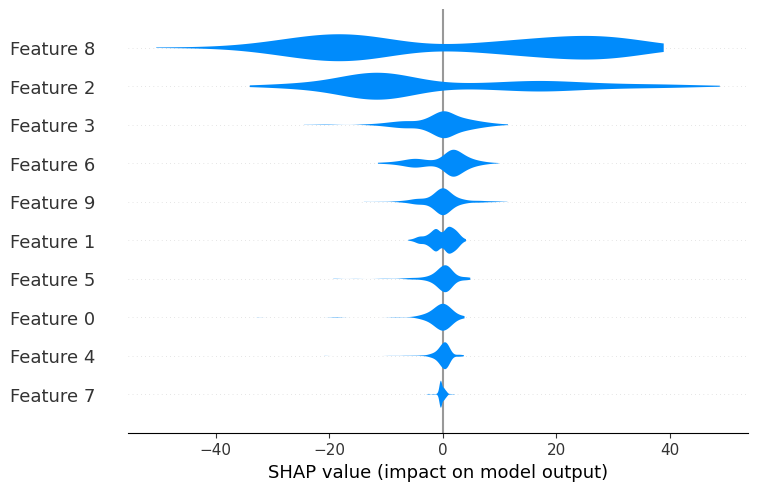
糖尿病数据集中有10个可用特征。
默认情况下,shap.plots.violin 显示的最大特征数量为 20。
小提琴摘要图显示的特征数量可以通过 max_display 参数进行调整:
[12]:
shap.plots.violin(shap_values, max_display=3)
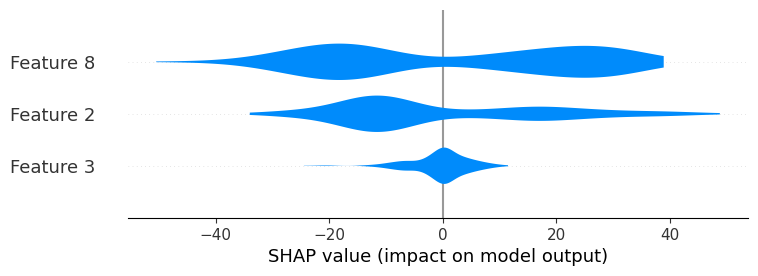
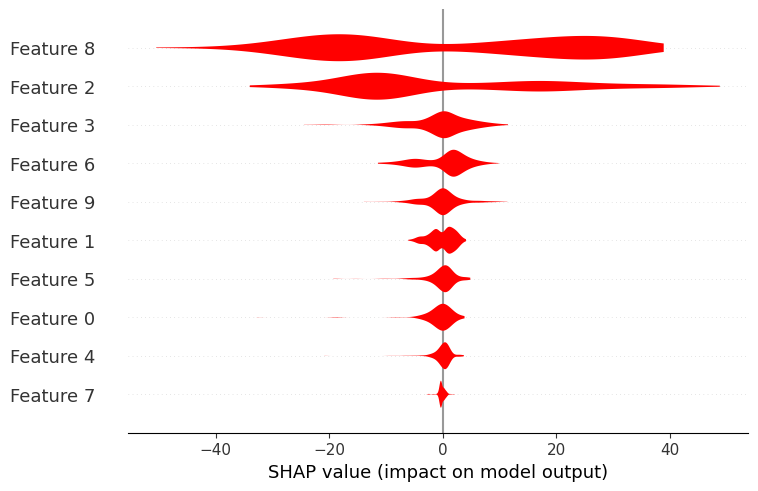
默认情况下,标准小提琴图的颜色为蓝色,但可以使用 color 参数进行更改:
[13]:
shap.plots.violin(shap_values, color="red")
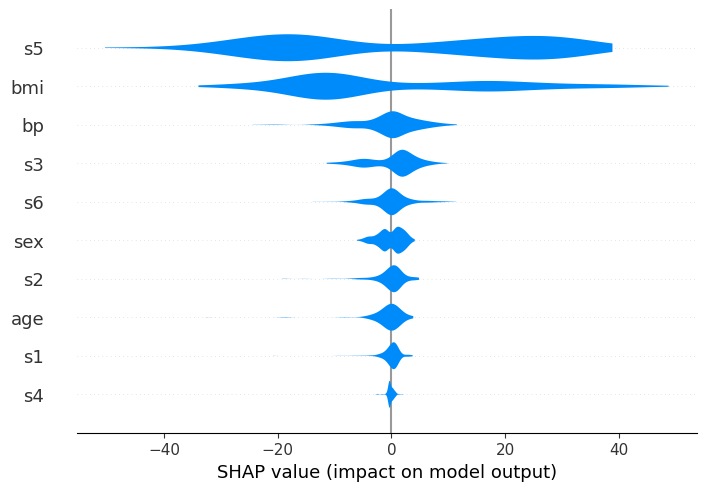
将特征名称作为列表提供可以帮助可视化和解释摘要图:
[14]:
feat_names = list(X.columns)
shap.plots.violin(shap_values, feature_names=feat_names)
分层小提琴图摘要
目前支持两种小提琴图类型:’violin’ 和 ‘layered_violin’。你可以通过 plot_type 参数来控制这一点。
分层小提琴图与小提琴图相同,只是异常值不会绘制为散点,并且它提供了关于特征值(高/低)对数据输出影响的见解。
让我们以糖尿病为例:
我们希望基于我们的数据(X)和计算出的shap_values,绘制一个分层的提琴图总结图。
我们传递的参数包括:- 我们的 shap_values : shap_values - 我们的 features : X - feature_names : feat_names(为了可读性) - 以及感兴趣的 plot_type : “layered_violin”
[15]:
shap.plots.violin(
