![]()
4 预测管道、调优和自动机器学习#
本笔记本是关于使用 sktime 进行时间序列预测的流水线处理和调优(网格搜索)。
[1]:
import warnings
import numpy as np
warnings.filterwarnings("ignore")
4.1 在预测中使用外生数据 X#
外生数据 X 是一个与 y 具有相同索引的 pd.DataFrame 。它可以可选地传递给预测器的 fit 和 predict 方法。如果在 fit 中给出了 X ,那么在 predict 中也必须给出 X ,这意味着在预测时必须提供 X 的未来值。
[ ]:
from sktime.datasets import load_longley
from sktime.forecasting.base import ForecastingHorizon
from sktime.split import temporal_train_test_split
from sktime.utils.plotting import plot_series
y, X = load_longley()
y_train, y_test, X_train, X_test = temporal_train_test_split(y=y, X=X, test_size=6)
fh = ForecastingHorizon(y_test.index, is_relative=False)
[3]:
plot_series(y_train, y_test, labels=["y_train", "y_test"]);
[4]:
X.head()
[4]:
| GNPDEFL | GNP | UNEMP | ARMED | POP | |
|---|---|---|---|---|---|
| Period | |||||
| 1947 | 83.0 | 234289.0 | 2356.0 | 1590.0 | 107608.0 |
| 1948 | 88.5 | 259426.0 | 2325.0 | 1456.0 | 108632.0 |
| 1949 | 88.2 | 258054.0 | 3682.0 | 1616.0 | 109773.0 |
| 1950 | 89.5 | 284599.0 | 3351.0 | 1650.0 | 110929.0 |
| 1951 | 96.2 | 328975.0 | 2099.0 | 3099.0 | 112075.0 |
[5]:
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(suppress_warnings=True)
forecaster.fit(y=y_train, X=X_train)
y_pred = forecaster.predict(fh=fh, X=X_test)
如果我们没有未来的 X 值来调用 predict(...),我们可以通过 ForecastX 组合类单独预测 X。这个类需要两个独立的预测器,一个用于预测 y,另一个用于预测 X。这意味着当我们调用 predict(...) 时,首先预测 X,然后将其提供给 y 预测器来预测 y。
[6]:
from sktime.forecasting.compose import ForecastX
from sktime.forecasting.var import VAR
forecaster_X = ForecastX(
forecaster_y=AutoARIMA(sp=1, suppress_warnings=True),
forecaster_X=VAR(),
)
forecaster_X.fit(y=y, X=X, fh=fh)
# now in predict() we don't need to pass X
y_pred = forecaster_X.predict(fh=fh)
4.2 简单的预测管道#
我们已经看到:管道将多个估计器组合成一个。
预测方法有两个关键的数据参数,都是时间序列:
内生数据,
y外生数据
X
管道存在于两者之中
内源性数据的管道转换器 - y 参数#
没有管道对象的转换序列:
[7]:
from sktime.forecasting.arima import AutoARIMA
from sktime.transformations.series.detrend import Deseasonalizer, Detrender
detrender = Detrender()
deseasonalizer = Deseasonalizer()
forecaster = AutoARIMA(sp=1, suppress_warnings=True)
# fit_transform
y_train_1 = detrender.fit_transform(y_train)
y_train_2 = deseasonalizer.fit_transform(y_train_1)
# fit
forecaster.fit(y_train_2)
# predidct
y_pred_2 = forecaster.predict(fh)
# inverse_transform
y_pred_1 = detrender.inverse_transform(y_pred_2)
y_pred_isolated = deseasonalizer.inverse_transform(y_pred_1)
作为一个端到端的预测器,使用 TransformedTargetForecaster 类:
[8]:
from sktime.forecasting.compose import TransformedTargetForecaster
pipe_y = TransformedTargetForecaster(
steps=[
("detrend", Detrender()),
("deseasonalize", Deseasonalizer()),
("forecaster", AutoARIMA(sp=1, suppress_warnings=True)),
]
)
pipe_y.fit(y=y_train)
y_pred_pipe = pipe_y.predict(fh=fh)
from pandas.testing import assert_series_equal
# make sure that outputs are the same
assert_series_equal(y_pred_pipe, y_pred_isolated)
外生数据上的管道转换器 - X 参数#
在传递给预测器之前,对 X 参数应用转换器。
这里:Detrender 然后 Deseasonalizer,然后传递给 AutoARIMA 的 X
[9]:
