LM引导的思维链
李等人 (2024) 的一篇新论文提出使用小语言模型改进LLM中的推理能力。
首先,它通过知识蒸馏将大语言模型生成的原因应用于小语言模型,希望缩小推理能力差距。
基本上,原因是由轻量级语言模型生成的,然后答案预测留给冻结的大语言模型。这种资源高效的方法避免了对大模型进行微调的需要,而是将原因生成外包给了小语言模型。
经过知识蒸馏的LM进一步通过使用几个面向原因和面向任务的奖励信号进行强化学习进行优化。
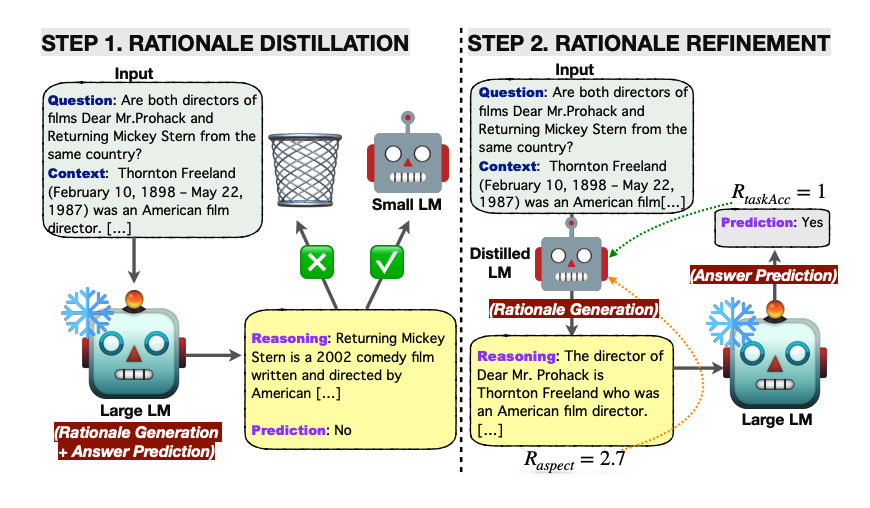 来源: https://arxiv.org/pdf/2404.03414.pdf
来源: https://arxiv.org/pdf/2404.03414.pdf
该框架在多跳抽取式问答上进行了测试,在答案预测准确性方面优于所有基线。强化学习有助于提高生成原因的质量,进而提高问答性能。
本文提出的LM引导的CoT提示方法在性能上优于标准提示和CoT提示。自一致性解码也提高了性能。
这种方法展示了对小语言模型进行原因生成的巧妙运用。考虑到更喜欢较大语言模型而不是较小语言模型具备这种能力,结果令人瞩目。开发人员应深入思考如何分解任务。并非所有任务都需要由大模型完成。在微调时,思考要优化的确切方面,并测试看看小语言模型是否能胜任。