部分GPU
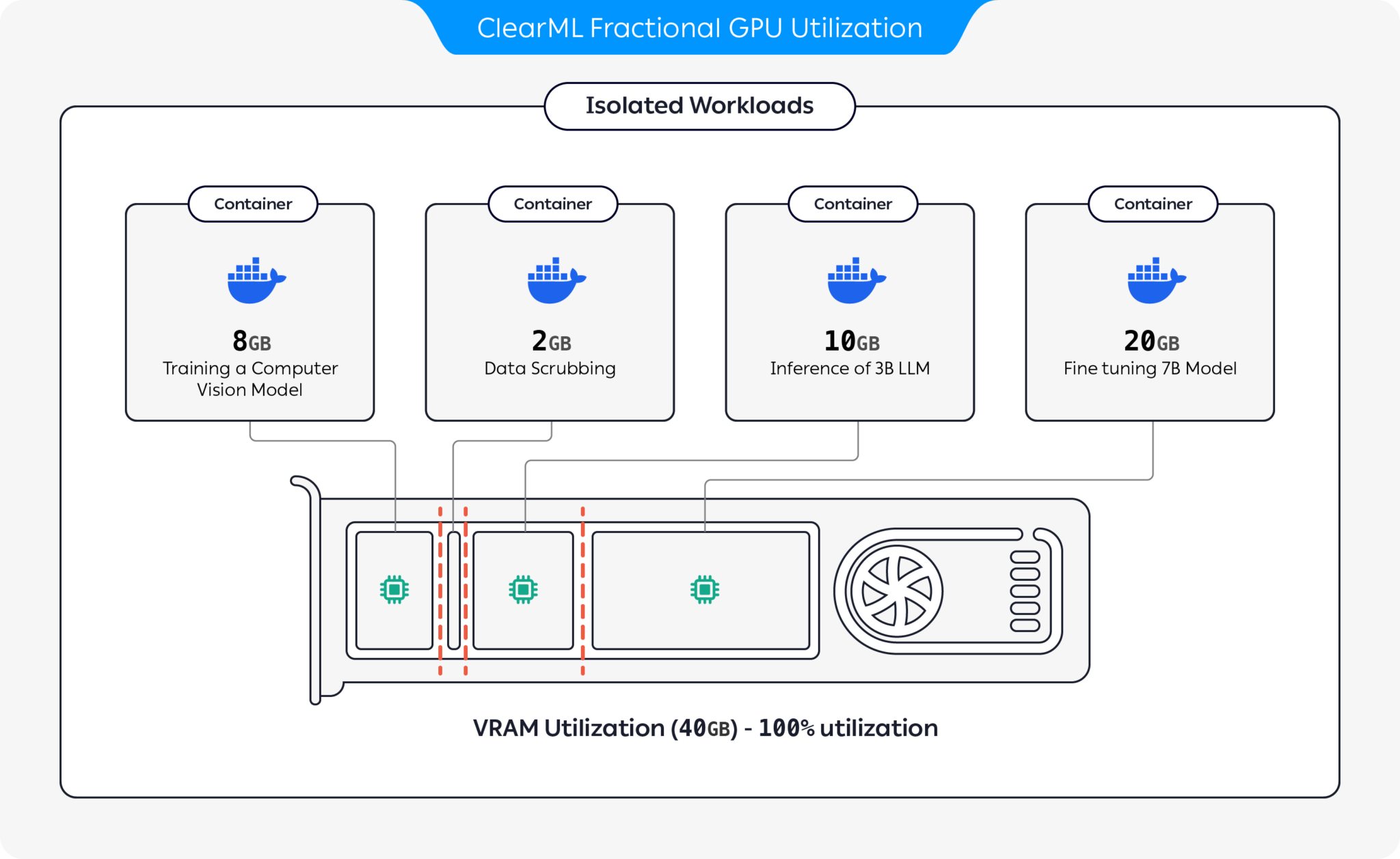
您发送执行的一些任务需要最少的计算和内存,但您最终为它们分配了整个GPU。为了优化您的计算资源使用,您可以将GPU分割成多个切片。您可以让一个GPU设备在单独的切片上运行多个隔离的工作负载,这些工作负载不会相互影响,并且只会使用分配给它们的GPU内存的一部分。
ClearML 提供了多种 GPU 切片选项以优化计算资源利用率:
- 动态GPU切片: 为每个任务按需提供GPU切片,适用于MIG和非MIG设备(仅在ClearML企业计划中可用):
- 基于容器的内存限制: 使用内置内存限制的预打包容器在同一GPU上运行多个容器(作为ClearML开源产品的一部分提供)
- 基于Kubernetes的静态MIG切片: 设置Kubernetes支持NVIDIA MIG(多实例GPU),为特定工作负载定义GPU部分(作为ClearML开源产品的一部分提供)
动态GPU分数
动态GPU切片在ClearML企业计划下可用。
ClearML 动态 GPU 分配提供了即时的、按任务的 GPU 切片功能,无需设置容器或预先配置任务的内存限制。在代理调用中为队列指定一个 GPU 分配比例,代理从队列中拉取的每个任务都将在具有指定限制的容器上运行。这样,您可以安全地同时运行多个任务,而不用担心一个任务会占用所有 GPU 的内存。
您可以在裸金属或Kubernetes上动态切片GPU,适用于支持MIG和不支持MIG的设备。
裸机部署
-
安装所需的包:
pip install clearml-agent clearml-agent-fractional-gpu -
启动具有动态GPU分配的ClearML代理。使用
--gpus来指定活动的GPU,并使用--queue标志来指定队列名称和分配给它们的GPU数量(或比例)。clearml-agent daemon --dynamic-gpus --gpus 0, 1 --queue half_gpu=0.5 --docker
代理可以使用2个GPU(GPU 0和1)。每个排入half_gpu队列的任务将由代理运行,并且只分配50%的GPU内存(即可以同时运行4个任务)。
您可以通过指定单个GPU的一小部分(增量最小为0.125,例如0.125、0.25、0.50等)或整个GPU(例如1、2、4等)来为队列的任务分配GPU。但是,您不能指定大于一个GPU的分数(例如1.25)。
您可以设置多个队列,每个队列为每个任务分配不同数量的GPU。请注意,队列列出的顺序是它们的优先级顺序,因此代理将首先服务列出的第一个队列中的任务,然后再服务后续队列:
clearml-agent daemon --dynamic-gpus --gpus 0-2 --queue dual_gpus=2 quarter_gpu=0.25 half_gpu=0.5 single_gpu=1 --docker
此代理将利用3个GPU(GPU 0、1和2)。代理可以根据配置到队列的GPU数量从不同的队列中启动多个作业。
示例工作流程
假设有四个任务被排队,每个任务对应上述队列中的一个(dual_gpus、quarter_gpu、half_gpu、single_gpu)。代理将首先从dual_gpus队列中拉取任务,因为它列在第一位,并将使用2个GPU运行它。接下来,它将运行来自quarter_gpu和half_gpu的任务——这两个任务都将在剩余的可用GPU上运行。这将留下single_gpu队列中的任务。目前,3个GPU中有2.75个正在使用,因此只有当有足够的GPU可用时,该任务才会被拉取并运行。
Kubernetes 部署
ClearML 通过定制的企业版 Helm Charts 支持在 Kubernetes 上使用部分 GPU,适用于 MIG 和非 MIG 设备:
对于任一设置,您可以在企业ClearML Agent Helm图表中设置发送到每个队列的任务的资源需求。当任务在ClearML中排队时,它会转换为在指定设备上运行的Kubernetes pod,并使用Agent Helm图表中定义的指定部分资源。
支持MIG的GPU
ClearML 动态 MIG 操作符 (CDMO) 图表通过在 K8s 上运行 AI 工作负载,通过促进 MIG GPU 分区来优化硬件利用率和工作负载性能。请确保您拥有一个支持 MIG 的 GPU。
准备集群
-
helm repo add nvidia https://helm.ngc.nvidia.com
helm repo update
helm install -n gpu-operator \
gpu-operator \
nvidia/gpu-operator \
--create-namespace \
--set migManager.enabled=false \
--set mig.strategy=mixed -
启用MIG支持:
-
通过在用于训练的所有节点上运行以下命令来启用集群上的动态MIG支持(为集群中的每个GPU ID运行):
nvidia-smi -i <gpu_id> -mig 1 -
如果需要,重启节点。
-
为所有用于训练的节点添加以下标签:
kubectl label nodes <node-name> "cdmo.clear.ml/gpu-partitioning=mig"
-
配置 ClearML 队列
ClearML 企业版计划支持 K8S 服务多个 ClearML 队列,并为每个队列提供 pod 模板,用于描述每个 pod 使用的资源。
在values.yaml文件中,设置每个ClearML队列的资源需求。例如,以下配置了default025和default050队列要使用的资源:
agentk8sglue:
queues:
default025:
templateOverrides:
labels:
required-resources: "0.25"
resources:
limits:
nvidia.com/mig-1g.10gb: 1
default050:
templateOverrides:
labels:
required-resources: "0.50"
resources:
limits:
nvidia.com/mig-1g.10gb: 1
非MIG设备
Fractional GPU Injector 图表使得在 k8s 上以优化的方式运行 AI 工作负载成为可能,允许您在非 MIG 设备上使用部分 GPU。
需求
通过 Helm 图表安装 Nvidia GPU Operator。确保启用 timeSlicing。
例如:
devicePlugin:
config:
name: device-plugin-config
create: true
default: "any"
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
renameByDefault: false
failRequestsGreaterThanOne: false
resources:
- name: nvidia.com/gpu
replicas: 4
副本数量是GPU上的最大切片数。
配置 ClearML 队列
在values.yaml文件中,设置每个ClearML队列的资源需求。当任务被加入队列时,它会在指定的设备上运行一个Kubernetes pod,并使用指定的资源切片。队列必须配置特定的标签和注释。例如,以下配置将default0500队列设置为使用50%的GPU,并将default0250队列设置为使用25%的GPU:
agentk8sglue:
queues:
default0500:
templateOverrides:
labels:
required-resources: "0.5"
clearml-injector/fraction: "0.500"
resources:
limits:
nvidia.com/gpu: 1
clear.ml/fraction-1: "0.5"
queueSettings:
maxPods: 10
default0250:
templateOverrides:
labels:
required-resources: "0.25"
clearml-injector/fraction: "0.250"
resources:
limits:
nvidia.com/gpu: 1
clear.ml/fraction-1: "0.25"
queueSettings:
maxPods: 10
如果一个pod有一个标签匹配模式clearml-injector/fraction: ",注入器将配置该pod以利用指定的GPU比例:
labels:
clearml-injector/fraction: "<gpu_fraction_value>"
其中
- "0.125"
- "0.250"
- "0.375"
- "0.500"
- "0.625"
- "0.750"
- "0.875"
基于容器的内存限制
使用clearml-fractional-gpu的预打包容器,这些容器内置了硬内存限制。在这些容器中运行的工作负载只能使用到容器的内存限制。多个隔离的工作负载可以在同一个GPU上运行,而不会相互影响。
用法
手动执行
-
选择具有适当内存限制的容器。ClearML 支持 CUDA 11.x 和 CUDA 12.x,内存限制从 2 GB 到 12 GB 不等(完整列表请参见 clearml-fractional-gpu 仓库)。
-
启动容器:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bash此示例在GPU 0上运行带有CUDA 12.3的ClearML Ubuntu 22容器,该容器被限制使用最多8GB的内存。
note--pid=host 是必需的,以便在限制内存使用时允许驱动程序区分容器的进程和其他主机进程
-
在容器内运行以下命令以验证部分GPU内存限制是否正常工作:
nvidia-smi以下是之前8GB限制的示例在A100上的预期输出:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
远程执行
你可以设置一个ClearML代理在部分GPU容器中执行任务。通过命令行设置代理的默认容器。例如,这个代理从default队列中拉取的所有任务将在Ubuntu 22和CUDA 12.3容器中执行,该容器限制使用最多8GB的内存:
clearml-agent daemon --queue default --docker clearml/fractional-gpu:u22-cu12.3-8gb
代理的默认容器可以通过用户界面进行覆盖:
-
克隆任务
-
在克隆任务的执行标签页 > 容器部分设置Docker

-
将克隆的任务加入队列
任务将在用户界面中指定的容器中执行。
欲了解更多信息,请参阅Docker Mode。
Kubernetes上的部分GPU容器
分数GPU容器可用于限制您的Kubernetes作业/ Pod的内存消耗,并允许多个容器共享GPU设备而不会相互干扰。
例如,以下配置使用 clearml/fractional-gpu:u22-cu12.3-8gb 容器运行一个 K8s pod,
该容器将 pod 的 GPU 内存限制为 8 GB:
apiVersion: v1
kind: Pod
metadata:
name: train-pod
labels:
app: trainme
spec:
hostPID: true
containers:
- name: train-container
image: clearml/fractional-gpu:u22-cu12.3-8gb
command: ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")']
hostPID: true 是必需的,以便在限制内存使用时允许驱动程序区分容器的进程和其他主机进程。
自定义容器
通过继承ClearML的一个容器来构建您自己的自定义部分GPU容器:在您的Dockerfile中,确保包含From ,以便容器从相关容器继承。
请参阅clearml-fractional-gpu 仓库中的示例自定义 Dockerfiles。
Kubernetes 静态 MIG 分数
为Kubernetes设置NVIDIA MIG(多实例GPU)支持,通过您的NVIDIA设备插件为特定工作负载定义GPU分数配置文件。
配置Kubernetes pod模板以使用特定MIG切片的标准方法是让模板在Containers.resources.limits下指定请求的GPU切片。例如,以下配置使K8s pod运行一个3g.20gb MIG设备:
# tf-benchmarks-mixed.yaml
apiVersion: v1
kind: Pod
metadata:
name: tf-benchmarks-mixed
spec:
restartPolicy: Never
Containers:
- name: tf-benchmarks-mixed
image: ""
command: []
args: []
resources:
limits:
nvidia.com/mig-3g.20gb: 1
nodeSelector: #optional
nvidia.com/gpu.product: A100-SXM4-40GB
ClearML Agent Helm 图表允许您为每个队列指定一个 pod 模板,该模板描述了 pod 将使用的资源。ClearML Agent 使用此配置生成必要的 Kubernetes pod 模板,以便通过调度它们的队列执行任务。
当任务被添加到相关队列时,代理会拉取任务并使用指定的GPU切片创建一个pod来执行它。
例如,以下配置从默认队列中使用 1g.5gb MIG 切片的任务:
agentk8sglue:
queue: default
# …
basePodTemplate:
# …
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
nvidia.com/gpu.product: A100-SXM4-40GB-MIG-1g.5gb