
最后更新:2024年4月4日;AutoGen 版本:v0.2.21

TL;DR:
- 我们介绍了 AutoGen 的 RAG 代理(RetrieveUserProxyAgent 和 RetrieveAssistantAgent),它们实现了检索增强生成,并介绍了其基本用法。
- 我们展示了 RAG 代理的自定义,例如自定义嵌入函数、文本分割函数和向量数据库。
- 我们还展示了 RAG 代理的两种高级用法,即与群聊集成和构建使用 Gradio 的聊天应用程序。
简介
检索增强已经成为一种实用且有效的方法,通过引入外部文档来缓解 LLM 的固有限制。在本博文中,我们介绍了 AutoGen 的 RAG 代理,它实现了检索增强生成。该系统由两个代理组成:检索增强用户代理(RetrieveUserProxyAgent)和检索增强助理代理(RetrieveAssistantAgent),它们都是基于 AutoGen 的内置代理进行扩展的。RAG 代理的整体架构如上图所示。
要使用检索增强聊天功能,需要初始化两个代理,包括检索增强用户代理和检索增强助理代理。初始化检索增强用户代理需要指定文档集合的路径。随后,检索增强用户代理可以下载文档,将其分割成特定大小的块,计算嵌入并�将其存储在向量数据库中。一旦启动聊天,代理将根据以下步骤进行代码生成或问答:
- 检索增强用户代理根据嵌入相似性检索文档块,并将其与问题一起发送给检索增强助理。
- 检索增强助理使用 LLM 根据提供的问题和上下文生成代码或文本作为答案。如果 LLM 无法生成令人满意的响应,则指示其回复“更新上下文”给检索增强用户代理。
- 如果响应中包含代码块,检索增强用户代理将执行代码并将输出作为反馈发送。如果没有代码块或更新上下文的指令,则会终止对话。否则,它会更新上下文,并将问题与新上下文转发给检索增强助理。请注意,如果启用了人工输入请求,个人可以主动向检索增强助理发送任何反馈,包括“更新上下文”。
- 如果检索增强助理收到“更新上下文”,它会从检索增强用户代理请求与上下文最相似的下一个文档块作为新上下文。否则,它将继续生成答案。 根据反馈和聊天历史生成新的代码或文本。如果LLM无法生成答案,则会再次回复“Update Context”。这个过程可以重复多次。如果没有更多的文档可用于上下文,则对话终止。
RAG代理的基本用法
- 安装依赖项
在使用RAG代理之前,请使用[retrievechat]选项安装pyautogen。
pip install "pyautogen[retrievechat]"
RetrieveChat可以处理各种类型的文档。默认情况下,它可以处理纯文本和PDF文件,包括'txt'、'json'、'csv'、'tsv'、'md'、'html'、'htm'、'rtf'、'rst'、'jsonl'、'log'、'xml'、'yaml'、'yml'和'pdf'等格式。如果安装了unstructured,还可以支持其他文档类型,如'docx'、'doc'、'odt'、'pptx'、'ppt'、'xlsx'、'eml'、'msg'、'epub'等。
- 在Ubuntu上安装
unstructured
sudo apt-get update
sudo apt-get install -y tesseract-ocr poppler-utils
pip install unstructured[all-docs]
您可以使用autogen.retrieve_utils.TEXT_FORMATS找到所有支持的文档类型列表。
- 导入代理
import autogen
from autogen.agentchat.contrib.retrieve_assistant_agent import RetrieveAssistantAgent
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
- 创建一个名为“assistant”的'RetrieveAssistantAgent'实例和一个名为“ragproxyagent”的'RetrieveUserProxyAgent'实例
assistant = RetrieveAssistantAgent(
name="assistant",
system_message="You are a helpful assistant.",
llm_config=llm_config,
)
ragproxyagent = RetrieveUserProxyAgent(
name="ragproxyagent",
retrieve_config={
"task": "qa",
"docs_path": "https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
},
)
- 初始化聊天并提问问题
assistant.reset()
ragproxyagent.initiate_chat(assistant, message=ragproxyagent.message_generator, problem="What is autogen?")
