从任务构建管道
pipeline_from_tasks.py 示例展示了一个简单的管道,其中每个步骤都是一个ClearML任务。
管道是使用PipelineController类实现的。步骤被添加到PipelineController对象中,该对象在执行时启动并监控这些步骤。
这个例子包含了四个任务,每个任务都是使用不同的脚本创建的:
- 控制器任务 (pipeline_from_tasks.py) - 实现管道控制器,将步骤(任务)添加到管道中,并运行管道。
- 第一步 (step1_dataset_artifact.py) - 下载数据并将数据存储为工件。
- 步骤 2 (step2_data_processing.py) - 加载存储的数据(来自步骤 1),处理它,并将处理后的数据存储为工件。
- 步骤 3 (step3_train_model.py) - 加载处理后的数据(来自步骤 2)并训练网络。
当控制器任务被执行时,它会克隆步骤任务,并将新克隆的任务加入队列以执行。请注意,从中克隆步骤的基础任务仅用作模板,本身不会被执行。还要注意,为了使控制器能够克隆,这些基础任务需要存在于系统中(作为之前运行的结果或使用clearml-task)。
控制器任务本身可以在本地运行,或者,如果控制器任务已经至少运行过一次并且在ClearML服务器中,则可以克隆控制器,并且克隆的任务可以远程执行。
以下部分更详细地描述了控制器任务和每个步骤任务中发生的情况。
管道控制器
-
创建
PipelineController对象:pipe = PipelineController(
name='pipeline demo',
project='examples',
version='0.0.1',
add_pipeline_tags=False,
) -
设置执行队列,未明确指定执行队列的管道步骤将通过该队列执行。这些管道步骤将被排队在此队列中执行。
pipe.set_default_execution_queue('default') -
构建管道(完整参考请参见
PipelineController.add_step方法):管道的第一步使用了
examples项目中预先存在的任务pipeline step 1 dataset artifact。该步骤上传本地数据并将其存储为一个工件。pipe.add_step(
name='stage_data',
base_task_project='examples',
base_task_name='pipeline step 1 dataset artifact'
)第二步使用
examples项目中预先存在的任务pipeline step 2 process dataset。第二步对第一步完成的依赖通过将其设置为其父级来指定。parameter_override参数用于为每个步骤设置特定的执行配置。 在下面的代码中,第一步的工件被输入到第二步。通过使用
pre_execute_callback和post_execute_callback,分别为此步骤添加了特殊的执行前和执行后逻辑。pipe.add_step(
name='stage_process',
parents=['stage_data', ],
base_task_project='examples',
base_task_name='pipeline step 2 process dataset',
parameter_override={
'General/dataset_url': '${stage_data.artifacts.dataset.url}',
'General/test_size': 0.25
},
pre_execute_callback=pre_execute_callback_example,
post_execute_callback=post_execute_callback_example
)第三步使用
examples项目中的现有任务pipeline step 3 train model。该步骤使用第二步的工件。 -
运行管道:
pipe.start()管道通过服务队列远程启动,除非另有说明。
步骤 1 - 下载数据
管道的第一个步骤(step1_dataset_artifact.py)执行以下操作:
-
使用
StorageManager.get_local_copy()下载数据:# simulate local dataset, download one, so we have something local
local_iris_pkl = StorageManager.get_local_copy(
remote_url='https://github.com/allegroai/events/raw/master/odsc20-east/generic/iris_dataset.pkl'
) -
将数据存储为名为
dataset的工件,使用Task.upload_artifact():# add and upload local file containing our toy dataset
task.upload_artifact(name='dataset', artifact_object=local_iris_pkl)
步骤 2 - 处理数据
管道的第二步 (step2_data_processing.py) 执行以下操作:
-
将其配置参数与ClearML任务连接:
args = {
'dataset_task_id': '',
'dataset_url': '',
'random_state': 42,
'test_size': 0.2,
}
# store arguments, later we will be able to change them from outside the code
task.connect(args) -
下载上一步创建的数据(通过
dataset_url参数指定),使用StorageManager.get_local_copy()iris_pickle = StorageManager.get_local_copy(remote_url=args['dataset_url']) -
从数据中生成测试和训练集,并将它们存储为工件。
task.upload_artifact(name='X_train', artifact_object=X_train)
task.upload_artifact(name='X_test', artifact_object=X_test)
task.upload_artifact(name='y_train', artifact_object=y_train)