from sktime.forecasting.compose import ForecastingPipeline
pipe_X = ForecastingPipeline(
steps=[
("detrend", Detrender()),
("deseasonalize", Deseasonalizer()),
("forecaster", AutoARIMA(sp=1, suppress_warnings=True)),
]
)
pipe_X.fit(y=y_train, X=X_train)
y_pred = pipe_X.predict(fh=fh, X=X_test)
通过嵌套对 y 和 X 数据进行管道处理#
[10]:
pipe_y = TransformedTargetForecaster(
steps=[
("detrend", Detrender()),
("deseasonalize", Deseasonalizer()),
("forecaster", AutoARIMA(sp=1, suppress_warnings=True)),
]
)
pipe_X = ForecastingPipeline(
steps=[
("detrend", Detrender()),
("deseasonalize", Deseasonalizer()),
("forecaster", pipe_y),
]
)
pipe_X.fit(y=y_train, X=X_train)
y_pred = pipe_X.predict(fh=fh, X=X_test)
sktime 为估计器提供了双下划线方法,以便将它们链接到管道和其他组合中。要创建管道,我们可以使用 * 来创建 TransformedTargetForecaster,使用 ** 来创建 ForecastingPipeline。更多的双下划线方法在本文档末尾的附录部分给出。
[11]:
pipe_y = Detrender() * Deseasonalizer() * AutoARIMA()
pipe_y
[11]:
TransformedTargetForecaster(steps=[Detrender(), Deseasonalizer(), AutoARIMA()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
TransformedTargetForecaster(steps=[Detrender(), Deseasonalizer(), AutoARIMA()])
[12]:
pipe_X = Detrender() ** Deseasonalizer() ** AutoARIMA()
pipe_X
[12]:
ForecastingPipeline(steps=[Detrender(), Deseasonalizer(), AutoARIMA()])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ForecastingPipeline(steps=[Detrender(), Deseasonalizer(), AutoARIMA()])
使用双下划线嵌套,包括 X 和 y:
[13]:
pipe_nested = (
Detrender() * Deseasonalizer() * (Detrender() ** Deseasonalizer() ** AutoARIMA())
)
4.3 调优#
时间交叉验证#
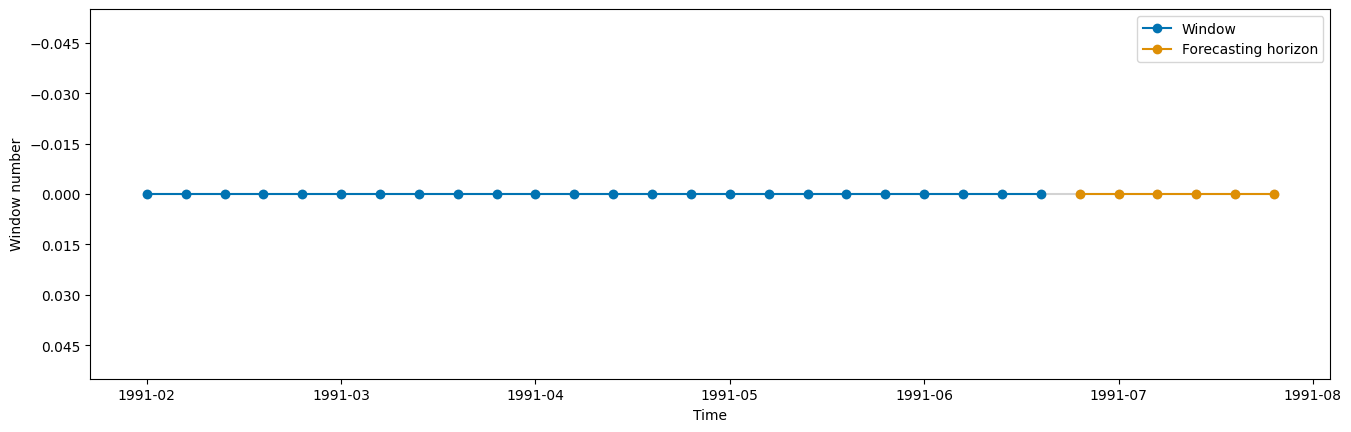
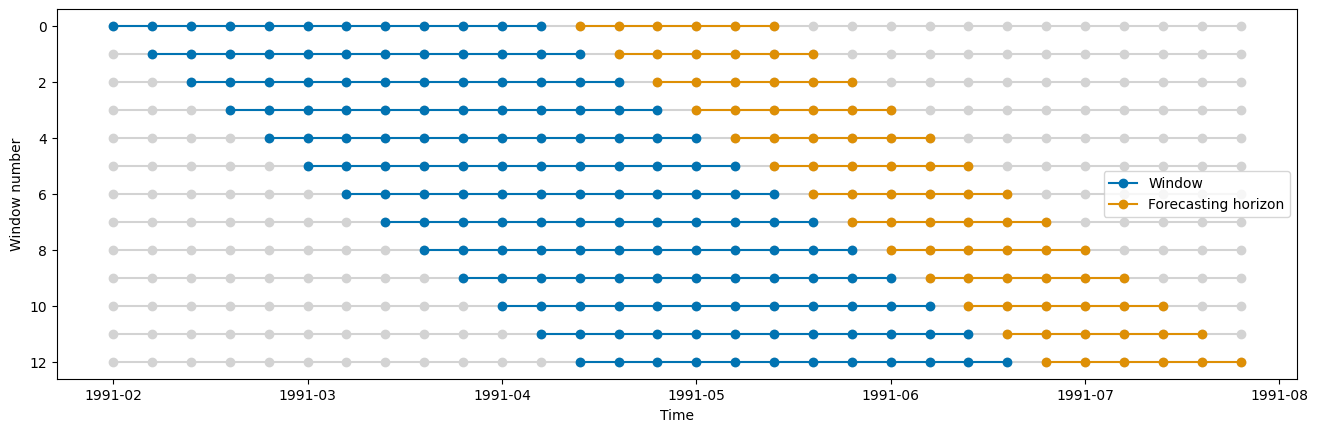
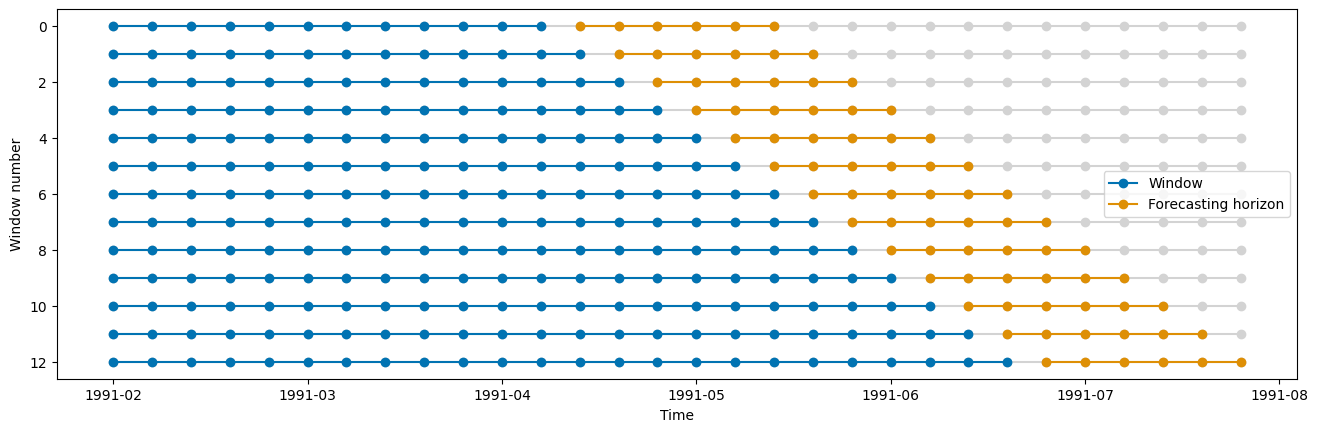
在 sktime 中,有三种不同类型的时序交叉验证分割器可用:- SingleWindowSplitter,相当于一次训练-测试分割 - SlidingWindowSplitter,使用滚动窗口方法,随着时间推移,会“遗忘”最旧的观测值 - ExpandingWindowSplitter,使用扩展窗口方法,随着时间推移,训练集中的所有观测值都会保留
[14]:
from sktime.datasets import load_shampoo_sales
y = load_shampoo_sales()
y_train, y_test = temporal_train_test_split(y=y, test_size=6)
plot_series(y_train, y_test, labels=["y_train", "y_test"]);
[15]:
from sktime.forecasting.base import ForecastingHorizon
from sktime.split import (
ExpandingWindowSplitter,
SingleWindowSplitter,
SlidingWindowSplitter,
)
from sktime.utils.plotting import plot_windows
fh = ForecastingHorizon(y_test.index, is_relative=False).to_relative(
cutoff=y_train.index[-1]
)
[16]:
cv = SingleWindowSplitter(fh=fh, window_length=len(y_train) - 6)
plot_windows(cv=cv, y=y_train)
[17]:
cv = SlidingWindowSplitter(fh=fh, window_length=12, step_length=1)
plot_windows(cv=cv, y=y_train)
[18]:
cv = ExpandingWindowSplitter(fh=fh, initial_window=12, step_length=1)
plot_windows(cv=cv, y=y_train)
[19]:
# get number of total splits (folds)
cv.get_n_splits(y=y_train)
[19]:
13
网格搜索#
在 sktime 中执行网格搜索可以通过使用交叉验证来搜索最佳参数组合,这与 sklearn 中的做法相当。
[20]:
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
from sktime.forecasting.model_selection import ForecastingGridSearchCV
from sktime.performance_metrics.forecasting import MeanSquaredError
