![]()
使用 sktime 和 ClaSP 进行时间序列分割#
在这个笔记本中,我们将展示 sktime 和 ClaSP 用于时间序列分割任务。我们将首先介绍时间序列分割任务,展示 ClaSP 的易用性,并展示找到的分割示例。
时间序列分割的任务#
本笔记本中我们将研究的一个特别有趣的问题是时间序列分割(TSS)。
TSS 旨在发现时间序列中与相邻区域在语义上不相似的区域。TSS 是一项重要技术,因为它通过分析测量结果可以推断出底层系统的属性,因为从一个片段到另一个片段的转变通常是由被监测过程的状态变化引起的,例如从一个操作状态到另一个操作状态的转变或异常事件的开始。变化点检测(CPD)的任务是找到底层信号中的这种转变,而分段是变化点的有序序列。
The following image shows two examples of (a) heartbeats recorded from a patient with different medical conditions, and (b) a person walking, jogging and running. The time series contain three visually very distinct segments, which we also denoted by colors and annotated by the underlying state. 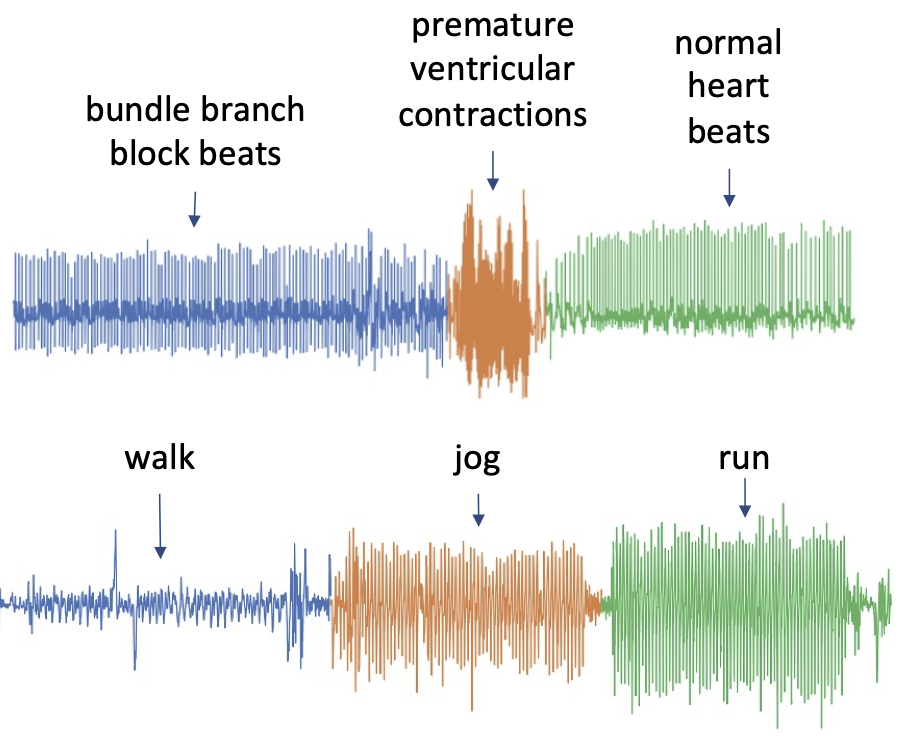
任何TSS算法的任务是找到这些片段。
先决条件#
[14]:
import sys
sys.path.insert(0, "..")
