使用Python进行数据管理
dataset_creation.py 和
data_ingestion.py 脚本
一起展示了如何使用 ClearML 的 Dataset 类来创建数据集并随后导入数据。
数据集创建
dataset_creation.py 脚本 展示了如何执行以下操作:
- 创建一个数据集并向其中添加文件
- 将数据集上传到ClearML服务器
- Complete dataset
下载数据
首先,您需要获取CIFAR数据集的本地副本。
以下代码下载数据,dataset_path 包含下载数据的路径:
from clearml import StorageManager
manager = StorageManager()
dataset_path = manager.get_local_copy(
remote_url="https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"
)
创建数据集
以下代码在dataset examples项目中创建了一个名为cifar_dataset的数据处理任务,可以在WebApp中查看。
from clearml import Dataset
dataset = Dataset.create(
dataset_name="cifar_dataset",
dataset_project="dataset examples"
)
添加文件
将下载的文件添加到当前数据集中:
dataset.add_files(path=dataset_path)
上传文件
上传数据集:
dataset.upload()
默认情况下,数据集会上传到ClearML文件服务器。可以通过指定upload方法的output_url参数来更改数据集的目标存储位置。
完成数据集
运行finalize命令以关闭数据集并将该数据集的任务状态设置为已完成。只有在没有任何待处理的上传时,数据集才能被最终化。
dataset.finalize()
数据集关闭后,将无法再进行修改。这确保了未来的可重复性。
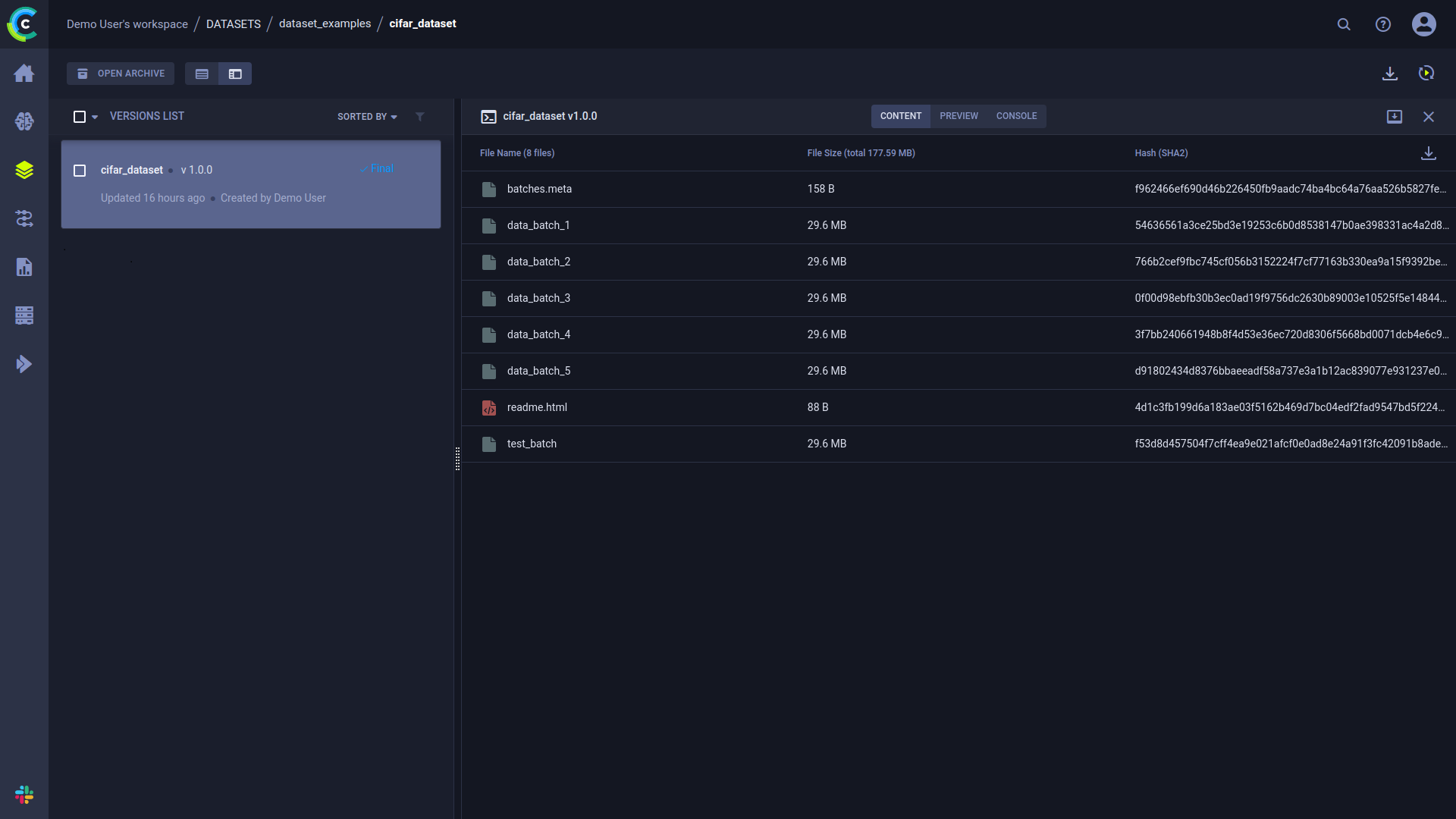
关于数据集的信息可以在WebApp中查看,位于数据集的详细信息面板中。 在面板的内容选项卡中,您可以看到一个汇总版本内容的表格,包括文件名、文件大小和哈希值。
数据摄取
现在新的数据集已经注册,你可以使用它了!
data_ingestion.py 脚本 展示了如何使用第一个脚本中创建的数据集进行数据导入。
以下脚本获取数据集并使用 Dataset.get_local_copy() 返回缓存只读本地数据集的路径。
dataset_name = "cifar_dataset"
dataset_project = "dataset_examples"
dataset_path = Dataset.get(
dataset_name=dataset_name,
dataset_project=dataset_project
).get_local_copy()
如果你需要一个可修改的数据集副本,请使用以下代码:
Dataset.get(dataset_name, dataset_project).get_mutable_local_copy("path/to/download")
然后,脚本创建一个神经网络来训练一个模型,以对上面创建的数据集中的图像进行分类。