![]()
本笔记本概述#
为什么选择变压器?
sktime中的变压器transformers = 模块化数据处理步骤
简单的管道示例 & 转换器解释
transformer 功能概览
变压器类型 - 输入类型,输出类型
广播/向量化到面板、分层、多变量
使用
all_estimators搜索转换器
[1]:
import warnings
warnings.filterwarnings("ignore")
目录#
3. sktime 中的 Transformers
3.1 为何选择变压器?
3.2 变压器 - 接口和特性
3.2.1 什么是变压器?
3.2.2 不同类型的变压器
3.2.3 广播,即变压器的矢量化
3.2.4 作为流水线组件的变压器
3.3 结合变换器、特征工程
3.4 技术细节 - 变压器类型和签名
3.5 扩展指南
3.6 总结
3. sktime 中的转换器#
3.1 为何选择变压器?#
或者:为什么 sktime 转换器会改善你的生活!
(免责声明:与深度学习变压器不是同一产品)
假设我们想要预测这个著名的数据集(在固定范围内按年份划分的航空公司乘客)
[2]:
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
y = load_airline()
plot_series(y)
[2]:
(<Figure size 1600x400 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
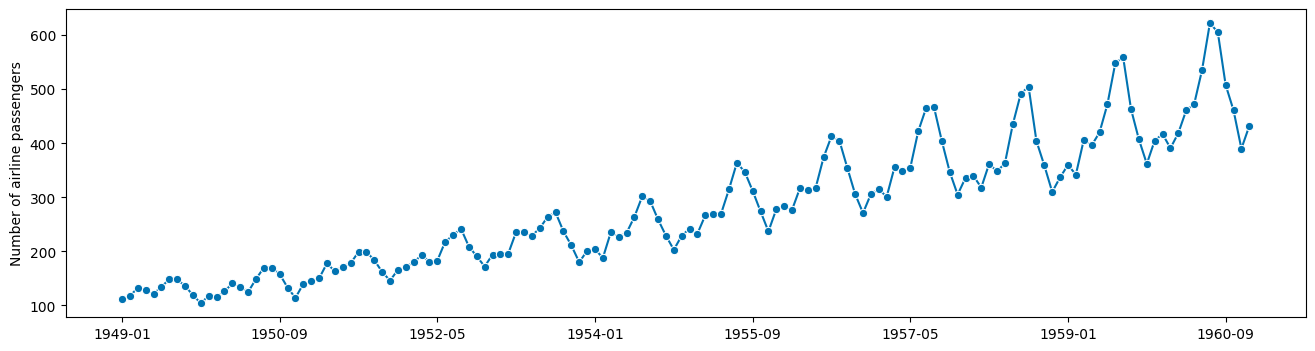
观察结果:
存在季节性周期,12个月周期
季节性周期看起来是乘法性质的(不是加法性质的),与趋势相关。
想法:预测可能会更容易
去除季节性
在对数数值尺度上(乘法变为加法)
天真的方法 - 不要在家里尝试!#
也许一步一步手动做这个是个好主意?
[3]:
import numpy as np
# compute the logarithm
logy = np.log(y)
plot_series(logy)
[3]:
(<Figure size 1600x400 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
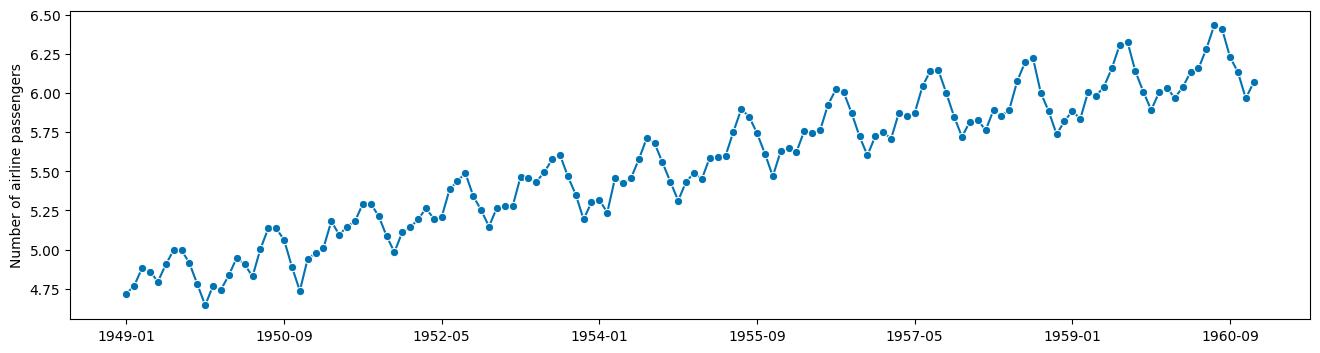
这看起来现在是附加的!
好的,接下来 - 去季节性
[4]:
from statsmodels.tsa.seasonal import seasonal_decompose
# apply this to y
# wait no, to logy
seasonal_result = seasonal_decompose(logy, period=12)
trend = seasonal_result.trend
resid = seasonal_result.resid
seasonal = seasonal_result.seasonal
[5]:
plot_series(trend)
[5]:
(<Figure size 1600x400 with 1 Axes>, <AxesSubplot: ylabel='trend'>)
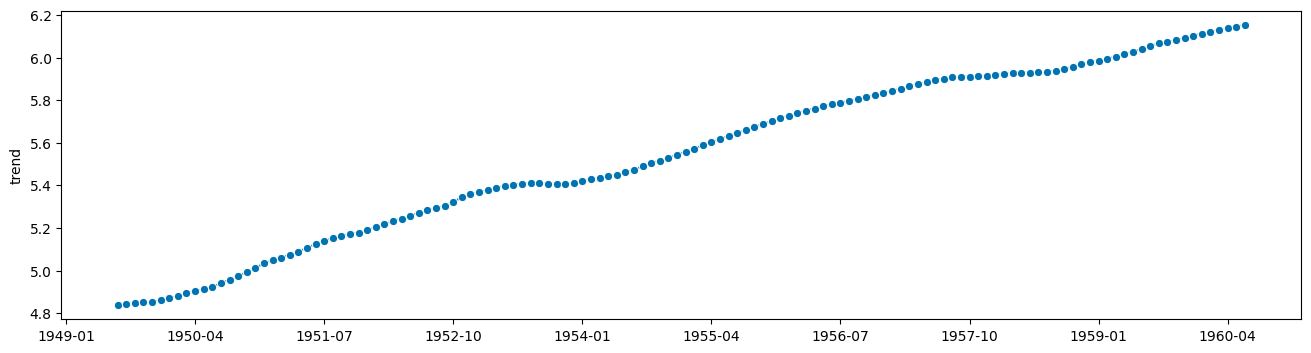
[6]:
plot_series(seasonal, resid, labels=["seasonal component", "residual component"])
[6]:
(<Figure size 1600x400 with 1 Axes>, <AxesSubplot: ylabel='seasonal'>)
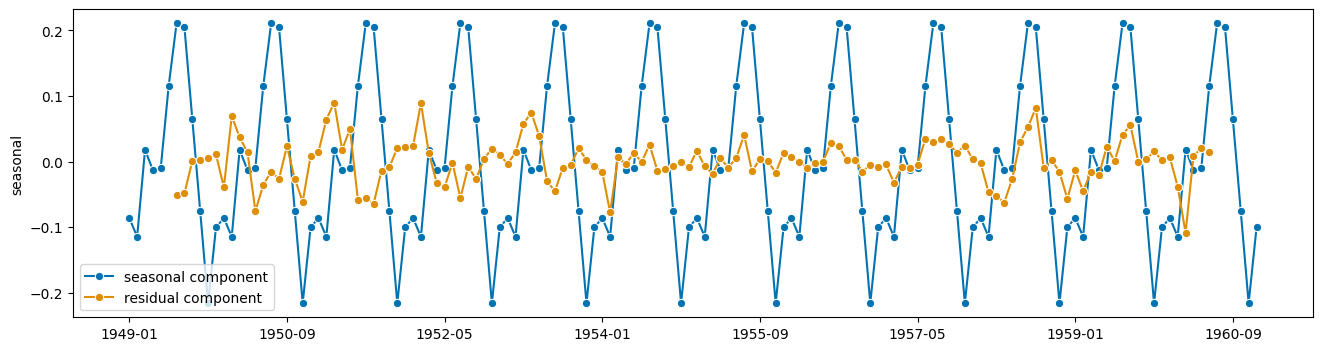
好的,现在来预测一下!
… 什么的?
啊,是的,残差加趋势,因为季节性只是重复自身。
[7]:
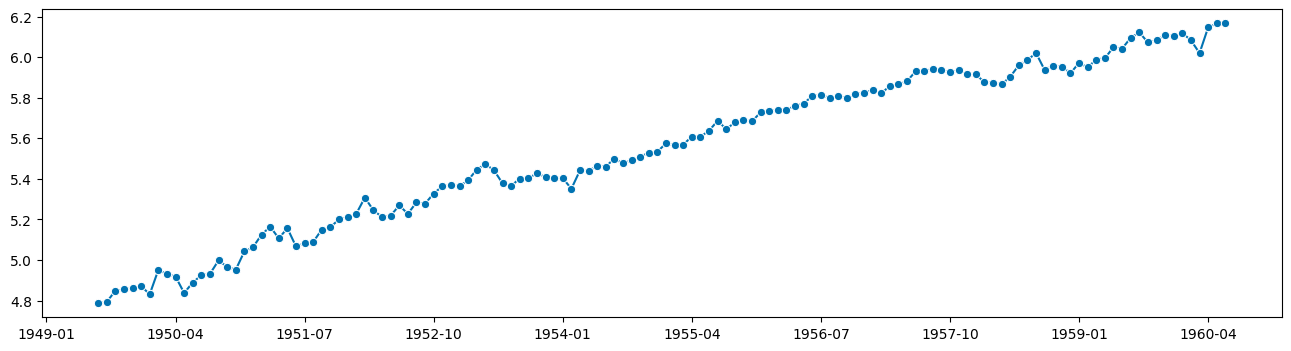
# forecast this:
plot_series(trend + resid)
[7]:
(<Figure size 1600x400 with 1 Axes>, <AxesSubplot: >)
[8]:
# this has nans??
trend
[8]:
1949-01 NaN
1949-02 NaN
1949-03 NaN
1949-04 NaN
1949-05 NaN
..