import pandas as pd
import seaborn as sns
sns.set_theme()
sns.set_color_codes()
from sktime.annotation.clasp import ClaSPSegmentation, find_dominant_window_sizes
from sktime.annotation.plotting.utils import (
plot_time_series_with_change_points,
plot_time_series_with_profiles,
)
from sktime.datasets import load_electric_devices_segmentation
以下用例展示了一个包含四个变化点的家用电器能耗概况,这些变化点表示不同的运行状态或接入的家用电器。
[2]:
ts, period_size, true_cps = load_electric_devices_segmentation()
_ = plot_time_series_with_change_points("Electric Devices", ts, true_cps)
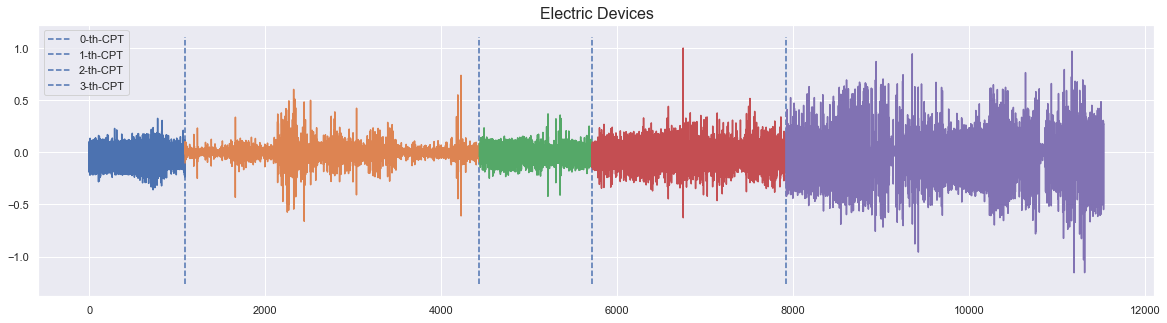
注释的变更点围绕时间戳 \([1090,4436,5712,7923]\) ,从中记录了不同的电器设备。
通过 ClaSP 进行时间序列分割#
这个 Jupyter-Notebook 展示了 分类评分概况 (ClaSP) 在时间序列分割中的使用。
ClaSP 分层地将一个时间序列(TS)分成两部分,其中每个分割点是通过为每个可能的分割点训练一个二进制时间序列分类器,并选择准确率最高的那一个来确定的,即,能够最好地识别子序列属于任一分区的那个分割点。
详情请参阅我们在 CIKM ‘21 发表的论文:P. Schäfer, A. Ermshaus, U. Leser, ClaSP - Time Series Segmentation, CIKM 2021
获取数据#
首先,让我们查看并绘制要分割的时间序列。
[15]:
