最佳实践
本页面介绍clearml-data,ClearML基于文件的数据管理解决方案。
有关ClearML的高级可查询数据集管理解决方案,请参见Hyper-Datasets。
以下是使用ClearML Data的一些建议。
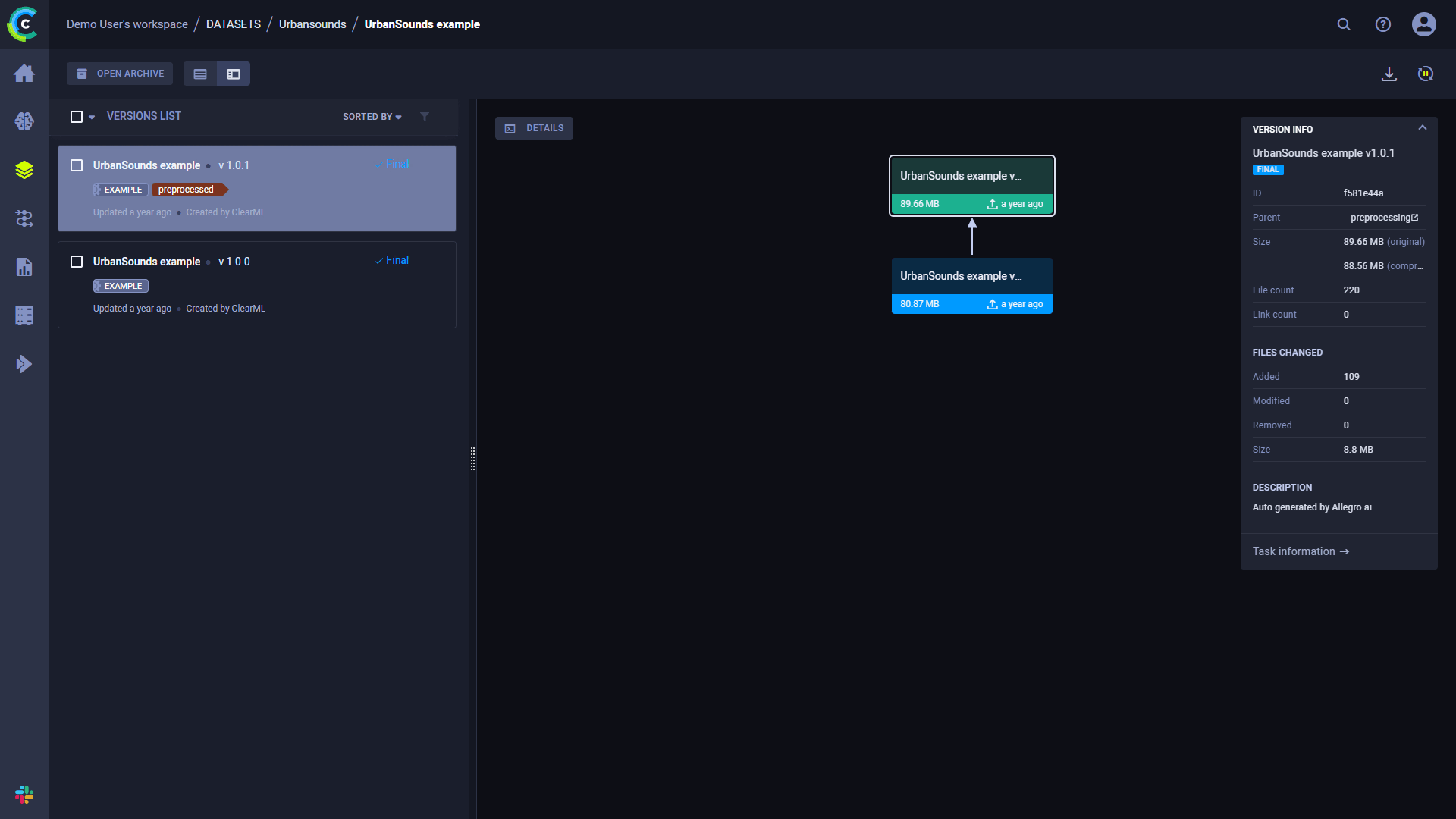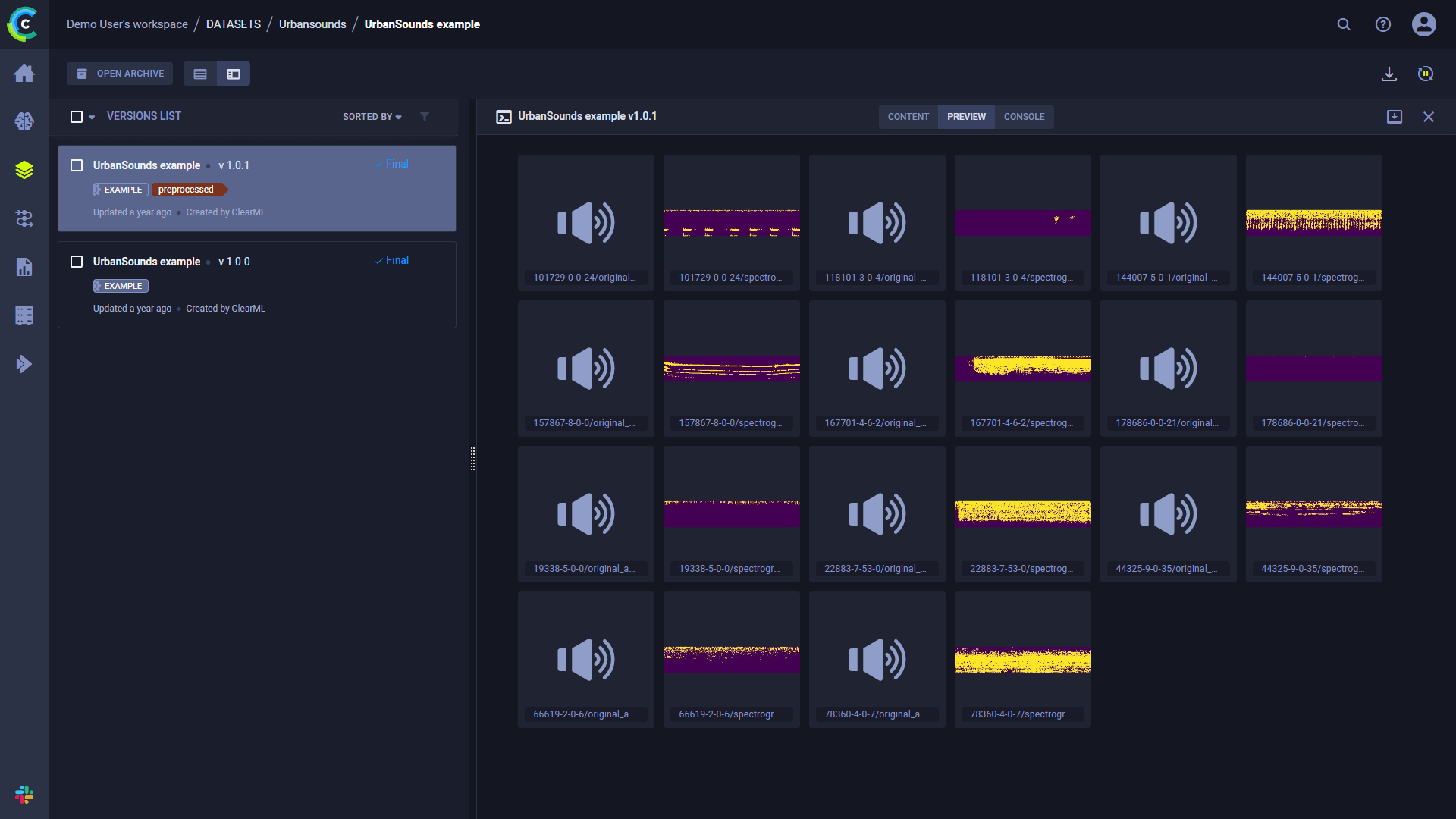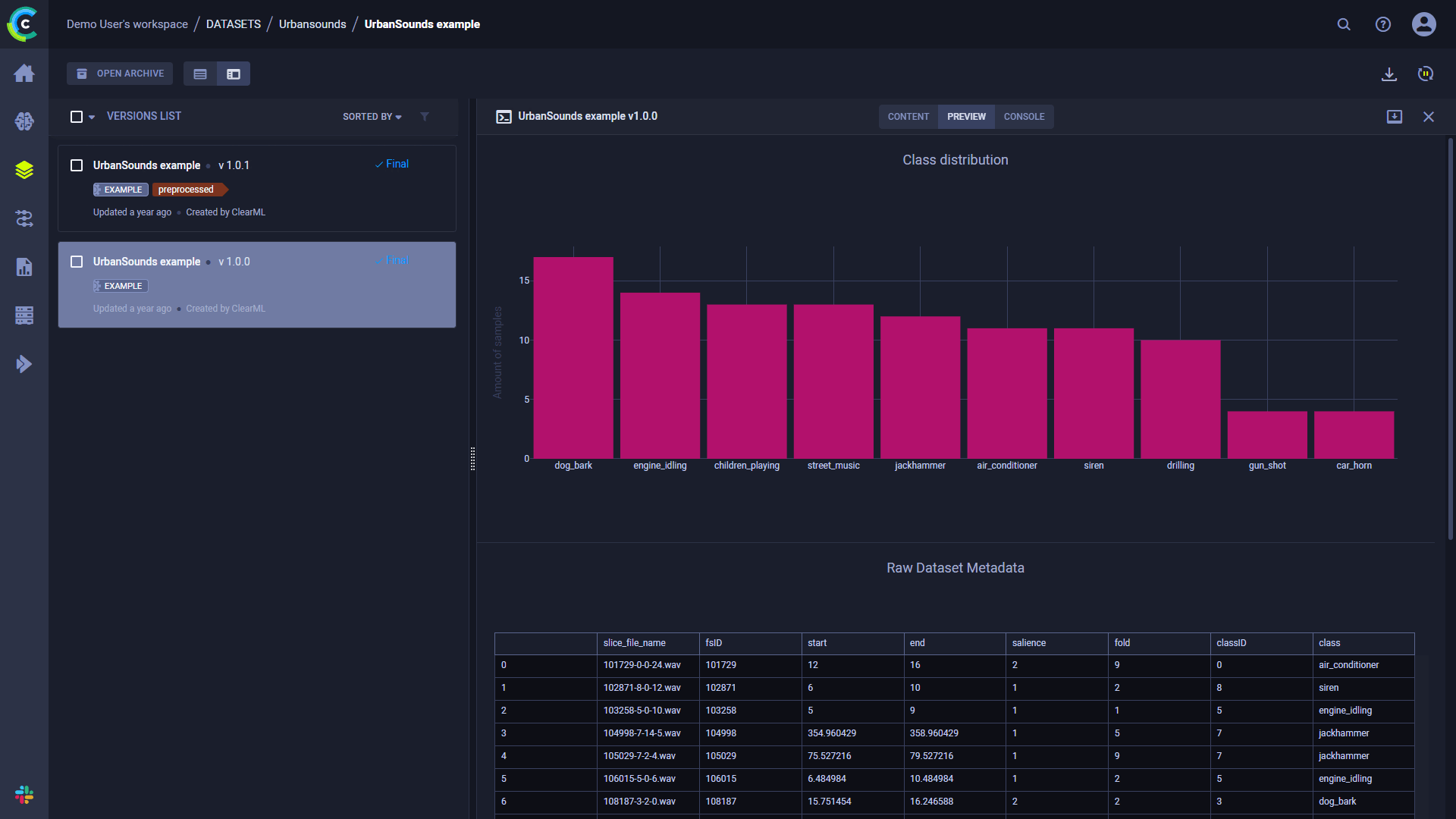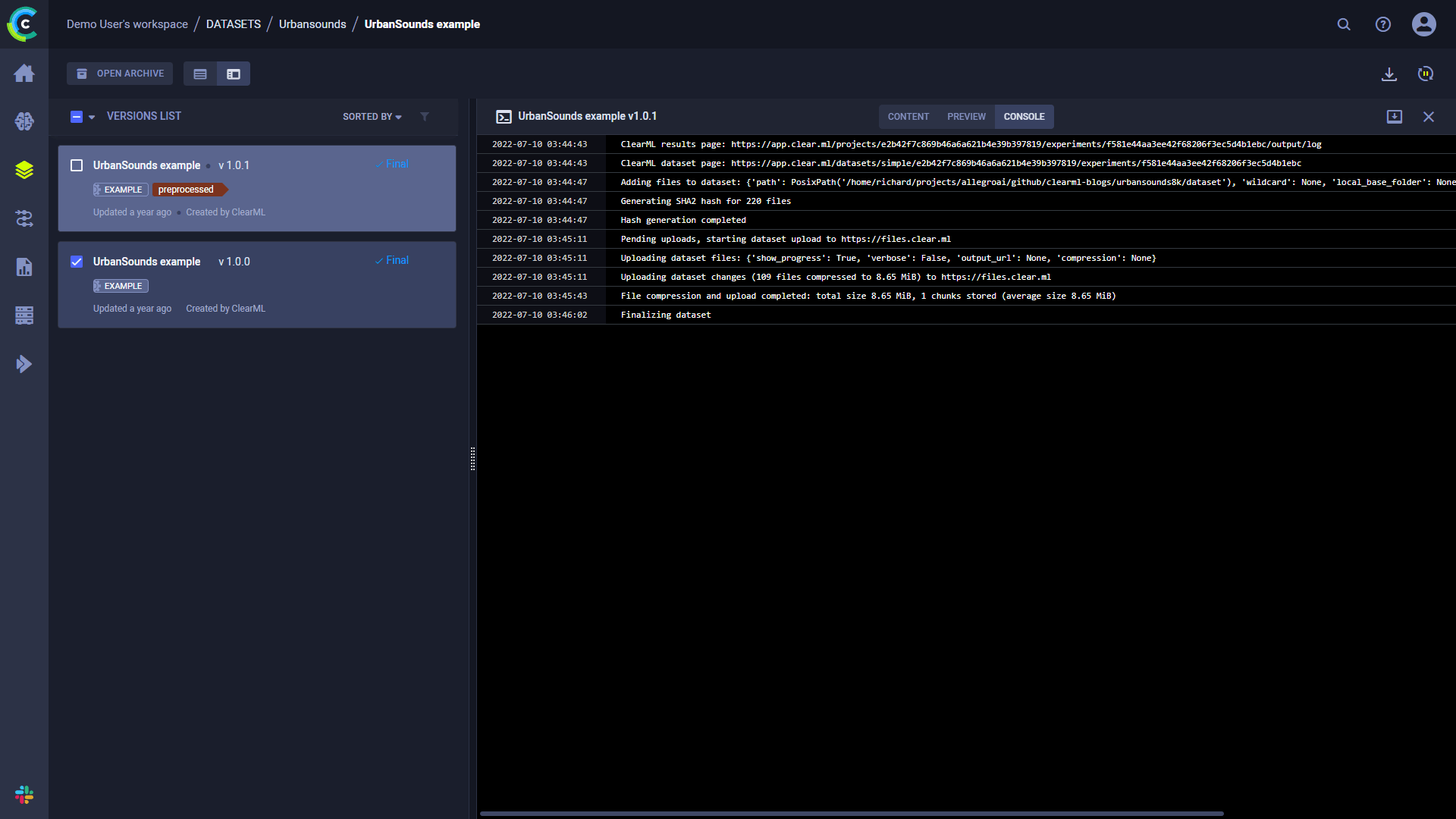
版本控制数据集
使用ClearML Data来版本化您的数据集。一旦数据集被最终确定,就无法再进行修改。这样可以清楚地知道哪个版本的数据集与哪个任务一起使用,从而确保实验的准确复现。
一旦你需要更改数据集的内容,你可以通过指定前一个数据集作为父级来创建数据集的新版本。这使得新数据集版本继承前一个版本的内容,新版本的内容可以随时更新。
组织数据集以便更轻松地访问
根据用例和使用标签组织数据集。这使得管理多个数据集并为不同用例访问最新数据集变得更加容易。
与任何ClearML任务一样,数据集可以组织到项目(和子项目)中。 此外,在创建数据集时,可以为数据集应用标签,这将使搜索数据集变得更加容易。
通过用例将您的数据集组织到项目中,可以更轻松地访问该用例的最新数据集版本。
如果仅在使用Dataset.get()时指定了一个项目,该方法将返回该项目中的最新数据集。标签也是如此;如果指定了标签,该方法将返回标记有该标签的最新数据集。
在任务中使用数据集的情况下(例如消费数据集),您可以通过使用Dataset.get()的alias参数轻松跟踪任务正在使用的数据集。传递alias=,使用数据集的任务将在任务的配置 > 超参数 > 数据集部分下的dataset_alias_string参数中存储数据集的ID。
记录您的数据集
将信息性指标或调试样本附加到数据集本身。使用Dataset.get_logger()访问数据集的日志记录器对象,然后使用Logger对象提供的方法向数据集添加任何附加信息。
您可以添加一些数据集摘要(如表格报告)以创建数据存储的预览,以便更好地查看,或附加数据摄取过程中生成的任何统计信息。
定期更新您的数据集
您的数据可能会不时发生变化。如果数据被更新到同一个本地/网络文件夹结构中,该结构作为数据集的单一真实来源,您可以安排一个脚本,该脚本使用数据集的sync功能,该功能将根据对文件夹所做的修改来更新数据集。这样,就不需要手动修改数据集。此功能还将跟踪对文件夹所做的修改。