
排除内存溢出循环故障
内存不足(OOM)循环发生在正在运行的进程消耗越来越多的内存,直到操作系统被迫终止并重启该进程。当进程被终止时,分配给该进程的内存被释放,但在重启后,它继续消耗越来越多的RAM,直到循环重新开始。
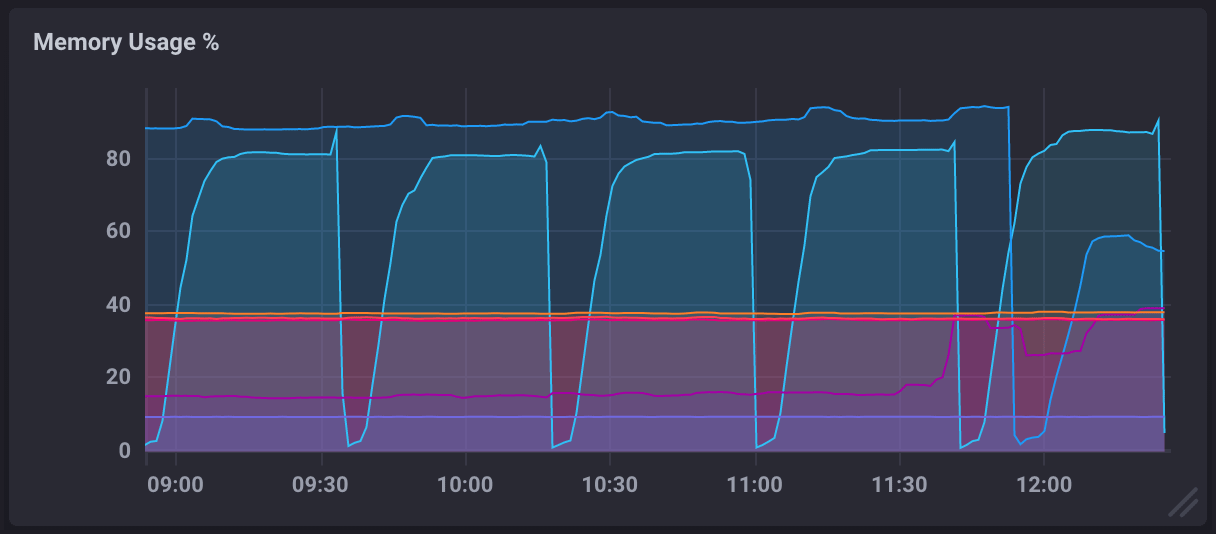
在监控仪表盘中,OOM循环将出现在内存使用%指标中,类似于以下内容:
潜在原因
OOM 循环的原因可能千差万别,具体取决于您对 TICK 堆栈的特定使用案例,但以下是最常见的:
未优化的查询
查询的内容和查询的方式可以极大地影响InfluxDB的内存使用和性能。由于重复发出消耗内存的查询,将会发生OOM循环。例如,一个设置为每30秒刷新一次的仪表板单元。
选择一个不指定时间范围的测量
在未指定时间范围的情况下从测量中选择时,InfluxDB 尝试从 UNIX 纪元时间的开始(1970 年 1 月 1 日 00:00:00 UTC)提取数据点,将返回的数据存储在内存中,直到准备好输出。由于内存使用过高,操作系统最终会结束该过程。
没有时间范围的测量选择示例
SELECT * FROM "telegraf"."autogen"."cpu"
解决方案
识别和更新未优化的查询
在InfluxDB中,OOM循环最常见的原因是未优化的查询,但识别出哪些查询可以更好地优化可能很具挑战性。InfluxQL包含工具,帮助识别查询的“成本”,并洞察哪些查询有优化的空间。
查看您的InfluxDB日志
如果一个查询被终止,它会被InfluxDB记录。 查看您的 InfluxDB logs 以获取有关哪些查询被终止的提示。
估算查询成本
InfluxQL的 EXPLAIN 语句 解析并计划一个查询,然后输出估计成本的摘要。这允许您在实际运行查询之前估计查询可能的资源消耗。
示例 EXPLAIN 语句
> EXPLAIN SELECT * FROM "telegraf"."autogen"."cpu"
QUERY PLAN
----------
EXPRESSION: <nil>
AUXILIARY FIELDS: cpu::tag, host::tag, usage_guest::float, usage_guest_nice::float, usage_idle::float, usage_iowait::float, usage_irq::float, usage_nice::float, usage_softirq::float, usage_steal::float, usage_system::float, usage_user::float
NUMBER OF SHARDS: 12
NUMBER OF SERIES: 108
CACHED VALUES: 38250
NUMBER OF FILES: 1080
NUMBER OF BLOCKS: 10440
SIZE OF BLOCKS: 23252999
EXPLAIN只会输出查询引擎创建的迭代器。它不会捕获查询引擎中的任何其他信息,例如将实际处理多少个点。
分析实际查询成本
InfluxQL的 EXPLAIN ANALYZE 语句 实际上执行一个查询并计算运行时的成本。
示例 EXPLAIN ANALYZE 语句
> EXPLAIN ANALYZE SELECT * FROM "telegraf"."autogen"."cpu" WHERE time > now() - 1d
EXPLAIN ANALYZE
---------------
.
└── select
├── execution_time: 104.608549ms
├── planning_time: 5.08487ms
├── total_time: 109.693419ms
└── build_cursor
├── labels
│ └── statement: SELECT cpu::tag, host::tag, usage_guest::float, usage_guest_nice::float, usage_idle::float, usage_iowait::float, usage_irq::float, usage_nice::float, usage_softirq::float, usage_steal::float, usage_system::float, usage_user::float FROM telegraf.autogen.cpu
└── iterator_scanner
├── labels
│ └── auxiliary_fields: cpu::tag, host::tag, usage_guest::float, usage_guest_nice::float, usage_idle::float, usage_iowait::float, usage_irq::float, usage_nice::float, usage_softirq::float, usage_steal::float, usage_system::float, usage_user::float
└── create_iterator
├── labels
│ ├── measurement: cpu
│ └── shard_id: 317
├── cursors_ref: 0
├── cursors_aux: 90
├── cursors_cond: 0
├── float_blocks_decoded: 450
├── float_blocks_size_bytes: 960943
├── integer_blocks_decoded: 0
├── integer_blocks_size_bytes: 0
├── unsigned_blocks_decoded: 0
├── unsigned_blocks_size_bytes: 0
├── string_blocks_decoded: 0
├── string_blocks_size_bytes: 0
├── boolean_blocks_decoded: 0
├── boolean_blocks_size_bytes: 0
└── planning_time: 4.523978ms
扩展可用内存
如果可能,增加可用与InfluxDB的内存。 在虚拟化或云环境中运行时,这更容易,因为资源可以灵活扩展。 在资源固定的环境中,这可能是一个非常困难的挑战。