forecaster = ExponentialSmoothing()
param_grid = {
"sp": [4, 6, 12],
"seasonal": ["add", "mul"],
"trend": ["add", "mul"],
"damped_trend": [True, False],
}
gscv = ForecastingGridSearchCV(
forecaster=forecaster,
param_grid=param_grid,
cv=cv,
verbose=1,
scoring=MeanSquaredError(square_root=True),
)
gscv.fit(y_train)
y_pred = gscv.predict(fh=fh)
Fitting 13 folds for each of 24 candidates, totalling 312 fits
[21]:
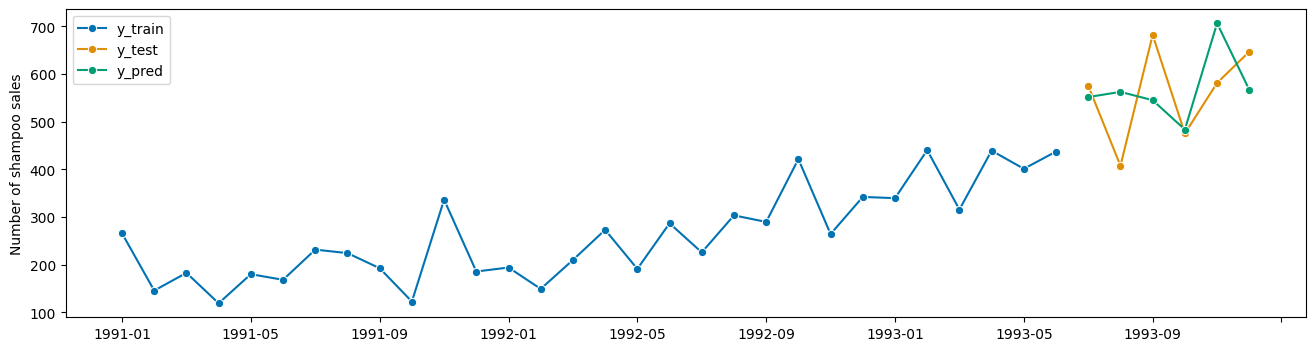
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
[22]:
gscv.best_params_
[22]:
{'damped_trend': True, 'seasonal': 'add', 'sp': 12, 'trend': 'mul'}
[23]:
gscv.best_forecaster_
[23]:
ExponentialSmoothing(damped_trend=True, seasonal='add', sp=12, trend='mul')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ExponentialSmoothing(damped_trend=True, seasonal='add', sp=12, trend='mul')
[24]:
gscv.cv_results_.head()
[24]:
| mean_test_MeanSquaredError | mean_fit_time | mean_pred_time | params | rank_test_MeanSquaredError | |
|---|---|---|---|---|---|
| 0 | 98.635359 | 0.126247 | 0.004085 | {'damped_trend': True, 'seasonal': 'add', 'sp'... | 7.0 |
| 1 | 98.327241 | 0.137226 | 0.004455 | {'damped_trend': True, 'seasonal': 'add', 'sp'... | 6.0 |
| 2 | 104.567201 | 0.127894 | 0.004397 | {'damped_trend': True, 'seasonal': 'add', 'sp'... | 13.0 |
| 3 | 112.555601 | 0.137103 | 0.004005 | {'damped_trend': True, 'seasonal': 'add', 'sp'... | 16.0 |
| 4 | 147.065358 | 0.107994 | 0.003920 | {'damped_trend': True, 'seasonal': 'add', 'sp'... | 22.0 |
使用管道进行网格搜索#
对于使用管道等组合调整参数,我们可以使用从 scikit-learn 中已知的 <estimator>__<parameter> 语法。对于多层嵌套,我们可以使用相同的语法,带有两个下划线,例如 forecaster__transformer__parameter。
[25]:
from sklearn.preprocessing import MinMaxScaler, PowerTransformer, RobustScaler
from sktime.forecasting.compose import TransformedTargetForecaster
from sktime.transformations.series.adapt import TabularToSeriesAdaptor
from sktime.transformations.series.detrend import Deseasonalizer, Detrender
forecaster = TransformedTargetForecaster(
steps=[
("detrender", Detrender()),
("deseasonalizer", Deseasonalizer()),
("minmax", TabularToSeriesAdaptor(MinMaxScaler((1, 10)))),
("power", TabularToSeriesAdaptor(PowerTransformer())),
("scaler", TabularToSeriesAdaptor(RobustScaler())),
("forecaster", ExponentialSmoothing()),
]
)
# using dunder notation to access inner objects/params as in sklearn
param_grid = {
# deseasonalizer
"deseasonalizer__model": ["multiplicative", "additive"],
# power
"power__transformer__method": ["yeo-johnson", "box-cox"],
"power__transformer__standardize": [True, False],
# forecaster
"forecaster__sp": [4, 6, 12],
"forecaster__seasonal": ["add", "mul"],
"forecaster__trend": ["add", "mul"],
"forecaster__damped_trend": [True, False],
}
gscv = ForecastingGridSearchCV(
forecaster=forecaster,
param_grid=param_grid,
cv=cv,
verbose=1,
scoring=MeanSquaredError(square_root=True), # set custom scoring function
)
gscv.fit(y_train)
y_pred = gscv.predict(fh=fh)
Fitting 13 folds for each of 192 candidates, totalling 2496 fits
