TL;DR: 介绍一种新的类 AgentOptimizer,用于在 LLM 作为服务的时代训练 LLM agents。 AgentOptimizer 能够根据历史对话和表现,提示 LLMs 迭代优化 AutoGen agents 的功能/技能。
更多信息请参考:
论文: https://arxiv.org/abs/2402.11359.
Notebook: https://github.com/microsoft/autogen/blob/main/notebook/agentchat_agentoptimizer.ipynb.
引��言
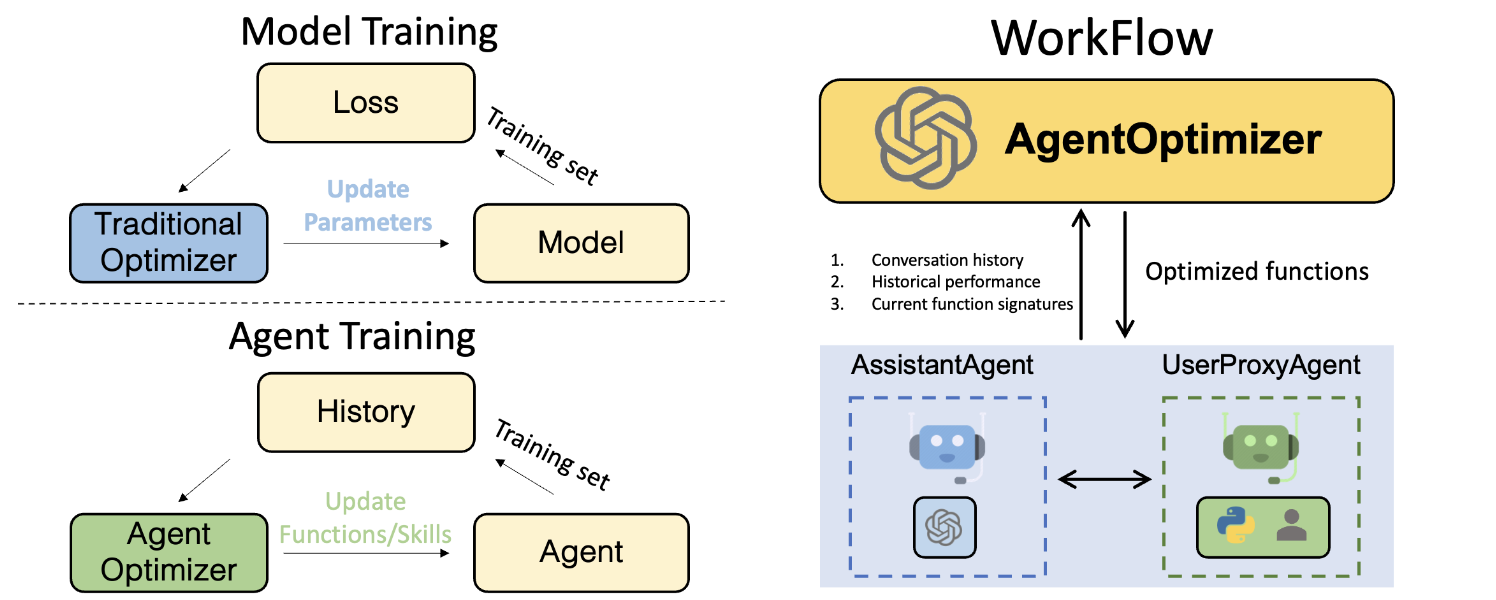
在传统的机器学习流程中,我们通过更新模型在训练集上的损失来训练模型,而在 LLM agents 时代,我们应该如何训练一个 agent 呢? 在这里,我们迈出了训练 agent 的第一步。受到 OpenAI 提供的 function calling 功能的启发, 我们将模型的权重与 agent 的功能/技能进行类比,并根据 agent 在训练集上的历史表现来更新其功能/技能。 具体来说,我们提出使用 function calling 功能来将优化 agent 功能的操作表示为一组函数调用,以支持迭代地添加、修改和删除现有的函数。 我们还包括了回滚和提前停止两种策略,以简化训练过程,克服训练时性能下降的问题。 作为一种主动训练 agent 的方式,我们的方法有助于增强 agent 的能力,而无需访问 LLM 的权重。
AgentOptimizer
AgentOptimizer 是一个用于优化 agent 的类,通过改进其函数调用来提升其性能。 它包含三个主要方法:
record_one_conversation:
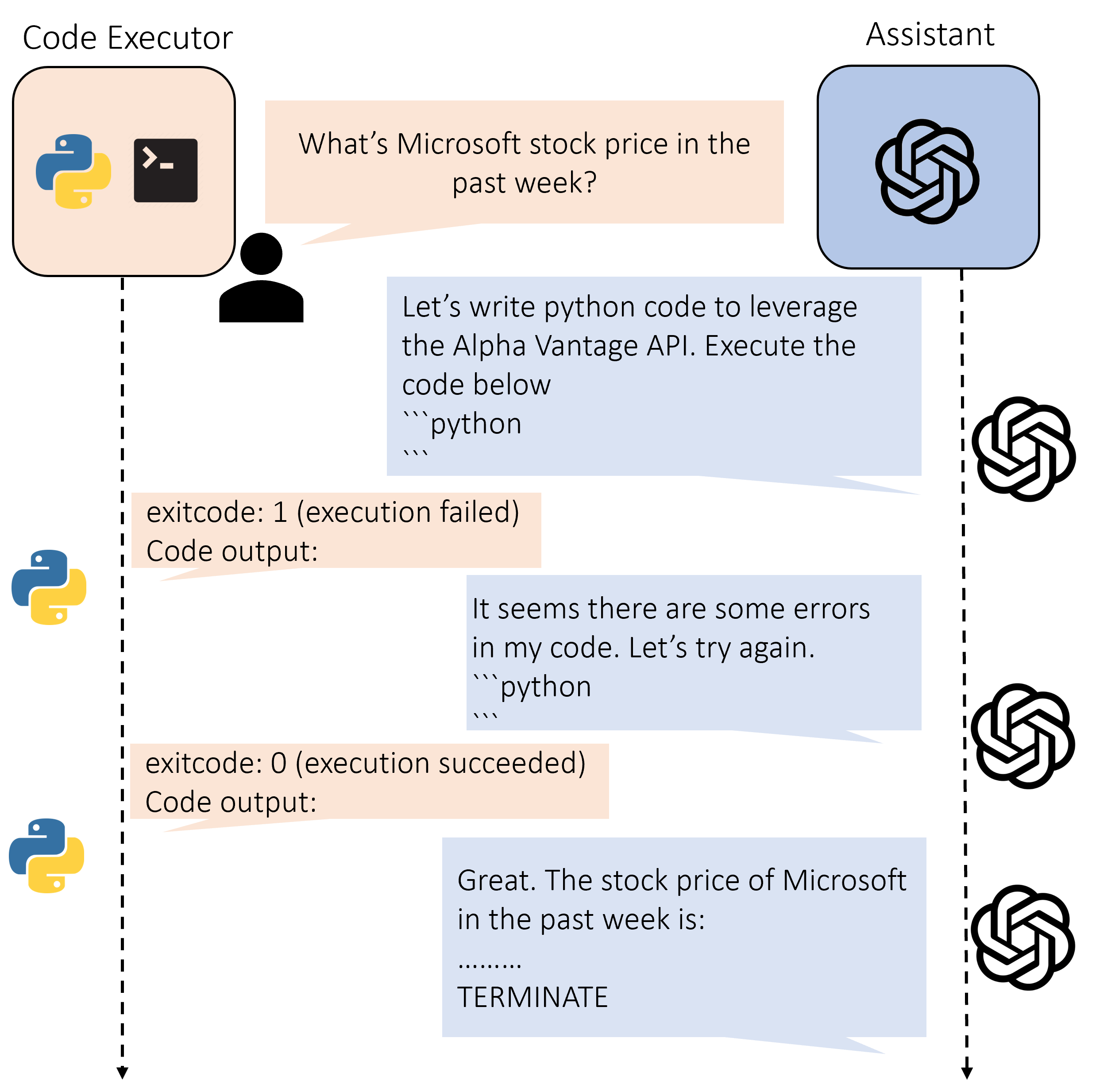
该方法记录 agent 在解决一个问题时的对话历史和表现。 它包括两个输入参数:conversation_history (List[Dict]) 和 is_satisfied (bool)。 conversation_history 是一个字典列表,可以从 AgentChat 类的 chat_messages_for_summary 方法中获取。 is_satisfied 是一个布尔值,表示用户是否对解决方案感到满意。如果为 None,则会要求用户输入满意度。
示例:
optimizer = AgentOptimizer(max_actions_per_step=3, llm_config = llm_config)