输出如下:
--------------------------------------------------------------------------------
AutoGen是一个框架,它使用可以相互对话以解决任务的多个代理来开发大型语言模型(LLM)应用程序。这些代理是可定制的、可对话的,并允许人类参与。它们可以在使用LLM、人类输入和工具的各种模式下运行。
--------------------------------------------------------------------------------
- 创建一个UserProxyAgent并提出同样的问题
assistant.reset()
userproxyagent = autogen.UserProxyAgent(name="userproxyagent")
userproxyagent.initiate_chat(assistant, message="What is autogen?")
输出如下:
助手(给 userproxyagent):
在计算机软件中,自动生成(autogen)是一种无需手动编码即可自动生成程序代码的工具。它通常用于软件工程、游戏开发和网页开发等领域,以加快开发过程并减少错误。自动生成工具通常使用预先编程的规则、模板和数据来为重复性任务生成代码,例如生成用户界面、数据库模式和数据模型。一些常用的自动生成工具包括 Visual Studio 的代码生成器和 Unity 的资源商店。
你可以看到 UserProxyAgent 的输出与我们的 autogen 不相关,因为 autogen 的最新信息不在 ChatGPT 的训练数据中。而 RetrieveUserProxyAgent 的输出是正确的,因为它可以根据给定的文档文件执行检索增强生成。
自定义 RAG 代理
RetrieveUserProxyAgent 可以通过 retrieve_config 进行自定义。根据不同的用例,有几个参数可以配置。在本节中,我们将展示如何自定义嵌入函数、文本分割函数和向量数据库。
自定义嵌入函数
默认情况下,我们将使用 Sentence Transformers 及其预训练模型来计算嵌入。但你可能希望使用 OpenAI、Cohere、HuggingFace 或其他嵌入函数。
- OpenAI
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_API_KEY",
model_name="text-embedding-ada-002"
)
ragproxyagent = RetrieveUserProxyAgent(
name="ragproxyagent",
retrieve_config={
"task": "qa",
"docs_path": "https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
