有限状态机(FSM)群聊允许用户约束代理转换。
TL;DR
最近发布了 FSM Group Chat,允许用户输入转换图来约束代理转换。随着代理数量的增加,这非常有用,因为转换对的数量(N 选 2 组合)呈指数级增长,增加了次优转换的风险,从而导致代币的浪费和/或结果不佳。
转换图的可能用例
- 单次工作流程,即我们希望每个代理只对问题进行一次处理,代理 A -> B -> C。
- 决策树流程,类似于决策树,我们从根节点(代理)开始,通过代理节点向下流动。例如,如果查询是 SQL 查询,则交给 SQL 代理,否则如果查询是 RAG 查询,则交给 RAG 代理。
- 顺序团队操作。假设我们有一个由 3 个开发人员代理组成的团队,每个人负责不同的 GitHub 仓库。我们还有一个由业务分析师组成的团队,讨论和辩论用户的整体目标。我们可以让开发团队的经理代理与业务分析团队的经理代理交谈。这样,讨论更加专注于团队,可以期望获得更好的结果。
请注意,我们不强制要求有向无环图;用户可以指定图为无环的,但循环工作流也可以用于迭代地解决问题,并在解决方案上添加额外的分析。
使用指南
我们添加了两个参数 allowed_or_disallowed_speaker_transitions 和 speaker_transitions_type。
allowed_or_disallowed_speaker_transitions:是一个期望类型为{Agent: [Agent]}的字典。键表示源代理,列表中的值表示目标代理。如果没有指定,则假定为完全连接图。speaker_transitions_type:是一个期望类型为字符串的字符串,具体而言,是 ["allowed", "disallowed"] 中的一个。我们希望用户能够提供一个允许或禁止的转换字典,以提高使用的便利性。在代码库中,我们会将禁止的转换反转为允许的转换字典allowed_speaker_transitions_dict。
FSM 功能的应用
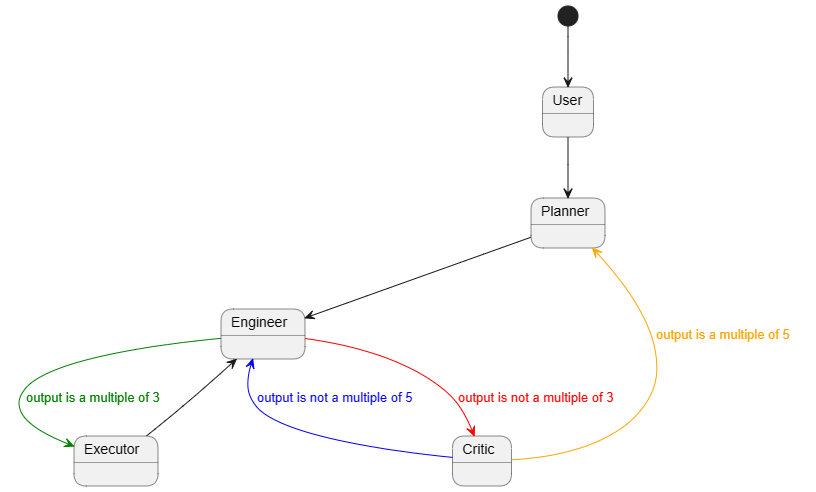
在 AutoGen 框架中,我们来快速演示如何启动基于有限状态机(FSM)的 GroupChat。在这个演示中,我们将每个代理都视为一个状态,并且每个代理根据特定条件发言。例如,用户始终首先发起任务,然后规划者创建计划。接下来,工程师和执行者交替工作,评论者在必要时进行干预,评论者之后只有规划者才能修改额外的计划。每个状态一次只能存在一个,并且状态之间存在转换条件。因此,GroupChat 可以很好地抽象为一个有限状态机(FSM)。
使用方法
- 准备工作
pip install autogen[graph]
-
导入依赖库
from autogen.agentchat import GroupChat, AssistantAgent, UserProxyAgent, GroupChatManager
from autogen.oai.openai_utils import config_list_from_dotenv -
配置 LLM 参数
# 请根据需要自行更改
config_list = config_list_from_dotenv(
dotenv_file_path='.env',
model_api_key_map={'gpt-4-1106-preview':'OPENAI_API_KEY'},
filter_dict={
"model": {
"gpt-4-1106-preview"
}
}
)
gpt_config = {
"cache_seed": None,
"temperature": 0,
"config_list": config_list,
"timeout": 100,
} -
定义任务
# 描述任务
task = """在上一角色输出的数字上加1。如果上一个数字是20,则输出"TERMINATE"。""" -
定义代理
# 代理配置
engineer = AssistantAgent(
name="Engineer",
llm_config=gpt_config,
system_message=task,
description="""我**只能**在 `Planner`、`Critic` 和 `Executor` 之后**立即**发言。
如果 `Critic` 提到的最后一个数字不是5的倍数,则下一个发言者必须是 `Engineer`。
"""
)
planner = AssistantAgent(
name="Planner",
system_message=task,
llm_config=gpt_config,
description="""我**只能**在 `User` 或 `Critic` 之后**立即**发言。
如果 `Critic` 提到的最后一个数字是5的倍数,则下一个发言者必须是 `Planner`。
"""
)
executor = AssistantAgent(
name="Executor",
system_message=task,
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("FINISH"),
llm_config=gpt_config,
description="""我**只能**在 `Engineer` 之后**立即**发言。
如果 `Engineer` 提到的最后一个数字是3的倍数,则下一个发言者只能是 `Executor`。
"""
)
critic = AssistantAgent(
name="Critic",
system_message=task,
llm_config=gpt_config,
5
-
在这个例子中,我们创建了一个多代理的聊天系统。每个代理都有特定的角色和限制条件。
-
User代理是一个特殊的代理,它不能作为发言者。 -
Planner代理在User之后发言,然后是Engineer代理。 -
Engineer代理在Planner之后发言,然后可以是Critic或Executor代理。 -
Critic代理在Engineer之后发言,然后又回到Engineer或Planner代理。 -
Executor代理在Engineer之后发言。 -
这些限制条件和代理之间的关系构成了一个有向图,代表了聊天系统中的状态转换。
-
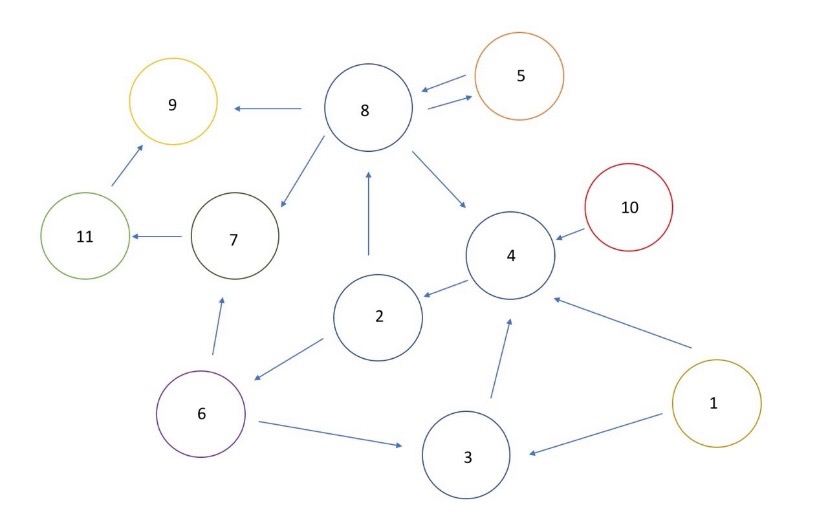
定义图表
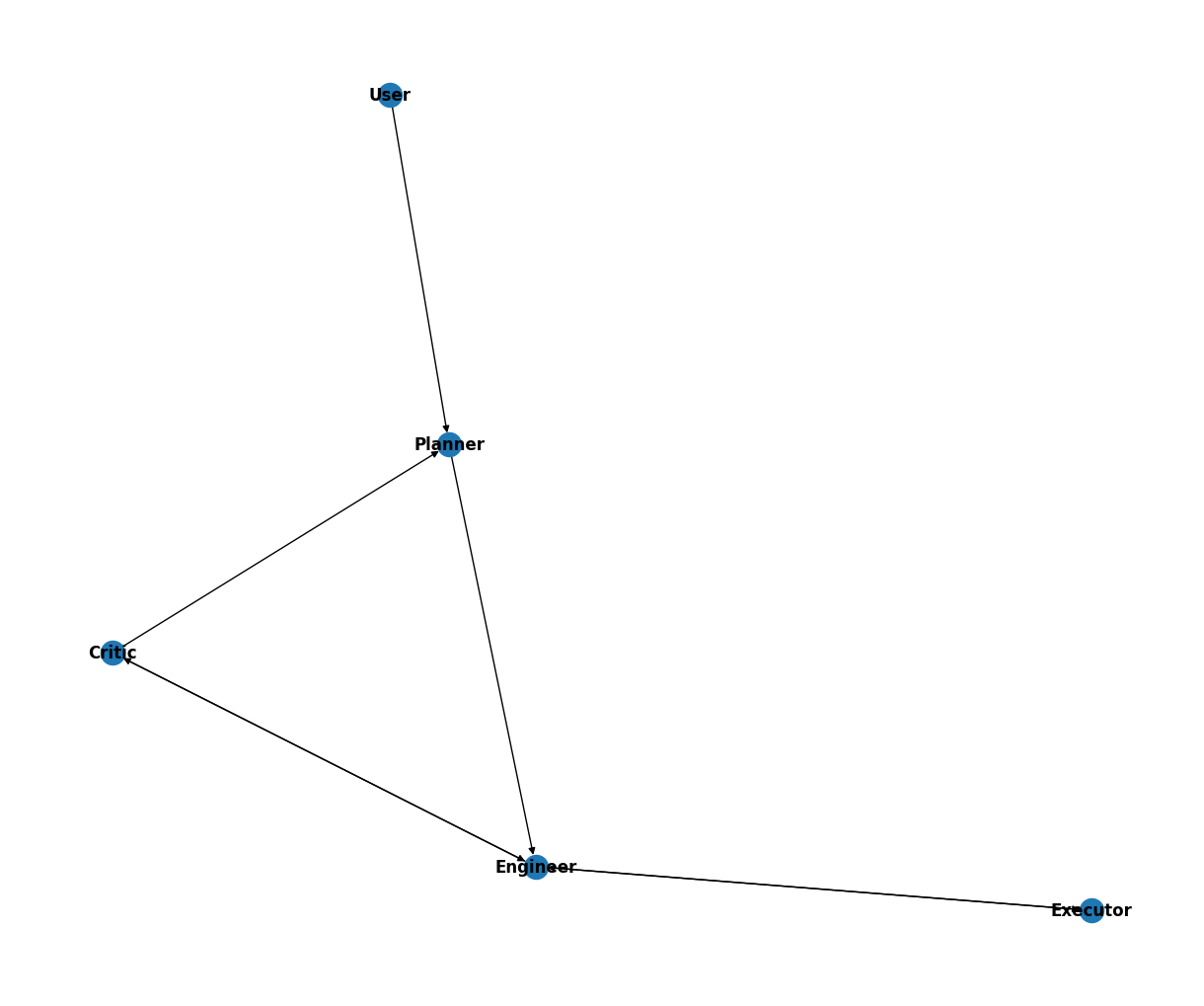
graph_dict = {}
graph_dict[user_proxy] = [planner]
graph_dict[planner] = [engineer]
graph_dict[engineer] = [critic, executor]
graph_dict[critic] = [engineer, planner]
graph_dict[executor] = [engineer]- 这个图表和上面提到的转换条件一起构成了一个完整的有限状态机(FSM)。两者都是必不可少的。
- 您可以根据需要进行可视化,如下所示:
-
定义一个
GroupChat和一个GroupChatManageragents = [user_proxy, engineer, planner, executor, critic]
# 创建群聊
group_chat = GroupChat(agents=agents, messages=[], max_round=25, allowed_or_disallowed_speaker_transitions=graph_dict, allow_repeat_speaker=None, speaker_transitions_type="allowed")
# 创建管理器
manager = GroupChatManager(
groupchat=group_chat,
llm_config=gpt_config,
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config=False,
) -
开始聊天
# 初始化任务
user_proxy.initiate_chat(
manager,
message="1",
clear_history=True
) -
您可能会得到以下输出(我删除了可以忽略的警告):
1
--------------------------------------------------------------------------------
2
--------------------------------------------------------------------------------
3
--------------------------------------------------------------------------------
4
--------------------------------------------------------------------------------
```python
5
5
评论家(对话管理器):
6
工程师(对话管理器):
7
评论家(对话管理器):
8
工程师(对话管理器):
9
执行者(对话管理器):
10
工程师(对话管理器):
11
评论家(对话管理器):
12
工程师(对话管理器):
13
评论家(对话管理器):
14
工程师(对话管理器):
15
执行者(对话管理器):
16
工程师(对话管理器):
17
评论家(对话管理器):
18
工程师(对话管理器):
19
评论家(对话管理器):
20
规划者(对话管理器):
终止
笔记本示例
更多示例可以在notebook中找到。该笔记本包含了更多可能的转换路径示例,例�如(1)中心和辐射,(2)顺序团队操作,以及(3)大声思考和辩论。它还使用了autogen.graph_utils中的visualize_speaker_transitions_dict函数来可视化各种图形。