

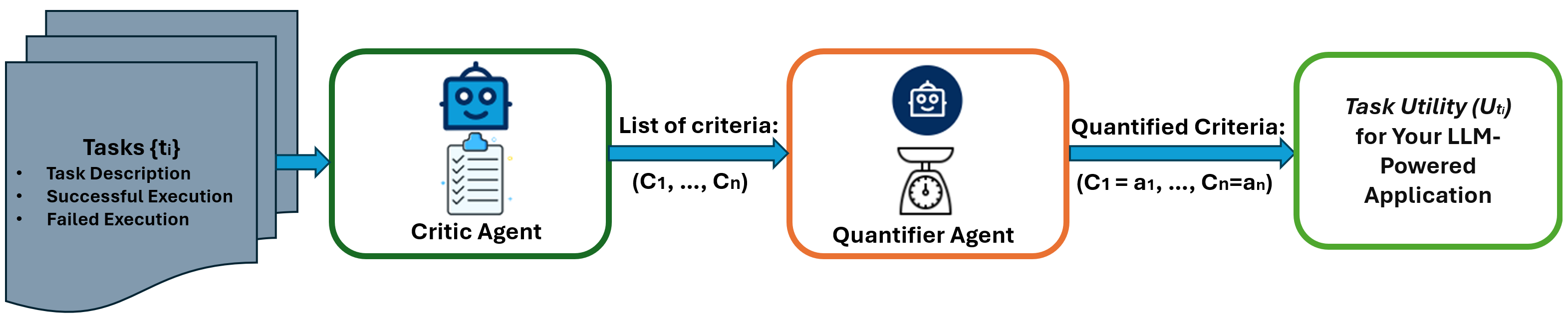
图1展示了AgentEval的一般流程
TL;DR:
- 作为一个LLM应用的开发者,你如何评估它对最终用户的实用性,同时又能帮助他们完成任务?
- 为了回答上述问题,我们介绍了
AgentEval——一个用于评估任何LLM应用实用性的框架的第一个版本。AgentEval旨在简化评估过程,通过自动提出一组与应用的独特目的相适应的标准,实现全面评估,并量化应用相对于建议标准的实用性。 - 我们使用数学问题数据集作为示例,在以下笔记本中演示了
AgentEval的工作原理。对于未来的发展,任何反馈都将非常有用。请通过我们的Discord与我们联系。
引言
AutoGen旨在简化开发LLM驱动的多Agent系统,以应用于各种应用程序,最终通过协助用户完成任务来简化用户的生活。接下来,我们都渴望了解我们开发的系统的性能,对用户的实用性以及最重要的是如何改进它们。直接评估多Agent系统存在挑战,因为当前的方法主要依赖于成功度量标准,即Agent是否完成任务。然而,理解用户与系统的交互远不止于仅仅成功。以数学问题为例,重要的不仅仅是Agent解决问题,同样重要的是它能够根据各种标准传达解决方案,包括完整性、简洁性和提供的解释的清晰度。此外,并非每个任务的成功都有明确定义。
LLM和多Agent系统的快速发展带来了许多新兴的能力,我们渴望将其转化为对最终用户有实际用途的工具。我们介绍了AgentEval框架的第一个版本——一个旨在帮助开发者快速评估LLM应用实用性的工具,以帮助最终用户完成所需任务。
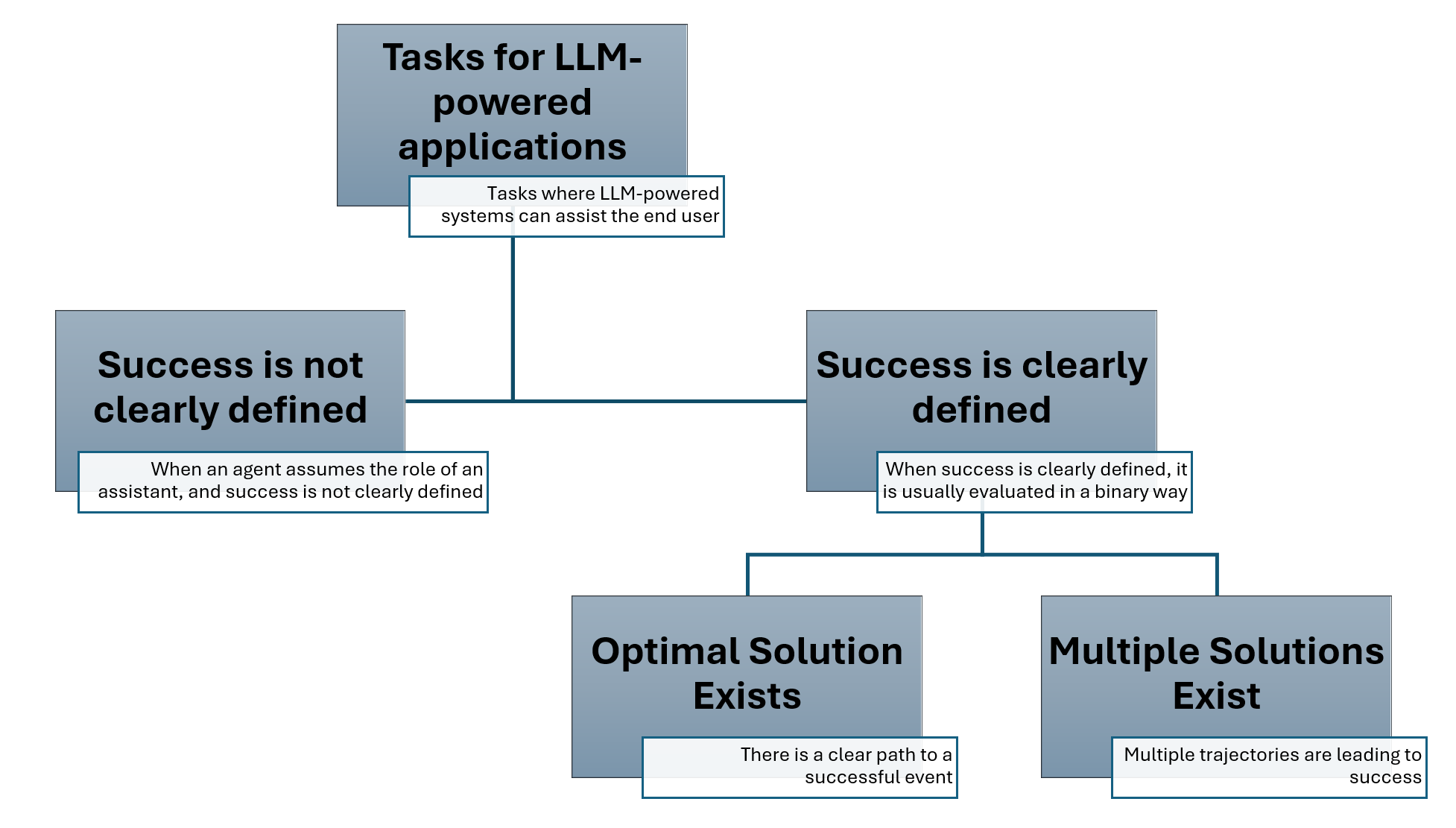
图2提供了任务分类的概览
让我们首先了解一个多Agent系统可以设计的任务��分类的概览。一般来说,任务可以分为两类,即:
- 成功没有明确定义 - 指的是用户以辅助方式使用系统的情况,寻求建议而不是期望系统解决任务。例如,用户可能要求系统生成一封电子邮件。在许多情况下,生成的内容作为用户稍后将编辑的模板。然而,对于这种任务来说,准确定义成功相对复杂。
- 成功有明确定义 - 指的是我们可以明确定义系统是否解决了任务的情况。考虑到协助完成家务任务的代理程序,成功的定义是明确且可衡量的。这个类别可以进一步分为两个子类别:
- 存在最优解 - 这些是只有一个解决方案可能的任务。例如,如果你要求你的助手打开灯,这个任务的成功是明确定义的,而且只有一种方法可以完成它。
- 存在多个解决方案 - 越来越多的情况下,我们观察到多个代理行为轨迹可以导致成功或失败。在这种情况下,区分各种成功和失败的轨迹非常重要。例如,当你要求代理程序给你建议一个食谱或者讲个笑话时。
在我们的AgentEval框架中,我们目前专注于_成功有明确定义_的任务。接下来,我们将介绍建议的框架。
AgentEval框架
我们之前在Minecraft中的辅助代理研究中发现,获取人类判断的最佳方式是将两个代理程序并排呈现给人类,并询问他们的偏好。在这种成对比较的设置中,人类可以制定标准来解释为什么他们更喜欢一个代理程序的行为而不是另一个。例如,“第��一个代理程序执行速度更快”,或者“第二个代理程序移动更自然”。因此,比较的性质使人类能够提出一系列标准,有助于推断任务的效用。基于这个想法,我们设计了AgentEval(如图1所示),其中我们使用LLMs来帮助我们理解、验证和评估多代理系统的任务效用。具体来说:
CriticAgent的目标是提供一份可以用来评估任务效用的标准列表(图1)。这是使用Autogen定义CriticAgent的一个示例:
critic = autogen.AssistantAgent(
name="critic",
llm_config={"config_list": config_list},
system_message="""你是一个乐于助人的助理。你会为评估不同任务提供评价标准。这些标准应该是可区分的、可量化的,并且不重复。
将评估标准转化为一个字典,其中键是标准的名称。
每个键的值是一个字典,格式如下:{"description": 标准描述, "accepted_values": 该键的可接受输入}
确保键是用于评估给定任务的标准。"accepted_values" 包括每个键的可接受输入,这些输入应该是细粒度的,最好是多级别的。"description" 包括标准的描述。
只返回字典。"""
)
接下来,评论家将获得任务执行的成功和失败示例;然后,它能够返回一系列的标准(图1)。请参考以下笔记本。
QuantifierAgent的目标是量化每个建议的标准(图1),从而让我们了解该系统在给定任务中的效用。以下是如何定义它的示例:
quantifier = autogen.AssistantAgent(
name="quantifier",
llm_config={"config_list": config_list},
system_message = """You are a helpful assistant. You quantify the output of different tasks based on the given criteria.
The criterion is given in a dictionary format where each key is a distinct criteria.
The value of each key is a dictionary as follows {"description": criteria description , "accepted_values": possible accepted inputs for this key}
You are going to quantify each of the criteria for a given task based on the task description.
Return a dictionary where the keys are the criteria and the values are the assessed performance based on accepted values for each criteria.
Return only the dictionary."""
)
基于数学问题数据集的 AgentEval 结果
例如,运行 CriticAgent 后,我们获得了以下标准来验证数学问题数据集的结果:
| 标准 | 描述 | 可接受的值 |
|---|---|---|
| 问题解释 | 正确解释问题的能力 | ["完全错误", "稍微相关", "相关", "大部分准确", "完全准确"] |
| 数学方法 | 选择的数学或算法方法对于问题的适当性 | ["不适当", "勉强合适", "合适", "大部分有效", "完全有效"] |
| 计算正确性 | 计算的准确性和给出的解决方案 | ["完全不正确", "大部分不正确", "无法确定", "大部分正确", "完全正确"] |
| 解释清晰度 | 解释的清晰度和可理解性,包括语言使用和结构 | ["完全不清晰", "稍微清晰", "中等清晰", "非常清晰", "完全清晰"] |
| 代码效率 | 代码的质量,包括效率和优雅程度 | ["完全不高效", "稍微高效", "中等高效", "非常高效", "极其高效"] |
| 代码正确性 | 提供的代码的正确性 | ["完全不正确", "大部分不正确", "部分正确", "大部分正确", "完全正确"] |
然后,运行 QuantifierAgent 后,我们获得了图3中呈现的结果,其中您可以看到三个模型:
- AgentChat
- ReAct
- GPT-4 Vanilla Solver
较浅的颜色表示失败案例的估计,较亮的颜色显示了发现的标准是如何被量化的。
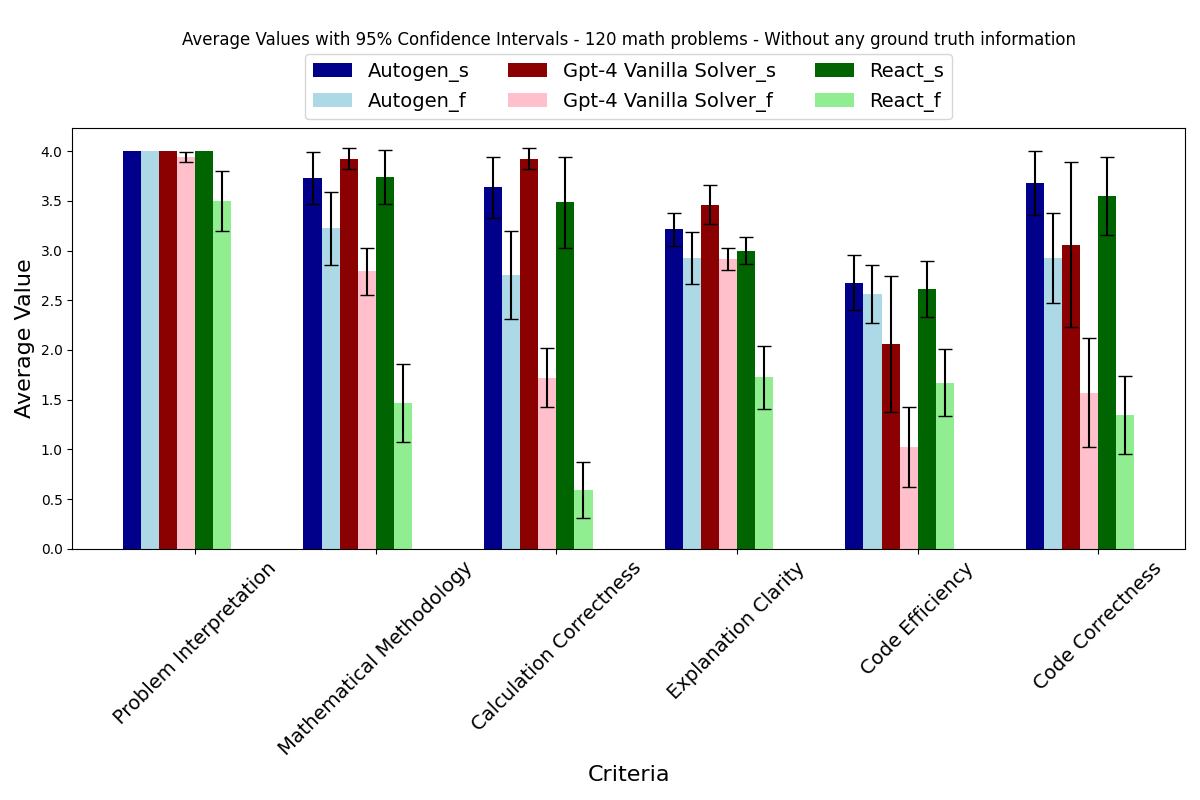
图3显示了基于整体数学问题数据集的结果,_s代表成功案例,_f代表失败案例
我们注意到,在应用AgentEval到数学问题时,该代理并没有接触到任何关于问题的真实信息。因此,这个图表展示了三个不同代理(Autogen(蓝色)、Gpt-4(红色)和ReAct(绿色))的估计性能。通过比较任何一个代理在成功案例(任何颜色的深色条形)和失败案例(同一条形的浅色版本)中的表现,我们可以观察到AgentEval能够给成功案例分配比失败案例更高的量化值。这个观察结果验证了AgentEval在任务效用预测方面的能力。此外,AgentEval还允许我们超越对成功的二元定义,实现对成功和失败案例的更深入比较。
重要的是,不仅要识别出不起作用的原因,还要认识到什么以及为什么实际上做得好。
限制和未来工作
目前的AgentEval实现存在一些限制,我们计划在未来克服这些限制:
- 根据每次运行的不同,评估标准的列表也会有所变化(除非您存储了一个种子)。我们建议至少运行
CriticAgent两次,并选择您认为对您的领域重要的标准。 QuantifierAgent的结果可能会随每次运行而变化,因此我们建议进行多次运行以观察结果变化的程度。
为了缓解上述限制,我们正在开发VerifierAgent,其目标是稳定结果并提供额外的解释。
总结
CriticAgent和QuantifierAgent可以应用于任何类型应用的日志,为您提供对您的解决方案在给定任务中为用户带来的效用的深入理解。
我们很想听听AgentEval在您的应用中的表现如何。任何反馈对未来的发展都将非常有用。请通过我们的Discord与我们联系。
先前的研究
@InProceedings{pmlr-v176-kiseleva22a,
title = "在协作环境中的交互式基于场景的语言理解:IGLU 2021",
author = "Kiseleva, Julia and Li, Ziming and Aliannejadi, Mohammad and Mohanty, Shrestha and ter Hoeve, Maartje and Burtsev, Mikhail and Skrynnik, Alexey and Zholus, Artem and Panov, Aleksandr and Srinet, Kavya and Szlam, Arthur and Sun, Yuxuan and Hofmann, Katja and C{\^o}t{\'e}, Marc-Alexandre and Awadallah, Ahmed and Abdrazakov, Linar and Churin, Igor and Manggala, Putra and Naszadi, Kata and van der Meer, Michiel and Kim, Taewoon",
booktitle = "NeurIPS 2021竞赛和演示论文集",
pages = "146--161",
year = 2022,
editor = "Kiela, Douwe and Ciccone, Marco and Caputo, Barbara",
volume = 176,
series = "机器学习研究论文集",
month = "12月6日至14日",
publisher = "PMLR",
pdf = {https://proceedings.mlr.press/v176/kiseleva22a/kiseleva22a.pdf},
url = {https://proceedings.mlr.press/v176/kiseleva22a.html}.
}
@InProceedings{pmlr-v220-kiseleva22a,
title = "在协作环境中的交互式基于场景的语言理解:Iglu 2022竞赛回顾",
author = "Kiseleva, Julia and Skrynnik, Alexey and Zholus, Artem and Mohanty, Shrestha and Arabzadeh, Negar and C\^{o}t\'e, Marc-Alexandre and Aliannejadi, Mohammad and Teruel, Milagro and Li, Ziming and Burtsev, Mikhail and ter Hoeve, Maartje and Volovikova, Zoya and Panov, Aleksandr and Sun, Yuxuan and Srinet, Kavya and Szlam, Arthur and Awadallah, Ahmed and Rho, Seungeun and Kwon, Taehwan and Wontae Nam, Daniel and Bivort Haiek, Felipe and Zhang, Edwin and Abdrazakov, Linar and Qingyam, Guo and Zhang, Jason and Guo, Zhibin",
booktitle = "NeurIPS 2022竞赛论文集",
pages = "204--216",
year = 2022,
editor = "Ciccone, Marco and Stolovitzky, Gustavo and Albrecht, Jacob",
volume = 220,
series = "机器学习研究论文集",
month = "11月28日--12月9日",
publisher = "PMLR",
pdf = "https://proceedings.mlr.press/v220/kiseleva22a/kiseleva22a.pdf",
url = "https://proceedings.mlr.press/v220/kiseleva22a.html".
}