"embedding_function": openai_ef,
},
)
- HuggingFace
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key="YOUR_API_KEY",
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
更多示例可以在这里找到。
自定义文本分割函数
在将文档存储到向量数据库之前,我们需要将文本分割成块。虽然我们在 autogen 中实现了一个灵活的文本分割器,但你可能仍然想使用不同的文本分割器。也有一些现有的文本分割工具可以重用。
例如,你可以使用 langchain 中的所有文本分割器。
from langchain.text_splitter import RecursiveCharacterTextSplitter
recur_spliter = RecursiveCharacterTextSplitter(separators=["\n", "\r", "\t"])
ragproxyagent = RetrieveUserProxyAgent(
name="ragproxyagent",
retrieve_config={
"task": "qa",
"docs_path": "https://raw.githubusercontent.com/microsoft/autogen/main/README.md",
"custom_text_split_function": recur_spliter.split_text,
},
)
自定义向量数据库
我们使用 chromadb 作为默认的向量数据库,你也可以通过简单地覆盖 RetrieveUserProxyAgent 的 retrieve_docs 函数来替换为任何其他向量数据库。
例如,你可以使用 Qdrant,如下所示:
# 创建 qdrant 客户端
from qdrant_client import QdrantClient
client = QdrantClient(url="***", api_key="***")
# 包装 RetrieveUserProxyAgent
from litellm import embedding as test_embedding
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
from qdrant_client.models import SearchRequest, Filter, FieldCondition, MatchText
class QdrantRetrieveUserProxyAgent(RetrieveUserProxyAgent):