[26]:
gscv.best_params_
[26]:
{'deseasonalizer__model': 'additive',
'forecaster__damped_trend': False,
'forecaster__seasonal': 'add',
'forecaster__sp': 4,
'forecaster__trend': 'add',
'power__transformer__method': 'yeo-johnson',
'power__transformer__standardize': False}
模型选择#
有三种方法可以从多个模型中选择一个模型:1) ForecastingGridSearchCV 2) MultiplexForecaster 3) relative_loss 或 RelativeLoss
ForecastingGridSearchCV#
我们可以使用 ForecastingGridSearchCV 来拟合多个预测器,并使用与 sklearn 中相同的符号表示法找到最佳的预测器。我们可以选择以下两种方式之一:param_grid: List[Dict] 或者我们只需在网格中列出预测器:forecaster": [NaiveForecaster(), STLForecaster()]。这样做的好处是,在调整其他参数的同时,我们可以使用与其他参数相同的交叉验证来找到整体最佳的预测器和参数。
[27]:
from sktime.forecasting.naive import NaiveForecaster
from sktime.forecasting.theta import ThetaForecaster
from sktime.forecasting.trend import STLForecaster
forecaster = TransformedTargetForecaster(
steps=[
("detrender", Detrender()),
("deseasonalizer", Deseasonalizer()),
("scaler", TabularToSeriesAdaptor(RobustScaler())),
("minmax2", TabularToSeriesAdaptor(MinMaxScaler((1, 10)))),
("forecaster", NaiveForecaster()),
]
)
gscv = ForecastingGridSearchCV(
forecaster=forecaster,
param_grid=[
{
"scaler__transformer__with_scaling": [True, False],
"forecaster": [NaiveForecaster()],
"forecaster__strategy": ["drift", "last", "mean"],
"forecaster__sp": [4, 6, 12],
},
{
"scaler__transformer__with_scaling": [True, False],
"forecaster": [STLForecaster(), ThetaForecaster()],
"forecaster__sp": [4, 6, 12],
},
],
cv=cv,
)
gscv.fit(y)
gscv.best_params_
[27]:
{'forecaster': NaiveForecaster(sp=4),
'forecaster__sp': 4,
'forecaster__strategy': 'last',
'scaler__transformer__with_scaling': True}
2) MultiplexForecaster#
我们可以使用 MultiplexForecaster 来比较不同预测器的性能。如果我们想比较已经分别调优和拟合的不同预测器的性能,这种方法可能会有用。MultiplexForecaster 只是一个预测器组合,它提供了一个可以通过网格搜索调优的参数 selected_forecaster: List[str]。预测器的其他参数不会被调优。
[28]:
from sktime.forecasting.compose import MultiplexForecaster
forecaster = MultiplexForecaster(
forecasters=[
("naive", NaiveForecaster()),
("stl", STLForecaster()),
("theta", ThetaForecaster()),
]
)
gscv = ForecastingGridSearchCV(
forecaster=forecaster,
param_grid={"selected_forecaster": ["naive", "stl", "theta"]},
cv=cv,
)
gscv.fit(y)
gscv.best_params_
[28]:
{'selected_forecaster': 'theta'}
3) relative_loss 或 RelativeLoss#
我们可以通过相对损失计算来比较给定测试数据上的两个模型。然而,这与上述模型选择方法1)和2)相比,并没有进行任何交叉验证。
相对损失函数将预测性能指标应用于一组预测和基准预测,并报告从预测到基准预测的指标比率。相对损失输出是非负浮点数。最佳值为0.0。相对损失函数默认使用``mean_absolute_error``作为误差指标。如果得分``>1``,则作为``y_pred``给出的预测比``y_pred_benchmark``中的基准预测更差。如果我们想要自定义相对损失,可以使用``RelativeLoss``评分器类,例如提供一个自定义损失函数。
[29]:
from sktime.performance_metrics.forecasting import mean_squared_error, relative_loss
relative_loss(y_true=y_test, y_pred=y_pred_1, y_pred_benchmark=y_pred_2)
[29]:
123.00771294252276
[30]:
from sktime.performance_metrics.forecasting import RelativeLoss
relative_mse = RelativeLoss(relative_loss_function=mean_squared_error)
relative_mse(y_true=y_test, y_pred=y_pred_1, y_pred_benchmark=y_pred_2)
[30]:
14720.015012346896
将管道结构调整作为超参数#
流水线结构选择影响性能