shap_values, features=X, feature_names=feat_names, plot_type="layered_violin"
)
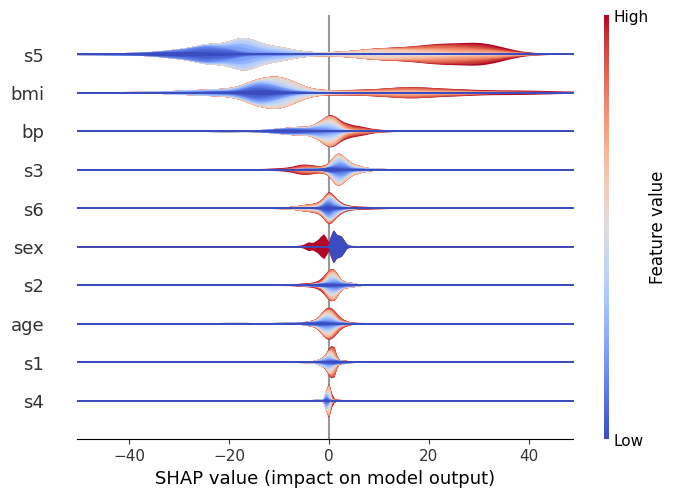
在这种情况下,与标准小提琴类似,我们可以看到 s5 是最重要的变量,并且通常它会导致预测结果发生较大的正向或负向变化。
然而,我们现在也可以从数据中感受到影响的走向。红色代表变量的大值,蓝色代表小值,针对所考虑的特征。
因此,可以看出例如 s5 的大值会增加预测,反之亦然。我们还可以看到其他特征(如 s6)的分布相当均匀,这表明尽管它们总体上仍然重要,但它们的相互作用依赖于其他变量。(毕竟,像 xgboost 这样的树模型的全部意义在于捕捉这些相互作用,所以我们不能期望在单一维度上看到所有内容!)
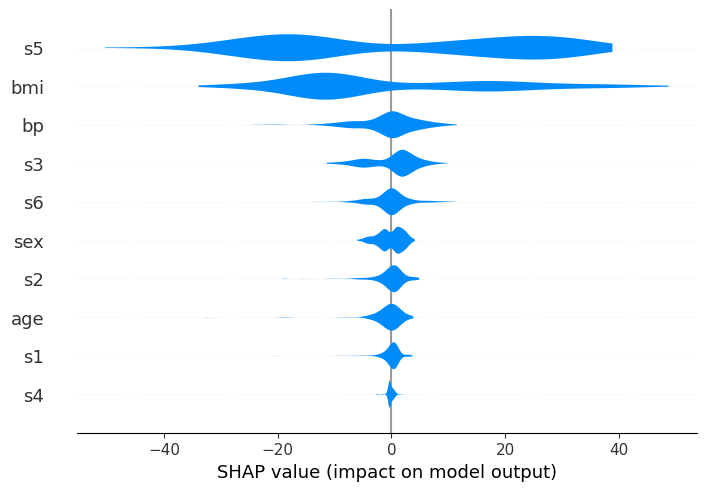
绘图尺寸
最后,使用 plot_size 参数,您可以控制摘要图的大小。默认情况下,大小会根据显示的特征数量自动缩放。
传递一个单一的浮点数将导致每一行的高度为该浮点数英寸。
传递一对浮点数将按该英寸数缩放绘图。
如果传递 None,则当前图形的大小将保持不变。
[16]:
# auto-scaled:
shap.plots.violin(shap_values, feature_names=feat_names)
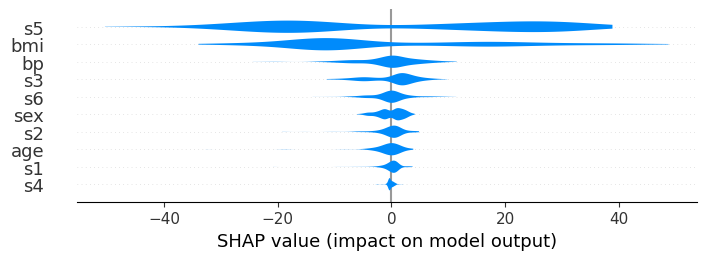
[17]:
# each plot is 0.1 inches
shap.plots.violin(shap_values, feature_names=feat_names, plot_size=0.1)
[18]:
# scale: 1x3 inches
shap.plots.violin(shap_values, feature_names=feat_names, plot_size=(1, 3))
有更多有用示例的想法吗?我们鼓励提交增加此文档笔记本的拉取请求!