 简介:
简介:
- 我们介绍了MathChat,这是一个利用大型语言模型(LLM),特别是GPT-4,来解决高级数学问题的对话框架。
- MathChat在解决具有挑战性的数学问题时提高了LLM的性能,比基本提示和其他策略提高了约6%。在代数类别中,准确性提高了15%。
- 尽管有所进展,但GPT-4仍然难以解决非常具有挑战性的数学问题,即使采用了有效的提示策略。需要进一步改进,例如开发更具体的助手模型或集成新的工具和提示。
最近的大型语言模型(LLM)如GTP-3.5和GPT-4在各种任务上展示了令人惊讶的能力,例如文本生成、问题回答和代码生成。此外,这些模型可以通过对话与人类进行交流,并记住先前的上下文,使人类更容易与它们进行互动。这些模型在我们的日常生活中扮演着越来越重要的角色,帮助人们完成不同的任务,如写电子邮件、总结文件和编写代码。
在本博客文章中,我们探讨了LLM的问题解决能力。具体而言,我们对它们解决高级数学问题的能力感兴趣,这可能代表了一类需要精确推理并具有确定性解决方案的更广泛问题。
我们介绍了MathChat,这是一个用于解决具有挑战性数学问题的对话框架,利用了最先进的LLM的聊天优化特性。该框�架利用用户代理和LLM助手之间的对话模拟来解决数学问题。我们还测试了之前的提示技术以进行比较。
MathChat框架
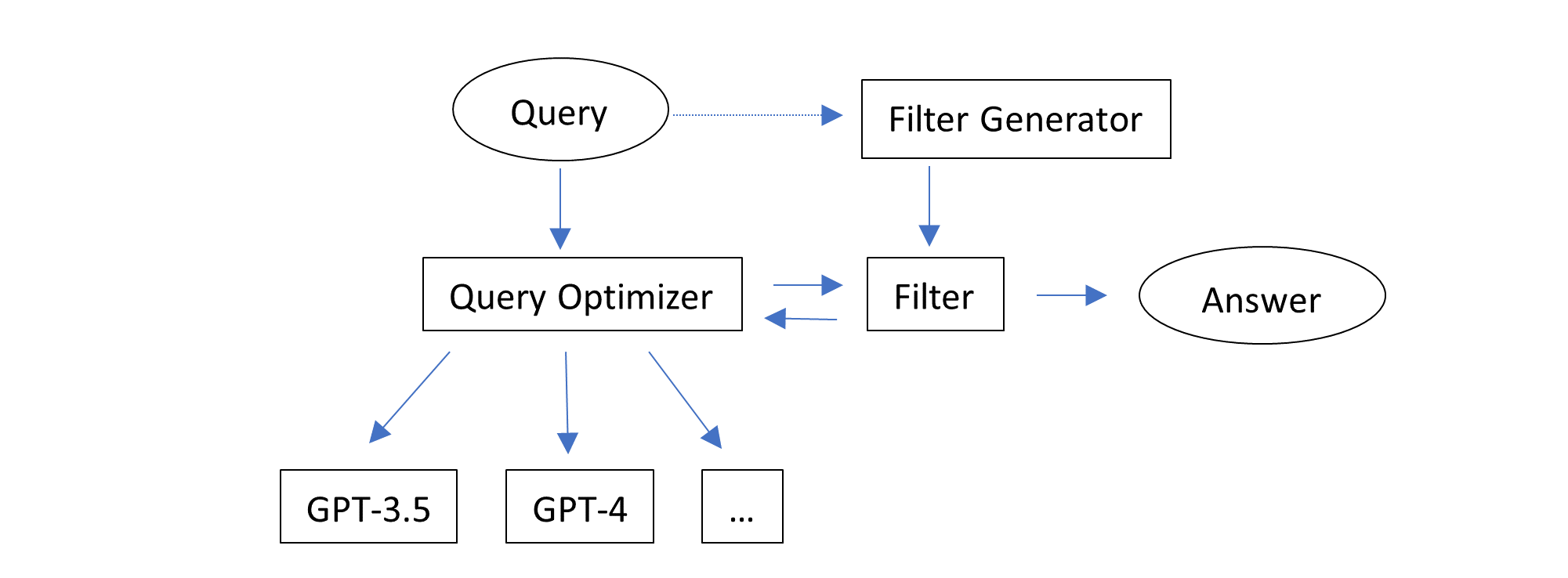
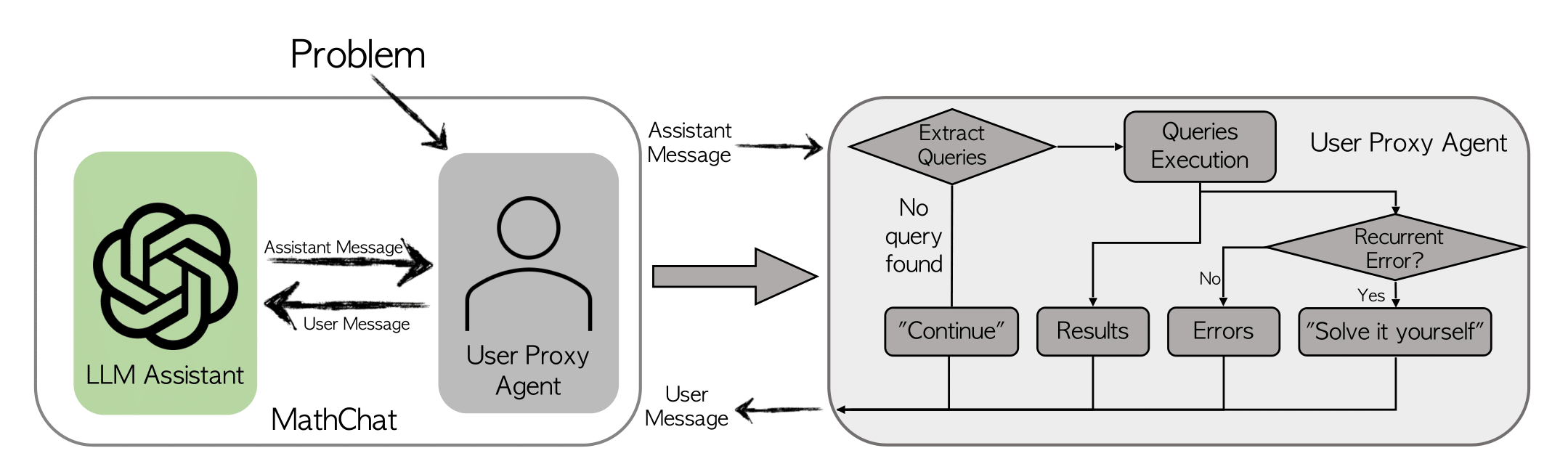
MathChat模拟了LLM助手和用户代理之间的对话。正如名称所示,用户代理充当用户的代理,负责与LLM助手进行通信并以所需的方式继续对话。
用户代理首先向LLM助手提出一个数学问题,并通过初始提示来指导助手在解决问题时如何进行协作。我们采用了现有的提示方法,如CoT(思维链)和使用工具的提示。提示的关键组成部分包括:
-
使用工具的提示: 这指导LLM助手使用正确格式的Python代码来解决问题,使用户代理能够解析代码并提供适当的结果。
-
问题解决策略选择提示: 助手被指示选择三种潜在的问题解决策略,包括:
- 编写一个Python程序直接解决问题。
- 不使用Python直接解决问题,这样可以锻炼LLMs固有的推理能力。
- 使用Python逐步解决问题。当前两种策略不适用时,应使用此策略。
-
最终答案封装提示: 这部分指示助手将最终答案放在 \boxed 中。
MathChat中的提示设计灵活,可以轻松地进行改进,包括添加其他工具,如Wolfram Alpha。
让我们来看一个用户代理人和LLM助手(GPT-4)之间的示例对话。对话集中在如何使用Python解决不等式问题上。 (为了易读性,对话进行了修改。)
| 参与者 | 对话 |
|---|---|
| 用户代理人 | (初始提示:让我们使用Python解决一个数学��问题...)问题:找出所有满足不等式(2x+10)(x+3)<(3x+9)(x+8)的x。用区间表示你的答案。 |
| LLM助手 | 解决这个问题的关键思想是找到临界点,即不等式相等的点。然后,测试临界点之间的区间,找到不等式成立的区间。 |
| LLM助手(继续) | 这是用Python代码找到临界点的方法:from sympy import symbols, Eq, solve; x = symbols("x"); lhs = (2*x + 10)*(x + 3); rhs = (3*x + 9)*(x + 8); equation = Eq(lhs, rhs); critical_points = solve(equation, x); critical_points |