sktime 允许通过结构化组合器来展示这些选择:
在变换/预测之间切换:
MultiplexTransformer,MultiplexForecaster变压器开关:
OptionalPassthrough变换器序列:
Permute
结合管道和 FeatureUnion 以构建丰富的结构空间
变压器的组合#
给定一组四个不同的变压器,我们想知道这四个变压器的哪种组合具有最佳误差。因此,总共有 4² = 16 种不同的组合。我们可以使用 GridSearchCV 来找到最佳组合。
[31]:
steps = [
("detrender", Detrender()),
("deseasonalizer", Deseasonalizer()),
("power", TabularToSeriesAdaptor(PowerTransformer())),
("scaler", TabularToSeriesAdaptor(RobustScaler())),
("forecaster", ExponentialSmoothing()),
]
在 sktime 中,有一个名为 OptionalPassthrough() 的转换器组合,它接受一个转换器作为参数,并有一个参数 passthrough: bool。设置 passthrough=True 将对给定数据返回一个恒等变换。设置 passthrough=False 将对数据应用给定的内部转换器。
[32]:
from sktime.transformations.compose import OptionalPassthrough
transformer = OptionalPassthrough(transformer=Detrender(), passthrough=True)
transformer.fit_transform(y_train).head()
[32]:
1991-01 266.0
1991-02 145.9
1991-03 183.1
1991-04 119.3
1991-05 180.3
Freq: M, Name: Number of shampoo sales, dtype: float64
[33]:
y_train.head()
[33]:
1991-01 266.0
1991-02 145.9
1991-03 183.1
1991-04 119.3
1991-05 180.3
Freq: M, Name: Number of shampoo sales, dtype: float64
[34]:
transformer = OptionalPassthrough(transformer=Detrender(), passthrough=False)
transformer.fit_transform(y_train).head()
[34]:
1991-01 130.376344
1991-02 1.503263
1991-03 29.930182
1991-04 -42.642900
1991-05 9.584019
Freq: M, dtype: float64
[35]:
forecaster = TransformedTargetForecaster(
steps=[
("detrender", OptionalPassthrough(Detrender())),
("deseasonalizer", OptionalPassthrough(Deseasonalizer())),
("power", OptionalPassthrough(TabularToSeriesAdaptor(PowerTransformer()))),
("scaler", OptionalPassthrough(TabularToSeriesAdaptor(RobustScaler()))),
("forecaster", ExponentialSmoothing()),
]
)
param_grid = {
"detrender__passthrough": [True, False],
"deseasonalizer__passthrough": [True, False],
"power__passthrough": [True, False],
"scaler__passthrough": [True, False],
}
gscv = ForecastingGridSearchCV(
forecaster=forecaster,
param_grid=param_grid,
cv=cv,
verbose=1,
scoring=MeanSquaredError(square_root=True),
)
gscv.fit(y_train)
Fitting 13 folds for each of 16 candidates, totalling 208 fits
[35]:
ForecastingGridSearchCV(cv=ExpandingWindowSplitter(fh=ForecastingHorizon([1, 2, 3, 4, 5, 6], dtype='int64', is_relative=True),
initial_window=12),
forecaster=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('power',
OptionalPassthrough(transform...
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
ExponentialSmoothing())]),
n_jobs=-1,
param_grid={'deseasonalizer__passthrough': [True,
False],
'detrender__passthrough': [True, False],
'power__passthrough': [True, False],
'scaler__passthrough': [True, False]},
scoring=MeanSquaredError(square_root=True), verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ForecastingGridSearchCV(cv=ExpandingWindowSplitter(fh=ForecastingHorizon([1, 2, 3, 4, 5, 6], dtype='int64', is_relative=True),
initial_window=12),
forecaster=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('power',
OptionalPassthrough(transform...