1960-08 NaN
1960-09 NaN
1960-10 NaN
1960-11 NaN
1960-12 NaN
Freq: M, Name: trend, Length: 144, dtype: float64
[9]:
# ok, forecast this instead then:
y_to_forecast = logy - seasonal
# phew, no nans!
y_to_forecast
[9]:
1949-01 4.804314
1949-02 4.885097
1949-03 4.864689
1949-04 4.872858
1949-05 4.804757
...
1960-08 6.202368
1960-09 6.165645
1960-10 6.208669
1960-11 6.181992
1960-12 6.168741
Freq: M, Length: 144, dtype: float64
[10]:
from sktime.forecasting.trend import PolynomialTrendForecaster
f = PolynomialTrendForecaster(degree=2)
f.fit(y_to_forecast, fh=list(range(1, 13)))
y_fcst = f.predict()
plot_series(y_to_forecast, y_fcst)
[10]:
(<Figure size 1600x400 with 1 Axes>, <AxesSubplot: >)
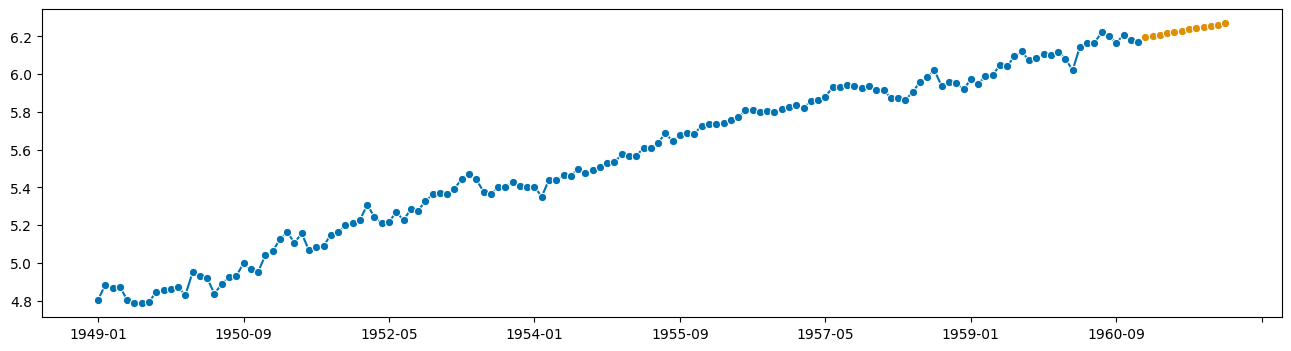
看起来很合理!
现在将其转化为原始 y 的预测…
添加季节性
反转对数
[11]:
y_fcst
[11]:
1961-01 6.195931
1961-02 6.202857
1961-03 6.209740
1961-04 6.216580
1961-05 6.223378
1961-06 6.230132
1961-07 6.236843
1961-08 6.243512
1961-09 6.250137
1961-10 6.256719
1961-11 6.263259
1961-12 6.269755
Freq: M, dtype: float64
[12]:
y_fcst_orig = y_fcst + seasonal[0:12]
y_fcst_orig_orig = np.exp(y_fcst_orig)
y_fcst_orig_orig
[12]:
1949-01 NaN
1949-02 NaN
1949-03 NaN
1949-04 NaN
1949-05 NaN
1949-06 NaN
1949-07 NaN
1949-08 NaN
1949-09 NaN
1949-10 NaN
1949-11 NaN
1949-12 NaN
1961-01 NaN
1961-02 NaN
1961-03 NaN
1961-04 NaN
1961-05 NaN
1961-06 NaN
1961-07 NaN
1961-08 NaN
1961-09 NaN
1961-10 NaN
1961-11 NaN
1961-12 NaN
Freq: M, dtype: float64
好吧,那没有起作用。某些东西与 pandas 索引有关??
[13]:
y_fcst_orig = y_fcst + seasonal[0:12].values
y_fcst_orig_orig = np.exp(y_fcst_orig)
plot_series(y, y_fcst_orig_orig)
[13]:
(<Figure size 1600x400 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
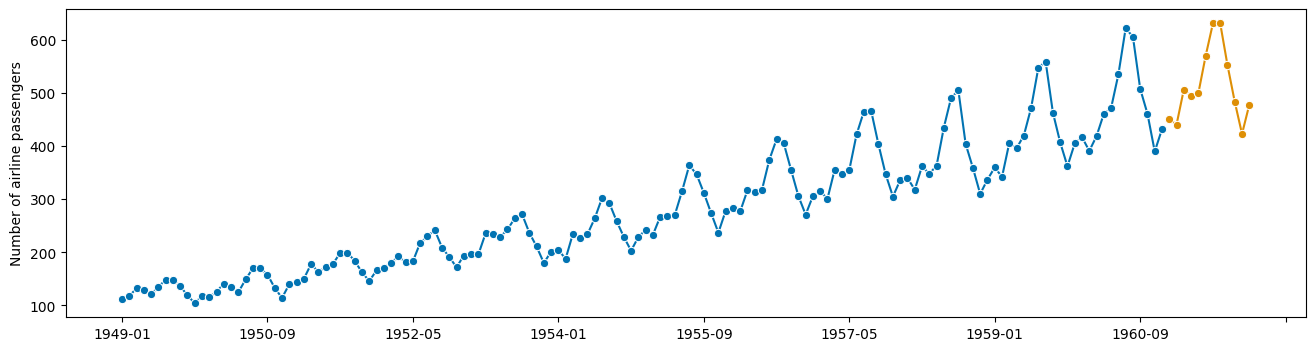
好了,完成了!而且只花了我们10年时间。
也许有更好的方法?
稍微不那么天真的方法 - 使用 sktime 转换器(糟糕地)#
好的,肯定有一种方法可以让我不必在每一步都摆弄那些变化无常的接口。
解决方案:使用 transformers!
每一步都使用相同的界面!
[14]:
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.boxcox import LogTransformer
from sktime.transformations.series.detrend import Deseasonalizer
y = load_airline()
t_log = LogTransformer()
ylog = t_log.fit_transform(y)
t_deseason = Deseasonalizer(sp=12)
y_deseason = t_deseason.fit_transform(ylog)
f = PolynomialTrendForecaster(degree=2)
f.fit(y_deseason, fh=list(range(1, 13)))
y_fcst = f.predict()
嗯,但现在我们需要反转这些变换…
幸运的是,转换器有一个逆变换的标准接口点。
[15]:
y_fcst_orig = t_deseason.inverse_transform(y_fcst)
# the deseasonalizer remembered the seasonality component! nice!
y_fcst_orig_orig = t_log.inverse_transform(y_fcst_orig)
plot_series(y, y_fcst_orig_orig)
[15]:
(<Figure size 1600x400 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
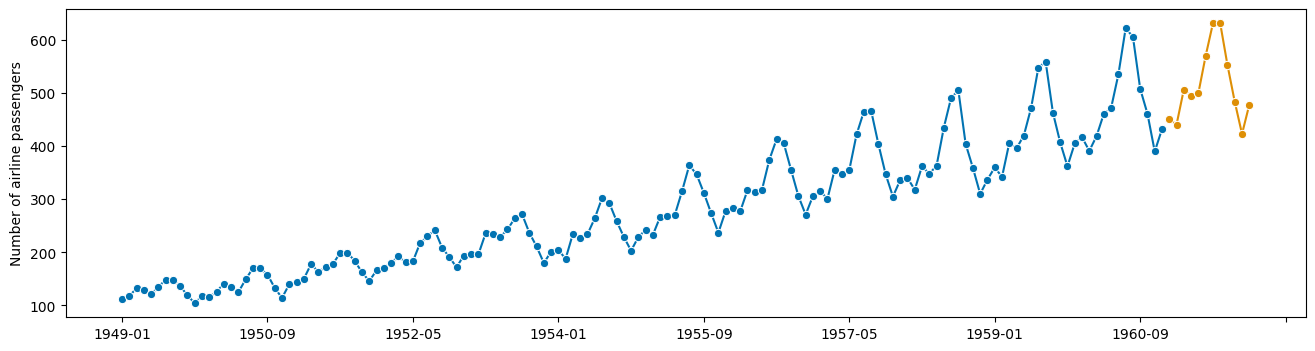
专家方法 - 使用 sktime 转换器与管道!#
包含炫耀的权利。
[16]:
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.boxcox import LogTransformer
from sktime.transformations.series.detrend import Deseasonalizer
y = load_airline()
f = LogTransformer() * Deseasonalizer(sp=12) * PolynomialTrendForecaster(degree=2)
f.fit(y, fh=list(range(1, 13)))
y_fcst = f.predict()
plot_series(y, y_fcst)
[16]:
(<Figure size 1600x400 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
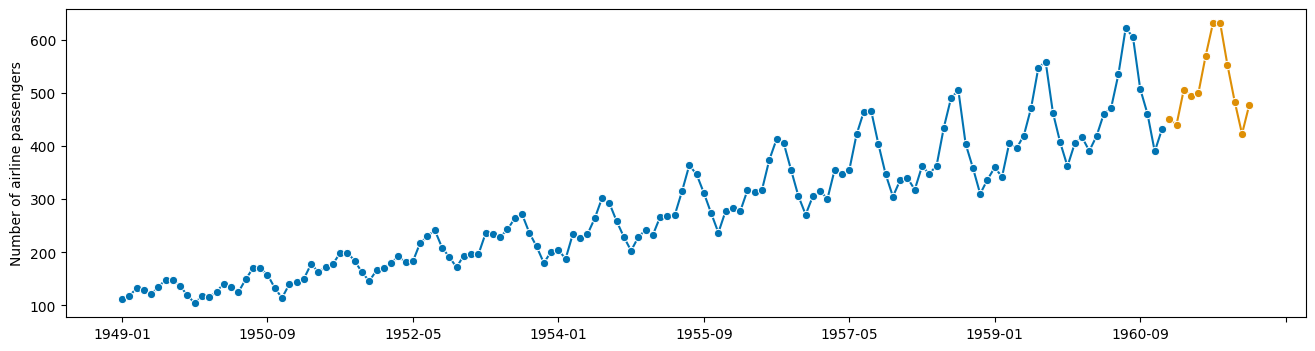
这里发生了什么?
