
TL;DR:
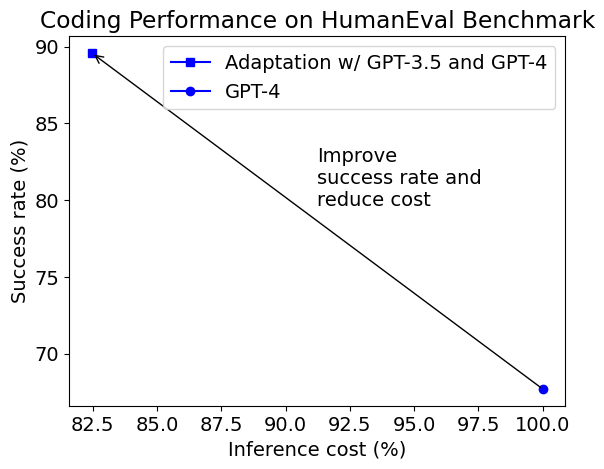
- 使用 HumanEval 基准测试的案例研究表明,使用多个 GPT 模型的自适应方法在编码方面可以实现更高的准确性(从 68% 提高到 90%),同时推理成本降低了 18%,比单独使用 GPT-4 更加高效。
GPT-4 是基础模型能力的重大升级,例如在代码和数学方面,但使用 GPT-4 的每个令牌的价格要比 GPT-3.5-Turbo 高出多达 10 倍以上。在由 OpenAI 开发的代码补全基准测试 HumanEval 上,GPT-4 可以成功解决 68% 的任务,而 GPT-3.5-Turbo 只能解决 46% 的任务。通过生成多个响应或进行多次调用,可以进一步提高 GPT-4 的成功率。然而,这将进一步增加成本,而已经接近使用 GPT-3.5-Turbo 的 20 倍,并且具有更受限制的 API 调用速率限制。我们能否以更少的成本实现更多的效果呢?
在本博客文章中,我们将探索一种创造性的、自适应的 GPT 模型使用方法,从而实现了一次巨大的飞跃。
观察结果
- GPT-3.5-Turbo 已经可以解决 40%-50% 的任务。对于这些任务,如果我们从不使用 GPT-4,我们可以节省近 40-50% 的成本。
- 如果我们使用节省下来的成本,为剩下的未解决任务使用 GPT-4 生成更多的响应,有可能解决其中的一些任务,同时保持平均成本较低。
利用这些观察结果的障碍在于我们不知道哪些任务可以由更便宜的模型解决,哪些任务可以由更昂贵的模型解决,以及哪些任务可以通过支付更多的费用来解决。
为了克服这个障碍,我们可能希望预测哪个任务需要使用哪个模型来解决,以及每个任务需要多少个响应。让我们看一个代码补全任务的例子:
def vowels_count(s):
"""编写一个函数 vowels_count,该函数接受一个表示单词的字符串作为输入,并返回字符串中元音字母的数量。
在这种情况下,元音字母是 'a'、'e'、'i'、'o'、'u'。这里,'y' 也是元音字母,但只有当它位于给定单词的末尾时才是。
示例:
>>> vowels_count("abcde")
2
>>> vowels_count("ACEDY")
3
"""
我们能否预测 GPT-3.5-Turbo 是否能够解决这个任务,或者我们需要使用 GPT-4?我最初的猜测是 GPT-3.5-Turbo 可以做对,因为指令相当简单。然而,事实证明,如果我们只给它一次机会,GPT-3.5-Turbo 并不总是能够正确解决。如何在不实际尝试的情况下预测性能并不明显(但这是一个有趣的研究问题!)。
我们还能做什么呢?我们注意到: 验证给定解决方案比从头开始找到正确解决方案要“容易”。 在文档字符串中提供了一些简单的示例测试用例。如果我们已经有了模型生成的响应,我们可以使用这些测试用例来过滤错误的实现,并使用更强大的模型或生成更多的响应,直到结果通过示例测试用例。此外,可以通过询问GPT-3.5-Turbo从文档字符串中给出的示例生成断言语句(一个更简单的任务,我们可以押注)并执行代码来自动化此步骤。
解决方案
结合这些观察结果,我们可以设计一个具有两个直观思路的解决方案:
- 利用自动生成的反馈,即代码执行结果,来过滤响应。
- 逐个尝试推理配置,直到找到一个能通过过滤的响应。
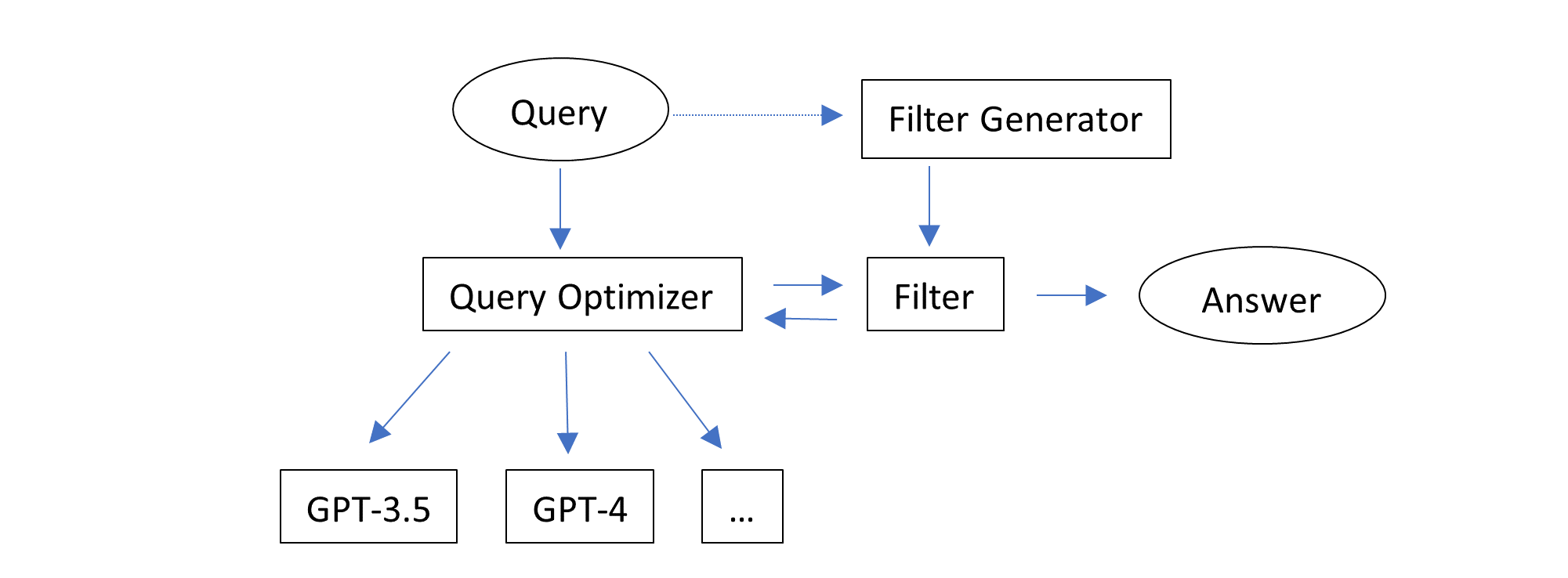
这个解决方案在不知道或预测哪个任务适合哪个配置的情况下,能够自适应地工作。它只是逐个尝试多个配置,从最便宜的配置开始。注意,一个配置可以生成多个响应(通过将推理参数n设置为大于1)。不同的配置可以��使用相同的模型和不同的推理参数,如n和temperature。每个任务只返回和评估一个响应。
在autogen中提供了这个解决方案的实现。它使用以下配置序列:
- GPT-3.5-Turbo,n=1,temperature=0
- GPT-3.5-Turbo,n=7,temperature=1,stop=["\nclass", "\ndef", "\nif", "\nprint"]
- GPT-4,n=1,temperature=0
- GPT-4,n=2,temperature=1,stop=["\nclass", "\ndef", "\nif", "\nprint"]
- GPT-4,n=1,temperature=1,stop=["\nclass", "\ndef", "\nif", "\nprint"]
实验结果
本博文的第一个图表显示了自适应解决方案与默认的GPT-4相比的成功率和平均推理成本。推理成本包括我们解决方案中生成断言的成本。生成的断言并不总是正确的,通过/未通过生成的断言的程序也不总是正确/错误的。尽管如此,自适应解决方案可以将成功率(在文献中称为pass@1)从68%提高到90%,同时将成本降低了18%。
以下是由组合中的不同配置解决的一些函数定义示例。
- 由GPT-3.5-Turbo,n=1,temperature=0解决
def compare(game, guess):
"""我想我们都记得那种期待已久的事件结果终于揭晓的感觉。那一刻你所拥有的感受和想法绝对值得记录下来并进行比较。
你的任务是确定一个人是否正确猜测了一系列比赛的结果。
给定两个长度相等的得分和猜测的数组,每个索引表示一场比赛。
返回一个相同长度的数组,表示每个猜测离实际结果有多远。如果猜测正确,则值为0,否则值为猜测值与实际得分之间的绝对差值。
示例:
compare([1,2,3,4,5,1],[1,2,3,4,2,-2]) -> [0,0,0,0,3,3]
compare([0,5,0,0,0,4],[4,1,1,0,0,-2]) -> [4,4,1,0,0,6]
"""
-
使用 GPT-3.5-Turbo,n=7,temperature=1,stop=["\nclass", "\ndef", "\nif", "\nprint"],解决了之前提出的
vowels_count函数。 -
使用 GPT-4,n=1,temperature=0,解决了以下问题:
def string_xor(a: str, b: str) -> str:
""" 输入是两个字符串 a 和 b,只包含 1 和 0。
对这些输入进行二进制异或运算,并将结果作为字符串返回。
>>> string_xor('010', '110')
'100'
"""
- 使用 GPT-4,n=2,temperature=1,stop=["\nclass", "\ndef", "\nif", "\nprint"],解决了以下问题:
def is_palindrome(string: str) -> bool:
""" 检测给定的字符串是否是回文 """
return string == string[::-1]
def make_palindrome(string: str) -> str:
""" 找到以给定字符串开头的最短回文串。
算法思想很简单:
- 找到给定字符串的最长后缀,该后缀是回文的。
- 将回文后缀之前的字符串前缀的反转附加到字符串的末尾。
>>> make_palindrome('')
''
>>> make_palindrome('cat')
'catac'
>>> make_palindrome('cata')
'catac'
"""
- 使用 GPT-4,n=1,temperature=1,stop=["\nclass", "\ndef", "\nif", "\nprint"],解决了以下问题:
def sort_array(arr):
"""
在这个 Kata 中,你需要根据二进制表示中 1 的个数按升序对非负整数数组进行排序。
对于相同数量的 1,根据十进制值进行排序。
必须按照以下方式实现:
>>> sort_array([1, 5, 2, 3, 4]) == [1, 2, 3, 4, 5]
>>> sort_array([-2, -3, -4, -5, -6]) == [-6, -5, -4, -3, -2]
>>> sort_array([1, 0, 2, 3, 4]) [0, 1, 2, 3, 4]
"""
最后一个问题是一个示例,原始定义中的示例测试用例是错误的。这会误导自适应解决方案,因为正确的实现被视为错误,并进行了更多的尝试。序列中的最后一个配置返回了正确的实现,即使它没有通过自动生成的断言。这个例子说明了以下几点:
- 我们的自适应解决方案具有一定的容错能力。
- 如果使用正确的示例测试用例,自适应解决方案的成功率和推理成本可以进一步提高。
值得注意的是,减少的推理成本是对所有任务的摊销成本。对于每个单独的任务,成本可能比直接使用 GPT-4 要大或者要小。这是自适应解决方案的本质:对于困难的任务,成本通常比简单任务要大。
可以在以下链接找到一个运行此实验的示例笔记本:https://github.com/microsoft/FLAML/blob/v1.2.1/notebook/research/autogen_code.ipynb。该实验是在 AutoGen 是 FLAML 的子包时运行的。
讨论
我们的解决方案非常简单,使用 autogen 中提供的通用接口实现,但结果令人鼓舞。
虽然生成断言的具体方法因应用而异,但在LLM操作中的主要思想是通用的:
- 生成多个响应供选择 - 当选择一个好的响应相对容易,而一次生成一个好的响应相对困难时,这一点尤为有用。
- 考虑多个配置来生成响应 - 当:
- 模型和其他推理参数的选择影响效用成本权衡时;或者
- 不同的配置具有互补效果时,这一点尤为有用。
先前的博客文章 提供了证据,证明这些思想在解决数学问题时也是相关的。
autogen使用一种名为EcoOptiGen的技术来支持推理参数调优和模型选择。
在研究和开发中有许多扩展方向:
- 推广提供反馈的方式。
- 自动化配置优化过程。
- 为不同应用构建自适应代理。
您是否认为这种方法适用于您的用例?您是否有关于LLM应用的其他挑战要分享?您是否希望看到更多关于LLM优化或自动化的支持或研究?请加入我们的Discord服务器进行讨论。