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
ExponentialSmoothing())]),
n_jobs=-1,
param_grid={'deseasonalizer__passthrough': [True,
False],
'detrender__passthrough': [True, False],
'power__passthrough': [True, False],
'scaler__passthrough': [True, False]},
scoring=MeanSquaredError(square_root=True), verbose=1)TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('power',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=PowerTransformer()))),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster', ExponentialSmoothing())])TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('power',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=PowerTransformer()))),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster', ExponentialSmoothing())])表现最佳的变压器组合:
[36]:
gscv.best_params_
[36]:
{'deseasonalizer__passthrough': True,
'detrender__passthrough': False,
'power__passthrough': True,
'scaler__passthrough': True}
表现最差的变压器组合:
[37]:
# worst params
gscv.cv_results_.sort_values(by="mean_test_MeanSquaredError", ascending=True).iloc[-1][
"params"
]
[37]:
{'deseasonalizer__passthrough': False,
'detrender__passthrough': True,
'power__passthrough': False,
'scaler__passthrough': True}
变压器排列#
给定一组四个不同的变压器,我们想知道这四个变压器的哪个排列(顺序)具有最佳误差。总共有 4! = 24 种不同的排列。我们可以使用 GridSearchCV 来找到最佳排列。
[38]:
from sktime.forecasting.compose import Permute
[39]:
forecaster = TransformedTargetForecaster(
steps=[
("detrender", Detrender()),
("deseasonalizer", Deseasonalizer()),
("power", TabularToSeriesAdaptor(PowerTransformer())),
("scaler", TabularToSeriesAdaptor(RobustScaler())),
("forecaster", ExponentialSmoothing()),
]
)
param_grid = {
"permutation": [
["detrender", "deseasonalizer", "power", "scaler", "forecaster"],
["power", "scaler", "detrender", "deseasonalizer", "forecaster"],
["scaler", "deseasonalizer", "power", "detrender", "forecaster"],
["deseasonalizer", "power", "scaler", "detrender", "forecaster"],
]
}
permuted = Permute(estimator=forecaster, permutation=None)
gscv = ForecastingGridSearchCV(
forecaster=permuted,
param_grid=param_grid,
cv=cv,
verbose=1,
scoring=MeanSquaredError(square_root=True),
)
permuted = gscv.fit(y, fh=fh)
Fitting 19 folds for each of 4 candidates, totalling 76 fits
[40]:
permuted.cv_results_
[40]:
| mean_test_MeanSquaredError | mean_fit_time | mean_pred_time | params | rank_test_MeanSquaredError | |
|---|---|---|---|---|---|
| 0 | 104.529303 | 0.119823 | 0.032105 | {'permutation': ['detrender', 'deseasonalizer'... | 4.0 |
| 1 | 95.172818 | 0.118840 | 0.033758 | {'permutation': ['power', 'scaler', 'detrender... | 1.5 |
| 2 | 95.243942 | 0.114363 | 0.033743 | {'permutation': ['scaler', 'deseasonalizer', '... | 3.0 |
| 3 | 95.172818 | 0.119377 | 0.030739 | {'permutation': ['deseasonalizer', 'power', 's... | 1.5 |
[41]:
gscv.best_params_
[41]:
{'permutation': ['power',
'scaler',
'detrender',
'deseasonalizer',
'forecaster']}
[42]:
# worst params
gscv.cv_results_.sort_values(by="mean_test_MeanSquaredError", ascending=True).iloc[-1][
"params"
]
[42]:
{'permutation': ['detrender',
'deseasonalizer',
'power',
'scaler',
'forecaster']}
4.4 综合运用:类似AutoML的管道和调优#
结合上述示例中的所有成分,我们可以构建一个接近通常称为 AutoML 的预测器。通过AutoML,我们旨在自动化尽可能多的ML模型创建步骤。我们可以用于此的 sktime 主要组件包括: - TransformedTargetForecaster - ForecastingPipeline - ForecastingGridSearchCV - OptionalPassthrough - Permute
单变量示例#
请参阅附录部分,了解使用外生数据的示例
[43]:
pipe_y = TransformedTargetForecaster(
steps=[
("detrender", OptionalPassthrough(Detrender())),
("deseasonalizer", OptionalPassthrough(Deseasonalizer())),
("scaler", OptionalPassthrough(TabularToSeriesAdaptor(RobustScaler()))),
("forecaster", STLForecaster()),
]
)
permuted_y = Permute(estimator=pipe_y, permutation=None)
param_grid = {
"permutation": [
["detrender", "deseasonalizer", "scaler", "forecaster"],
["scaler", "deseasonalizer", "detrender", "forecaster"],
],
"estimator__detrender__passthrough": [True, False],
"estimator__deseasonalizer__passthrough": [True, False],
"estimator__scaler__passthrough": [True, False],
"estimator__scaler__transformer__transformer__with_scaling": [True, False],
"estimator__scaler__transformer__transformer__with_centering": [True, False],
"estimator__forecaster__sp": [4, 8, 12],
}
gscv = ForecastingGridSearchCV(
forecaster=permuted_y,
param_grid=param_grid,
cv=cv,
verbose=1,
scoring=MeanSquaredError(square_root=True),
error_score="raise",
)
gscv.fit(y=y_train, fh=fh)
Fitting 13 folds for each of 192 candidates, totalling 2496 fits
[43]:
ForecastingGridSearchCV(cv=ExpandingWindowSplitter(fh=ForecastingHorizon([1, 2, 3, 4, 5, 6], dtype='int64', is_relative=True),
initial_window=12),
error_score='raise',
forecaster=Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),...
'estimator__scaler__passthrough': [True,
False],
'estimator__scaler__transformer__transformer__with_centering': [True,
False],
'estimator__scaler__transformer__transformer__with_scaling': [True,
False],
'permutation': [['detrender',
'deseasonalizer', 'scaler',
'forecaster'],
['scaler', 'deseasonalizer',
'detrender',
'forecaster']]},
scoring=MeanSquaredError(square_root=True), verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ForecastingGridSearchCV(cv=ExpandingWindowSplitter(fh=ForecastingHorizon([1, 2, 3, 4, 5, 6], dtype='int64', is_relative=True),
initial_window=12),
error_score='raise',
forecaster=Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),...
