

TL;DR: 介绍 AutoBuild,它可以自动、快速、轻松地构建用于复杂任务的多智能体系统,只需最少的用户提示,由新设计的 AgentBuilder 类提供支持。AgentBuilder 还通过利用 vLLM 和 FastChat 支持开源的LLM。请查看示例笔记本和源代码以供参考:
简介
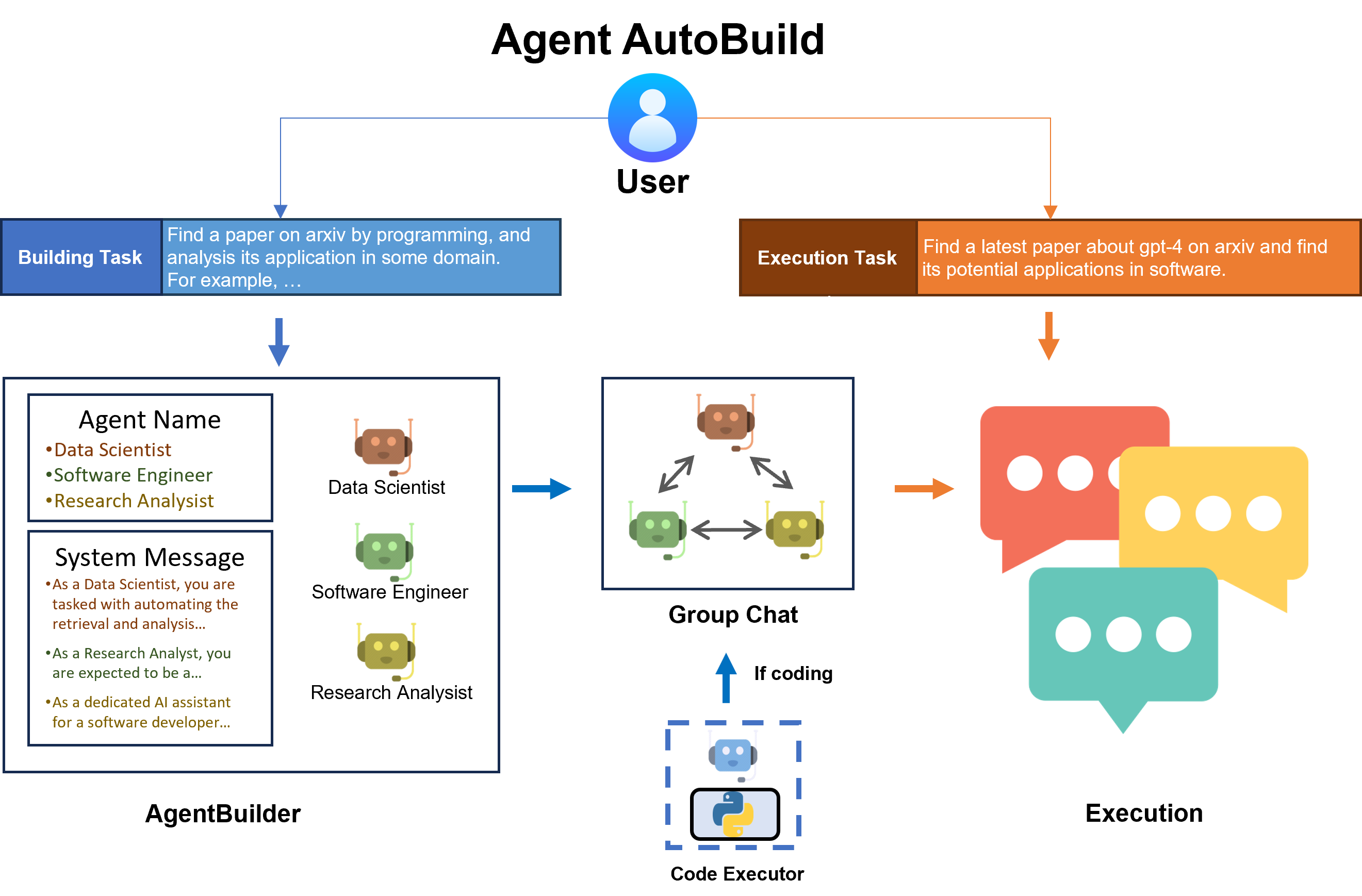
在本文中,我们介绍了一种名为 AutoBuild 的流水线,可以自动构建用于复杂任务的多智能体系统。具体来说,我们设计了一个名为 AgentBuilder 的新类,它将在用户提供建筑任务和执行任务的描述后,自动完成参与者专家智能体的生成和群组聊天的构建。
AgentBuilder 支持由 vLLM 和 FastChat 提供支持的开源模型。一旦用户选择使用开源的LLM,AgentBuilder 将自动设置一个端点服务器,无需用户参与。
安装
- AutoGen:
pip install pyautogen[autobuild]
- (可选:如果您想使用开源的LLM)vLLM 和 FastChat
pip install vllm fastchat
基本示例
在本节中,我们提供了一个逐步示例,介绍如何使用 AgentBuilder 构建特定任务的多智能体系统。
步骤1:准备配置
首先,我们需要准备智能体的配置。 具体来说,需要一个包含模型名称和API密钥的配置文件路径,以及每个智能体的默认配置。
config_file_or_env = '/home/elpis_ubuntu/LLM/autogen/OAI_CONFIG_LIST' # 修改路径
default_llm_config = {
'temperature': 0
}
步骤2:创建 AgentBuilder 实例
然后,我们使用配置文件路径和默认配置创建一个 AgentBuilder 实例。 您还可以指定构建器模型和智能体模型,它们是用于构建和智能体的LLM。
from autogen.agentchat.contrib.agent_builder import AgentBuilder
builder = AgentBuilder(config_file_or_env=config_file_or_env, builder_model='gpt-4-1106-preview', agent_model='gpt-4-1106-preview')
步骤3:指定建筑任务
使用一般描述指定一个建筑任务。建筑任务将帮助建筑经理(一个LLM)决定应该构建哪些智能体。 请注意,您的建筑任务应该有一个关于任�务的一般描述。添加一些具体的示例会更好。
building_task = "在 arxiv 上找一篇与编程相关的论文,并分析其在某个领域的应用。例如,在 arxiv 上找一篇关于 GPT-4 的最新论文,并找出它在软件领域的潜在应用。"
第四步:构建群聊代理
使用 build() 方法,让构建管理器(使用 builder_model 作为主干)完成群聊代理的生成。
如果你认为在任务中需要编码,你可以使用 coding=True 将一个用户代理(本地代码解释��器)添加到代理列表中,如下所示:
agent_list, agent_configs = builder.build(building_task, default_llm_config, coding=True)
如果没有指定 coding 参数,AgentBuilder 将根据任务自行决定是否添加用户代理。
生成的 agent_list 是一个 AssistantAgent 实例的列表。如果 coding 为 True,将会在 agent_list 的第一个元素位置添加一个用户代理(UserProxyAssistant 实例)。
agent_configs 是一个代理配置的列表,包括代理名称、主干 LLM 模型和系统消息。
例如:
// 一个 agent_configs 的示例。AgentBuilder 将生成具有以下配置的代理。
[
{
"name": "ArXiv_Data_Scraper_Developer",
"model": "gpt-4-1106-preview",
"system_message": "您现在在一个群聊中。您需要与其他参与者一起完成一个任务。作为 ArXiv_Data_Scraper_Developer,您的重点是创建和改进能够智能搜索和从 arXiv 提取数据的工具,专注于计算机科学和医学科学领域的主题。利用您在 Python 编程方面的熟练程度,设计脚本来浏览、查询和解析平台上的信息,生成有价值的见解和数据集进行分析。\n\n在您的任务��中,不仅仅是制定查询;您的角色还包括优化和精确数据检索过程,确保提取的信息的相关性和准确性。如果您在脚本中遇到问题或预期输出有差异,鼓励您在群聊中进行故障排除并提供修订的代码。\n\n当您达到现有代码库无法满足任务要求的程度,或者对提供的代码的操作不清楚时,您应该向群聊管理员寻求帮助。他们将通过提供指导或指派其他参与者来促进您的进展。根据同行的反馈能力来调整和改进脚本至关重要,因为数据爬取的动态性要求不断完善技术和方法。\n\n通过确认您提供的数据爬取解决方案是否满足用户的需求来结束您的参与。在群聊中回复“TERMINATE”来指示您任务的完成。",
"description": "ArXiv_Data_Scraper_Developer 是一个专门的软件开发角色,需要精通 Python,包括熟悉 BeautifulSoup 或 Scrapy 等网络爬虫库,并对 API 和数据解析有扎实的理解。他们必须具备在现有脚本中识别和纠正错误的能力,并自信地参与技术讨论,以改进数据检索过程。该角色还需要具备疑难解答和优化代码的敏锐眼光,以确保从 ArXiv 平台高效地提取研究和分析所需的数据。"
},
...