# ts is a pd.Series
# we convert it into a DataFrame for display purposed only
pd.DataFrame(ts)
[15]:
| 1 | |
|---|---|
| 0 | |
| 1 | -0.187086 |
| 2 | 0.098119 |
| 3 | 0.088967 |
| 4 | 0.107328 |
| 5 | -0.193514 |
| ... | ... |
| 11528 | 0.300240 |
| 11529 | 0.200745 |
| 11530 | -0.548908 |
| 11531 | 0.274886 |
| 11532 | 0.274022 |
11532 rows × 1 columns
ClaSP - 分类分数概况#
让我们运行 ClaSP 来找到真正的变化点。
ClaSP 有两个超参数:- 周期长度 - 要查找的变点数量
ClaSP 的结果是一个概况,其中最大值表示找到的变化点。
[4]:
clasp = ClaSPSegmentation(period_length=period_size, n_cps=5, fmt="sparse")
found_cps = clasp.fit_predict(ts)
profiles = clasp.profiles
scores = clasp.scores
print("The found change points are", found_cps.to_numpy())
The found change points are [1038 4525 5719 7883]
分割的可视化#
… 并且我们可视化结果。
[5]:
_ = plot_time_series_with_profiles(
"Electric Devices",
ts,
profiles,
true_cps,
found_cps,
)
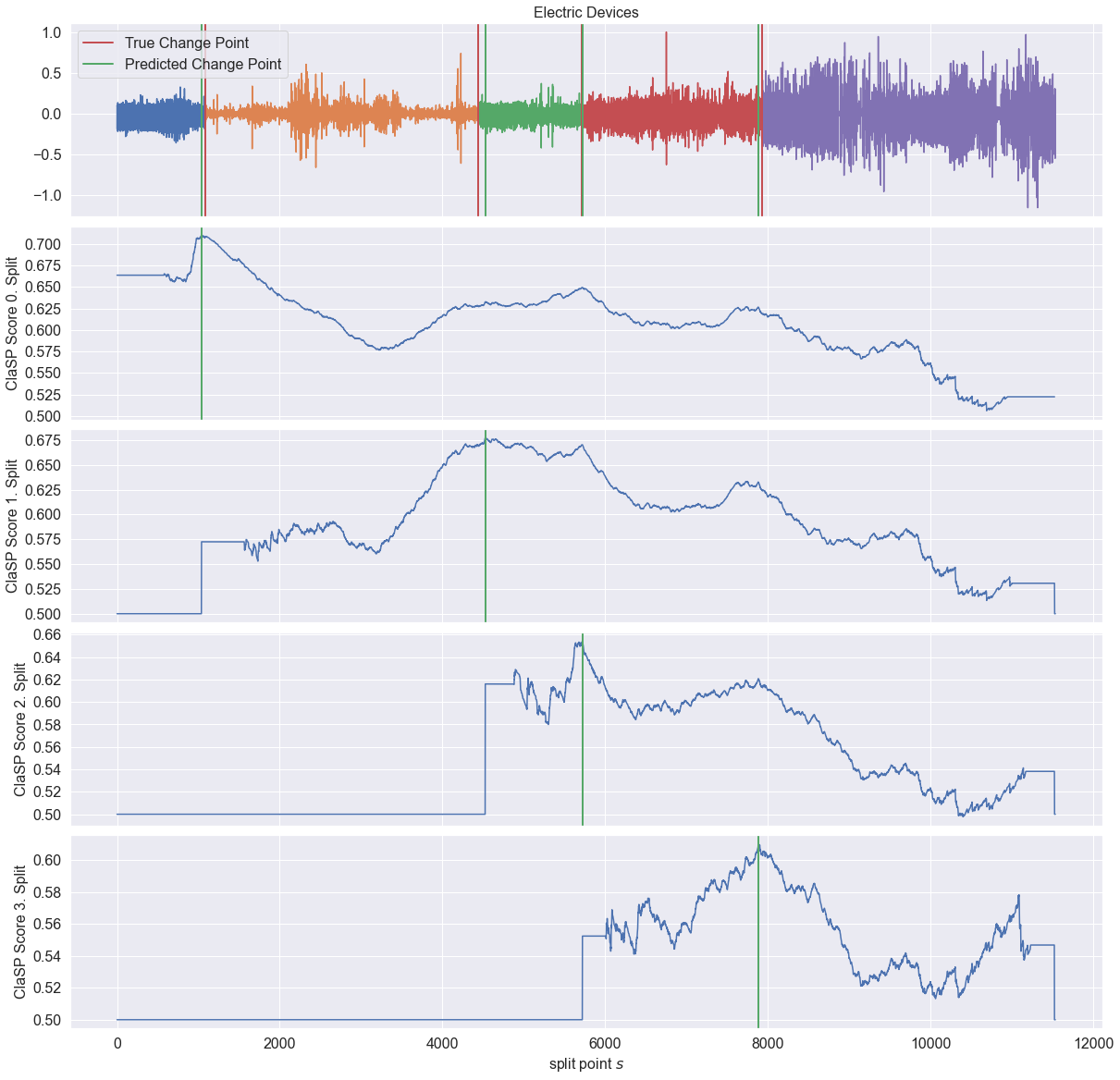
绿色预测的变化点与红色真实的变化点非常相似。
输出格式#