def query_vector_db(
self,
query_texts: List[str],
n_results: int = 10,
search_string: str = "",
**kwargs,
) -> Dict[str, Union[List[str], List[List[str]]]]:
# 在这里定义你自己的查询函数
embed_response = test_embedding('text-embedding-ada-002', input=query_texts)
all_embeddings: List[List[float]] = []
for item in embed_response['data']:
all_embeddings.append(item['embedding'])
search_queries: List[SearchRequest] = []
for embedding in all_embeddings:
search_queries.append(
SearchRequest(
vector=embedding,
filter=Filter(
must=[
FieldCondition(
key="page_content",
match=MatchText(
text=search_string,
)
)
]
),
limit=n_results,
with_payload=True,
)
)
search_response = client.search_batch(
collection_name="{你的集合名称}",
requests=search_queries,
)
return {
"ids": [[scored_point.id for scored_point in batch] for batch in search_response],
"documents": [[scored_point.payload.get('page_content', '') for scored_point in batch] for batch in search_response],
"metadatas": [[scored_point.payload.get('metadata', {}) for scored_point in batch] for batch in search_response]
}
def retrieve_docs(self, problem: str, n_results: int = 20, search_string: str = "", **kwargs):
results = self.query_vector_db(
query_texts=[problem],
n_results=n_results,
search_string=search_string,
