
简介:
- 仅通过调整推理参数,如模型、回答数量、温度等,而不改变任何模型权重或提示,高中数学竞赛问题中未调整的gpt-4的基准准确率可以提高20%。
- 对于简单问题,调整后的gpt-3.5-turbo模型在准确性(例如90%对70%)和成本效益方面远远优于未调整的gpt-4。对于困难问题,调整后的gpt-4比未调整的gpt-4更准确(例如35%对20%)且成本更低。
- AutoGen可以帮助LLM应用中的模型选择、参数调整和节省成本。
大型语言模型(LLM)是强大的工具,可以为各种应用生成自然语言文本,例如聊天机器人、摘要、翻译等。GPT-4是目前世界上最先进的LLM。模型选择是否无关紧要?推理参数又如何?
在本篇博文中,我们将使用一个关于MATH的案例研究,探讨模型和推理参数在LLM应用中的重要性。MATH是一个用于评估LLM在高级数学问题解决上的基准测试。MATH包含来自AMC-10、AMC-12和AIME的1.2万个数学竞赛问题。每个问题都附带有逐步解决方案。
我们将使用AutoGen来自动找到给定任务和数据集上LLM的最佳模型和推理参数,同时考虑推理预算,使用一种新颖的低成本搜索和修剪策略。AutoGen目前支持OpenAI的所有LLM,如GPT-3.5和GPT-4。
我们将使用AutoGen进行模型选择和推理参数调整。然后,我们将与未调整的gpt-4比较在解决代数问题上的性能和推理成本。我们还将分析不同难度级别对结果的影响。
实验设置
我们使用AutoGen在目标推理预算为每个实例0.02美元的情况下,在以下模型之间进行选择:
- gpt-3.5-turbo,一种相对便宜的模型,用于推动流行的ChatGPT应用
- gpt-4,代价是gpt-3.5-turbo的10倍以上的最先进LLM
我们使用训练集中的20个示例来调整模型,将问题陈述作为输入,生成解决方案作为输出。我们使用以下推理参数:
- 温度:控制输出文本的随机性的参数。较高的温度意味着更多的多样性但较少的连贯性。我们在[0, 1]的范围内搜索最佳温度。
- top_p: 控制输出标记的概率质量的参数。只有累积概率小于等于 top-p 的标记才会被考虑。较低的 top-p 值意味着更多的多样性但较少的连贯性。我们在 [0, 1] 的范围内搜索最佳的 top-p 值。
- max_tokens: 每个输出可以生成的最大标记数。我们在 [50, 1000] 的范围内搜索最佳的最大长度。
- n: 要生成的响应数量。我们在 [1, 100] 的范围内搜索最佳的 n 值。
- prompt: 我们使用模板:“{problem} 仔细解决问题。尽量简化你的答案。将最终答案放在 \boxed{{}} 中。”其中 {problem} 将被数学问题实例替换。