# ------------ 解决一个问题的代码 ------------
# ......
# -------------------------------------------------
history = assistant.chat_messages_for_summary(UserProxy)
optimizer.record_one_conversation(history, is_satisfied=result)
step():
step() 是 AgentOptimizer 的核心方法。
在每次优化迭代中,它将返回两个字段register_for_llm和register_for_executor,随后用于更新assistant和UserProxy代理。
register_for_llm, register_for_exector = optimizer.step()
for item in register_for_llm:
assistant.update_function_signature(**item)
if len(register_for_exector.keys()) > 0:
user_proxy.register_function(function_map=register_for_exector)
reset_optimizer:
这个方法将优��化器重置为初始状态,当你想从头开始训练代理时非常有用。
AgentOptimizer包括在返回register_for_llm和register_for_exector之前检查(1)函数的有效性和(2)代码实现的机制。 此外,它还包括检查每个更新是否可行的机制,例如避免由于幻觉而删除当前函数中不存在的函数。
优化过程的伪代码
优化过程如下所示:
optimizer = AgentOptimizer(max_actions_per_step=3, llm_config = llm_config)
for i in range(EPOCH):
is_correct = user_proxy.initiate_chat(assistant, message = problem)
history = assistant.chat_messages_for_summary(user_proxy)
optimizer.record_one_conversation(history, is_satisfied=is_correct)
register_for_llm, register_for_exector = optimizer.step()
for item in register_for_llm:
assistant.update_function_signature(**item)
if len(register_for_exector.keys()) > 0:
user_proxy.register_function(function_map=register_for_exector)
给定一个准备好的训练数据集,代理们迭代地解决训练集中的问题,以获取对话历史和统计信息。 然后使用AgentOptimizer改进函数。每次迭代可以看作是一次训练步骤,类似于传统的机器学习,其中优化元素是代理所拥有的函数。 经过EPOCH次迭代,代理预计将获得更好的函数,这些函数可能在未来的任务中使用。
AgentOptimizer背后的实现技术
为了从AgentOptimizer中获得稳定和结构化的函数签名和代码实现,
我们利用OpenAI提供的函数调用能力,将操作函数的动作表示为一组函数调用。
具体而言,我们引入了三个函数调用来在每个步骤中操作当前函数:add_function、remove_function和revise_function。
这些调用分别在现有函数列表中添加、删除和修改函数。
这种做法可以充分利用GPT-4的函数调用能力,并输出具有更稳定签名和代码实现的结构化函数。
下面是这些函数调用的JSON模式:
add_function:添加一个可能在未来任务中使用的新函数。
ADD_FUNC = {
"type": "function",
"function": {
"name": "add_function",
"description": "在对话的上下文中添加一个函数。必须声明所需的 Python 包。函数的名称必须与您生成的代码中的函数名称相同。",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "代码实现中函数的名称。"},
"description": {"type": "string", "description": "函数的简短描述。"},
"arguments": {
"type": "string",
"description": '以字符串形式编码的参数的 JSON 模式。请注意,JSON 模式仅支持特定类型,包括字符串、整数、对象、数组、布尔值(不支持浮点数类型)。例如:{ "url": { "type": "string", "description": "URL" }}。在使用数组类型时,请避免出现错误 "array schema missing items"。',
},
"packages": {
"type": "string",
"description": "函数导入的包名称列表,需要在调用函数之前使用 pip 安装。这解决了 ModuleNotFoundError。它应该是字符串,而不是列表。",
},
"code": {
"type": "string",
"description": "Python 中的实现。不要包含函数声明。",
},
},
"required": ["name", "description", "arguments", "packages", "code"],
},
},
}
revise_function: 根据对话历史和性能,修改当前函数列表中的一个现有函数(代码实现,函数签名)。
REVISE_FUNC = {
"type": "function",
"function": {
"name": "revise_function",
"description": "在对话的上下文中修改函数。必须声明必要的Python包。函数的名称必须与您生成的代码中的函数名称相同。",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "代码实现中函数的名称。"},
"description": {"type": "string", "description": "函数的简短描述。"},
"arguments": {
"type": "string",
"description": '以字符串形式编码的参数的JSON模式。请注意,JSON模式仅支持特定类型,包��括字符串、整数、对象、数组、布尔值(不支持浮点类型)。例如:{ "url": { "type": "string", "description": "URL" }}。在使用数组类型时,请避免出现错误\'array schema missing items\'。',
},
"packages": {
"type": "string",
"description": "函数导入的包名称列表,需要在调用函数之前使用pip安装。��这解决了ModuleNotFoundError。它应该是字符串,而不是列表。",
},
"code": {
"type": "string",
"description": "Python中的实现。不要包含函数声明。",
},
},
"required": ["name", "description", "arguments", "packages", "code"],
},
},
}
remove_function: 从当前函数列表中删除一个现有函数。用于删除未来任务中不需要的函数(冗余函数)。
REMOVE_FUNC = {
"type": "function",
"function": {
"name": "remove_function",
"description": "在对话的上下文中删除一个函数。一旦删除一个函数,助手将不会在未来的对话中使用该函数。",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "代码实现中函数的名称。"}
},
"required": ["name"],
},
},
}
限制和未来工作
- 目前,它仅支持优化一个典型的用户代理和助手代理对。我们将在未来的工作中使此功能更通用,以支持其他代理类型。
- AgentOptimizer的当前实现仅对OpenAI GPT-4模型有效。将此功能/概念扩展到其他LLM是下一步。