“链”操作符 * 创建一个“预测管道”
具有与其他所有预测器相同的接口!无需额外数据处理!
Transformers 作为标准化组件“插入”。
[17]:
f
[17]:
TransformedTargetForecaster(steps=[LogTransformer(), Deseasonalizer(sp=12),
PolynomialTrendForecaster(degree=2)])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TransformedTargetForecaster(steps=[LogTransformer(), Deseasonalizer(sp=12),
PolynomialTrendForecaster(degree=2)])让我们更详细地看一下:
sktime转换器接口sktime管道构建
3.2 变压器 - 接口和功能#
transformer 接口
变压器类型
按类型搜索转换器
广播/向量化到面板和分层数据
转换器和管道
3.2.1 什么是变压器?#
Transformer = 模块化数据处理步骤,常用于机器学习
(“transformer” 在 scikit-learn 的意义上使用)
Transformer 是一些估计器,它们:
通过
fit(data)对一批数据进行拟合,从而改变其状态通过
transform(X)应用于另一批数据,生成转换后的数据可能有一个
inverse_transform(X)
在 sktime 中,输入 X 到 fit 和 transform 通常是一个时间序列或一个面板(时间序列的集合)。
sktime 时间序列转换器的基本用法如下:
[18]:
# 1. prepare the data
from sktime.utils._testing.series import _make_series
X = _make_series()
X_train = X[:7]
X_test = X[7:12]
# X_train and X_test are both pandas.Series
X_train, X_test
[18]:
(2000-01-01 4.708975
2000-01-02 1.803052
2000-01-03 2.403074
2000-01-04 3.076577
2000-01-05 2.902616
2000-01-06 3.831219
2000-01-07 2.121627
Freq: D, dtype: float64,
2000-01-08 4.858755
2000-01-09 3.460329
2000-01-10 2.280978
2000-01-11 1.930733
2000-01-12 4.604839
Freq: D, dtype: float64)
[19]:
# 2. construct the transformer
from sktime.transformations.series.boxcox import BoxCoxTransformer
# trafo is an sktime estimator inheriting from BaseTransformer
# Box-Cox transform with lambda parameter fitted via mle
trafo = BoxCoxTransformer(method="mle")
[20]:
# 3. fit the transformer to training data
trafo.fit(X_train)
# 4. apply the transformer to transform test data
# Box-Cox transform with lambda fitted on X_train
X_transformed = trafo.transform(X_test)
X_transformed
[20]:
2000-01-08 1.242107
2000-01-09 1.025417
2000-01-10 0.725243
2000-01-11 0.593567
2000-01-12 1.209380
Freq: D, dtype: float64
如果训练集和测试集相同,可以通过使用 fit_transform 更简洁地(有时更高效地)执行步骤 3 和 4:
[21]:
# 3+4. apply the transformer to fit and transform on the same data, X
X_transformed = trafo.fit_transform(X)
3.2.2 不同类型的变压器#
sktime 根据 fit 和 transform 的输入类型,以及 transform 的输出类型,区分不同类型的转换器。
变压器根据以下方面有所不同:
在
fit或transform中使用额外的y参数fit和transform的输入是一个时间序列、一组时间序列,还是标量值(数据框行)transform的输出是单个时间序列、时间序列集合,还是标量值(数据框行)fit和transform的输入是一个对象还是两个对象。两个对象作为输入和一个标量输出意味着该转换器是一个距离或核函数。
关于这点的更多细节在术语表中给出(第2.3节)。
为了说明差异,我们比较了两个输出不同的变压器:
Box-Cox 变换器
BoxCoxTrannsformer,它将一个时间序列转换为另一个时间序列摘要转换器
SummaryTransformer,它将时间序列转换为均值等标量
[22]:
# constructing the transformer
from sktime.transformations.series.boxcox import BoxCoxTransformer
from sktime.transformations.series.summarize import SummaryTransformer
from sktime.utils._testing.series import _make_series
# getting some data
# this is one pandas.Series
X = _make_series(n_timepoints=10)
# constructing the transformers
boxcox_trafo = BoxCoxTransformer(method="mle")
summary_trafo = SummaryTransformer()
[23]:
# this produces a pandas Series
boxcox_trafo.fit_transform(X)
[23]:
2000-01-01 3.217236
2000-01-02 6.125564
2000-01-03 5.264381
2000-01-04 3.811121
2000-01-05 1.966839
2000-01-06 2.621609
2000-01-07 3.851400
2000-01-08 3.199416
2000-01-09 0.000000
2000-01-10 6.629380
Freq: D, dtype: float64
[24]:
# this produces a pandas.DataFrame row
summary_trafo.fit_transform(X)
[24]:
| mean | std | min | max | 0.1 | 0.25 | 0.5 | 0.75 | 0.9 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 3.368131 | 1.128705 | 1.0 | 4.881081 | 2.339681 | 2.963718 | 3.376426 | 4.0816 | 4.67824 |
对于时间序列转换器,元数据标签描述了 transform 的预期输出:
[25]:
boxcox_trafo.get_tag("scitype:transform-output")
[25]:
'Series'
[26]:
summary_trafo.get_tag("scitype:transform-output")
[26]:
'Primitives'
要查找转换器,请使用 all_estimators 并按标签过滤:
"scitype:transform-output"- 输出类型。Series表示时间序列,Primitives表示原始特征(浮点数、类别),Panel表示时间序列集合。"scitype:transform-input"- 输入的科学类型。Series用于时间序列。"scitype:instancewise"- 如果True,则按序列进行矢量化操作。如果False,则使用多个时间序列非平凡地操作。
示例:查找所有输出时间序列的转换器
[27]:
from sktime.registry import all_estimators
# now subset to transformers that extract scalar features
all_estimators(
"transformer",
as_dataframe=True,
filter_tags={"scitype:transform-output": "Series"},
)
Importing plotly failed. Interactive plots will not work.
[27]:
| name | estimator | |
|---|---|---|
| 0 | Aggregator | <class 'sktime.transformations.hierarchical.ag... |
| 1 | AutoCorrelationTransformer | <class 'sktime.transformations.series.acf.Auto... |
| 2 | BoxCoxTransformer | <class 'sktime.transformations.series.boxcox.B... |
| 3 | ClaSPTransformer | <class 'sktime.transformations.series.clasp.Cl... |
| 4 | ClearSky | <class 'sktime.transformations.series.clear_sk... |
| ... | ... | ... |
| 69 | TransformerPipeline | <class 'sktime.transformations.compose.Transfo... |
| 70 | TruncationTransformer | <class 'sktime.transformations.panel.truncatio... |
| 71 | WhiteNoiseAugmenter | <class 'sktime.transformations.series.augmente... |
| 72 | WindowSummarizer | <class 'sktime.transformations.series.summariz... |
| 73 | YtoX | <class 'sktime.transformations.compose.YtoX'> |
74 rows × 2 columns
关于变压器类型和标签的更完整概述,请参见 sktime 变压器教程。
3.2.3 广播,即变压器的向量化#
sktime 转换器可能是原生单变量的,或者仅适用于单个时间序列。
即使在这种情况下,它们也会在变量和时间序列实例之间广播,如果适用的话(在 numpy 术语中也称为矢量化)。
这确保了所有 sktime 转换器都可以应用于多元和多实例(面板、层次结构)时间序列数据。
示例 1: 时间序列到时间序列变换器的广播/矢量化
来自前几节的 BoxCoxTransformer 适用于单个单变量时间序列实例。当看到多个实例或变量时,它会在两者之间广播:
[28]:
from sktime.transformations.series.boxcox import BoxCoxTransformer
from sktime.utils._testing.hierarchical import _make_hierarchical
# hierarchical data with 2 variables and 2 levels
X = _make_hierarchical(n_columns=2)
X
[28]:
| c0 | c1 | |||
|---|---|---|---|---|
| h0 | h1 | time | ||
| h0_0 | h1_0 | 2000-01-01 | 3.068024 | 3.177475 |
| 2000-01-02 | 2.917533 | 3.615065 | ||
| 2000-01-03 | 3.654595 | 3.327944 | ||
| 2000-01-04 | 2.848652 | 4.694433 | ||
| 2000-01-05 | 3.458690 | 3.349914 | ||
| ... | ... | ... | ... | ... |
| h0_1 | h1_3 | 2000-01-08 | 4.056444 | 3.726508 |
| 2000-01-09 | 2.462253 | 3.938115 | ||
| 2000-01-10 | 2.689640 | 1.000000 | ||
| 2000-01-11 | 1.233706 | 3.999155 | ||