]
第五步:执行任务
让在 build() 中生成的代理在群聊中协作完成任务。
import autogen
def start_task(execution_task: str, agent_list: list, llm_config: dict):
config_list = autogen.config_list_from_json(config_file_or_env, filter_dict={"model": ["gpt-4-1106-preview"]})
group_chat = autogen.GroupChat(agents=agent_list, messages=[], max_round=12)
manager = autogen.GroupChatManager(
groupchat=group_chat, llm_config={"config_list": config_list, **llm_config}
)
agent_list[0].initiate_chat(manager, message=execution_task)
start_task(
execution_task="在 arxiv 上找一篇关于 gpt-4 的最新论文,并找出它在软件领域的潜在应用。",
agent_list=agent_list,
llm_config=default_llm_config
)
第六步(可选):清除所有代理并准备下一个任务
如果任务已完成或下一个任务与当前任务差异较大,您可以使用以下代码清除在此任务中生成的所有代理。
builder.clear_all_agents(recycle_endpoint=True)
如果代理的骨干是开源的 LLM,则此过程还将关闭端点服务器。更多细节请参见下一节。
如果需要,您��可以使用 recycle_endpoint=False 保留先前开源 LLM 的端点服务器。
保存和加载
您可以通过以下代码保存构建的群聊代理的所有必要信息:
saved_path = builder.save()
配置将以 JSON 格式保存,内容如下:
// 文件名:save_config_TASK_MD5.json
{
"building_task": "在 arxiv 上找一篇关于 gpt-4 的论文,并分析其在某个领域的应用。例如,在 arxiv 上找一篇关于 gpt-4 的最新论文,并找出它在软件领域的潜在应用。",
"agent_configs": [
{
"name": "...",
"model": "...",
"system_message": "...",
"description": "..."
},
...
],
"manager_system_message": "...",
"code_execution_config": {...},
"default_llm_config": {...}
}
您可以提供特定的文件名,否则 AgentBuilder 将使用生成的文件名 save_config_TASK_MD5.json 将配置保存到当前路径。
您可以加载保存的配置并跳过构建过程。AgentBuilder 将使用这些信息创建代理,而无需提示构建管理器。
new_builder = AgentBuilder(config_file_or_env=config_file_or_env)
agent_list, agent_config = new_builder.load(saved_path)
start_task(...) # 跳过 build()
使用 OpenAI Assistant
Assistants API 允许您在自己的应用程序中构建 AI 助手。
助手具有指令,并可以利用模型、工具和知识来回应用户的查询。
AutoBuild 通过在 build() 中添加 use_oai_assistant=True 来支持助手 API。
# 转换为 OpenAI Assistant API。
agent_list, agent_config = new_builder.build(building_task, default_llm_config, use_oai_assistant=True)
...
(实验性)使用开源LLM
AutoBuild支持通过vLLM和FastChat使用开源LLM。 请在这里查看支持的模型列表。 满足要求后,您可以将开源LLM的huggingface仓库添加到配置文件中,
// 将LLM的huggingface仓库添加到您的配置文件中,并将api_key设置为EMPTY。
[
...
{
"model": "meta-llama/Llama-2-13b-chat-hf",
"api_key": "EMPTY"
}
]
并在初始化AgentBuilder时指定它。 AgentBuilder将自动设置一个用于开源LLM的端点服务器。请确保您有足够的GPU资源。
未来工作/路线图
- 让构建器从给定的库/数据库中选择最佳的代理来解决任务。
概述
我们提出了AutoBuild,其中包含一个新的类AgentBuilder。
AutoBuild可以帮助用户使用自动构建的多代理系统解决复杂任务。
AutoBuild支持开源LLM和GPTs API,使用户能够更灵活地选择他们喜欢的模型。
更多高级功能即将推出。