'estimator__scaler__passthrough': [True,
False],
'estimator__scaler__transformer__transformer__with_centering': [True,
False],
'estimator__scaler__transformer__transformer__with_scaling': [True,
False],
'permutation': [['detrender',
'deseasonalizer', 'scaler',
'forecaster'],
['scaler', 'deseasonalizer',
'detrender',
'forecaster']]},
scoring=MeanSquaredError(square_root=True), verbose=1)Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
STLForecaster())]))TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster', STLForecaster())])TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster', STLForecaster())])[44]:
gscv.cv_results_["mean_test_MeanSquaredError"].min()
[44]:
83.44136911735615
[45]:
gscv.cv_results_["mean_test_MeanSquaredError"].max()
[45]:
125.54124792614672
4.5 模型回测#
在拟合模型后,我们可以像交叉验证一样评估模型在过去的表现误差。为此,我们可以使用 evaluate 函数。这种方法通常也称为回测,因为我们希望测试预测器在过去的表现。
[46]:
from sktime.forecasting.model_evaluation import evaluate
y = load_shampoo_sales()
results = evaluate(
forecaster=STLForecaster(sp=12),
y=y,
cv=ExpandingWindowSplitter(fh=[1, 2, 3, 4, 5, 6], initial_window=12, step_length=6),
scoring=MeanSquaredError(square_root=True),
return_data=True,
)
results
[46]:
| test_MeanSquaredError | fit_time | pred_time | len_train_window | cutoff | y_train | y_test | y_pred | |
|---|---|---|---|---|---|---|---|---|
| 0 | 85.405220 | 0.008634 | 0.009597 | 12 | 1991-12 | Period 1991-01 266.0 1991-02 145.9 1991-... | Period 1992-01 194.3 1992-02 149.5 1992-... | 1992-01 266.0 1992-02 145.9 1992-03 1... |
| 1 | 129.383456 | 0.010045 | 0.007728 | 18 | 1992-06 | Period 1991-01 266.0 1991-02 145.9 1991-... | Period 1992-07 226.0 1992-08 303.6 1992-... | 1992-07 270.953646 1992-08 263.653646 19... |
| 2 | 126.393156 | 0.009373 | 0.008245 | 24 | 1992-12 | Period 1991-01 266.0 1991-02 145.9 1991-... | Period 1993-01 339.7 1993-02 440.4 1993-... | 1993-01 260.633333 1993-02 215.833333 19... |
| 3 | 171.142305 | 0.012287 | 0.009526 | 30 | 1993-06 | Period 1991-01 266.0 1991-02 145.9 1991-... | Period 1993-07 575.5 1993-08 407.6 1993-... | 1993-07 378.659609 1993-08 450.927848 19... |
[47]:
plot_series(
y,
results["y_pred"].iloc[0],
results["y_pred"].iloc[1],
results["y_pred"].iloc[2],
results["y_pred"].iloc[3],
markers=["o", "", "", "", ""],
labels=["y_true"] + ["y_pred (Backtest " + str(x) + ")" for x in range(4)],
);
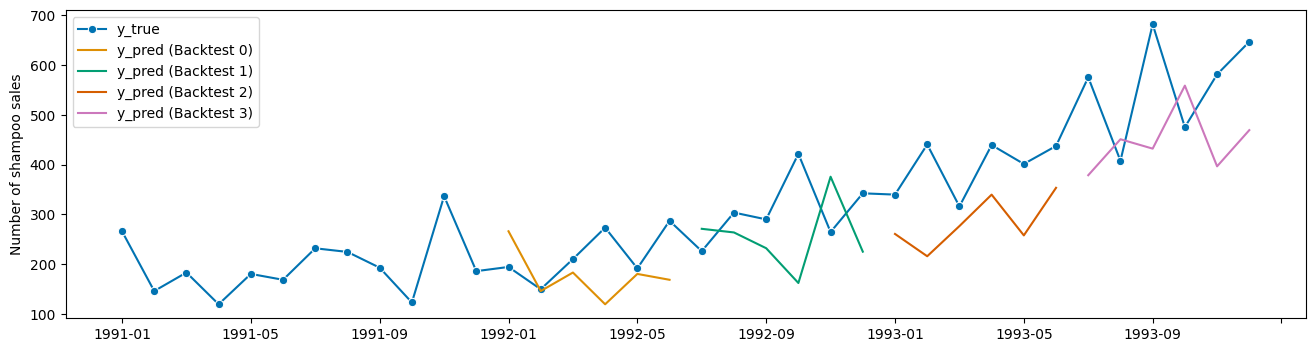
4.6 附录#
带有外生数据的类似AutoML的管道#
[48]:
from sktime.datasets import load_macroeconomic
data = load_macroeconomic()
y = data["unemp"]
X = data.drop(columns=["unemp"])
y_train, y_test, X_train, X_test = temporal_train_test_split(y, X, test_size=40)
fh = ForecastingHorizon(np.arange(1, 41), is_relative=True)
[49]:
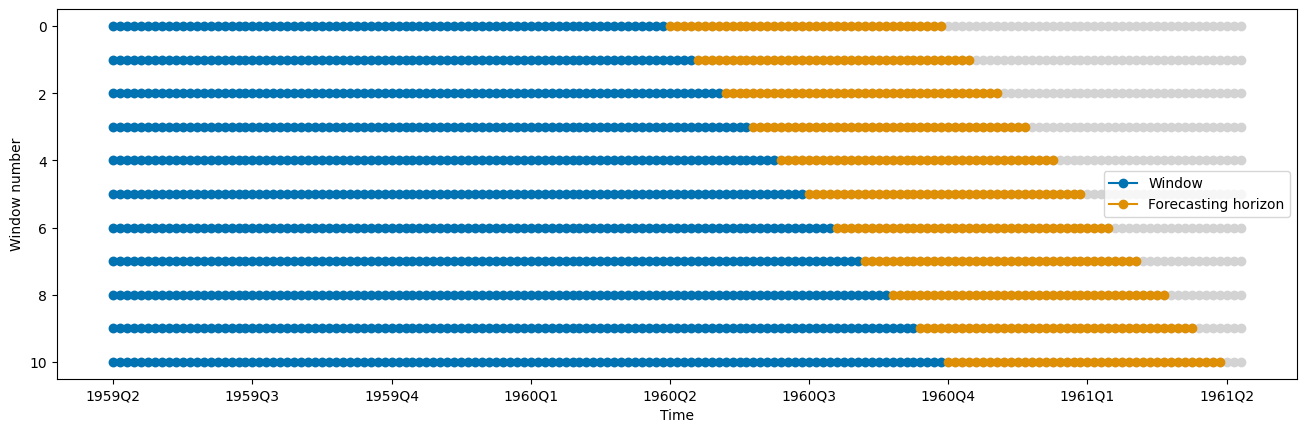
cv = ExpandingWindowSplitter(fh=fh, initial_window=80, step_length=4)
plot_windows(cv=cv, y=y_train)
[50]:
from sktime.datasets import load_macroeconomic
from sktime.forecasting.statsforecast import StatsForecastAutoARIMA
from sktime.split import temporal_train_test_split
data = load_macroeconomic()
y = data["unemp"]
X = data.drop(columns=["unemp"])
y_train, y_test, X_train, X_test = temporal_train_test_split(y, X, test_size=40)
fh = ForecastingHorizon(np.arange(1, 41), is_relative=True)
pipe_y = TransformedTargetForecaster(
steps=[
("detrender", OptionalPassthrough(Detrender())),
("deseasonalizer", OptionalPassthrough(Deseasonalizer())),
("scaler", OptionalPassthrough(TabularToSeriesAdaptor(RobustScaler()))),
("forecaster", StatsForecastAutoARIMA(sp=4)),
]
)
permuted_y = Permute(pipe_y, permutation=None)
pipe_X = TransformedTargetForecaster(
steps=[
("detrender", OptionalPassthrough(Detrender())),
("deseasonalizer", OptionalPassthrough(Deseasonalizer())),
("scaler", OptionalPassthrough(TabularToSeriesAdaptor(RobustScaler()))),
("forecaster", permuted_y),
]
)
permuted_X = Permute(pipe_X, permutation=None)
[51]:
gscv = ForecastingGridSearchCV(
forecaster=permuted_X,
param_grid={
"estimator__forecaster__permutation": [
["detrender", "deseasonalizer", "scaler", "forecaster"],
["scaler", "detrender", "deseasonalizer", "forecaster"],
],
"permutation": [
["detrender", "deseasonalizer", "scaler", "forecaster"],
["scaler", "detrender", "deseasonalizer", "forecaster"],
],
"estimator__forecaster__estimator__scaler__passthrough": [True, False],
"estimator__scaler__passthrough": [True, False],
},
cv=cv,
error_score="raise",
scoring=MeanSquaredError(square_root=True),
)
gscv.fit(y=y_train, X=X_train)
[51]:
ForecastingGridSearchCV(cv=ExpandingWindowSplitter(fh=ForecastingHorizon([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40],
dtype='int64', is_relative=True),
initial_window=80,
step_length=4),
error_score='raise',
forecaster=Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
Op...
'estimator__forecaster__permutation': [['detrender',
'deseasonalizer',
'scaler',
'forecaster'],
['scaler',
'detrender',
'deseasonalizer',
'forecaster']],
'estimator__scaler__passthrough': [True,
False],
'permutation': [['detrender',
'deseasonalizer', 'scaler',
'forecaster'],
['scaler', 'detrender',
'deseasonalizer',
'forecaster']]},
scoring=MeanSquaredError(square_root=True))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ForecastingGridSearchCV(cv=ExpandingWindowSplitter(fh=ForecastingHorizon([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40],
dtype='int64', is_relative=True),
initial_window=80,
step_length=4),
error_score='raise',
forecaster=Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
Op...
'estimator__forecaster__permutation': [['detrender',
'deseasonalizer',
'scaler',
'forecaster'],
['scaler',
'detrender',
'deseasonalizer',
'forecaster']],
'estimator__scaler__passthrough': [True,
False],
'permutation': [['detrender',
'deseasonalizer', 'scaler',
'forecaster'],
['scaler', 'detrender',
'deseasonalizer',
'forecaster']]},
scoring=MeanSquaredError(square_root=True))Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
StatsForecastAutoARIMA(sp=4))])))]))TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
StatsForecastAutoARIMA(sp=4))])))])TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
Permute(estimator=TransformedTargetForecaster(steps=[('detrender',
OptionalPassthrough(transformer=Detrender())),
('deseasonalizer',
OptionalPassthrough(transformer=Deseasonalizer())),
('scaler',
OptionalPassthrough(transformer=TabularToSeriesAdaptor(transformer=RobustScaler()))),
('forecaster',
StatsForecastAutoARIMA(sp=4))])))])[52]:
gscv.cv_results_["mean_test_MeanSquaredError"].min()
[52]:
1.9856591203311482
[53]:
gscv.cv_results_["mean_test_MeanSquaredError"].max()
[53]:
2.1207628182179863
[54]:
gscv.best_params_
[54]:
{'estimator__forecaster__estimator__scaler__passthrough': True,
'estimator__forecaster__permutation': ['detrender',
'deseasonalizer',
'scaler',
'forecaster'],
'estimator__scaler__passthrough': False,
'permutation': ['detrender', 'deseasonalizer', 'scaler', 'forecaster']}
[55]:
# worst params
gscv.cv_results_.sort_values(by="mean_test_MeanSquaredError", ascending=True).iloc[-1][
"params"
]
[55]:
{'estimator__forecaster__estimator__scaler__passthrough': True,
'estimator__forecaster__permutation': ['scaler',
'detrender',
'deseasonalizer',
'forecaster'],
'estimator__scaler__passthrough': True,
'permutation': ['scaler', 'detrender', 'deseasonalizer', 'forecaster']}
致谢:笔记本 4 - 管道#
笔记本创建: aiwalter