在这个实验中,当 n > 1 时,我们在所有响应中找到得票最高的答案,然后将其选为最终答案与真实答案进�行比较。例如,如果 n = 5,其中 3 个响应包含最终答案 301,而 2 个响应包含最终答案 159,我们选择 301 作为最终答案。这有助于解决由于随机性而导致的潜在错误。我们使用平均准确率和平均推理成本作为评估数据集性能的指标。特定实例的推理成本由每 1K 标记的价格和消耗的标记数来衡量。
实验结果
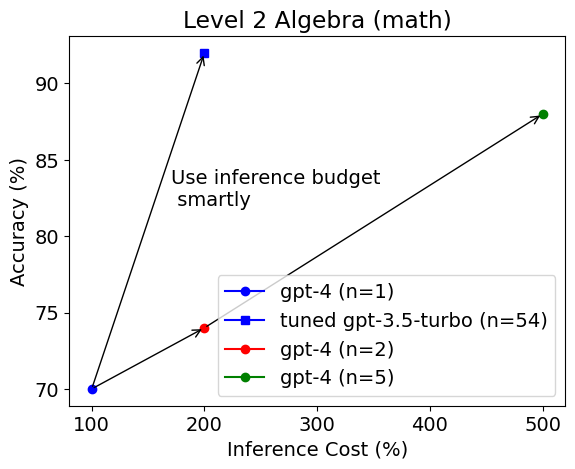
本博文的第一个图显示了在二级代数测试集上每个配置的平均准确率和平均推理成本。
令人惊讶的是,调整后的 gpt-3.5-turbo 模型被选为更好的模型,并且在准确率上远远优于未调整的 gpt-4(92% vs. 70%),而推理预算相等或高出 2.5 倍。 在三级代数测试集上也可以得出同样的观察结果。
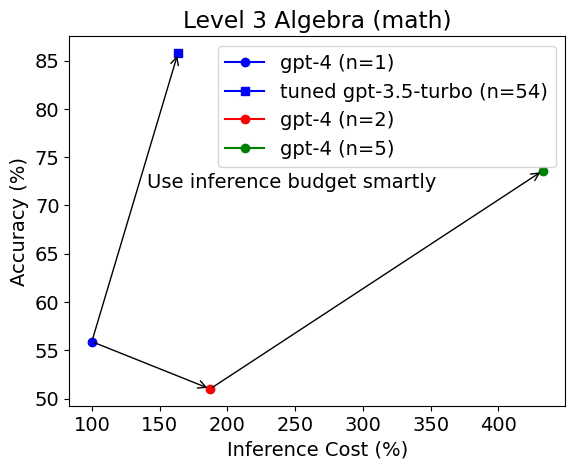
然而,在四级代数中选择的模型发生了变化。
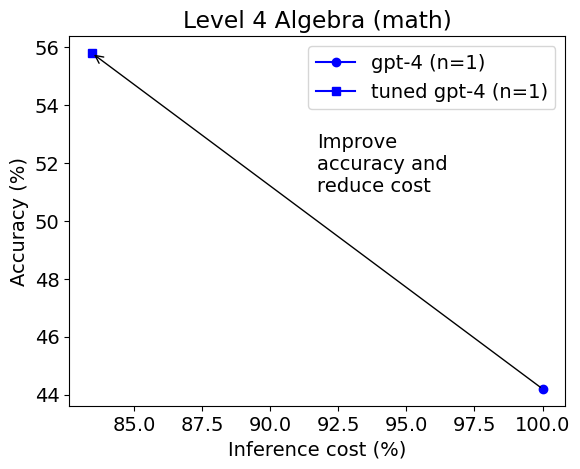
这次选择了 gpt-4 作为最佳模型。调整后的 gpt-4 在准确率上比未调整的 gpt-4 高得多(56% vs. 44%),成本更低。 在五级代数中的结果类似。
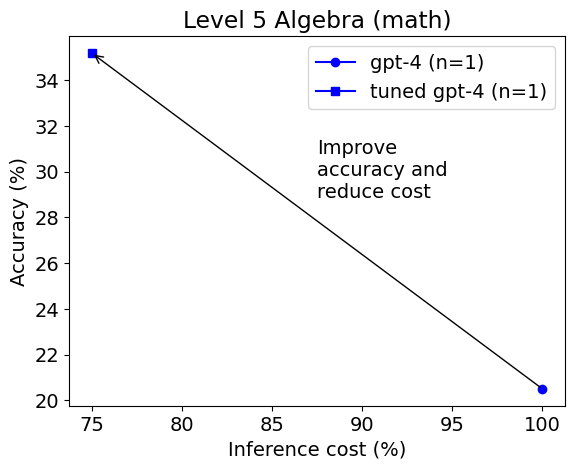
我们可以看到 AutoGen 对于每个特定级别的子集找到了不同的最佳模型和推理参数,这表明这些参数在成本敏感的 LLM 应用中很重要,需要进行仔细调整或适应。
可以在以下链接找到一个运行这些实验的示例笔记本:https://github.com/microsoft/FLAML/blob/v1.2.1/notebook/autogen_chatgpt.ipynb。这些实验是在 AutoGen 是 FLAML 的一个子包时运行的。
分析与讨论
虽然 gpt-3.5-turbo 在相同推理预算下在相对简单的代数问题中展示了与投票答案相竞争的准确性,但对于最困难的问题来说,gpt-4 是更好的选择。一般来说,通过参数调整和模型选择,我们可以确定在更具挑战性的任务中节省昂贵模型的机会,并提高预算受限系统的整体效果。
还有许多其他解决数学问题的替代方法,我们在本博客文章中没有涵盖。当推理参数以外有选择时,可以通过 flaml.tune 进行通常的调整。
对于模型选择、参数调整和成本节约的需求并不局限于数学问题。Auto-GPT 项目就是一个例子,高成本很容易阻止完成通用复杂任务,因为它需要进行多次 LLM 推理调用。
进一步阅读
你有关于 LLM 应用的经验要分享吗?你是否希望看到更多关于 LLM 优化或自动化的支持或研究?请加入我们的 Discord 服务器进行讨论。