**kwargs,
)
self._results = results
# 使用 QdrantRetrieveUserProxyAgent
qdrantragagent = QdrantRetrieveUserProxyAgent(
name="ragproxyagent",
human_input_mode="NEVER",
max_consecutive_auto_reply=2,
retrieve_config={
"task": "qa",
},
)
qdrantragagent.retrieve_docs("什么是 Autogen?", n_results=10, search_string="autogen")
RAG 代理的高级用法
与其他代理在群聊中集成
在群聊中使用 RetrieveUserProxyAgent 和在两个代理之间的聊天中使用几乎是一样的。唯一的区别是你需要使用 RetrieveUserProxyAgent 初始化聊天。在群聊中不需要使用 RetrieveAssistantAgent。
然而,在某些情况下,你可能希望使用另一个代理来初始化聊天。为了充分利用 RetrieveUserProxyAgent 的优势,你需要从一个函数中调用它。
boss = autogen.UserProxyAgent(
name="Boss",
is_termination_msg=termination_msg,
human_input_mode="TERMINATE",
system_message="提问问题和分配任务的老板。",
)
boss_aid = RetrieveUserProxyAgent(
name="Boss_Assistant",
is_termination_msg=termination_msg,
system_message="拥有额外内容检索能力,用于解决困难问题的助手。",
human_input_mode="NEVER",
max_consecutive_auto_reply=3,
retrieve_config={
"task": "qa",
},
code_execution_config=False, # 在这种情况下,我们不想执行代码。
)
coder = autogen.AssistantAgent(
name="Senior_Python_Engineer",
is_termination_msg=termination_msg,
system_message="你是一名高级 Python 工程师。在完成所有工作后回复“TERMINATE”。",
llm_config={"config_list": config_list, "timeout": 60, "temperature": 0},
)
pm = autogen.AssistantAgent(
name="Product_Manager",