| 2000-01-12 | 3.101318 | 3.632666 |
96 rows × 2 columns
[29]:
# constructing the transformers
boxcox_trafo = BoxCoxTransformer(method="mle")
# applying to X results in hierarchical data
boxcox_trafo.fit_transform(X)
[29]:
| c0 | c1 | |||
|---|---|---|---|---|
| h0 | h1 | time | ||
| h0_0 | h1_0 | 2000-01-01 | 0.307301 | 3.456645 |
| 2000-01-02 | 0.305723 | 4.416187 | ||
| 2000-01-03 | 0.311191 | 3.777609 | ||
| 2000-01-04 | 0.304881 | 7.108861 | ||
| 2000-01-05 | 0.310189 | 3.825267 | ||
| ... | ... | ... | ... | ... |
| h0_1 | h1_3 | 2000-01-08 | 1.884165 | 9.828613 |
| 2000-01-09 | 1.087370 | 11.311330 | ||
| 2000-01-10 | 1.216886 | 0.000000 | ||
| 2000-01-11 | 0.219210 | 11.761224 | ||
| 2000-01-12 | 1.435712 | 9.208733 |
96 rows × 2 columns
向量化变换器的拟合模型组件可以在 transformers_ 属性中找到,或者通过通用的 get_fitted_params 接口访问:
[30]:
boxcox_trafo.transformers_
# this is a pandas.DataFrame that contains the fitted transformers
# one per time series instance and variable
[30]:
| c0 | c1 | ||
|---|---|---|---|
| h0 | h1 | ||
| h0_0 | h1_0 | BoxCoxTransformer() | BoxCoxTransformer() |
| h1_1 | BoxCoxTransformer() | BoxCoxTransformer() | |
| h1_2 | BoxCoxTransformer() | BoxCoxTransformer() | |
| h1_3 | BoxCoxTransformer() | BoxCoxTransformer() | |
| h0_1 | h1_0 | BoxCoxTransformer() | BoxCoxTransformer() |
| h1_1 | BoxCoxTransformer() | BoxCoxTransformer() | |
| h1_2 | BoxCoxTransformer() | BoxCoxTransformer() | |
| h1_3 | BoxCoxTransformer() | BoxCoxTransformer() |
[31]:
boxcox_trafo.get_fitted_params()
# this returns a dictionary
# the transformers DataFrame is available at the key "transformers"
# individual transformers are available at dataframe-like keys
# it also contains all fitted lambdas as keyed parameters
[31]:
{'transformers': c0 c1
h0 h1
h0_0 h1_0 BoxCoxTransformer() BoxCoxTransformer()
h1_1 BoxCoxTransformer() BoxCoxTransformer()
h1_2 BoxCoxTransformer() BoxCoxTransformer()
h1_3 BoxCoxTransformer() BoxCoxTransformer()
h0_1 h1_0 BoxCoxTransformer() BoxCoxTransformer()
h1_1 BoxCoxTransformer() BoxCoxTransformer()
h1_2 BoxCoxTransformer() BoxCoxTransformer()
h1_3 BoxCoxTransformer() BoxCoxTransformer(),
"transformers.loc[('h0_0', 'h1_0'),c0]": BoxCoxTransformer(),
"transformers.loc[('h0_0', 'h1_0'),c0]__lambda": -3.1599525634239187,
"transformers.loc[('h0_0', 'h1_1'),c1]": BoxCoxTransformer(),
"transformers.loc[('h0_0', 'h1_1'),c1]__lambda": 0.37511296223989965}
示例 2:将时间序列广播/矢量化为标量特征转换器
SummaryTransformer 的行为类似。多个时间序列实例被转换为结果数据框的不同列。
[32]:
from sktime.transformations.series.summarize import SummaryTransformer
summary_trafo = SummaryTransformer()
# this produces a pandas DataFrame with more rows and columns
# rows correspond to different instances in X
# columns are multiplied and names prefixed by [variablename]__
# there is one column per variable and transformed feature
summary_trafo.fit_transform(X)
[32]:
| c0__mean | c0__std | c0__min | c0__max | c0__0.1 | c0__0.25 | c0__0.5 | c0__0.75 | c0__0.9 | c1__mean | c1__std | c1__min | c1__max | c1__0.1 | c1__0.25 | c1__0.5 | c1__0.75 | c1__0.9 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| h0 | h1 | ||||||||||||||||||
| h0_0 | h1_0 | 3.202174 | 0.732349 | 2.498101 | 5.283440 | 2.709206 | 2.834797 | 2.975883 | 3.348140 | 3.635005 | 3.360042 | 0.744295 | 1.910203 | 4.694433 | 2.278782 | 3.194950 | 3.377147 | 3.722876 | 3.981182 |
| h1_1 | 2.594633 | 0.850142 | 1.000000 | 4.040674 | 1.618444 | 1.988190 | 2.742309 | 3.084133 | 3.349082 | 3.637274 | 1.006419 | 2.376048 | 5.112509 | 2.402845 | 2.703573 | 3.644124 | 4.535796 | 4.873311 | |
| h1_2 | 3.649374 | 1.181054 | 1.422356 | 5.359634 | 2.249409 | 2.881057 | 3.813969 | 4.319322 | 5.021987 | 2.945555 | 1.245355 | 1.684464 | 6.469536 | 1.795508 | 2.324243 | 2.757053 | 3.159779 | 3.547420 | |
| h1_3 | 2.865339 | 0.745604 | 1.654998 | 4.718420 | 2.313490 | 2.477173 | 2.839630 | 3.137472 | 3.372838 | 3.394633 | 0.971250 | 1.866518 | 5.236633 | 2.506371 | 2.653524 | 3.259750 | 4.192159 | 4.419325 | |
| h0_1 | h1_0 | 2.946692 | 1.025167 | 1.085568 | 5.159135 | 1.933525 | 2.375844 | 2.952310 | 3.412478 | 3.687086 | 3.203431 | 0.970914 | 1.554428 | 4.546142 | 1.756260 | 2.405147 | 3.544128 | 3.954901 | 4.046171 |
| h1_1 | 3.274710 | 0.883594 | 1.930773 | 4.771649 | 1.988411 | 2.710401 | 3.434244 | 3.799033 | 4.167242 | 3.116279 | 0.604060 | 2.235531 | 4.167924 | 2.426392 | 2.655720 | 3.079178 | 3.660901 | 3.762036 | |
| h1_2 | 3.397527 | 0.630344 | 2.277090 | 4.571272 | 2.791987 | 2.965040 | 3.457581 | 3.783002 | 4.031893 | 3.297039 | 0.938834 | 1.826276 | 4.919249 | 2.292343 | 2.646870 | 3.139703 | 3.975298 | 4.365553 | |
| h1_3 | 3.356722 | 1.326547 | 1.233706 | 5.505544 | 2.467667 | 2.567089 | 2.884737 | 4.308726 | 5.273261 | 3.232578 | 1.003957 | 1.000000 | 4.234051 | 2.113028 | 2.568151 | 3.659943 | 3.953375 | 4.022143 |
3.2.4 作为流水线组件的转换器#
sktime 转换器可以与任何其他 sktime 估计器类型进行流水线操作,包括预测器、分类器和其他转换器。
管道 = 同一类型的估计器,与专用类具有相同的接口
流水线构建操作:make_pipeline 或通过 * 双下划线
流水线 pipe = trafo * est 生成与 est 相同类型的 pipe。
在 pipe.fit 中,首先执行 trafo.fit_transform,然后对结果执行 est.fit。
在 pipe.predict 中,首先执行 trafo.transform,然后执行 est.predict。
(通过管道的参数因类型而异,可以在管道类的文档字符串中查找,或参考专门的教程)
我们在上面已经看到了这个例子
[33]:
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.boxcox import LogTransformer
from sktime.transformations.series.detrend import Deseasonalizer
y = load_airline()
pipe = LogTransformer() * Deseasonalizer(sp=12) * PolynomialTrendForecaster(degree=2)
pipe
[33]:
TransformedTargetForecaster(steps=[LogTransformer(), Deseasonalizer(sp=12),
PolynomialTrendForecaster(degree=2)])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TransformedTargetForecaster(steps=[LogTransformer(), Deseasonalizer(sp=12),
PolynomialTrendForecaster(degree=2)])[34]:
# this is a forecaster with the same interface as Polynomial Trend Forecaster
pipe.fit(y, fh=[1, 2, 3])
y_pred = pipe.predict()
plot_series(y, y_pred)
[34]:
(<Figure size 1600x400 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
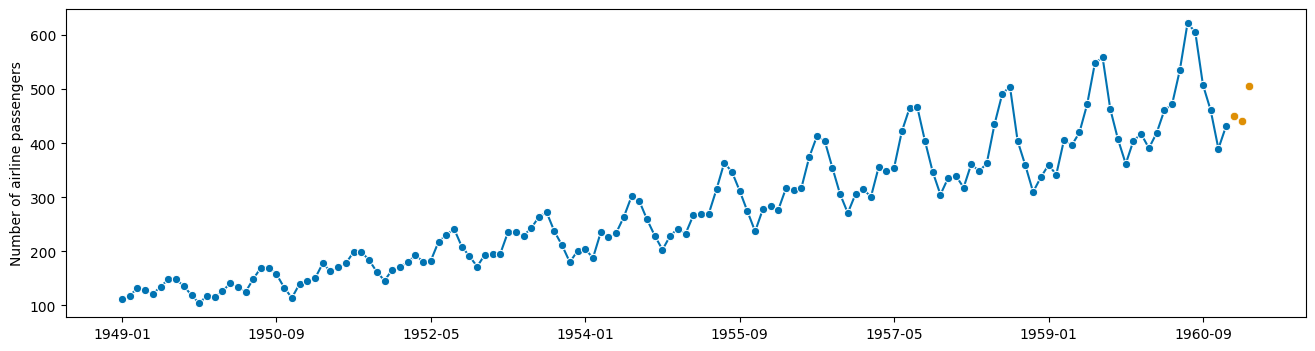
分类器或其他估计器类型的工作方式相同!
