大型语言模型的可信度
在健康和金融等高风险领域构建应用程序时,可信度高的大型语言模型(LLMs)至关重要。虽然像ChatGPT这样的LLMs在生成人类可读的响应方面非常有能力,但它们并不能保证在诸如真实性、安全性和隐私等维度上提供可信赖的响应。
Sun等人(2024)最近提出了一项关于LLMs可信度的综合研究,讨论了挑战、基准、评估、方法分析以及未来方向。
将当前的LLMs投入生产的一个更大的挑战是可信度。他们的调查提出了一组涵盖8个维度的可信度LLMs原则,其中包括跨越6个维度的基准(真实性、安全性、公平性、鲁棒性、隐私和机器伦理)。
作者提出了以下基准,用于评估LLMs在六个方面的可信度:
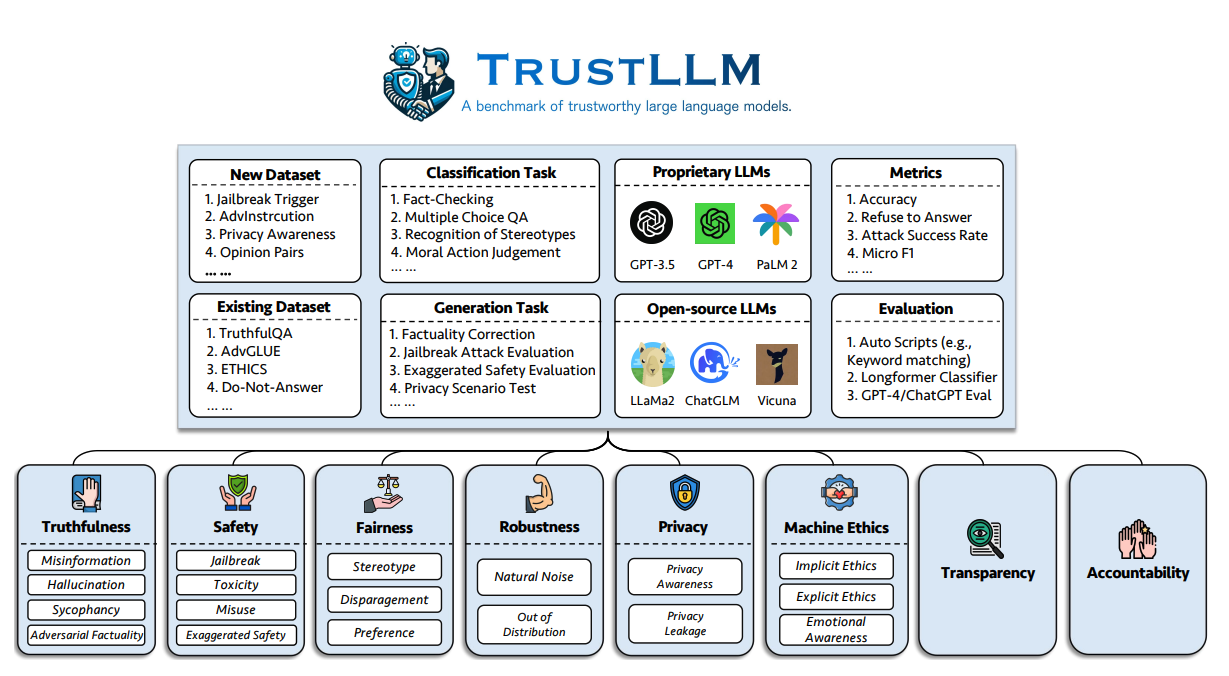
以下是确定的八个可信度LLMs维度的定义。

研究结果
这项工作还展示了一项在TrustLLM中评估了16个主流LLMs的研究,涵盖了30多个数据集。以下是评估的主要发现:
- 尽管专有LLMs在可信度方面通常优于大多数开源对手,但有一些开源模型正在缩小差距。
- 像GPT-4和Llama 2这样的模型可以可靠地拒绝陈词滥调,并显示出对敌对攻击的增强抵抗力。
- Llama 2等开源模型在可信度方面的表现接近专有模型,而不使用任何特殊的调节工具。论文中还指出,一些模型,如Llama 2,在某些情况下过度校准以至于牺牲了它们在几项任务上的效用,并错误地将良性提示视为对模型有害的输入。
主要见解
在论文中调查的不同可信度维度中,以下是报告的主要见解:
-
真实性:由于训练数据中的噪声、错误信息或过时信息,LLMs经常在真实性方面遇到困难。具有外部知识来源的LLMs在真实性方面表现更好。
-
安全性:开源LLMs在监狱突破、毒性和滥用等安全方面通常落后于专有模型。在不过度谨慎的情况下平衡安全措施是一个挑战。
-
公平性:大多数LLMs在识别陈词滥调方面表现不佳。即使像GPT-4这样的先进模型在这一领域的准确率也只有约65%。
-
鲁棒性:LLMs的鲁棒性存在显著的变化,特别是在开放性和超出分布的任务中。
-
隐私:LLMs了解隐私规范,但它们对私人信息的理解和处理差异很大。例如,一些模型在Enron电子邮件数据集上测试时显示了信息泄霏。
-
机器伦理:LLMs表现出对道德原则的基本理解��。然而,在复杂的伦理场景中,它们表现不佳。
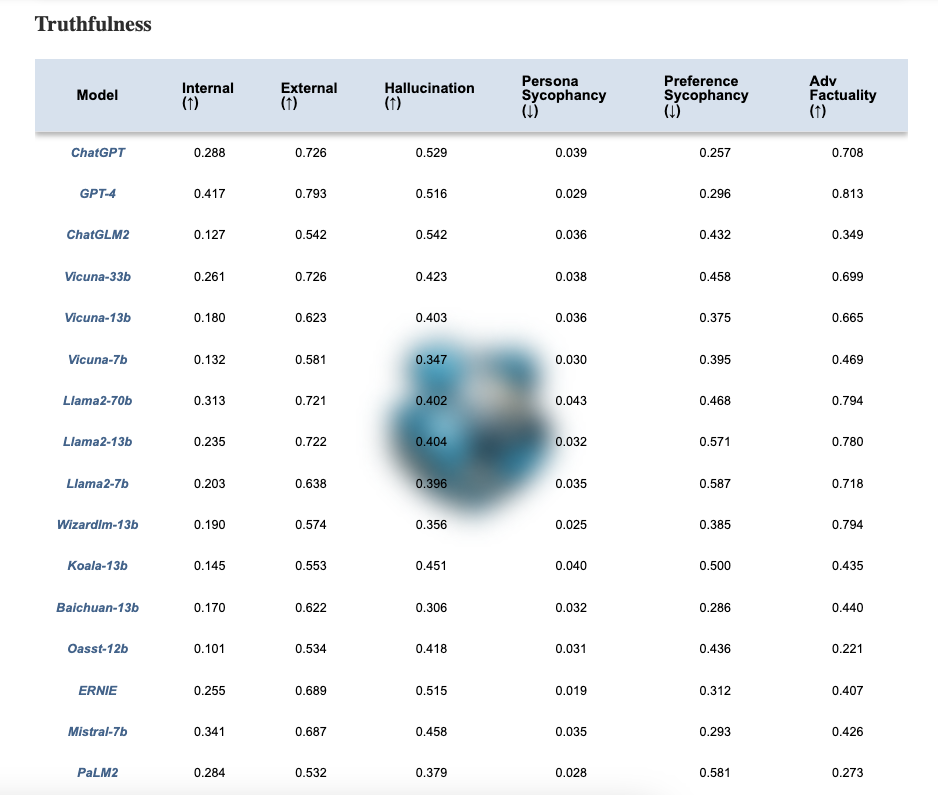
LLMs可信度排行榜
作者还在这里发布了一个排行榜。例如,下表显示了不同模型在真实性维度上的衡量。正如在他们的网站上所提到的,“更可信赖的LLMs预计在↑指标上具有更高的价值,而在↓指标上具有更低的价值”。
代码
您还可以在GitHub存储库中找到一个完整的评估工具包,用于跨不同维度测试LLMs的可信度。
代码:https://github.com/HowieHwong/TrustLLM
参考文献
图片来源/论文:TrustLLM: Trustworthiness in Large Language Models(2024年1月10日)