is_termination_msg=termination_msg,
system_message="你是一名产品经理。在完成所有工作后回复“TERMINATE”。",
llm_config={"config_list": config_list, "timeout": 60, "temperature": 0},
)
reviewer = autogen.AssistantAgent(
name="Code_Reviewer",
is_termination_msg=termination_msg,
system_message="你是一名代码审查员。在完成所有工作后回复“TERMINATE”。",
llm_config={"config_list": config_list, "timeout": 60, "temperature": 0},
)
def retrieve_content(
message: Annotated[
str,
"经过优化的消息,保留原始含义,可用于检索内容以进行代码生成和问题回答。",
],
n_results: Annotated[int, "结果数量"] = 3,
) -> str:
boss_aid.n_results = n_results # 设置要检索的结果数量。
# 检查是否需要更新上下文。
update_context_case1, update_context_case2 = boss_aid._check_update_context(message)
if (update_context_case1 or update_context_case2) and boss_aid.update_context:
boss_aid.problem = message if not hasattr(boss_aid, "problem") else boss_aid.problem
_, ret_msg = boss_aid._generate_retrieve_user_reply(message)
else:
_context = {"problem": message, "n_results": n_results}
ret_msg = boss_aid.message_generator(boss_aid, None, _context)
return ret_msg if ret_msg else message
for caller in [pm, coder, reviewer]:
d_retrieve_content = caller.register_for_llm(
description="检索内容以进行代码生成和问题回答。",
api_style="function"
)(retrieve_content)
for executor in [boss, pm]:
executor.register_for_execution()(d_retrieve_content)
groupchat = autogen.GroupChat(
agents=[boss, pm, coder, reviewer],
messages=[],
max_round=12,
speaker_selection_method="round_robin",
allow_repeat_speaker=False,
)
llm_config = {"config_list": config_list, "timeout": 60, "temperature": 0}
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=llm_config)
# 作为用户代理代理开始与老板聊天。
boss.initiate_chat(
manager,
message="如何在 FLAML 中使用 Spark 进行并行训练?给我一个示例代码。",
)
使用 Gradio 构建聊天应用程序
现在,让我们用 AutoGen 和 Gradio 来封装它,创建一个聊天应用程序。
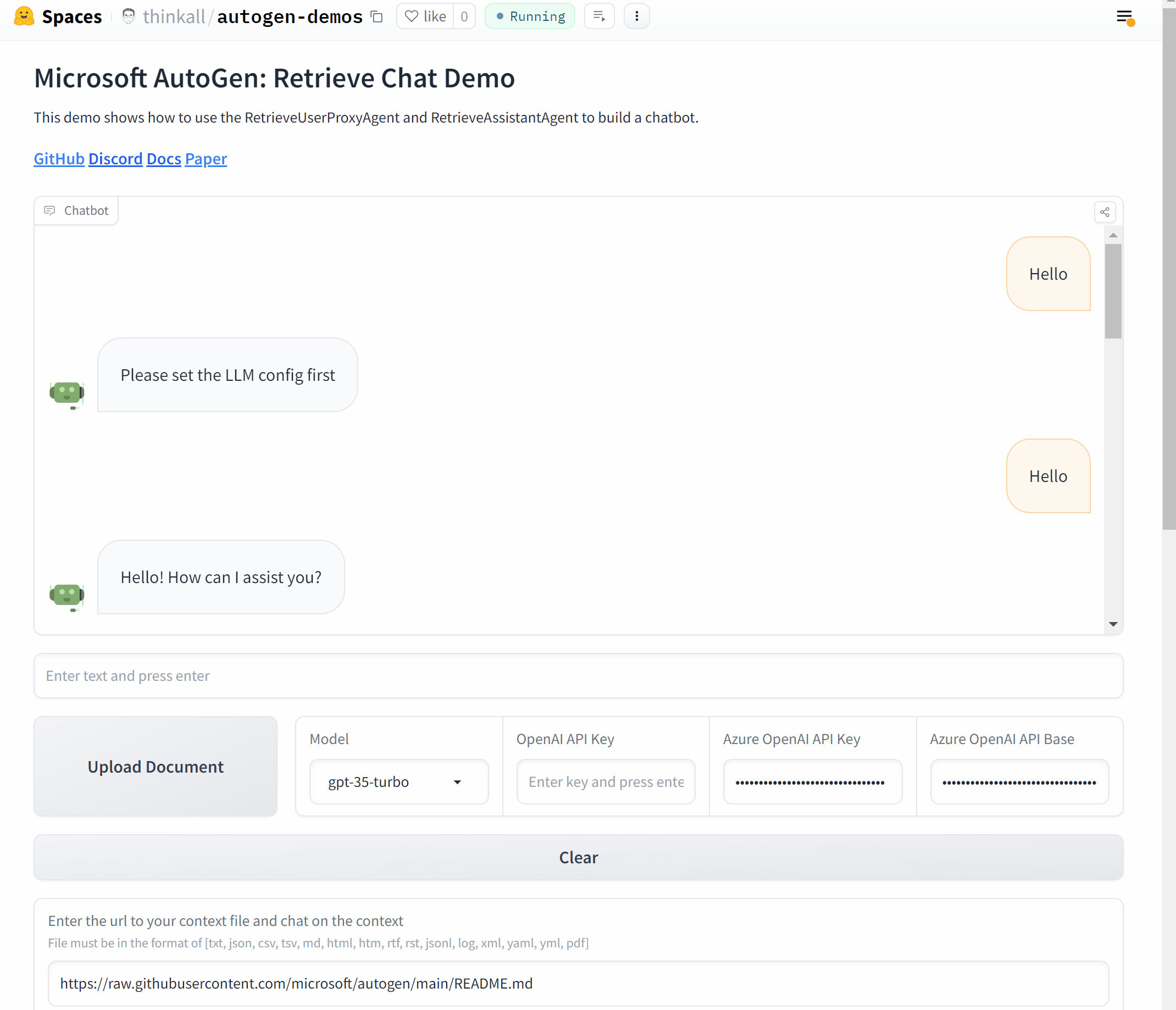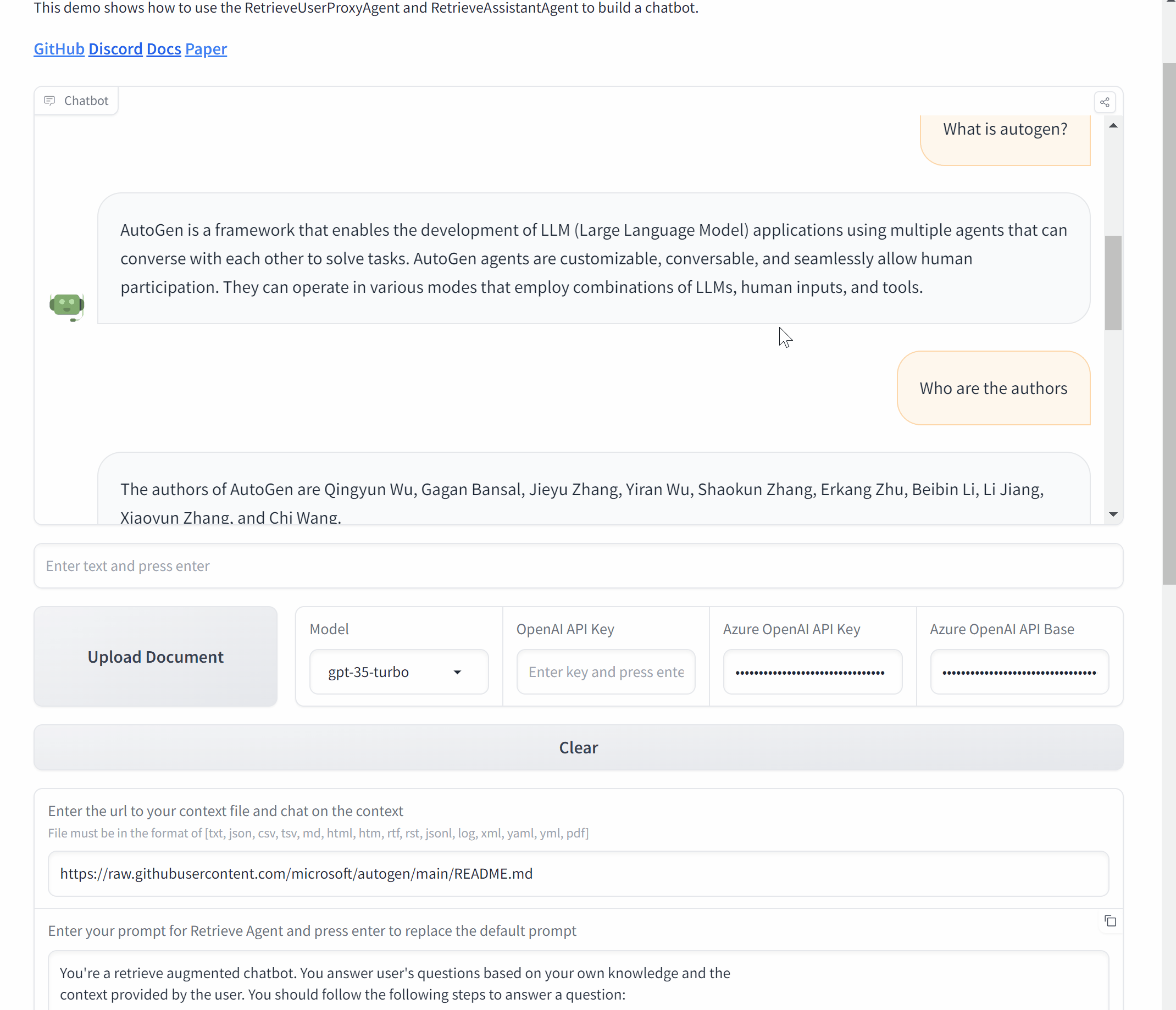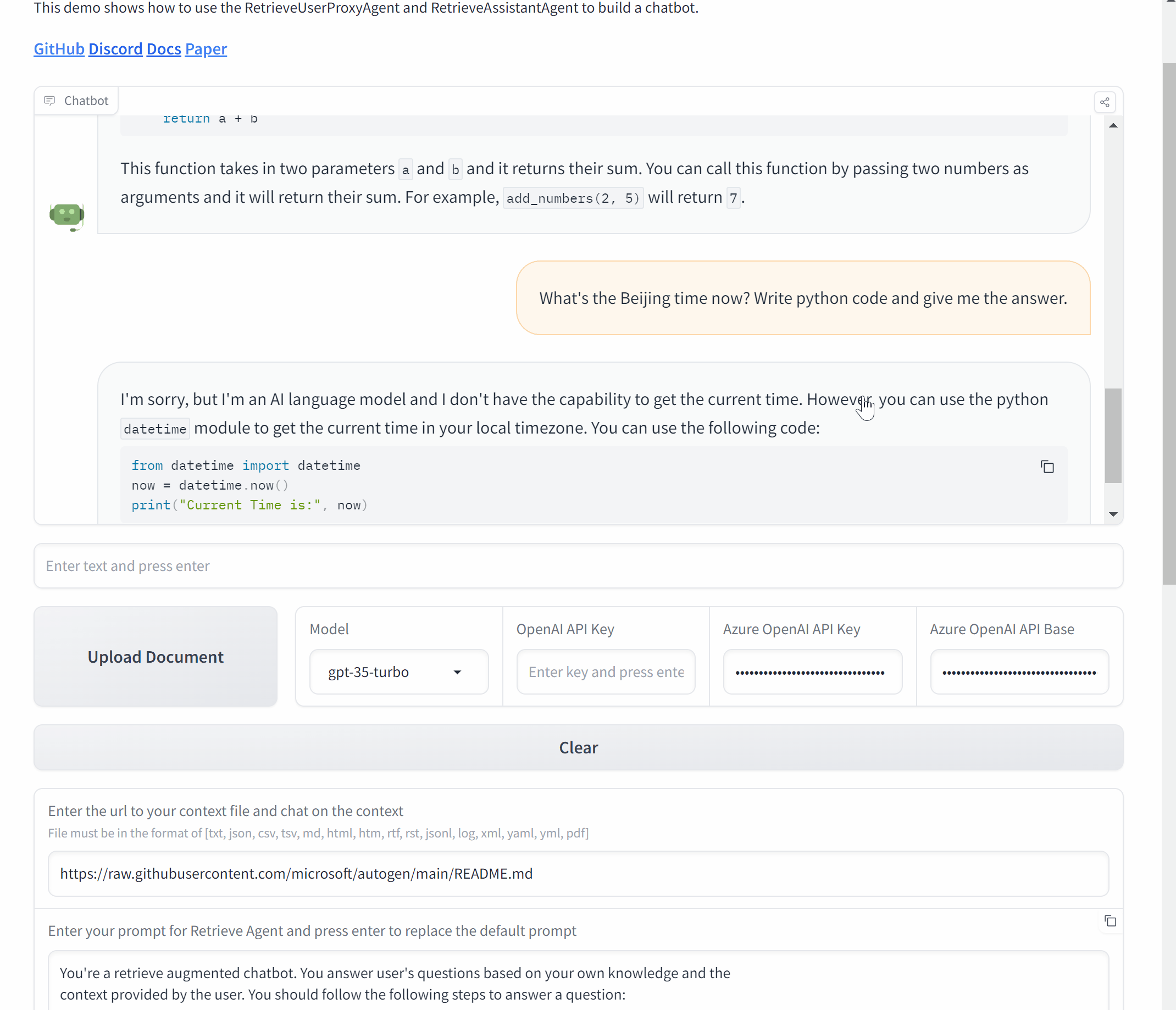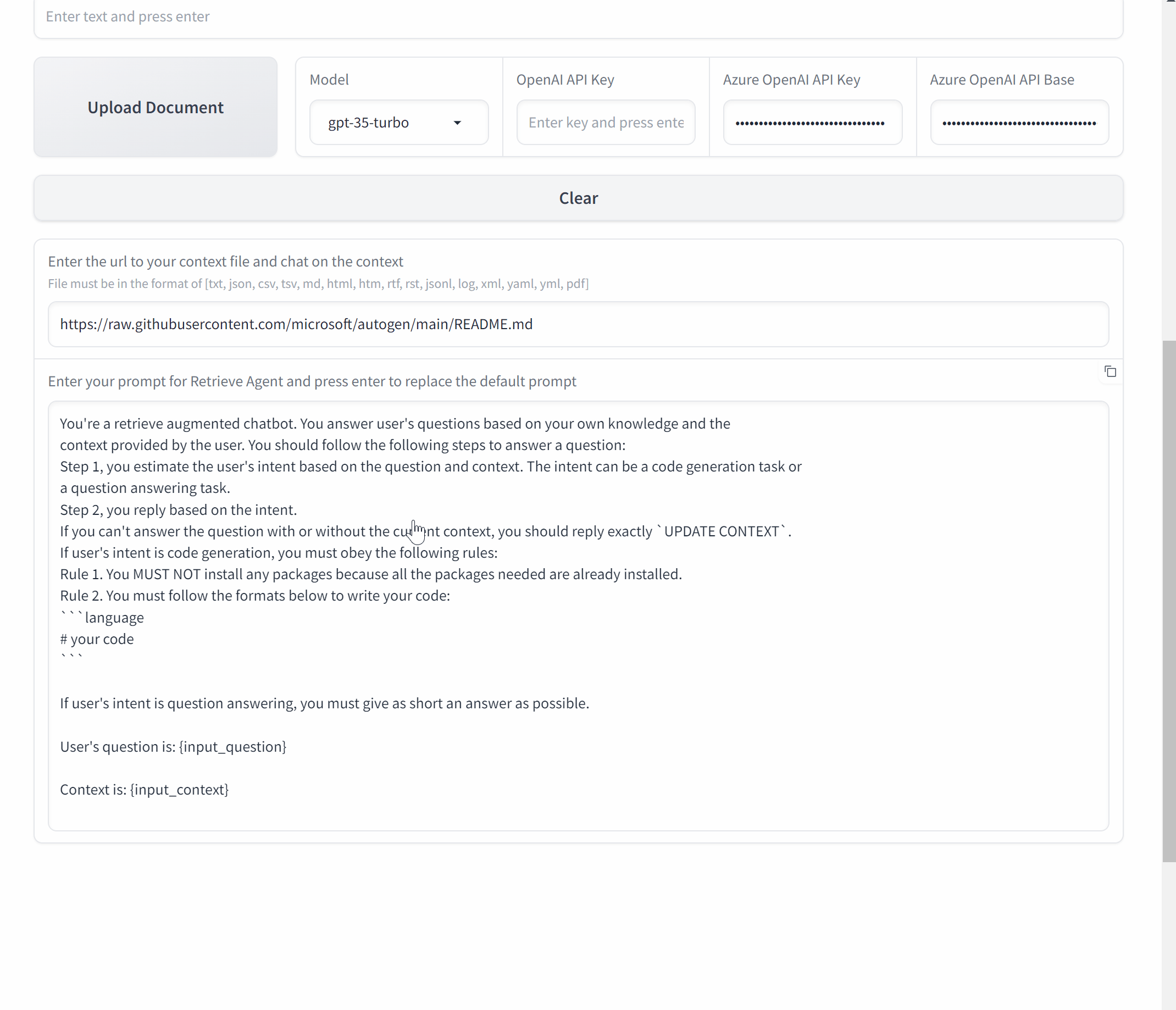
# 初始化代理
def initialize_agents(config_list, docs_path=None):
...
return assistant, ragproxyagent
# 初始化聊天
def initiate_chat(config_list, problem, queue, n_results=3):
...
assistant.reset()
try:
ragproxyagent.a_initiate_chat(
assistant, problem=problem, silent=False, n_results=n_results
)
messages = ragproxyagent.chat_messages
messages = [messages[k] for k in messages.keys()][0]
messages = [m["content"] for m in messages if m["role"] == "user"]
print("messages: ", messages)
except Exception as e:
messages = [str(e)]
queue.put(messages)
# 将 AutoGen 部分封装成一个函数
def chatbot_reply(input_text):