[35]:
from sktime.classification.distance_based import KNeighborsTimeSeriesClassifier
from sktime.transformations.series.exponent import ExponentTransformer
pipe = ExponentTransformer() * KNeighborsTimeSeriesClassifier()
# this constructs a ClassifierPipeline, which is also a classifier
pipe
[35]:
ClassifierPipeline(classifier=KNeighborsTimeSeriesClassifier(),
transformers=[ExponentTransformer()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ClassifierPipeline(classifier=KNeighborsTimeSeriesClassifier(),
transformers=[ExponentTransformer()])KNeighborsTimeSeriesClassifier()
KNeighborsTimeSeriesClassifier()
[36]:
from sktime.datasets import load_unit_test
X_train, y_train = load_unit_test(split="TRAIN")
X_test, _ = load_unit_test(split="TEST")
# this is a forecaster with the same interface as knn-classifier
# first applies exponent transform, then knn-classifier
pipe.fit(X_train, y_train)
[36]:
ClassifierPipeline(classifier=KNeighborsTimeSeriesClassifier(),
transformers=[ExponentTransformer()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ClassifierPipeline(classifier=KNeighborsTimeSeriesClassifier(),
transformers=[ExponentTransformer()])KNeighborsTimeSeriesClassifier()
KNeighborsTimeSeriesClassifier()
3.3 结合变换器和特征工程#
转换器是自然管道组件
数据处理步骤
特征工程步骤
后处理步骤
它们可以通过多种其他方式组合:
pipelining = 顺序链接
特征联合 = 并行,特征的增加
特征子集化 = 选择列
inversion = 切换变换和逆变换
多路复用 = 在变压器之间切换
passthrough = 开关 开/关
通过 * 链接转换器#
[37]:
from sktime.transformations.series.difference import Differencer
from sktime.transformations.series.summarize import SummaryTransformer
pipe = Differencer() * SummaryTransformer()
# this constructs a TransformerPipeline, which is also a transformer
pipe
[37]:
TransformerPipeline(steps=[Differencer(), SummaryTransformer()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TransformerPipeline(steps=[Differencer(), SummaryTransformer()])
[38]:
from sktime.utils._testing.hierarchical import _bottom_hier_datagen
X = _bottom_hier_datagen(no_levels=1, no_bottom_nodes=2)
# this is a transformer with the same interface
# first applies differencer, then summary transform
pipe.fit_transform(X)
[38]:
| mean | std | min | max | 0.1 | 0.25 | 0.5 | 0.75 | 0.9 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.222222 | 33.636569 | -101.0 | 87.00 | -37.700 | -16.000 | 3.50 | 22.25 | 43.000 |
| 1 | 48.111111 | 810.876526 | -2680.3 | 2416.86 | -826.462 | -323.145 | 76.33 | 448.86 | 1021.974 |
兼容 sklearn 转换器!
默认情况下,对每个时间序列作为数据框表应用 sklearn 转换器
[39]:
from sklearn.preprocessing import StandardScaler
pipe = Differencer() * StandardScaler()
pipe
[39]:
TransformerPipeline(steps=[Differencer(),
TabularToSeriesAdaptor(transformer=StandardScaler())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TransformerPipeline(steps=[Differencer(),
TabularToSeriesAdaptor(transformer=StandardScaler())])[40]:
pipe.fit_transform(X)
[40]:
| passengers | ||
|---|---|---|
| l1_agg | timepoints | |
| l1_node01 | 1949-01 | -0.066296 |
| 1949-02 | 0.112704 | |
| 1949-03 | 0.351370 | |
| 1949-04 | -0.155796 | |
| 1949-05 | -0.304963 | |
| ... | ... | ... |
| l1_node02 | 1960-08 | -0.623659 |
| 1960-09 | -3.376512 | |
| 1960-10 | -1.565994 | |
| 1960-11 | -2.231567 | |
| 1960-12 | 1.210249 |
288 rows × 1 columns
可以手动构建管道适配器链:
sktime.transformations.compose.TransformerPipelinesktime.transformations.series.adapt.TabularToSeriesAdaptor用于sklearn
复合对象与 get_params / set_params 参数接口兼容:
[41]:
pipe.get_params()
[41]:
{'steps': [Differencer(),
TabularToSeriesAdaptor(transformer=StandardScaler())],
'Differencer': Differencer(),
'TabularToSeriesAdaptor': TabularToSeriesAdaptor(transformer=StandardScaler()),
'Differencer__lags': 1,
'Differencer__memory': 'all',
'Differencer__na_handling': 'fill_zero',
'TabularToSeriesAdaptor__fit_in_transform': False,
'TabularToSeriesAdaptor__transformer__copy': True,
'TabularToSeriesAdaptor__transformer__with_mean': True,
'TabularToSeriesAdaptor__transformer__with_std': True,
'TabularToSeriesAdaptor__transformer': StandardScaler()}
通过 + 进行特征联合#
[42]:
from sktime.transformations.series.difference import Differencer
from sktime.transformations.series.lag import Lag
pipe = Differencer() + Lag()
# this constructs a FeatureUnion, which is also a transformer
pipe
[42]:
FeatureUnion(transformer_list=[Differencer(), Lag()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
FeatureUnion(transformer_list=[Differencer(), Lag()])
[43]:
from sktime.utils._testing.hierarchical import _bottom_hier_datagen
X = _bottom_hier_datagen(no_levels=1, no_bottom_nodes=2)
# applies both Differencer and Lag, returns transformed in different columns
pipe.fit_transform(X)
[43]:
| Differencer__passengers | Lag__lag_0__passengers | ||
|---|---|---|---|
| l1_agg | timepoints | ||
| l1_node01 | 1949-01 | 0.00 | 112.00 |
| 1949-02 | 6.00 | 118.00 | |
| 1949-03 | 14.00 | 132.00 | |
| 1949-04 | -3.00 | 129.00 | |
| 1949-05 | -8.00 | 121.00 | |
| ... | ... | ... | ... |
| l1_node02 | 1960-08 | -1920.80 | 38845.27 |
| 1960-09 | -10759.42 | 28085.85 | |
| 1960-10 | -4546.78 | 23539.07 | |
| 1960-11 | -6114.52 | 17424.55 | |
| 1960-12 | 3507.42 | 20931.97 |
288 rows × 2 columns
要保留原始列,请使用 Id 转换器:
[44]:
from sktime.transformations.compose import Id
from sktime.transformations.series.difference import Differencer
from sktime.transformations.series.lag import Lag
pipe = Id() + Differencer() + Lag([1, 2], index_out="original")
pipe.fit_transform(X)
[44]:
| Id__passengers | Differencer__passengers | Lag__lag_1__passengers | Lag__lag_2__passengers | ||
|---|---|---|---|---|---|
| l1_agg | timepoints | ||||
| l1_node01 | 1949-01 | 112.00 | 0.00 | NaN | NaN |
| 1949-02 | 118.00 | 6.00 | 112.00 | NaN | |
| 1949-03 | 132.00 | 14.00 | 118.00 | 112.00 | |
| 1949-04 | 129.00 | -3.00 | 132.00 | 118.00 | |
| 1949-05 | 121.00 | -8.00 | 129.00 | 132.00 | |
| ... | ... | ... | ... | ... | ... |
| l1_node02 | 1960-08 | 38845.27 | -1920.80 | 40766.07 | 30877.65 |
| 1960-09 | 28085.85 | -10759.42 | 38845.27 | 40766.07 | |
| 1960-10 | 23539.07 | -4546.78 | 28085.85 | 38845.27 | |
| 1960-11 | 17424.55 | -6114.52 | 23539.07 | 28085.85 | |
| 1960-12 | 20931.97 | 3507.42 | 17424.55 | 23539.07 |
288 rows × 4 columns
[45]:
# parameter inspection
pipe.get_params()
[45]:
{'flatten_transform_index': True,
'n_jobs': None,
'transformer_list': [Id(),
Differencer(),
Lag(index_out='original', lags=[1, 2])],
'transformer_weights': None,
'Id': Id(),
'Differencer': Differencer(),
'Lag': Lag(index_out='original', lags=[1, 2]),
'Id___output_convert': 'auto',
'Differencer__lags': 1,
'Differencer__memory': 'all',
'Differencer__na_handling': 'fill_zero',
'Lag__flatten_transform_index': True,
'Lag__freq': None,
'Lag__index_out': 'original',
'Lag__keep_column_names': False,
'Lag__lags': [1, 2]}
通过 [colname] 选择输入列的子集#
假设我们要将 Differencer 应用于第0列,并将 Lag 应用于第1列。
我们也保留原始列以供说明
[46]:
from sktime.utils._testing.hierarchical import _make_hierarchical
X = _make_hierarchical(
hierarchy_levels=(2, 2), n_columns=2, min_timepoints=3, max_timepoints=3
)
X
[46]:
| c0 | c1 | |||
|---|---|---|---|---|
| h0 | h1 | time | ||
| h0_0 | h1_0 | 2000-01-01 | 3.356766 | 2.649204 |
| 2000-01-02 | 2.262487 | 2.204119 | ||
| 2000-01-03 | 2.087692 | 2.186494 | ||
| h1_1 | 2000-01-01 | 4.311237 | 3.129610 | |
| 2000-01-02 | 3.190134 | 1.747807 | ||
| 2000-01-03 | 4.231399 | 2.483151 | ||
| h0_1 | h1_0 | 2000-01-01 | 4.356575 | 3.550554 |
| 2000-01-02 | 2.865619 | 2.783107 | ||
| 2000-01-03 | 3.781770 | 2.619533 | ||
| h1_1 | 2000-01-01 | 3.113704 | 1.000000 | |
| 2000-01-02 | 2.673081 | 2.561047 | ||
| 2000-01-03 | 1.000000 | 2.953516 |
[47]:
from sktime.transformations.compose import Id
from sktime.transformations.series.difference import Differencer
from sktime.transformations.series.lag import Lag
pipe = Id() + Differencer()["c0"] + Lag([1, 2], index_out="original")["c1"]
pipe.fit_transform(X)
[47]:
| Id__c0 | Id__c1 | TransformerPipeline_1__c0 | TransformerPipeline_2__lag_1__c1 | TransformerPipeline_2__lag_2__c1 | |||
|---|---|---|---|---|---|---|---|
| h0 | h1 | time | |||||
| h0_0 | h1_0 | 2000-01-01 | 3.356766 | 2.649204 | 0.000000 | NaN | NaN |
| 2000-01-02 | 2.262487 | 2.204119 | -1.094279 | 2.649204 | NaN | ||
| 2000-01-03 | 2.087692 | 2.186494 | -0.174795 | 2.204119 | 2.649204 | ||
| h1_1 | 2000-01-01 | 4.311237 | 3.129610 | 0.000000 | NaN | NaN | |
| 2000-01-02 | 3.190134 | 1.747807 | -1.121103 | 3.129610 | NaN | ||
| 2000-01-03 | 4.231399 | 2.483151 | 1.041265 | 1.747807 | 3.129610 | ||
| h0_1 | h1_0 | 2000-01-01 | 4.356575 | 3.550554 | 0.000000 | NaN | NaN |
| 2000-01-02 | 2.865619 | 2.783107 | -1.490956 | 3.550554 | NaN | ||
| 2000-01-03 | 3.781770 | 2.619533 | 0.916151 | 2.783107 | 3.550554 | ||
| h1_1 | 2000-01-01 | 3.113704 | 1.000000 | 0.000000 | NaN | NaN | |
| 2000-01-02 | 2.673081 | 2.561047 | -0.440623 | 1.000000 | NaN | ||
| 2000-01-03 | 1.000000 | 2.953516 | -1.673081 | 2.561047 | 1.000000 |
可以通过显式使用 FeatureUnion 来替换自动生成的名称:
[48]:
from sktime.transformations.compose import FeatureUnion
pipe = FeatureUnion(
[
("original", Id()),
("diff", Differencer()["c0"]),
("lag", Lag([1, 2], index_out="original")),
]
)
pipe.fit_transform(X)
[48]:
| original__c0 | original__c1 | diff__c0 | lag__lag_1__c0 | lag__lag_1__c1 | lag__lag_2__c0 | lag__lag_2__c1 | |||
|---|---|---|---|---|---|---|---|---|---|
| h0 | h1 | time | |||||||
| h0_0 | h1_0 | 2000-01-01 | 3.356766 | 2.649204 | 0.000000 | NaN | NaN | NaN | NaN |
| 2000-01-02 | 2.262487 | 2.204119 | -1.094279 | 3.356766 | 2.649204 | NaN | NaN | ||
| 2000-01-03 | 2.087692 | 2.186494 | -0.174795 | 2.262487 | 2.204119 | 3.356766 | 2.649204 | ||
| h1_1 | 2000-01-01 | 4.311237 | 3.129610 | 0.000000 | NaN | NaN | NaN | NaN | |
| 2000-01-02 | 3.190134 | 1.747807 | -1.121103 | 4.311237 | 3.129610 | NaN | NaN | ||
| 2000-01-03 | 4.231399 | 2.483151 | 1.041265 | 3.190134 | 1.747807 | 4.311237 | 3.129610 | ||
| h0_1 | h1_0 | 2000-01-01 | 4.356575 | 3.550554 | 0.000000 | NaN | NaN | NaN | NaN |
| 2000-01-02 | 2.865619 | 2.783107 | -1.490956 | 4.356575 | 3.550554 | NaN | NaN | ||
| 2000-01-03 | 3.781770 | 2.619533 | 0.916151 | 2.865619 | 2.783107 | 4.356575 | 3.550554 | ||
| h1_1 | 2000-01-01 | 3.113704 | 1.000000 | 0.000000 | NaN | NaN | NaN | NaN | |
| 2000-01-02 | 2.673081 | 2.561047 | -0.440623 | 3.113704 | 1.000000 | NaN | NaN | ||
| 2000-01-03 | 1.000000 | 2.953516 | -1.673081 | 2.673081 | 2.561047 | 3.113704 | 1.000000 |
通过反转 ~ 将对数变换转换为指数变换#
[49]:
import numpy as np
from sktime.transformations.series.boxcox import LogTransformer
log = LogTransformer()
exp = ~log
# this behaves like an "e to the power of" transformer now
exp.fit_transform(np.array([1, 2, 3]))
[49]:
array([ 2.71828183, 7.3890561 , 20.08553692])
autoML 结构组合器:多路复用器开关 ¦ 和 开/关开关 -#
将决策作为参数公开
我们想要差分器 还是 滞后?用于后续调优
我们想要 [差异和滞后] 还是 [原始特征和滞后] ? 以便稍后进行调整
[50]:
# differencer or lag
from sktime.transformations.series.difference import Differencer
from sktime.transformations.series.lag import Lag
pipe = Differencer() | Lag()
pipe.get_params()
[50]:
{'selected_transformer': None,
'transformers': [Differencer(), Lag()],
'Differencer': Differencer(),
'Lag': Lag(),
'Differencer__lags': 1,
'Differencer__memory': 'all',
'Differencer__na_handling': 'fill_zero',
'Lag__flatten_transform_index': True,
'Lag__freq': None,
'Lag__index_out': 'extend',
'Lag__keep_column_names': False,
'Lag__lags': 0}
selected_transformer 参数暴露了选择:
这是表现为 Lag 还是 Differencer?
[51]:
# switch = Lag -> this is a Lag transformer now!
pipe.set_params(selected_transformer="Lag")
[51]:
MultiplexTransformer(selected_transformer='Lag',
transformers=[Differencer(), Lag()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MultiplexTransformer(selected_transformer='Lag',
transformers=[Differencer(), Lag()])[52]:
# switch = Lag -> this is a Differencer now!
pipe.set_params(selected_transformer="Differencer")
[52]:
MultiplexTransformer(selected_transformer='Differencer',
transformers=[Differencer(), Lag()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MultiplexTransformer(selected_transformer='Differencer',
transformers=[Differencer(), Lag()])类似地,带有 ~ 的开关用于打开/关闭
作为包装的transformer和``Id``之间的多路复用器
[53]:
optional_differencer = -Differencer()
# this behaves as Differencer now
optional_differencer
[53]:
OptionalPassthrough(transformer=Differencer())In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
OptionalPassthrough(transformer=Differencer())
Differencer()
Differencer()
[54]:
# this is now just the identity transformer
optional_differencer.set_params(passthrough=True)
[54]:
OptionalPassthrough(passthrough=True, transformer=Differencer())In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
OptionalPassthrough(passthrough=True, transformer=Differencer())
Differencer()
Differencer()
3.4 技术细节 - 变压器类型和签名#
本节详细解释了 sktime 中不同类型的变压器。
sktime 中有四种主要的转换类型:
将一系列/序列转换为标量或类别值特征。例如:
tsfresh,或提取整体的``均值``和``方差``。将一个序列转换为另一个序列。例如:去趋势化、平滑化、过滤、滞后。
将一个面板转换为另一个面板。示例:主成分投影;将单个序列到序列的转换应用于面板中的所有序列。
将一对序列转换为标量值。示例:序列/序列之间的动态时间规整距离;序列/序列之间的广义对齐核。
值得注意的是,前三种(序列到原始特征、序列到序列、面板到面板)由相同的基类模板和模块覆盖。我们称这些转换器为“时间序列转换器”,或者简称为“转换器”。时间序列和序列的内核和距离具有相同的数学签名,仅在数学属性(例如,确定性假设)上有所不同——它们由更抽象的科学类型“成对转换器”覆盖。
下面,我们通过子部分进行概述:
3.4.1 数据容器格式#
sktime 转换器应用于单个时间序列和面板。面板是时间序列的集合,我们将面板中的每个时间序列称为面板的“实例”。这被形式化为抽象的“科学类型” Series 和 Panel,具有多种可能的内存中表示,即所谓的“mtypes”。
在本教程中,我们将使用最常见的m类型。有关更多详细信息和正式数据类型规范,请参阅“数据类型和数据集”教程。
Series 通常表示为:
pandas.Series用于单变量时间序列和序列pandas.DataFrame用于单变量或多变量时间序列和序列
Series.index 和 DataFrame.index 用于表示时间序列或序列索引。sktime 支持 pandas 整数、周期和时间戳索引。
Panel 通常表示为:* 一个特定格式的 pandas.DataFrame,由 pd-multiindex mtype 定义。它具有一个2级索引,用于时间点和实例 * 一个 pandas.DataFrame 的 list,其中所有 pandas.DataFrame 都是 Series 格式。不同的 list 元素代表不同的实例
在任何情况下,“时间”索引必须是与 sktime 兼容的时间索引类型,就像 Series 一样。
[55]:
from sktime.datatypes import get_examples
[56]:
# example of a univariate series
get_examples("pd.Series", "Series")[0]
[56]:
0 1.0
1 4.0
2 0.5
3 -3.0
Name: a, dtype: float64
[57]:
# example of a multivariate series
get_examples("pd.DataFrame", "Series")[1]
[57]:
| a | b | |
|---|---|---|
| 0 | 1.0 | 3.000000 |
| 1 | 4.0 | 7.000000 |
| 2 | 0.5 | 2.000000 |
| 3 | -3.0 | -0.428571 |
[58]:
# example of a panel with mtype pd-multiindex
get_examples("pd-multiindex", "Panel")[0]
[58]:
| var_0 | var_1 | ||
|---|---|---|---|
| instances | timepoints | ||
| 0 | 0 | 1 | 4 |
| 1 | 2 | 5 | |
| 2 | 3 | 6 | |
| 1 | 0 | 1 | 4 |
| 1 | 2 | 55 | |
| 2 | 3 | 6 | |
| 2 | 0 | 1 | 42 |
| 1 | 2 | 5 | |
| 2 | 3 | 6 |
[59]:
# example of the same panel with mtype df-list
get_examples("df-list", "Panel")[0]
[59]:
[ var_0 var_1
0 1 4
1 2 5
2 3 6,
var_0 var_1
0 1 4
1 2 55
2 3 6,
var_0 var_1
0 1 42
1 2 5
2 3 6]
sktime 支持更多 mtypes,详情请参阅“数据类型和数据集”教程。
3.4.2 通用变压器签名 - 时间序列变压器#
Series 和 Panel 的转换器具有相同的高级接口。根据它们更常用于哪种数据类型,它们可以在 transformations.series 或 transformations.panel 模块中找到。如前所述,这并不意味着接口是分开的。
transformers 最重要的接口点是:
带有参数的构造,这与任何其他
sktime估计器相同通过
fit拟合变换器通过
transform转换数据逆变换,通过
inverse_transform- 并非所有变换器都有这个接口点,因为并非所有变换都是可逆的通过
update更新转换器 - 并非所有转换器都有这个接口点(update目前正在开发中,截至 v0.8.x,欢迎贡献)
我们通过以下两个示例转换器展示这一点——一个转换器的 transform 输出 Series,另一个转换器的 transform 输出原始特征(数字或类别)。
我们将对以下 Series 和 Panel 数据应用这两种转换:
[60]:
from sktime.datatypes import get_examples
# univariate series used in the examples
X_series = get_examples("pd.Series", "Series")[3]
# panel used in the examples
X_panel = get_examples("pd-multiindex", "Panel")[2]
[61]:
X_series
[61]:
0 1.0
1 4.0
2 0.5
3 3.0
Name: a, dtype: float64
[62]:
X_panel
[62]:
| var_0 | ||
|---|---|---|
| instances | timepoints | |
| 0 | 0 | 4 |
| 1 | 5 | |
| 2 | 6 |
Box-Cox 转换器将 Box-Cox 变换应用于序列或面板中的单个值。开始时,转换器需要使用参数设置进行构造,这与任何 sktime 估计器相同。
[63]:
# constructing the transformer
from sktime.transformations.series.boxcox import BoxCoxTransformer
my_boxcox_trafo = BoxCoxTransformer(method="mle")
现在,我们将构建的转换器 my_trafo 应用于一个(单变量)序列。首先,转换器被拟合:
[64]:
# fitting the transformer
my_boxcox_trafo.fit(X_series)
[64]:
BoxCoxTransformer()Please rerun this cell to show the HTML repr or trust the notebook.
BoxCoxTransformer()
接下来,应用变换器,这将产生一个变换后的序列。
[65]:
# transforming the series
my_boxcox_trafo.transform(X_series)
[65]:
0 0.000000
1 1.636217
2 -0.640098
3 1.251936
Name: a, dtype: float64
通常,传递给 transform 的序列不必与 fit 中的相同,但如果它们相同,则可以使用简写 fit_transform:
[66]:
my_boxcox_trafo.fit_transform(X_series)
[66]:
0 0.000000
1 1.636217
2 -0.640098
3 1.251936
Name: a, dtype: float64
转换器也可以应用于 Panel 数据。
[67]:
my_boxcox_trafo.fit_transform(X_panel)
[67]:
| var_0 | ||
|---|---|---|
| instances | timepoints | |
| 0 | 0 | 2.156835 |
| 1 | 2.702737 | |
| 2 | 3.206011 |
注意:使用的 BoxCoxTransformer 对面板中的每个系列单独应用了 Box-Cox 变换,但这并不一定是所有变换器的通用情况。
摘要转换器可以用来从序列中提取样本统计数据,如均值和方差。首先,我们构建转换器:
[68]:
# constructing the transformer
from sktime.transformations.series.summarize import SummaryTransformer
my_summary_trafo = SummaryTransformer()
和之前一样,我们可以使用 fit、transform 和 fit_transform 进行拟合/应用。
SummaryTransformer 返回原始特征,因此输出将是一个 pandas.DataFrame,每一行对应输入中的一个序列。
如果输入是一个单一序列,transform 和 fit_transform 的输出将是一个一行九列的 DataFrame,对应于该单一序列的九数概括:
[69]:
my_summary_trafo.fit_transform(X_series)
[69]:
| mean | std | min | max | 0.1 | 0.25 | 0.5 | 0.75 | 0.9 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.125 | 1.652019 | 0.5 | 4.0 | 0.65 | 0.875 | 2.0 | 3.25 | 3.7 |
如果输入是一个面板,transform 和 fit_transform 的输出将是一个 DataFrame,其行数与 Panel 中的序列数相同。第 i 行包含面板 X_panel 中第 i 个序列的汇总统计数据:
[70]:
my_summary_trafo.fit_transform(X_panel)
[70]:
| mean | std | min | max | 0.1 | 0.25 | 0.5 | 0.75 | 0.9 | |
|---|---|---|---|---|---|---|---|---|---|
| instances | |||||||||
| 0 | 5.0 | 1.0 | 4.0 | 6.0 | 4.2 | 4.5 | 5.0 | 5.5 | 5.8 |
transform 是否会返回时间序列类对象(如 Series 或 Panel)或基本类型(即 pandas.DataFrame),可以通过使用 "scitype:transform-output" 标签来检查。对于第一个示例(BoxCoxTransformer),其行为对应的标签为 "Series",而对于第二个示例(SummaryTransformer),其行为对应的标签为 "Primitives":
[71]:
my_boxcox_trafo.get_tag("scitype:transform-output")
[71]:
'Series'
[72]:
my_summary_trafo.get_tag("scitype:transform-output")
[72]:
'Primitives'
使用标签来描述和搜索变压器将在第4节中更详细地讨论。
注意:目前并非所有转换器都已重构以接受 Series 到 Panel 的参数,因此上述内容可能无法完全适用于所有转换器。非常感谢对转换器重构的贡献。
3.4.3 通用转换器签名 - 成对系列转换器#
成对系列变换器模型数学对象的签名 (Series, Series) -> float,或者用数学符号表示,
常见的例子包括序列之间的距离,或(正定)序列上的核。
成对变换器有一个参数化的构造函数,就像其他 sktime 对象一样。变换是通过 transform 方法实现的,或者为了简洁起见,通过调用构造的对象来实现。
方法 transform 总是返回一个 2D 的 numpy.ndarray,并且可以通过多种方式调用:
我们在下面展示几个例子。
[73]:
from sktime.datatypes import get_examples
# unviariate series used in the examples
X_series = get_examples("pd.Series", "Series")[0]
X2_series = get_examples("pd.Series", "Series")[1]
# panel used in the examples
X_panel = get_examples("pd-multiindex", "Panel")[0]
首先,我们用参数构建成对变换器。在这种情况下,成对变换器是一个距离(平均欧几里得距离):
[74]:
# constructing the transformer
from sktime.dists_kernels import AggrDist, ScipyDist
# mean of paired Euclidean distances
my_series_dist = AggrDist(ScipyDist(metric="euclidean"))
然后我们可以通过 transform 或直接调用来评估距离:
[75]:
# evaluate the metric on two series, via transform
my_series_dist.transform(X_series, X2_series)
[75]:
array([[2.6875]])
[76]:
# evaluate the metric on two series, by direct call - this is the same
my_series_dist(X_series, X2_series)
[76]:
array([[2.6875]])
[77]:
# evaluate the metric on two identical panels of three series
my_series_dist(X_panel, X_panel)
[77]:
array([[ 1.25707872, 17.6116986 , 13.12667685],
[17.6116986 , 22.85520736, 21.30677498],
[13.12667685, 21.30677498, 16.55183053]])
[78]:
# this is the same as providing only one argument
my_series_dist(X_panel)
[78]:
array([[ 1.25707872, 17.6116986 , 13.12667685],
[17.6116986 , 22.85520736, 21.30677498],
[13.12667685, 21.30677498, 16.55183053]])
[79]:
# one series, one panel
# we subset X_panel to univariate, since the distance in question
# cannot compare series with different number of variables
my_series_dist(X_series, X_panel[["var_1"]])
[79]:
array([[ 4.375 , 21.04166667, 17.04166667]])
成对变换器是可组合的,并且使用熟悉的 get_params 接口,就像任何其他 sktime 对象和 scikit-learn 估计器一样:
[80]:
my_series_dist.get_params()
[80]:
{'aggfunc': None,
'aggfunc_is_symm': False,
'transformer': ScipyDist(),
'transformer__colalign': 'intersect',
'transformer__metric': 'euclidean',
'transformer__metric_kwargs': None,
'transformer__p': 2,
'transformer__var_weights': None}
3.4.4 通用转换器签名 - 成对转换器#
sktime 还提供了对表格数据进行成对变换的功能,即签名 (DataFrame-行, DataFrame-行) -> 浮点数 的数学对象,或者用数学符号表示,
. 常见的例子包括序列之间的距离,或(正定)序列上的核。
行为与系列变压器相同,可以通过 transform(X, X2) 或直接调用来进行评估。
成对(表格)转换器的 transform 输入必须始终为 pandas.DataFrame。输出是一个 m x n 矩阵,即一个二维的 np.ndarray,其中 m = len(X), n=len(X2)。第 (i,j) 个条目对应于 t(Xi, X2j),其中 Xi 是 X 的第 i 行,X2j 是 X2 的第 j 行。如果未传递 X2,则默认为 X。
示例:
[81]:
from sktime.datatypes import get_examples
# we retrieve some DataFrame examples
X_tabular = get_examples("pd.DataFrame", "Series")[1]
X2_tabular = get_examples("pd.DataFrame", "Series")[1][0:3]
[82]:
# constructing the transformer
from sktime.dists_kernels import ScipyDist
# mean of paired Euclidean distances
my_tabular_dist = ScipyDist(metric="euclidean")
[83]:
# obtain matrix of distances between each pair of rows in X_tabular, X2_tabular
my_tabular_dist(X_tabular, X2_tabular)
[83]:
array([[ 0. , 5. , 1.11803399],
[ 5. , 0. , 6.10327781],
[ 1.11803399, 6.10327781, 0. ],
[ 5.26831112, 10.20704039, 4.26004216]])
3.4.5 搜索变压器#
与所有 sktime 对象一样,我们可以使用 registry.all_estimators 工具来显示 sktime 中的所有转换器。
相关的科学类型有:* "transformer" 表示所有转换器(如第2.2节所述)* "transformer-pairwise" 表示所有表格数据上的成对转换器(如第2.4节所述)* "transformer-panel" 表示所有面板数据上的成对转换器(如第2.3节所述)
要进一步按输入和输出来筛选转换器("transformer" 科学类型),请使用标签,最重要的是:
这些以及更多的标签将在第2节中更详细地解释。
[84]:
from sktime.registry import all_estimators
[85]:
# listing all pairwise panel transformers - distances, kernels on time series
all_estimators("transformer", as_dataframe=True)
[85]:
| name | object | |
|---|---|---|
| 0 | ADICVTransformer | <class 'sktime.transformations.series.adi_cv.A... |
| 1 | Aggregator | <class 'sktime.transformations.hierarchical.ag... |
| 2 | AutoCorrelationTransformer | <class 'sktime.transformations.series.acf.Auto... |
| 3 | BKFilter | <class 'sktime.transformations.series.bkfilter... |
| 4 | Bollinger | <class 'sktime.transformations.series.bollinge... |
| ... | ... | ... |
| 123 | TruncationTransformer | <class 'sktime.transformations.panel.truncatio... |
| 124 | VmdTransformer | <class 'sktime.transformations.series.vmd.VmdT... |
| 125 | WhiteNoiseAugmenter | <class 'sktime.transformations.series.augmente... |
| 126 | WindowSummarizer | <class 'sktime.transformations.series.summariz... |
| 127 | YtoX | <class 'sktime.transformations.compose._ytox.Y... |
128 rows × 2 columns
[86]:
# now subset to transformers that extract scalar features
all_estimators(
"transformer",
as_dataframe=True,
filter_tags={"scitype:transform-output": "Primitives"},
)
[86]:
| name | object | |
|---|---|---|
| 0 | ADICVTransformer | <class 'sktime.transformations.series.adi_cv.A... |
| 1 | Catch22 | <class 'sktime.transformations.panel.catch22.C... |
| 2 | Catch22Wrapper | <class 'sktime.transformations.panel.catch22wr... |
| 3 | DistanceFeatures | <class 'sktime.transformations.panel.compose_d... |
| 4 | FittedParamExtractor | <class 'sktime.transformations.panel.summarize... |
| 5 | MatrixProfile | <class 'sktime.transformations.panel.matrix_pr... |
| 6 | MiniRocket | <class 'sktime.transformations.panel.rocket._m... |
| 7 | MiniRocketMultivariate | <class 'sktime.transformations.panel.rocket._m... |
| 8 | MiniRocketMultivariateVariable | <class 'sktime.transformations.panel.rocket._m... |
| 9 | MultiRocket | <class 'sktime.transformations.panel.rocket._m... |
| 10 | MultiRocketMultivariate | <class 'sktime.transformations.panel.rocket._m... |
| 11 | RandomIntervalFeatureExtractor | <class 'sktime.transformations.panel.summarize... |
| 12 | RandomIntervals | <class 'sktime.transformations.panel.random_in... |
| 13 | RandomShapeletTransform | <class 'sktime.transformations.panel.shapelet_... |
| 14 | Rocket | <class 'sktime.transformations.panel.rocket._r... |
| 15 | RocketPyts | <class 'sktime.transformations.panel.rocket._r... |
| 16 | ShapeletTransform | <class 'sktime.transformations.panel.shapelet_... |
| 17 | ShapeletTransformPyts | <class 'sktime.transformations.panel.shapelet_... |
| 18 | SignatureTransformer | <class 'sktime.transformations.panel.signature... |
| 19 | SummaryTransformer | <class 'sktime.transformations.series.summariz... |
| 20 | SupervisedIntervals | <class 'sktime.transformations.panel.supervise... |
| 21 | TSFreshFeatureExtractor | <class 'sktime.transformations.panel.tsfresh.T... |
| 22 | TSFreshRelevantFeatureExtractor | <class 'sktime.transformations.panel.tsfresh.T... |
| 23 | Tabularizer | <class 'sktime.transformations.panel.reduce.Ta... |
| 24 | TimeBinner | <class 'sktime.transformations.panel.reduce.Ti... |
[87]:
# listing all pairwise (tabular) transformers - distances, kernels on vectors/df-rows
all_estimators("transformer-pairwise", as_dataframe=True)
[87]:
| name | object | |
|---|---|---|
| 0 | ScipyDist | <class 'sktime.dists_kernels.scipy_dist.ScipyD... |
[88]:
# listing all pairwise panel transformers - distances, kernels on time series
all_estimators("transformer-pairwise-panel", as_dataframe=True)
[88]:
| name | object | |
|---|---|---|
| 0 | AggrDist | <class 'sktime.dists_kernels.compose_tab_to_pa... |
| 1 | CombinedDistance | <class 'sktime.dists_kernels.algebra.CombinedD... |
| 2 | ConstantPwTrafoPanel | <class 'sktime.dists_kernels.dummy.ConstantPwT... |
| 3 | CtwDistTslearn | <class 'sktime.dists_kernels.ctw.CtwDistTslearn'> |
| 4 | DistFromAligner | <class 'sktime.dists_kernels.compose_from_alig... |
| 5 | DistFromKernel | <class 'sktime.dists_kernels.dist_to_kern.Dist... |
| 6 | DtwDist | <class 'sktime.dists_kernels.dtw._dtw_sktime.D... |
| 7 | DtwDistTslearn | <class 'sktime.dists_kernels.dtw._dtw_tslearn.... |
| 8 | DtwDtaidistMultiv | <class 'sktime.dists_kernels.dtw._dtw_dtaidist... |
| 9 | DtwDtaidistUniv | <class 'sktime.dists_kernels.dtw._dtw_dtaidist... |
| 10 | DtwPythonDist | <class 'sktime.dists_kernels.dtw._dtw_python.D... |
| 11 | EditDist | <class 'sktime.dists_kernels.edit_dist.EditDist'> |
| 12 | FlatDist | <class 'sktime.dists_kernels.compose_tab_to_pa... |
| 13 | GAKernel | <class 'sktime.dists_kernels.gak.GAKernel'> |
| 14 | IndepDist | <class 'sktime.dists_kernels.indep.IndepDist'> |
| 15 | KernelFromDist | <class 'sktime.dists_kernels.dist_to_kern.Kern... |
| 16 | LcssTslearn | <class 'sktime.dists_kernels.lcss.LcssTslearn'> |
| 17 | LuckyDtwDist | <class 'sktime.dists_kernels.lucky.LuckyDtwDist'> |
| 18 | PwTrafoPanelPipeline | <class 'sktime.dists_kernels.compose.PwTrafoPa... |
| 19 | SignatureKernel | <class 'sktime.dists_kernels.signature_kernel.... |
| 20 | SoftDtwDistTslearn | <class 'sktime.dists_kernels.dtw._dtw_tslearn.... |
3.5 扩展指南 - 实现你自己的转换器#
sktime 旨在易于扩展,既可以直接为 sktime 贡献,也可以通过自定义方法进行本地/私有扩展。
要通过新的本地或贡献的转换器扩展 sktime ,一个好的工作流程是:
阅读 transformer 扩展模板 - 这是一个包含
todo块的python文件,标记了需要添加更改的位置。可选地,如果你计划对界面进行任何重大手术:查看 基类架构 - 请注意,“普通”扩展(例如,新算法)应该可以轻松完成,无需此操作。
将转换器扩展模板复制到您自己仓库中的本地文件夹(本地/私有扩展),或者复制到您克隆的
sktime或相关仓库中的合适位置(如果是贡献的扩展),位于sktime.transformations内;重命名文件并适当地更新文件文档字符串。解决“待办”部分。通常,这意味着:更改类的名称,设置标签值,指定超参数,填充
__init__、_fit、_transform以及可选的方法如_inverse_transform或 ``_update``(详情见扩展模板)。你可以添加私有方法,只要它们不覆盖默认的公共接口。更多详情,请参见扩展模板。手动测试您的估计器:导入您的估计器并在第2.2节的工作流中运行它;然后在第2.3节的合成器中使用它。
要自动测试您的估计器:在您的估计器上调用
sktime.tests.test_all_estimators.check_estimator。您可以在类或对象实例上调用此方法。确保您已根据扩展模板在get_test_params方法中指定了测试参数。
在直接向 sktime 或其附属包贡献的情况下,还需:
3.6 总结#
transformers 是具有统一接口的数据处理步骤 -
fit、transform,以及可选的inverse_transform用作任何学习任务、预测、分类的管道组件
按输入/输出类型分类 - 时间序列、基本类型、时间序列对、面板/层次结构。
使用
all_estimators通过标签如scitype:transform-output和scitype:instancewise查找转换器丰富的组合语法 -
*表示管道,+表示特征联合,[in, out]表示变量子集,|表示多路复用/切换sktime提供了易于使用的转换器扩展模板,构建您自己的,即插即用
致谢:笔记本 3 - 转换器#
笔记本创建: fkiraly
基于设计理念:sklearn、magrittr、mlr、mlj