| 用户代理人 | 临界点是:[-14, -3] |
实验设置
我们评估了MathChat带来的改进。
在实验中,我们专注于来自MATH数据集的5级问题,这些问题由高中竞赛问题组成。这些问题涉及定理的应用和复杂方程的推导,即使对于本科生来说也具有挑战性。我们评估了数据集中的6个类别(几何学除外):初等代数,代数,数论,计数与概率,中级代数和预微积分。
我们评估了GPT-4,并使用OpenAI API的默认配置。为了获得最终的性能,我们手动将最终答案与正确答案进行比较。对于原始提示、思维程序和MathChat,我们让GPT-4将最终答案放在_\boxed_中,并将PoT函数的返回值作为最终答案。
我们还评估了以下方法进行比较:
-
原始提示: 评估GPT-4的直接问题解决能力。使用的提示是:“仔细解决问题。将最终答案放在\boxed中”。
-
思维程序(PoT): 使用零-shot的PoT提示,要求模型创建一个_Solver_函数来解决问题并返回最�终答案。
-
程序合成(PS)提示: 类似于PoT,它提示模型编写一个程序来解决问题。使用的提示是:“编写一个程序来回答以下问题:{Problem}”。
实验结果
不同方法在MATH数据集的不同类别中,难度为5级的所有问题上的准确率如下所示:
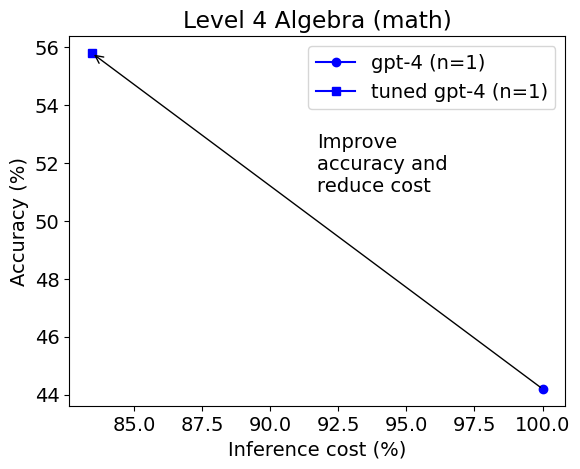
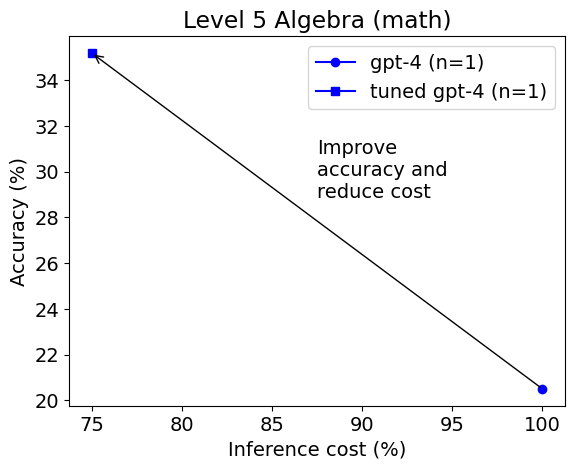
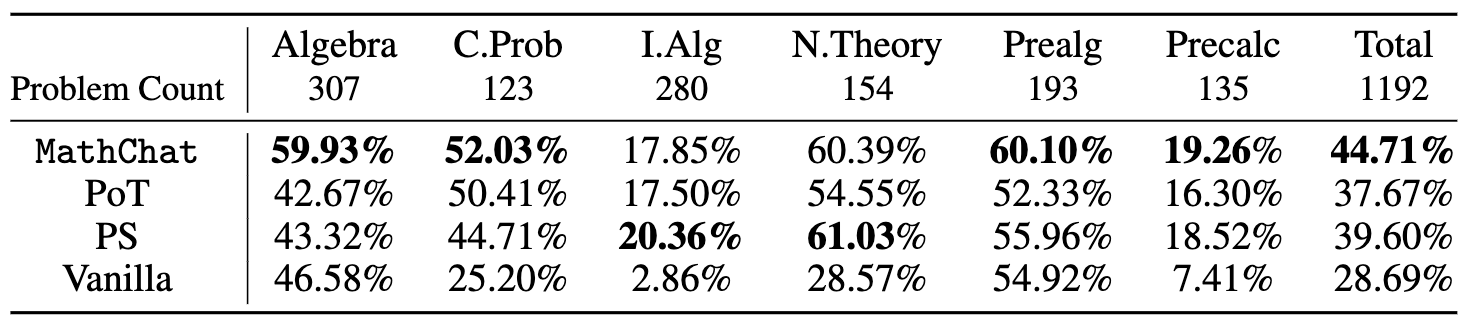 我们发现,与基本提示相比,使用Python在PoT或PS策略的背景下,可以将GPT-4的整体准确性提高约10%。这种增加主要出现在涉及更多数值操作的类别中,例如计数与概率、数论,以及更复杂的类别,如中级代数和预微积分。
我们发现,与基本提示相比,使用Python在PoT或PS策略的背景下,可以将GPT-4的整体准确性提高约10%。这种增加主要出现在涉及更多数值操作的类别中,例如计数与概率、数论,以及更复杂的类别,如中级代数和预微积分。
对于代数和初代数等类别,PoT和PS的改进很小,甚至在某些情况下,准确性还会下降。然而,与PoT和PS相比,MathChat能够将总体准确性提高约6%,在所有类别中表现出竞争力。值得注意的是,MathChat在代数类别中的准确性比其他方法提高了约15%。需要注意的是,中级代数和预微积分等类别对所有方法来说仍然具有挑战性,只有约20%的问题能够准确解决。
实验代码可以在这个仓库中找到。我们现在提供了使用AutoGen中的交互式代理实现的MathChat。请参考这个notebook了解示例用法。
未来的方向
尽管MathChat相对于以前的方法有所改进,但结果显示,对于最近强大的LLM(如GPT-4)来说,复杂的数学问题仍然具有挑战性,即使在外部工具的帮助下也是如此。
可以进行进一步的工作来改进这个框架或数学问题的解决方法:
- 尽管使模型能够使用Python等工具可以减少计算错误,但LLM仍然容易出现逻辑错误。采用自一致性(对最终答案进行多次采样并进行多数投票)或自验证(使用另一个LLM实例来检查答案是否正确)等方法可能会提高性能。
- 有时,LLM能否解决问题取决于它使用的计划。某些计划需要较少的计算和逻辑推理,从而减少了错误的可能性。
- MathChat有潜力成为一个协作系统,可以帮助用户解决数学问题。这个系统可以让用户更多地参与到解决问题的过程中,从而可能提高学习效果。
进一步阅读
您是否正在开发涉及数学问题解决的应用程序?您是否希望在LLM为基础的代理在数学问题解决中的应用方面获得更多的研究或支持?请加入我们的Discord服务器进行讨论。