"""通过终端与代理进行聊天。"""
queue = mp.Queue()
process = mp.Process(
target=initiate_chat,
args=(config_list, input_text, queue),
)
process.start()
try:
messages = queue.get(timeout=TIMEOUT)
except Exception as e:
messages = [str(e) if len(str(e)) > 0 else "无效的 OpenAI 请求,请检查您的 API 密钥。"]
finally:
try:
process.terminate()
except:
pass
return messages
...
# 使用 Gradio 设置用户界面
with gr.Blocks() as demo:
...
assistant, ragproxyagent = initialize_agents(config_list)
chatbot = gr.Chatbot(
[],
elem_id="chatbot",
bubble_full_width=False,
avatar_images=(None, (os.path.join(os.path.dirname(__file__), "autogen.png"))),
# height=600,
)
txt_input = gr.Textbox(
scale=4,
show_label=False,
placeholder="输入文本并按回车键",
container=False,
)
with gr.Row():
txt_model = gr.Dropdown(
label="模型",
choices=[
"gpt-4",
"gpt-35-turbo",
"gpt-3.5-turbo",
],
allow_custom_value=True,
value="gpt-35-turbo",
container=True,
)
txt_oai_key = gr.Textbox(
label="OpenAI API 密钥",
placeholder="输入密钥并按回车键",
max_lines=1,
show_label=True,
value=os.environ.get("OPENAI_API_KEY", ""),
container=True,
type="password",
)
...
clear = gr.ClearButton([txt_input, chatbot])
...
if __name__ == "__main__":
demo.launch(share=True)
在线应用程序和源代码托管在 HuggingFace 上。随时试用一下吧!
阅读更多
您可以查看更多 RAG 使用案例的示例笔记本: