自定义发言者选择
在 GroupChat 中,我们可以通过将函数传递给 speaker_selection_method 来自定义发言者的选择:
def custom_speaker_selection_func(
last_speaker: Agent,
groupchat: GroupChat
) -> Union[Agent, Literal['auto', 'manual', 'random' 'round_robin'], None]:
"""定义一个自定义的发言者选择函数。
一种推荐的方式是为群聊中的每个发言者定义一个转换。
参数:
- last_speaker: Agent
群聊中的上一个发言者。
- groupchat: GroupChat
GroupChat 对象。
返回:
返回以下之一:
1. 一个 `Agent` 类,必须是群聊中的一个代理。
2. 一个字符串,来自 ['auto', 'manual', 'random', 'round_robin'],用于选择默认方法。
3. None,表示聊天应该终止。
"""
pass
groupchat = autogen.GroupChat(
speaker_selection_method=custom_speaker_selection_func,
...,
)
函数中传递了上一个发言者和群聊对象。常用的群聊变量有 groupchat.messages 和 groupchat.agents,分��别表示消息历史和群聊中的代理。您可以访问群聊的其他属性,例如 groupchat.allowed_speaker_transitions_dict,用于预定义的 allowed_speaker_transitions_dict。
下面是一个使用自定义发言者选择的研究工作流程的简单示例。
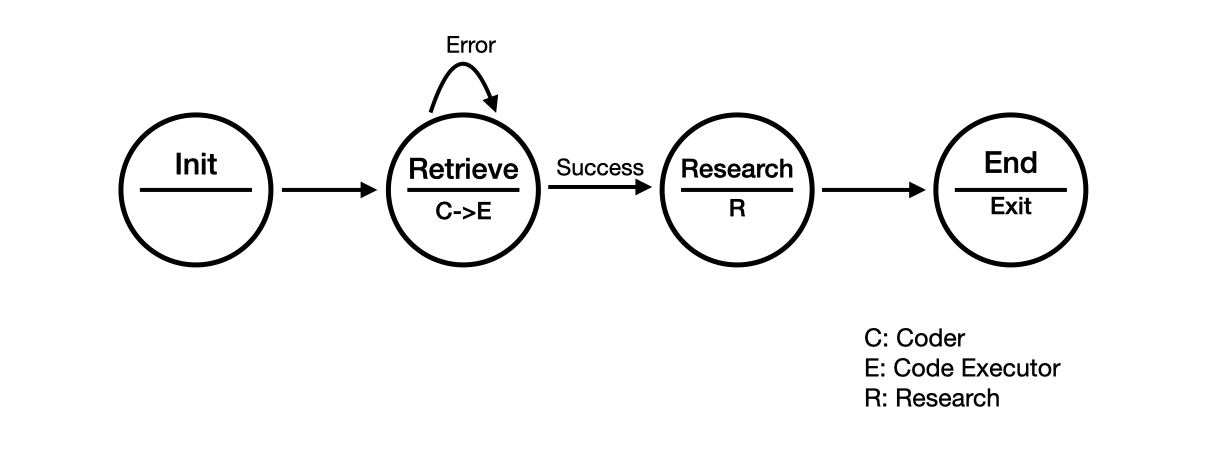
我们定义了以下代理:
- Initializer:通过发送任务开始工作流程。
- Coder:通过编写代码从互联网上获取论文。
- Executor:执行代码。
- Scientist:阅读论文并撰写摘要。
在图中,我们定义了一个简单的研究工作流程,包含 4 个状态:Init、Retrieve、Research 和 End。在每个状态中,我们将调用不同的代理来执行任务。
Init:我们使用 Initializer 来启动工作流程。Retrieve:我们首先调用 Coder 来编写代码,然后调用 Executor 来执行代码。Research:我们将调用 Scientist 来阅读论文并撰写摘要。End:我们将结束工作流程。
import os
import autogen
# 将您的 API 密钥放在环境变量 OPENAI_API_KEY 中
config_list = [
{
"model": "gpt-4-0125-preview",
"api_key": os.environ["OPENAI_API_KEY"],
}
]
# 您还可以创建一个名为 "OAI_CONFIG_LIST" 的文件,并将配置存储在其中
# config_list = autogen.config_list_from_json(
# "OAI_CONFIG_LIST",
# filter_dict={
# "model": ["gpt-4-0125-preview"],
# },
# )
gpt4_config = {
"cache_seed": 42, # 更改 cache_seed 以进行不同的试验
"temperature": 0,
"config_list": config_list,
"timeout": 120,
}
initializer = autogen.UserProxyAgent(
name="初始化",
)
coder = autogen.AssistantAgent(
name="检索_动作_1",
llm_config=gpt4_config,
system_message="""你是编码器。给定一个主题,编写代码从 arXiv API 中检索相关论文,并打印它们的标题、作者、摘要和链接。
你可以使用 Python/Shell 代码来解决任务。将代码放在代码块中,并指定脚本类型。用户无法修改你的代码,因此不要提供需要其他人修改的不完整代码。如果代码块不打算由执行器执行,请不要使用代码块。
一个回答中不要包含多个代码块。不要要求其他人复制粘贴结果。检查执行器返回的执行结果。
如果结果表明存在错误,请修复错误并重新输出代码。建议提供完整的代码,而不是部分代码或代码更改。如果错误无法修复,或者即使成功执行代码后任务仍未解决,请分析问题,重新审视你的假设,收集所需的其他信息,并考虑尝试不同的方法。
""",
)
executor = autogen.UserProxyAgent(
name="检索_动作_2",
system_message="执行器。执行编码器编写的代码并报告结果。",
human_input_mode="NEVER",
code_execution_config={
"last_n_messages": 3,
"work_dir": "paper",
"use_docker": False,
}, # 如果有可用的 Docker 来运行生成的代码,请将 use_docker 设置为 True。使用 Docker 比直接运行生成的代码更安全。
)
scientist = autogen.AssistantAgent(
name="研究_动作_1",
llm_config=gpt4_config,
system_message="""你是科学家。在打印出论文摘要后,请对论文进行分类,并创建一个带有领域、标题、作者、摘要和链接的 Markdown 表格。
""",
)
def state_transition(last_speaker, groupchat):
messages = groupchat.messages
if last_speaker is initializer:
# 初始化 -> 检索
return coder
elif last_speaker is coder:
# 检索:动作 1 -> 动作 2
return executor
elif last_speaker is executor:
if messages[-1]["content"] == "exitcode: 1":
# 检索 --(执行失败)--> 检索
return coder
else:
# 检索 --(执行成功)--> 研究
return scientist
elif last_speaker == "Scientist":
# 研究 -> 结束
return None
groupchat = autogen.GroupChat(
agents=[initializer, coder, executor, scientist],
messages=[],
max_round=20,
speaker_selection_method=state_transition,
)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=gpt4_config)
initializer.initiate_chat(
manager, message="话题:上周的LLM申请论文。要求:来自不同领域的5-10篇论文。"
)
初始化(给 chat_manager):
话题:上周的 LLM 应用论文。要求:来自不同领域的 5 - 10 篇论文。
--------------------------------------------------------------------------------
Retrieve_Action_1(给 chat_manager):
要从 arXiv API 检索相关论文,我们可以使用 Python 和 `requests` 库向 API 发送查询并解析响应。下面是一个 Python 脚本,它搜索与“LLM 应用”(Large Language Models 应用)相关的论文(上周的),跨越不同领域,并打印出 5 到 10 篇论文的所需信息。
```python
import requests
from datetime import datetime, timedelta
import feedparser
# 定义 arXiv API 的基本 URL
ARXIV_API_URL = 'http://export.arxiv.org/api/query?'
# 定义搜索参数
search_query = 'all:"LLM applications"'
start_date = (datetime.now() - timedelta(days=7)).strftime('%Y%m%d%H%M%S')
end_date = datetime.now().strftime('%Y%m%d%H%M%S')
start = 0
max_results = 10
sort_by = 'submittedDate'
sort_order = 'descending'
# 构造查询
query = f'search_query={search_query}&sortBy={sort_by}&sortOrder={sort_order}&start={start}&max_results={max_results}'
# 发送请求到 arXiv API
response = requests.get(ARXIV_API_URL + query)
# 使用 feedparser 解析响应
feed = feedparser.parse(response.content)
# 打印每篇论文的标题、作者、摘要和链接
for entry in feed.entries:
print("标题:", entry.title)
print("作者:", ', '.join(author.name for author in entry.authors))
print("摘要:", entry.summary)
print("链接:", entry.link)
print("\n")
# 检查是否有至少 5 篇论文,如果没有,则调整搜索或通知
if len(feed.entries) < 5:
print("找到的论文少于 5 篇。考虑调整搜索参数或时间范围。")
```
This script will print the title, authors, abstract, and link for each paper related to "LLM applications" from the last week, up to a maximum of 10 papers. If fewer than 5 papers are found, it will notify the user to consider adjusting the search parameters or timeframe.
--------------------------------------------------------------------------------
>>>>>>>> EXECUTING CODE BLOCK 0 (inferred language is python)...
exitcode: 0 (execution succeeded)
Code output:
Title: PRSA: Prompt Reverse Stealing Attacks against Large Language Models
Authors: Yong Yang, Xuhong Zhang, Yi Jiang, Xi Chen, Haoyu Wang, Shouling Ji, Zonghui Wang
Abstract: Prompt, recognized as crucial intellectual property, enables large language
models (LLMs) to perform specific tasks without the need of fine-tuning,
underscoring their escalating importance. With the rise of prompt-based
services, such as prompt marketplaces and LLM applications, providers often
display prompts' capabilities through input-output examples to attract users.
However, this paradigm raises a pivotal security concern: does the exposure of
input-output pairs pose the risk of potential prompt leakage, infringing on the
intellectual property rights of the developers? To our knowledge, this problem
still has not been comprehensively explored yet. To remedy this gap, in this
paper, we perform the first in depth exploration and propose a novel attack
framework for reverse-stealing prompts against commercial LLMs, namely PRSA.
The main idea of PRSA is that by analyzing the critical features of the
input-output pairs, we mimic and gradually infer (steal) the target prompts. In
detail, PRSA mainly consists of two key phases: prompt mutation and prompt
pruning. In the mutation phase, we propose a prompt attention algorithm based
on differential feedback to capture these critical features for effectively
inferring the target prompts. In the prompt pruning phase, we identify and mask
the words dependent on specific inputs, enabling the prompts to accommodate
diverse inputs for generalization. Through extensive evaluation, we verify that
PRSA poses a severe threat in real world scenarios. We have reported these
findings to prompt service providers and actively collaborate with them to take
protective measures for prompt copyright.
Link: http://arxiv.org/abs/2402.19200v1
Title: Political Compass or Spinning Arrow? Towards More Meaningful Evaluations
for Values and Opinions in Large Language Models
Authors: Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, Dirk Hovy
Abstract: Much recent work seeks to evaluate values and opinions in large language
models (LLMs) using multiple-choice surveys and questionnaires. Most of this
work is motivated by concerns around real-world LLM applications. For example,
politically-biased LLMs may subtly influence society when they are used by
millions of people. Such real-world concerns, however, stand in stark contrast
to the artificiality of current evaluations: real users do not typically ask
LLMs survey questions. Motivated by this discrepancy, we challenge the
prevailing constrained evaluation paradigm for values and opinions in LLMs and
explore more realistic unconstrained evaluations. As a case study, we focus on
the popular Political Compass Test (PCT). In a systematic review, we find that
most prior work using the PCT forces models to comply with the PCT's
multiple-choice format. We show that models give substantively different
answers when not forced; that answers change depending on how models are
forced; and that answers lack paraphrase robustness. Then, we demonstrate that
models give different answers yet again in a more realistic open-ended answer
setting. We distill these findings into recommendations and open challenges in
evaluating values and opinions in LLMs.
Link: http://arxiv.org/abs/2402.16786v1
Title: Large Language Models as Urban Residents: An LLM Agent Framework for
Personal Mobility Generation
Authors: Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Chuan Xiao
Abstract: This paper introduces a novel approach using Large Language Models (LLMs)
integrated into an agent framework for flexible and efficient personal mobility
generation. LLMs overcome the limitations of previous models by efficiently
processing semantic data and offering versatility in modeling various tasks.
Our approach addresses the critical need to align LLMs with real-world urban
mobility data, focusing on three research questions: aligning LLMs with rich
activity data, developing reliable activity generation strategies, and
exploring LLM applications in urban mobility. The key technical contribution is
a novel LLM agent framework that accounts for individual activity patterns and
motivations, including a self-consistency approach to align LLMs with
real-world activity data and a retrieval-augmented strategy for interpretable
activity generation. In experimental studies, comprehensive validation is
performed using real-world data. This research marks the pioneering work of
designing an LLM agent framework for activity generation based on real-world
human activity data, offering a promising tool for urban mobility analysis.
Link: http://arxiv.org/abs/2402.14744v1
Title: An Evaluation of Large Language Models in Bioinformatics Research
Authors: Hengchuang Yin, Zhonghui Gu, Fanhao Wang, Yiparemu Abuduhaibaier, Yanqiao Zhu, Xinming Tu, Xian-Sheng Hua, Xiao Luo, Yizhou Sun
Abstract: Large language models (LLMs) such as ChatGPT have gained considerable
interest across diverse research communities. Their notable ability for text
completion and generation has inaugurated a novel paradigm for
language-interfaced problem solving. However, the potential and efficacy of
these models in bioinformatics remain incompletely explored. In this work, we
study the performance LLMs on a wide spectrum of crucial bioinformatics tasks.
These tasks include the identification of potential coding regions, extraction
of named entities for genes and proteins, detection of antimicrobial and
anti-cancer peptides, molecular optimization, and resolution of educational
bioinformatics problems. Our findings indicate that, given appropriate prompts,
LLMs like GPT variants can successfully handle most of these tasks. In
addition, we provide a thorough analysis of their limitations in the context of
complicated bioinformatics tasks. In conclusion, we believe that this work can
provide new perspectives and motivate future research in the field of LLMs
applications, AI for Science and bioinformatics.
Link: http://arxiv.org/abs/2402.13714v1
Title: Privacy-Preserving Instructions for Aligning Large Language Models
Authors: Da Yu, Peter Kairouz, Sewoong Oh, Zheng Xu
Abstract: Service providers of large language model (LLM) applications collect user
instructions in the wild and use them in further aligning LLMs with users'
intentions. These instructions, which potentially contain sensitive
information, are annotated by human workers in the process. This poses a new
privacy risk not addressed by the typical private optimization. To this end, we
propose using synthetic instructions to replace real instructions in data
annotation and model fine-tuning. Formal differential privacy is guaranteed by
generating those synthetic instructions using privately fine-tuned generators.
Crucial in achieving the desired utility is our novel filtering algorithm that
matches the distribution of the synthetic instructions to that of the real
ones. In both supervised fine-tuning and reinforcement learning from human
feedback, our extensive experiments demonstrate the high utility of the final
set of synthetic instructions by showing comparable results to real
instructions. In supervised fine-tuning, models trained with private synthetic
instructions outperform leading open-source models such as Vicuna.
Link: http://arxiv.org/abs/2402.13659v1
Title: Ain't Misbehavin' -- Using LLMs to Generate Expressive Robot Behavior in
Conversations with the Tabletop Robot Haru
Authors: Zining Wang, Paul Reisert, Eric Nichols, Randy Gomez
Abstract: Social robots aim to establish long-term bonds with humans through engaging
conversation. However, traditional conversational approaches, reliant on
scripted interactions, often fall short in maintaining engaging conversations.
This paper addresses this limitation by integrating large language models
(LLMs) into social robots to achieve more dynamic and expressive conversations.
We introduce a fully-automated conversation system that leverages LLMs to
generate robot responses with expressive behaviors, congruent with the robot's
personality. We incorporate robot behavior with two modalities: 1) a
text-to-speech (TTS) engine capable of various delivery styles, and 2) a
library of physical actions for the robot. We develop a custom,
state-of-the-art emotion recognition model to dynamically select the robot's
tone of voice and utilize emojis from LLM output as cues for generating robot
actions. A demo of our system is available here. To illuminate design and
implementation issues, we conduct a pilot study where volunteers chat with a
social robot using our proposed system, and we analyze their feedback,
conducting a rigorous error analysis of chat transcripts. Feedback was
overwhelmingly positive, with participants commenting on the robot's empathy,
helpfulness, naturalness, and entertainment. Most negative feedback was due to
automatic speech recognition (ASR) errors which had limited impact on
conversations. However, we observed a small class of errors, such as the LLM
repeating itself or hallucinating fictitious information and human responses,
that have the potential to derail conversations, raising important issues for
LLM application.
Link: http://arxiv.org/abs/2402.11571v1
Title: Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots
in Ophthalmology and LLM-based evaluation using GPT-4
Authors: Ting Fang Tan, Kabilan Elangovan, Liyuan Jin, Yao Jie, Li Yong, Joshua Lim, Stanley Poh, Wei Yan Ng, Daniel Lim, Yuhe Ke, Nan Liu, Daniel Shu Wei Ting
Abstract: Purpose: To assess the alignment of GPT-4-based evaluation to human clinician
experts, for the evaluation of responses to ophthalmology-related patient
queries generated by fine-tuned LLM chatbots. Methods: 400 ophthalmology
questions and paired answers were created by ophthalmologists to represent
commonly asked patient questions, divided into fine-tuning (368; 92%), and
testing (40; 8%). We find-tuned 5 different LLMs, including LLAMA2-7b,
LLAMA2-7b-Chat, LLAMA2-13b, and LLAMA2-13b-Chat. For the testing dataset,
additional 8 glaucoma QnA pairs were included. 200 responses to the testing
dataset were generated by 5 fine-tuned LLMs for evaluation. A customized
clinical evaluation rubric was used to guide GPT-4 evaluation, grounded on
clinical accuracy, relevance, patient safety, and ease of understanding. GPT-4
evaluation was then compared against ranking by 5 clinicians for clinical
alignment. Results: Among all fine-tuned LLMs, GPT-3.5 scored the highest
(87.1%), followed by LLAMA2-13b (80.9%), LLAMA2-13b-chat (75.5%),
LLAMA2-7b-Chat (70%) and LLAMA2-7b (68.8%) based on the GPT-4 evaluation. GPT-4
evaluation demonstrated significant agreement with human clinician rankings,
with Spearman and Kendall Tau correlation coefficients of 0.90 and 0.80
respectively; while correlation based on Cohen Kappa was more modest at 0.50.
Notably, qualitative analysis and the glaucoma sub-analysis revealed clinical
inaccuracies in the LLM-generated responses, which were appropriately
identified by the GPT-4 evaluation. Conclusion: The notable clinical alignment
of GPT-4 evaluation highlighted its potential to streamline the clinical
evaluation of LLM chatbot responses to healthcare-related queries. By
complementing the existing clinician-dependent manual grading, this efficient
and automated evaluation could assist the validation of future developments in
LLM applications for healthcare.
Link: http://arxiv.org/abs/2402.10083v1
Title: Unmemorization in Large Language Models via Self-Distillation and
Deliberate Imagination
Authors: Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić
Abstract: While displaying impressive generation capabilities across many tasks, Large
Language Models (LLMs) still struggle with crucial issues of privacy violation
and unwanted exposure of sensitive data. This raises an essential question: how
should we prevent such undesired behavior of LLMs while maintaining their
strong generation and natural language understanding (NLU) capabilities? In
this work, we introduce a novel approach termed deliberate imagination in the
context of LLM unlearning. Instead of trying to forget memorized data, we
employ a self-distillation framework, guiding LLMs to deliberately imagine
alternative scenarios. As demonstrated in a wide range of experiments, the
proposed method not only effectively unlearns targeted text but also preserves
the LLMs' capabilities in open-ended generation tasks as well as in NLU tasks.
Our results demonstrate the usefulness of this approach across different models
and sizes, and also with parameter-efficient fine-tuning, offering a novel
pathway to addressing the challenges with private and sensitive data in LLM
applications.
Link: http://arxiv.org/abs/2402.10052v1
Title: Anchor-based Large Language Models
Authors: Jianhui Pang, Fanghua Ye, Derek F. Wong, Longyue Wang
Abstract: Large language models (LLMs) predominantly employ decoder-only transformer
architectures, necessitating the retention of keys/values information for
historical tokens to provide contextual information and avoid redundant
computation. However, the substantial size and parameter volume of these LLMs
require massive GPU memory. This memory demand increases with the length of the
input text, leading to an urgent need for more efficient methods of information
storage and processing. This study introduces Anchor-based LLMs (AnLLMs), which
utilize an innovative anchor-based self-attention network (AnSAN) and also an
anchor-based inference strategy. This approach enables LLMs to compress
sequence information into an anchor token, reducing the keys/values cache and
enhancing inference efficiency. Experiments on question-answering benchmarks
reveal that AnLLMs maintain similar accuracy levels while achieving up to 99%
keys/values cache reduction and up to 3.5 times faster inference. Despite a
minor compromise in accuracy, the substantial enhancements of AnLLMs employing
the AnSAN technique in resource utilization and computational efficiency
underscore their potential for practical LLM applications.
Link: http://arxiv.org/abs/2402.07616v2
Title: T-RAG: Lessons from the LLM Trenches
Authors: Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla
Abstract: Large Language Models (LLM) have shown remarkable language capabilities
fueling attempts to integrate them into applications across a wide range of
domains. An important application area is question answering over private
enterprise documents where the main considerations are data security, which
necessitates applications that can be deployed on-prem, limited computational
resources and the need for a robust application that correctly responds to
queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent
framework for building LLM-based applications. While building a RAG is
relatively straightforward, making it robust and a reliable application
requires extensive customization and relatively deep knowledge of the
application domain. We share our experiences building and deploying an LLM
application for question answering over private organizational documents. Our
application combines the use of RAG with a finetuned open-source LLM.
Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure
to represent entity hierarchies within the organization. This is used to
generate a textual description to augment the context when responding to user
queries pertaining to entities within the organization's hierarchy. Our
evaluations show that this combination performs better than a simple RAG or
finetuning implementation. Finally, we share some lessons learned based on our
experiences building an LLM application for real-world use.
Link: http://arxiv.org/abs/2402.07483v1
--------------------------------------------------------------------------------
Based on the retrieved abstracts, here is a markdown table categorizing the papers by domain, along with their titles, authors, summaries, and links:
| Domain | Title | Authors | Summary | Link |
|--------|-------|---------|---------|------|
| Security | PRSA: Prompt Reverse Stealing Attacks against Large Language Models | Yong Yang, Xuhong Zhang, Yi Jiang, Xi Chen, Haoyu Wang, Shouling Ji, Zonghui Wang | The paper explores the security risks associated with exposing input-output pairs of prompts used in LLMs and proposes a novel attack framework, PRSA, to reverse-steal prompts, posing a threat to intellectual property rights. | [Link](http://arxiv.org/abs/2402.19200v1) |
| Ethics & Evaluation | Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models | Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, Dirk Hovy | This work challenges the constrained evaluation paradigm for values and opinions in LLMs and explores more realistic unconstrained evaluations, focusing on the Political Compass Test (PCT). | [Link](http://arxiv.org/abs/2402.16786v1) |
| Urban Mobility | Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation | Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Chuan Xiao | Introduces an LLM agent framework for personal mobility generation, aligning LLMs with real-world urban mobility data, and offering a tool for urban mobility analysis. | [Link](http://arxiv.org/abs/2402.14744v1) |
| Bioinformatics | An Evaluation of Large Language Models in Bioinformatics Research | Hengchuang Yin, Zhonghui Gu, Fanhao Wang, Yiparemu Abuduhaibaier, Yanqiao Zhu, Xinming Tu, Xian-Sheng Hua, Xiao Luo, Yizhou Sun | Evaluates the performance of LLMs on bioinformatics tasks, highlighting their potential and limitations, and motivating future research in LLM applications in bioinformatics. | [Link](http://arxiv.org/abs/2402.13714v1) |
| Privacy | Privacy-Preserving Instructions for Aligning Large Language Models | Da Yu, Peter Kairouz, Sewoong Oh, Zheng Xu | Proposes using synthetic instructions generated by privately fine-tuned generators to replace real instructions in data annotation and model fine-tuning, ensuring privacy while maintaining utility. | [Link](http://arxiv.org/abs/2402.13659v1) |
| Social Robotics | Ain't Misbehavin' -- Using LLMs to Generate Expressive Robot Behavior in Conversations with the Tabletop Robot Haru | Zining Wang, Paul Reisert, Eric Nichols, Randy Gomez | Integrates LLMs into social robots to generate dynamic and expressive conversations, using a text-to-speech engine and a library of physical actions for the robot. | [Link](http://arxiv.org/abs/2402.11571v1) |
| Ophthalmology | Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots in Ophthalmology and LLM-based evaluation using GPT-4 | Ting Fang Tan, Kabilan Elangovan, Liyuan Jin, Yao Jie, Li Yong, Joshua Lim, Stanley Poh, Wei Yan Ng, Daniel Lim, Yuhe Ke, Nan Liu, Daniel Shu Wei Ting | Assesses the alignment of GPT-4-based evaluation to human clinician experts for evaluating responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. | [Link](http://arxiv.org/abs/2402.10083v1) |
| Privacy & Data Security | Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination | Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić | Introduces a novel approach for LLM unlearning by guiding LLMs to imagine alternative scenarios, effectively unlearning targeted text while preserving generation and NLU capabilities. | [Link](http://arxiv.org/abs/2402.10052v1) |
| Computational Efficiency | Anchor-based Large Language Models | Jianhui Pang, Fanghua Ye, Derek F. Wong, Longyue Wang | Proposes Anchor-based LLMs (AnLLMs) with an innovative anchor-based self-attention network (AnSAN) to reduce memory demand and enhance inference efficiency. | [Link](http://arxiv.org/abs/2402.07616v2) |
| Enterprise Applications | T-RAG: Lessons from the LLM Trenches | Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla | Shares experiences building and deploying an LLM application for question answering over private organizational documents, combining RAG with a finetuned LLM and a tree structure for entity hierarchies. | [Link](http://arxiv.org/abs/2402.07483v1) |
These papers cover a range of domains including security, ethics, urban mobility, bioinformatics, privacy, social robotics, ophthalmology, data security, computational efficiency, and enterprise applications, showcasing the diverse applications of large language models.
--------------------------------------------------------------------------------
标题一
这是一段关于标题一的内容。这里可以写一些关于标题一的背景信息和重要细节。
子标题一
这是子标题一的内容。在这里可以详细介绍子标题一的相关内容。
子标题二
这是子标题二的内容。在这里可以详细介绍子标题二的相关内容。
标题二
这是一段关于标题二的内容。这里可以写一些关于标题二的背景信息和重要细节。
子标题一
这是子标题一的内容。在这里可以详细介绍子标题一的相关内容。
子标题二
这是子标题二的内容。在这里可以详细介绍子标题二的相关内容。
参考文献
[1] 引用文献一
[2] 引用文献二
[3] 引用文献三
ChatResult(chat_id=None, chat_history=[{'content': 'Topic: LLM applications papers from last week. Requirement: 5 - 10 papers from different domains.', 'role': 'assistant'}, {'content': 'To retrieve related papers from the arXiv API, we can use Python with the `requests` library to send a query to the API and parse the response. Below is a Python script that searches for papers related to "LLM applications" (Large Language Models applications) from the last week, across different domains, and prints out the required information for 5 to 10 papers.\n\n```python\nimport requests\nfrom datetime import datetime, timedelta\nimport feedparser\n\n# Define the base URL for the arXiv API\nARXIV_API_URL = \'http://export.arxiv.org/api/query?\'\n\n# Define the search parameters\nsearch_query = \'all:"LLM applications"\'\nstart_date = (datetime.now() - timedelta(days=7)).strftime(\'%Y%m%d%H%M%S\')\nend_date = datetime.now().strftime(\'%Y%m%d%H%M%S\')\nstart = 0\nmax_results = 10\nsort_by = \'submittedDate\'\nsort_order = \'descending\'\n\n# Construct the query\nquery = f\'search_query={search_query}&sortBy={sort_by}&sortOrder={sort_order}&start={start}&max_results={max_results}\'\n\n# Send the request to the arXiv API\nresponse = requests.get(ARXIV_API_URL + query)\n\n# Parse the response using feedparser\nfeed = feedparser.parse(response.content)\n\n# Print the title, authors, abstract, and link of each paper\nfor entry in feed.entries:\n print("Title:", entry.title)\n print("Authors:", \', \'.join(author.name for author in entry.authors))\n print("Abstract:", entry.summary)\n print("Link:", entry.link)\n print("\\n")\n\n# Check if we have at least 5 papers, if not, adjust the search or notify\nif len(feed.entries) < 5:\n print("Less than 5 papers found. Consider adjusting the search parameters or timeframe.")\n```\n\nThis script will print the title, authors, abstract, and link for each paper related to "LLM applications" from the last week, up to a maximum of 10 papers. If fewer than 5 papers are found, it will notify the user to consider adjusting the search parameters or timeframe.', 'name': 'Retrieve_Action_1', 'role': 'user'}, {'content': "exitcode: 0 (execution succeeded)\nCode output: \nTitle: PRSA: Prompt Reverse Stealing Attacks against Large Language Models\nAuthors: Yong Yang, Xuhong Zhang, Yi Jiang, Xi Chen, Haoyu Wang, Shouling Ji, Zonghui Wang\nAbstract: Prompt, recognized as crucial intellectual property, enables large language\nmodels (LLMs) to perform specific tasks without the need of fine-tuning,\nunderscoring their escalating importance. With the rise of prompt-based\nservices, such as prompt marketplaces and LLM applications, providers often\ndisplay prompts' capabilities through input-output examples to attract users.\nHowever, this paradigm raises a pivotal security concern: does the exposure of\ninput-output pairs pose the risk of potential prompt leakage, infringing on the\nintellectual property rights of the developers? To our knowledge, this problem\nstill has not been comprehensively explored yet. To remedy this gap, in this\npaper, we perform the first in depth exploration and propose a novel attack\nframework for reverse-stealing prompts against commercial LLMs, namely PRSA.\nThe main idea of PRSA is that by analyzing the critical features of the\ninput-output pairs, we mimic and gradually infer (steal) the target prompts. In\ndetail, PRSA mainly consists of two key phases: prompt mutation and prompt\npruning. In the mutation phase, we propose a prompt attention algorithm based\non differential feedback to capture these critical features for effectively\ninferring the target prompts. In the prompt pruning phase, we identify and mask\nthe words dependent on specific inputs, enabling the prompts to accommodate\ndiverse inputs for generalization. Through extensive evaluation, we verify that\nPRSA poses a severe threat in real world scenarios. We have reported these\nfindings to prompt service providers and actively collaborate with them to take\nprotective measures for prompt copyright.\nLink: http://arxiv.org/abs/2402.19200v1\n\n\nTitle: Political Compass or Spinning Arrow? Towards More Meaningful Evaluations\n for Values and Opinions in Large Language Models\nAuthors: Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, Dirk Hovy\nAbstract: Much recent work seeks to evaluate values and opinions in large language\nmodels (LLMs) using multiple-choice surveys and questionnaires. Most of this\nwork is motivated by concerns around real-world LLM applications. For example,\npolitically-biased LLMs may subtly influence society when they are used by\nmillions of people. Such real-world concerns, however, stand in stark contrast\nto the artificiality of current evaluations: real users do not typically ask\nLLMs survey questions. Motivated by this discrepancy, we challenge the\nprevailing constrained evaluation paradigm for values and opinions in LLMs and\nexplore more realistic unconstrained evaluations. As a case study, we focus on\nthe popular Political Compass Test (PCT). In a systematic review, we find that\nmost prior work using the PCT forces models to comply with the PCT's\nmultiple-choice format. We show that models give substantively different\nanswers when not forced; that answers change depending on how models are\nforced; and that answers lack paraphrase robustness. Then, we demonstrate that\nmodels give different answers yet again in a more realistic open-ended answer\nsetting. We distill these findings into recommendations and open challenges in\nevaluating values and opinions in LLMs.\nLink: http://arxiv.org/abs/2402.16786v1\n\n\nTitle: Large Language Models as Urban Residents: An LLM Agent Framework for\n Personal Mobility Generation\nAuthors: Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Chuan Xiao\nAbstract: This paper introduces a novel approach using Large Language Models (LLMs)\nintegrated into an agent framework for flexible and efficient personal mobility\ngeneration. LLMs overcome the limitations of previous models by efficiently\nprocessing semantic data and offering versatility in modeling various tasks.\nOur approach addresses the critical need to align LLMs with real-world urban\nmobility data, focusing on three research questions: aligning LLMs with rich\nactivity data, developing reliable activity generation strategies, and\nexploring LLM applications in urban mobility. The key technical contribution is\na novel LLM agent framework that accounts for individual activity patterns and\nmotivations, including a self-consistency approach to align LLMs with\nreal-world activity data and a retrieval-augmented strategy for interpretable\nactivity generation. In experimental studies, comprehensive validation is\nperformed using real-world data. This research marks the pioneering work of\ndesigning an LLM agent framework for activity generation based on real-world\nhuman activity data, offering a promising tool for urban mobility analysis.\nLink: http://arxiv.org/abs/2402.14744v1\n\n\nTitle: An Evaluation of Large Language Models in Bioinformatics Research\nAuthors: Hengchuang Yin, Zhonghui Gu, Fanhao Wang, Yiparemu Abuduhaibaier, Yanqiao Zhu, Xinming Tu, Xian-Sheng Hua, Xiao Luo, Yizhou Sun\nAbstract: Large language models (LLMs) such as ChatGPT have gained considerable\ninterest across diverse research communities. Their notable ability for text\ncompletion and generation has inaugurated a novel paradigm for\nlanguage-interfaced problem solving. However, the potential and efficacy of\nthese models in bioinformatics remain incompletely explored. In this work, we\nstudy the performance LLMs on a wide spectrum of crucial bioinformatics tasks.\nThese tasks include the identification of potential coding regions, extraction\nof named entities for genes and proteins, detection of antimicrobial and\nanti-cancer peptides, molecular optimization, and resolution of educational\nbioinformatics problems. Our findings indicate that, given appropriate prompts,\nLLMs like GPT variants can successfully handle most of these tasks. In\naddition, we provide a thorough analysis of their limitations in the context of\ncomplicated bioinformatics tasks. In conclusion, we believe that this work can\nprovide new perspectives and motivate future research in the field of LLMs\napplications, AI for Science and bioinformatics.\nLink: http://arxiv.org/abs/2402.13714v1\n\n\nTitle: Privacy-Preserving Instructions for Aligning Large Language Models\nAuthors: Da Yu, Peter Kairouz, Sewoong Oh, Zheng Xu\nAbstract: Service providers of large language model (LLM) applications collect user\ninstructions in the wild and use them in further aligning LLMs with users'\nintentions. These instructions, which potentially contain sensitive\ninformation, are annotated by human workers in the process. This poses a new\nprivacy risk not addressed by the typical private optimization. To this end, we\npropose using synthetic instructions to replace real instructions in data\nannotation and model fine-tuning. Formal differential privacy is guaranteed by\ngenerating those synthetic instructions using privately fine-tuned generators.\nCrucial in achieving the desired utility is our novel filtering algorithm that\nmatches the distribution of the synthetic instructions to that of the real\nones. In both supervised fine-tuning and reinforcement learning from human\nfeedback, our extensive experiments demonstrate the high utility of the final\nset of synthetic instructions by showing comparable results to real\ninstructions. In supervised fine-tuning, models trained with private synthetic\ninstructions outperform leading open-source models such as Vicuna.\nLink: http://arxiv.org/abs/2402.13659v1\n\n\nTitle: Ain't Misbehavin' -- Using LLMs to Generate Expressive Robot Behavior in\n Conversations with the Tabletop Robot Haru\nAuthors: Zining Wang, Paul Reisert, Eric Nichols, Randy Gomez\nAbstract: Social robots aim to establish long-term bonds with humans through engaging\nconversation. However, traditional conversational approaches, reliant on\nscripted interactions, often fall short in maintaining engaging conversations.\nThis paper addresses this limitation by integrating large language models\n(LLMs) into social robots to achieve more dynamic and expressive conversations.\nWe introduce a fully-automated conversation system that leverages LLMs to\ngenerate robot responses with expressive behaviors, congruent with the robot's\npersonality. We incorporate robot behavior with two modalities: 1) a\ntext-to-speech (TTS) engine capable of various delivery styles, and 2) a\nlibrary of physical actions for the robot. We develop a custom,\nstate-of-the-art emotion recognition model to dynamically select the robot's\ntone of voice and utilize emojis from LLM output as cues for generating robot\nactions. A demo of our system is available here. To illuminate design and\nimplementation issues, we conduct a pilot study where volunteers chat with a\nsocial robot using our proposed system, and we analyze their feedback,\nconducting a rigorous error analysis of chat transcripts. Feedback was\noverwhelmingly positive, with participants commenting on the robot's empathy,\nhelpfulness, naturalness, and entertainment. Most negative feedback was due to\nautomatic speech recognition (ASR) errors which had limited impact on\nconversations. However, we observed a small class of errors, such as the LLM\nrepeating itself or hallucinating fictitious information and human responses,\nthat have the potential to derail conversations, raising important issues for\nLLM application.\nLink: http://arxiv.org/abs/2402.11571v1\n\n\nTitle: Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots\n in Ophthalmology and LLM-based evaluation using GPT-4\nAuthors: Ting Fang Tan, Kabilan Elangovan, Liyuan Jin, Yao Jie, Li Yong, Joshua Lim, Stanley Poh, Wei Yan Ng, Daniel Lim, Yuhe Ke, Nan Liu, Daniel Shu Wei Ting\nAbstract: Purpose: To assess the alignment of GPT-4-based evaluation to human clinician\nexperts, for the evaluation of responses to ophthalmology-related patient\nqueries generated by fine-tuned LLM chatbots. Methods: 400 ophthalmology\nquestions and paired answers were created by ophthalmologists to represent\ncommonly asked patient questions, divided into fine-tuning (368; 92%), and\ntesting (40; 8%). We find-tuned 5 different LLMs, including LLAMA2-7b,\nLLAMA2-7b-Chat, LLAMA2-13b, and LLAMA2-13b-Chat. For the testing dataset,\nadditional 8 glaucoma QnA pairs were included. 200 responses to the testing\ndataset were generated by 5 fine-tuned LLMs for evaluation. A customized\nclinical evaluation rubric was used to guide GPT-4 evaluation, grounded on\nclinical accuracy, relevance, patient safety, and ease of understanding. GPT-4\nevaluation was then compared against ranking by 5 clinicians for clinical\nalignment. Results: Among all fine-tuned LLMs, GPT-3.5 scored the highest\n(87.1%), followed by LLAMA2-13b (80.9%), LLAMA2-13b-chat (75.5%),\nLLAMA2-7b-Chat (70%) and LLAMA2-7b (68.8%) based on the GPT-4 evaluation. GPT-4\nevaluation demonstrated significant agreement with human clinician rankings,\nwith Spearman and Kendall Tau correlation coefficients of 0.90 and 0.80\nrespectively; while correlation based on Cohen Kappa was more modest at 0.50.\nNotably, qualitative analysis and the glaucoma sub-analysis revealed clinical\ninaccuracies in the LLM-generated responses, which were appropriately\nidentified by the GPT-4 evaluation. Conclusion: The notable clinical alignment\nof GPT-4 evaluation highlighted its potential to streamline the clinical\nevaluation of LLM chatbot responses to healthcare-related queries. By\ncomplementing the existing clinician-dependent manual grading, this efficient\nand automated evaluation could assist the validation of future developments in\nLLM applications for healthcare.\nLink: http://arxiv.org/abs/2402.10083v1\n\n\nTitle: Unmemorization in Large Language Models via Self-Distillation and\n Deliberate Imagination\nAuthors: Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić\nAbstract: While displaying impressive generation capabilities across many tasks, Large\nLanguage Models (LLMs) still struggle with crucial issues of privacy violation\nand unwanted exposure of sensitive data. This raises an essential question: how\nshould we prevent such undesired behavior of LLMs while maintaining their\nstrong generation and natural language understanding (NLU) capabilities? In\nthis work, we introduce a novel approach termed deliberate imagination in the\ncontext of LLM unlearning. Instead of trying to forget memorized data, we\nemploy a self-distillation framework, guiding LLMs to deliberately imagine\nalternative scenarios. As demonstrated in a wide range of experiments, the\nproposed method not only effectively unlearns targeted text but also preserves\nthe LLMs' capabilities in open-ended generation tasks as well as in NLU tasks.\nOur results demonstrate the usefulness of this approach across different models\nand sizes, and also with parameter-efficient fine-tuning, offering a novel\npathway to addressing the challenges with private and sensitive data in LLM\napplications.\nLink: http://arxiv.org/abs/2402.10052v1\n\n\nTitle: Anchor-based Large Language Models\nAuthors: Jianhui Pang, Fanghua Ye, Derek F. Wong, Longyue Wang\nAbstract: Large language models (LLMs) predominantly employ decoder-only transformer\narchitectures, necessitating the retention of keys/values information for\nhistorical tokens to provide contextual information and avoid redundant\ncomputation. However, the substantial size and parameter volume of these LLMs\nrequire massive GPU memory. This memory demand increases with the length of the\ninput text, leading to an urgent need for more efficient methods of information\nstorage and processing. This study introduces Anchor-based LLMs (AnLLMs), which\nutilize an innovative anchor-based self-attention network (AnSAN) and also an\nanchor-based inference strategy. This approach enables LLMs to compress\nsequence information into an anchor token, reducing the keys/values cache and\nenhancing inference efficiency. Experiments on question-answering benchmarks\nreveal that AnLLMs maintain similar accuracy levels while achieving up to 99%\nkeys/values cache reduction and up to 3.5 times faster inference. Despite a\nminor compromise in accuracy, the substantial enhancements of AnLLMs employing\nthe AnSAN technique in resource utilization and computational efficiency\nunderscore their potential for practical LLM applications.\nLink: http://arxiv.org/abs/2402.07616v2\n\n\nTitle: T-RAG: Lessons from the LLM Trenches\nAuthors: Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla\nAbstract: Large Language Models (LLM) have shown remarkable language capabilities\nfueling attempts to integrate them into applications across a wide range of\ndomains. An important application area is question answering over private\nenterprise documents where the main considerations are data security, which\nnecessitates applications that can be deployed on-prem, limited computational\nresources and the need for a robust application that correctly responds to\nqueries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent\nframework for building LLM-based applications. While building a RAG is\nrelatively straightforward, making it robust and a reliable application\nrequires extensive customization and relatively deep knowledge of the\napplication domain. We share our experiences building and deploying an LLM\napplication for question answering over private organizational documents. Our\napplication combines the use of RAG with a finetuned open-source LLM.\nAdditionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure\nto represent entity hierarchies within the organization. This is used to\ngenerate a textual description to augment the context when responding to user\nqueries pertaining to entities within the organization's hierarchy. Our\nevaluations show that this combination performs better than a simple RAG or\nfinetuning implementation. Finally, we share some lessons learned based on our\nexperiences building an LLM application for real-world use.\nLink: http://arxiv.org/abs/2402.07483v1\n\n\n", 'name': 'Retrieve_Action_2', 'role': 'user'}, {'content': "Based on the retrieved abstracts, here is a markdown table categorizing the papers by domain, along with their titles, authors, summaries, and links:\n\n| Domain | Title | Authors | Summary | Link |\n|--------|-------|---------|---------|------|\n| Security | PRSA: Prompt Reverse Stealing Attacks against Large Language Models | Yong Yang, Xuhong Zhang, Yi Jiang, Xi Chen, Haoyu Wang, Shouling Ji, Zonghui Wang | The paper explores the security risks associated with exposing input-output pairs of prompts used in LLMs and proposes a novel attack framework, PRSA, to reverse-steal prompts, posing a threat to intellectual property rights. | [Link](http://arxiv.org/abs/2402.19200v1) |\n| Ethics & Evaluation | Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models | Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, Dirk Hovy | This work challenges the constrained evaluation paradigm for values and opinions in LLMs and explores more realistic unconstrained evaluations, focusing on the Political Compass Test (PCT). | [Link](http://arxiv.org/abs/2402.16786v1) |\n| Urban Mobility | Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation | Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Chuan Xiao | Introduces an LLM agent framework for personal mobility generation, aligning LLMs with real-world urban mobility data, and offering a tool for urban mobility analysis. | [Link](http://arxiv.org/abs/2402.14744v1) |\n| Bioinformatics | An Evaluation of Large Language Models in Bioinformatics Research | Hengchuang Yin, Zhonghui Gu, Fanhao Wang, Yiparemu Abuduhaibaier, Yanqiao Zhu, Xinming Tu, Xian-Sheng Hua, Xiao Luo, Yizhou Sun | Evaluates the performance of LLMs on bioinformatics tasks, highlighting their potential and limitations, and motivating future research in LLM applications in bioinformatics. | [Link](http://arxiv.org/abs/2402.13714v1) |\n| Privacy | Privacy-Preserving Instructions for Aligning Large Language Models | Da Yu, Peter Kairouz, Sewoong Oh, Zheng Xu | Proposes using synthetic instructions generated by privately fine-tuned generators to replace real instructions in data annotation and model fine-tuning, ensuring privacy while maintaining utility. | [Link](http://arxiv.org/abs/2402.13659v1) |\n| Social Robotics | Ain't Misbehavin' -- Using LLMs to Generate Expressive Robot Behavior in Conversations with the Tabletop Robot Haru | Zining Wang, Paul Reisert, Eric Nichols, Randy Gomez | Integrates LLMs into social robots to generate dynamic and expressive conversations, using a text-to-speech engine and a library of physical actions for the robot. | [Link](http://arxiv.org/abs/2402.11571v1) |\n| Ophthalmology | Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots in Ophthalmology and LLM-based evaluation using GPT-4 | Ting Fang Tan, Kabilan Elangovan, Liyuan Jin, Yao Jie, Li Yong, Joshua Lim, Stanley Poh, Wei Yan Ng, Daniel Lim, Yuhe Ke, Nan Liu, Daniel Shu Wei Ting | Assesses the alignment of GPT-4-based evaluation to human clinician experts for evaluating responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. | [Link](http://arxiv.org/abs/2402.10083v1) |\n| Privacy & Data Security | Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination | Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić | Introduces a novel approach for LLM unlearning by guiding LLMs to imagine alternative scenarios, effectively unlearning targeted text while preserving generation and NLU capabilities. | [Link](http://arxiv.org/abs/2402.10052v1) |\n| Computational Efficiency | Anchor-based Large Language Models | Jianhui Pang, Fanghua Ye, Derek F. Wong, Longyue Wang | Proposes Anchor-based LLMs (AnLLMs) with an innovative anchor-based self-attention network (AnSAN) to reduce memory demand and enhance inference efficiency. | [Link](http://arxiv.org/abs/2402.07616v2) |\n| Enterprise Applications | T-RAG: Lessons from the LLM Trenches | Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla | Shares experiences building and deploying an LLM application for question answering over private organizational documents, combining RAG with a finetuned LLM and a tree structure for entity hierarchies. | [Link](http://arxiv.org/abs/2402.07483v1) |\n\nThese papers cover a range of domains including security, ethics, urban mobility, bioinformatics, privacy, social robotics, ophthalmology, data security, computational efficiency, and enterprise applications, showcasing the diverse applications of large language models.", 'name': 'Research_Action_1', 'role': 'user'}], summary="Based on the retrieved abstracts, here is a markdown table categorizing the papers by domain, along with their titles, authors, summaries, and links:\n\n| Domain | Title | Authors | Summary | Link |\n|--------|-------|---------|---------|------|\n| Security | PRSA: Prompt Reverse Stealing Attacks against Large Language Models | Yong Yang, Xuhong Zhang, Yi Jiang, Xi Chen, Haoyu Wang, Shouling Ji, Zonghui Wang | The paper explores the security risks associated with exposing input-output pairs of prompts used in LLMs and proposes a novel attack framework, PRSA, to reverse-steal prompts, posing a threat to intellectual property rights. | [Link](http://arxiv.org/abs/2402.19200v1) |\n| Ethics & Evaluation | Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models | Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schütze, Dirk Hovy | This work challenges the constrained evaluation paradigm for values and opinions in LLMs and explores more realistic unconstrained evaluations, focusing on the Political Compass Test (PCT). | [Link](http://arxiv.org/abs/2402.16786v1) |\n| Urban Mobility | Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation | Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Chuan Xiao | Introduces an LLM agent framework for personal mobility generation, aligning LLMs with real-world urban mobility data, and offering a tool for urban mobility analysis. | [Link](http://arxiv.org/abs/2402.14744v1) |\n| Bioinformatics | An Evaluation of Large Language Models in Bioinformatics Research | Hengchuang Yin, Zhonghui Gu, Fanhao Wang, Yiparemu Abuduhaibaier, Yanqiao Zhu, Xinming Tu, Xian-Sheng Hua, Xiao Luo, Yizhou Sun | Evaluates the performance of LLMs on bioinformatics tasks, highlighting their potential and limitations, and motivating future research in LLM applications in bioinformatics. | [Link](http://arxiv.org/abs/2402.13714v1) |\n| Privacy | Privacy-Preserving Instructions for Aligning Large Language Models | Da Yu, Peter Kairouz, Sewoong Oh, Zheng Xu | Proposes using synthetic instructions generated by privately fine-tuned generators to replace real instructions in data annotation and model fine-tuning, ensuring privacy while maintaining utility. | [Link](http://arxiv.org/abs/2402.13659v1) |\n| Social Robotics | Ain't Misbehavin' -- Using LLMs to Generate Expressive Robot Behavior in Conversations with the Tabletop Robot Haru | Zining Wang, Paul Reisert, Eric Nichols, Randy Gomez | Integrates LLMs into social robots to generate dynamic and expressive conversations, using a text-to-speech engine and a library of physical actions for the robot. | [Link](http://arxiv.org/abs/2402.11571v1) |\n| Ophthalmology | Fine-tuning Large Language Model (LLM) Artificial Intelligence Chatbots in Ophthalmology and LLM-based evaluation using GPT-4 | Ting Fang Tan, Kabilan Elangovan, Liyuan Jin, Yao Jie, Li Yong, Joshua Lim, Stanley Poh, Wei Yan Ng, Daniel Lim, Yuhe Ke, Nan Liu, Daniel Shu Wei Ting | Assesses the alignment of GPT-4-based evaluation to human clinician experts for evaluating responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. | [Link](http://arxiv.org/abs/2402.10083v1) |\n| Privacy & Data Security | Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination | Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić | Introduces a novel approach for LLM unlearning by guiding LLMs to imagine alternative scenarios, effectively unlearning targeted text while preserving generation and NLU capabilities. | [Link](http://arxiv.org/abs/2402.10052v1) |\n| Computational Efficiency | Anchor-based Large Language Models | Jianhui Pang, Fanghua Ye, Derek F. Wong, Longyue Wang | Proposes Anchor-based LLMs (AnLLMs) with an innovative anchor-based self-attention network (AnSAN) to reduce memory demand and enhance inference efficiency. | [Link](http://arxiv.org/abs/2402.07616v2) |\n| Enterprise Applications | T-RAG: Lessons from the LLM Trenches | Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla | Shares experiences building and deploying an LLM application for question answering over private organizational documents, combining RAG with a finetuned LLM and a tree structure for entity hierarchies. | [Link](http://arxiv.org/abs/2402.07483v1) |\n\nThese papers cover a range of domains including security, ethics, urban mobility, bioinformatics, privacy, social robotics, ophthalmology, data security, computational efficiency, and enterprise applications, showcasing the diverse applications of large language models.", cost=({'total_cost': 0}, {'total_cost': 0}), human_input=[])
标题1
这是一段普通的文本。
标题2
这是另一段普通的文本。
标题3
这是一张图片:

这是一个链接:链接描述
这是一个无序列表:
- 项目1
- 项目2
- 项目3
这是一个有序列表:
- 项目1
- 项目2
- 项目3
这是一段引用:
引用内容
这是一段代码:
print("Hello, World!")
这是一段公式:
$$ E = mc^2 $$
这是一段表格:
| 列1 | 列2 |
|---|---|
| 项1 | 项2 |
| 项3 | 项4 |
这是一段脚注[^1]。
这是一段注释[^2]。
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本��。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚��注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是一段下划线的文本。
这是一段高亮的文本。
这是一段行内代码。
这是一段超链接:链接描述
这是一段图片链接:
这是一段引用链接:[链接描述][1]
这是一段脚注链接:[^1]
这是一段加粗的文本。
这是一段斜体的文本。
这是一段删除线的文本。
这是