超数据集
Enterprise Feature
超数据集可在ClearML企业计划下使用。
ClearML的Hyper-Datasets是一种面向MLOps的数据抽象,它通过参数化数据访问和元数据版本控制,促进了可追踪、可复现的模型开发。
Hyper-Datasets 是一个专门为处理非结构化数据(如文本、音频或视觉数据)量身定制的数据管理系统。您可以创建、管理和版本化您的数据集。数据集可以设置为从其他数据集继承,从而可以创建数据谱系,用户可以跟踪数据何时以及如何发生变化。在 ClearML Enterprise 的 WebApp 中,您可以查看数据集的版本历史记录,以及其内容,包括注释、元数据、掩码和其他信息。
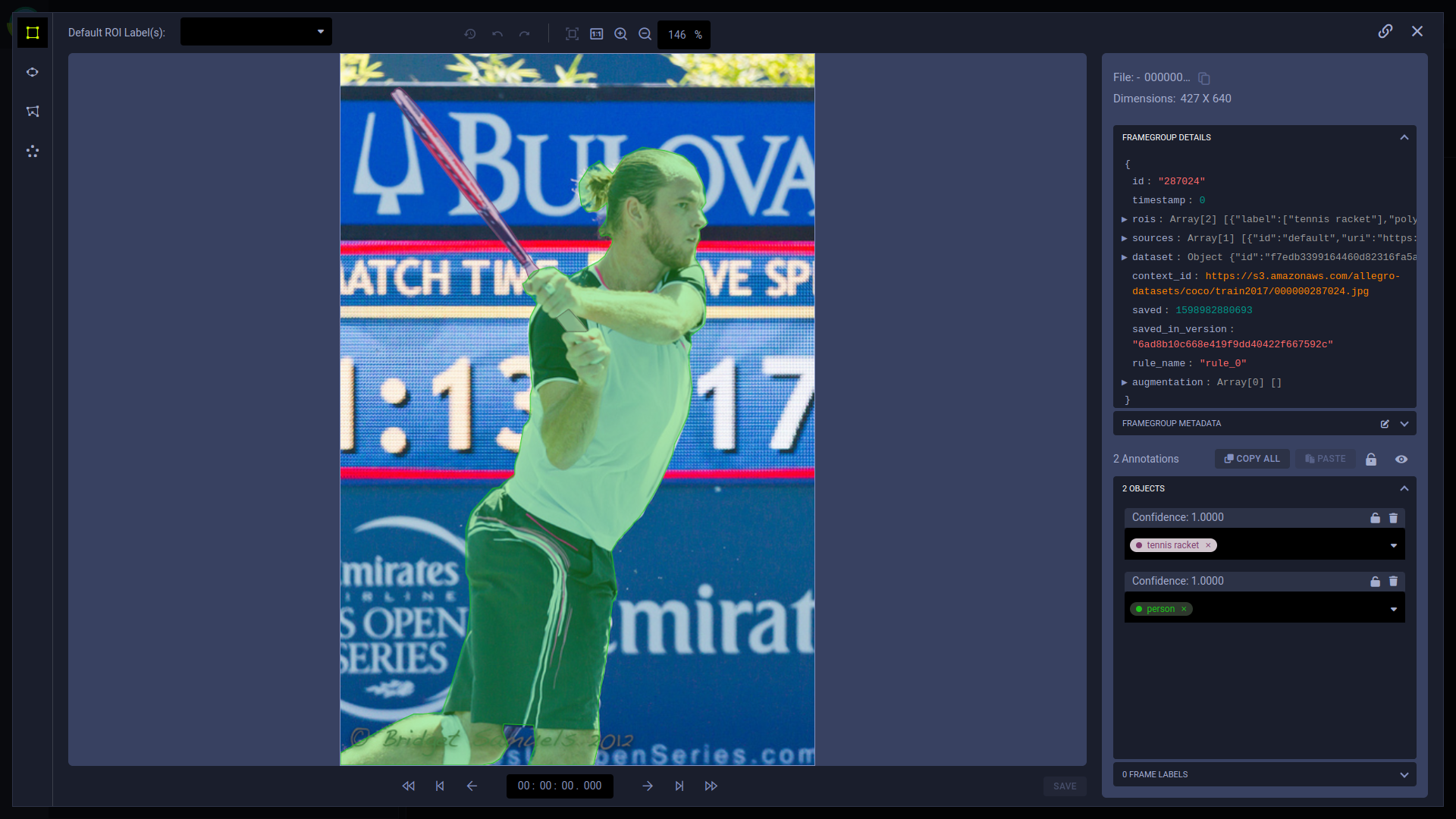
Hyper-Datasets 的基本前提是,用户形成的查询是 ML/DL 过程使用的数据集的完整表示。Hyper-Datasets 将元数据与原始数据文件解耦,允许您通过复杂的查询和参数来操作元数据,这些查询和参数可以通过实验管理器进行跟踪。您可以使用不同的数据操作(或 DataViews)克隆实验,而无需更改任何硬编码值,使这些操作成为实验的一部分。
ClearML Enterprise 的超数据集支持快速原型设计,创造新的机会,例如:
- 超参数优化数据本身
- QA/QC 流水线
- 部署期间的CD/CT(持续培训)
- 启用复杂的应用程序,如协作(联邦)学习。
欲了解更多信息,请参阅Hyper-Datasets。