ClaSP 根据 fmt 输入参数提供两种不同的输出格式:- fmt:"sparse":提供核心变化点 - fmt:"dense":提供分段区间序列
我们之前已经见过 fmt="sparse" 的输出。这次我们返回 fmt="dense"。
[6]:
clasp = ClaSPSegmentation(period_length=period_size, n_cps=5, fmt="dense")
found_segmentation = clasp.fit_predict(ts)
print(found_segmentation)
IntervalIndex([(0, 1038], (1038, 4525], (4525, 5719], (5719, 7883], (7883, 11532]],
closed='right',
dtype='interval[int64]')
ClaSP - 窗口大小选择#
ClaSP 将窗口大小 𝑤 作为超参数。此参数对 ClaSP 的性能有数据依赖的影响。当选择过小时,所有窗口往往看起来相似;当选择过大时,窗口更有可能与相邻段重叠,从而模糊其区分能力。
选择窗口大小的一个简单而有效的方法是傅里叶变换的主导频率。
[7]:
dominant_period_size = find_dominant_window_sizes(ts)
print("Dominant Period", dominant_period_size)
Dominant Period 10
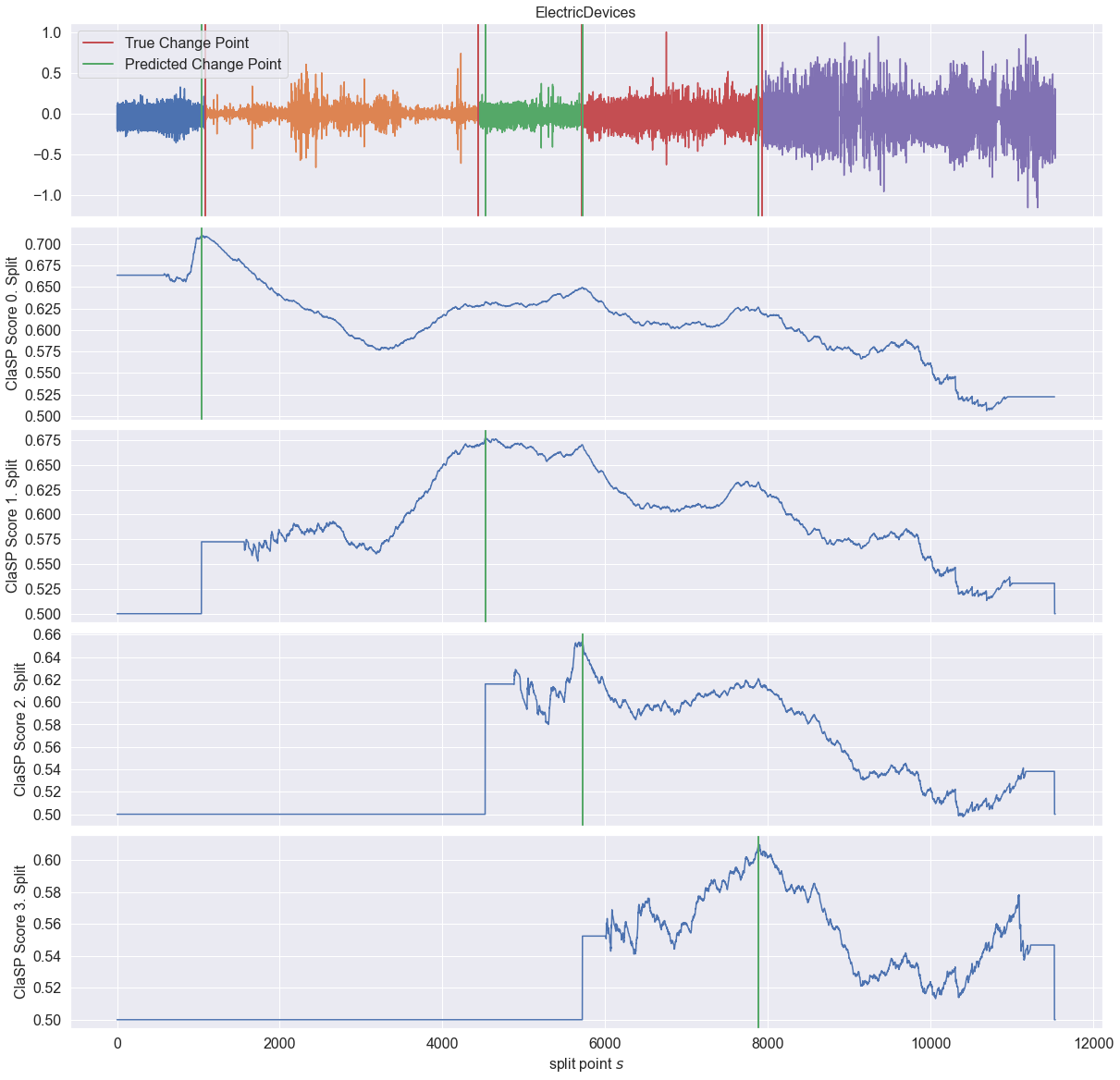
让我们使用找到的主导周期长度来运行 ClaSP。
[8]:
clasp = ClaSPSegmentation(period_length=dominant_period_size, n_cps=5)
found_cps = clasp.fit_predict(ts)
profiles = clasp.profiles
scores = clasp.scores
_ = plot_time_series_with_profiles(
"ElectricDevices",
ts,
profiles,
true_cps,
found_cps,
)
[ ]: