ClearML 数据
important
本页面涵盖了clearml-data,ClearML的基于文件的数据管理解决方案。
有关ClearML的高级可查询数据集管理解决方案,请参见Hyper-Datasets。
在机器学习中,您很可能会处理大量需要放入数据集的数据,然后您需要能够共享、复制和跟踪这些数据。
ClearML 数据管理解决了两个重要挑战:
- 可访问性 - 使数据能够从每台机器轻松访问,
- 版本控制 - 链接数据和实验以提高可追溯性。
我们相信数据不是代码。它不应该存储在git树中,因为数据集的进展并不总是线性的。 此外,在git树上找到与某个版本的数据集相关的提交可能会很困难且效率低下。
使用ClearML数据来创建、管理和版本化您的数据集。通过设置数据集的上传目的地(参见--storage
CLI选项或output_url参数),将您的文件存储在您选择的任何存储位置
(S3 / GS / Azure / 网络存储)。
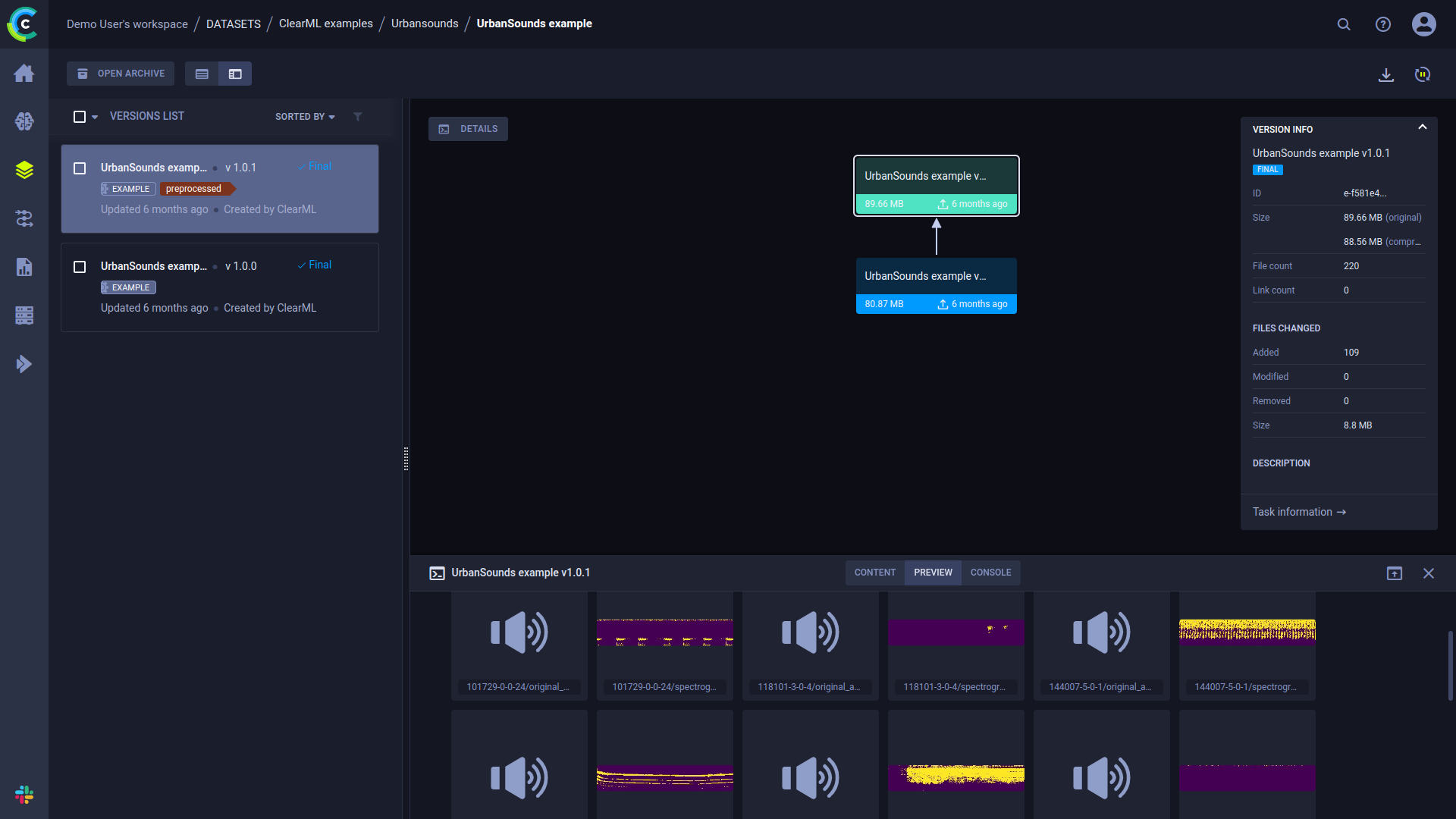
数据集可以设置为从其他数据集继承,因此可以创建数据谱系,用户可以跟踪他们的数据何时以及如何发生变化。数据集的变化使用可区分的存储方式存储,这意味着一个版本将存储其前一个数据集父级的变更集。
您可以在任何机器上获取数据集的本地副本。数据集的本地副本总是被缓存,因此相同的数据不需要下载两次。当拉取数据集时,它会自动拉取所有父数据集并将它们合并到一个输出文件夹中,供您使用。
Web UI中的数据集版本页面显示数据集版本的沿袭和内容信息。有关更多详细信息,请参阅数据集UI。
设置
clearml-data 内置在 clearml python 包中!查看 入门指南 获取更多信息!
使用 ClearML 数据
ClearML 数据支持两种接口:
clearml-data- 一个用于创建、上传和管理数据集的CLI工具。有关clearml-data命令的参考,请参见CLI。clearml.Dataset- 一个用于创建、检索、管理和使用数据集的Python接口。请参阅SDK以了解Dataset模块的基本方法概述。
有关ClearML数据工作流和实践的推荐概述,请参阅最佳实践。
数据集版本状态
下表显示了数据集版本的可能状态。
| State | Description |
|---|---|
| Uploading | Dataset creation is in progress |
| Failed | Dataset creation was terminated with an error |
| Aborted | Dataset creation was aborted by user before it was finalization |
| Final | A dataset was created and finalized successfully |
| Published | The dataset is read-only. Publish a dataset to prevent changes to it |