task.upload_artifact(name='y_test', artifact_object=y_test)
步骤 3 - 训练网络
管道的第三步 (step3_train_model.py) 执行以下操作:
-
将其配置参数与ClearML任务连接。这允许管道控制器在管道运行时覆盖
dataset_task_id值。# Arguments
args = {
'dataset_task_id': 'REPLACE_WITH_DATASET_TASK_ID',
}
task.connect(args) -
克隆基础任务并使用
Task.execute_remotely()将其加入队列:task.execute_remotely() -
访问在先前任务中创建的数据:
dataset_task = Task.get_task(task_id=args['dataset_task_id'])
X_train = dataset_task.artifacts['X_train'].get()
X_test = dataset_task.artifacts['X_test'].get()
y_train = dataset_task.artifacts['y_train'].get()
y_test = dataset_task.artifacts['y_test'].get() -
训练网络并记录图表。
运行管道
运行管道的步骤:
-
如果流水线步骤任务尚不存在,请运行其代码以创建ClearML任务:
python step1_dataset_artifact.py
python step2_data_processing.py
python step3_train_model.py -
运行管道控制器:
python pipeline_from_tasks.pynote如果你将一个任务加入队列,请确保有一个代理被分配到该队列,以便它能够执行该任务。
WebApp
当实验执行时,控制台输出显示任务ID,并链接到管道控制器任务页面和管道页面。
ClearML Task: created new task id=bc93610688f242ecbbe70f413ff2cf5f
ClearML results page: https://app.clear.ml/projects/462f48dba7b441ffb34bddb783711da7/experiments/bc93610688f242ecbbe70f413ff2cf5f/output/log
ClearML pipeline page: https://app.clear.ml/pipelines/462f48dba7b441ffb34bddb783711da7/experiments/bc93610688f242ecbbe70f413ff2cf5f
流水线运行的页面包含流水线的结构、每个步骤的执行状态,以及运行的配置参数和输出。
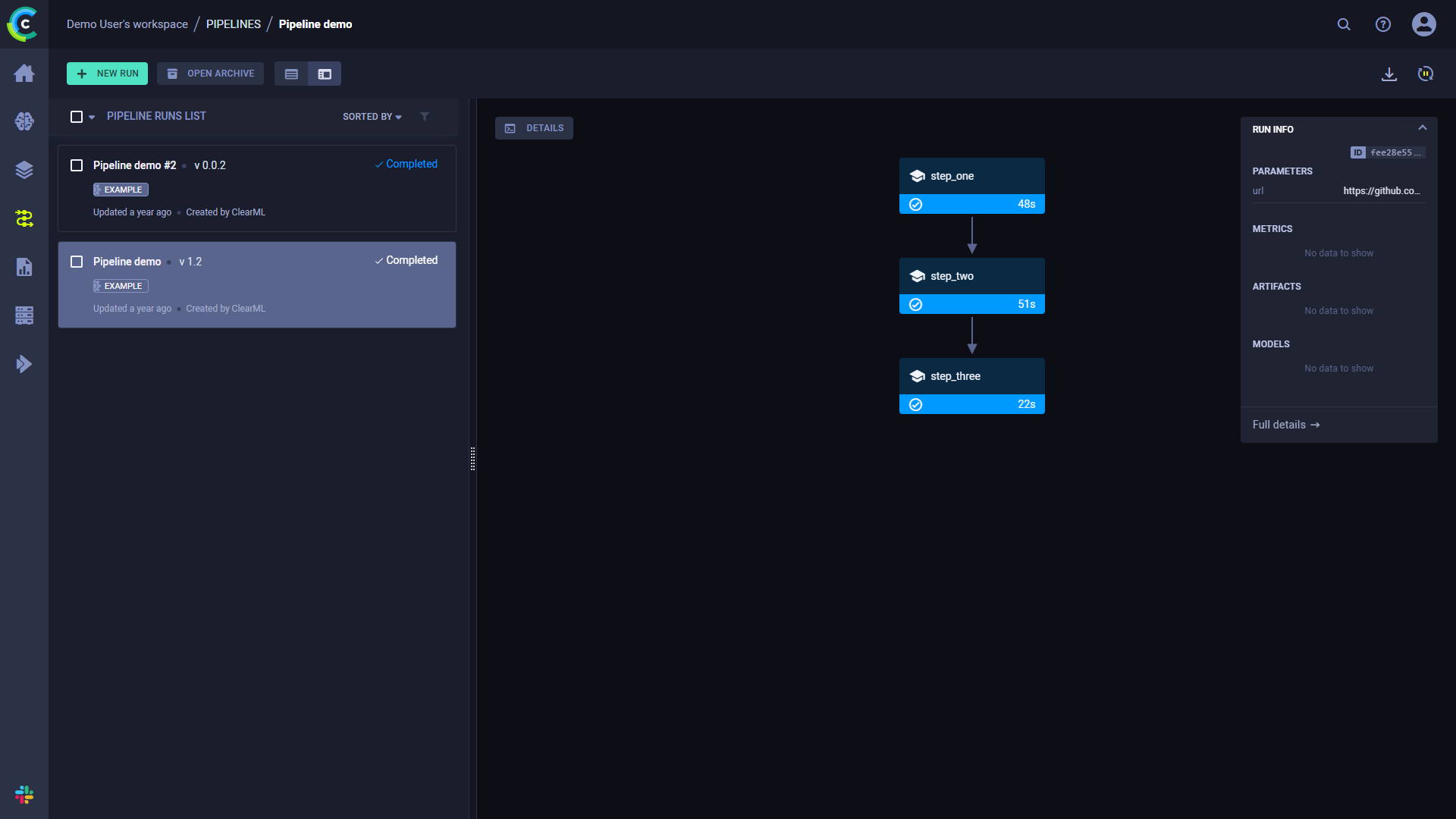
要查看运行的完整信息,请点击运行信息面板底部的完整详情,这将打开管道的控制器任务页面。
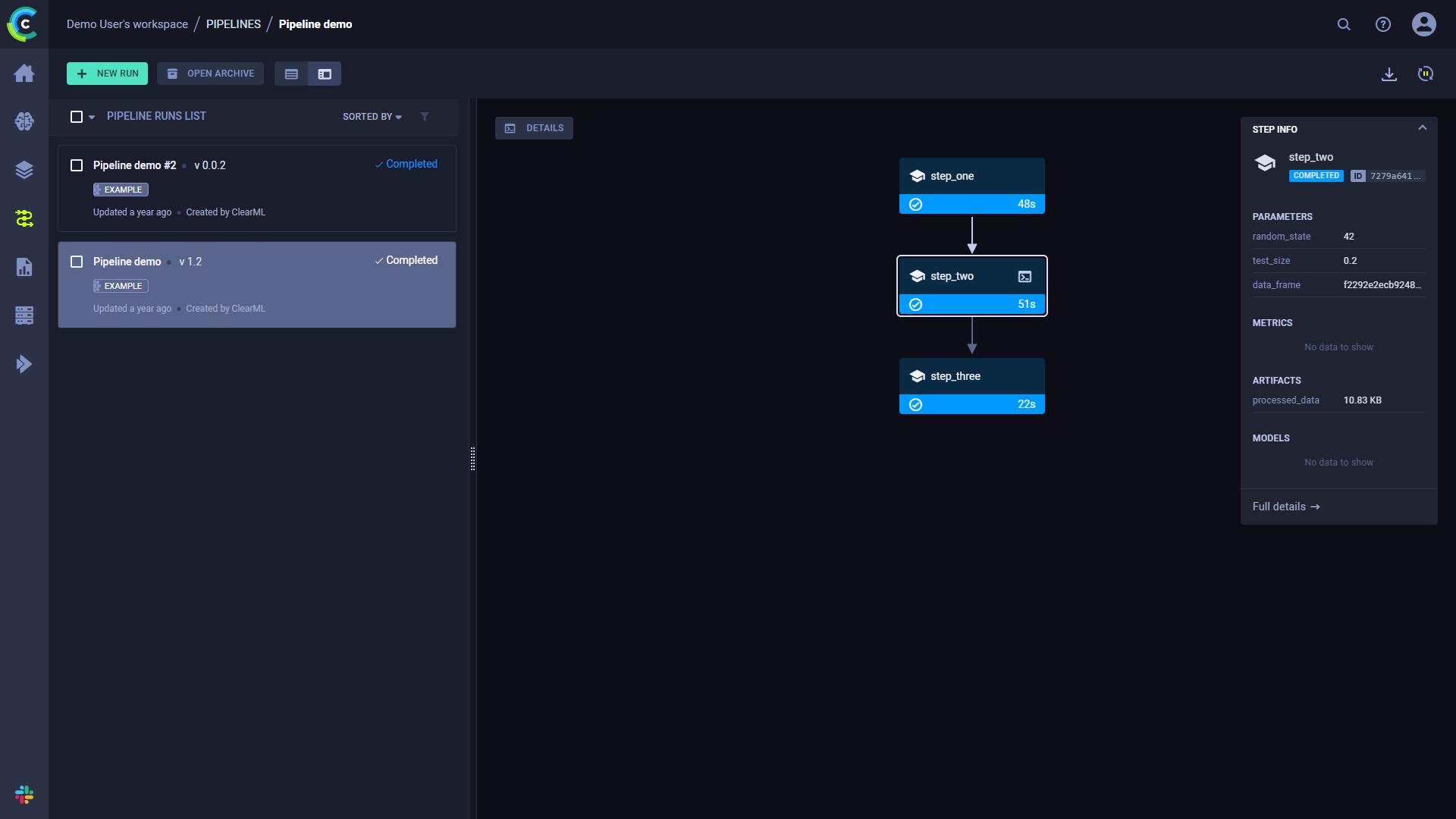
点击一个步骤以查看其摘要信息。
控制台
点击详细信息查看管道控制器控制台输出的日志。
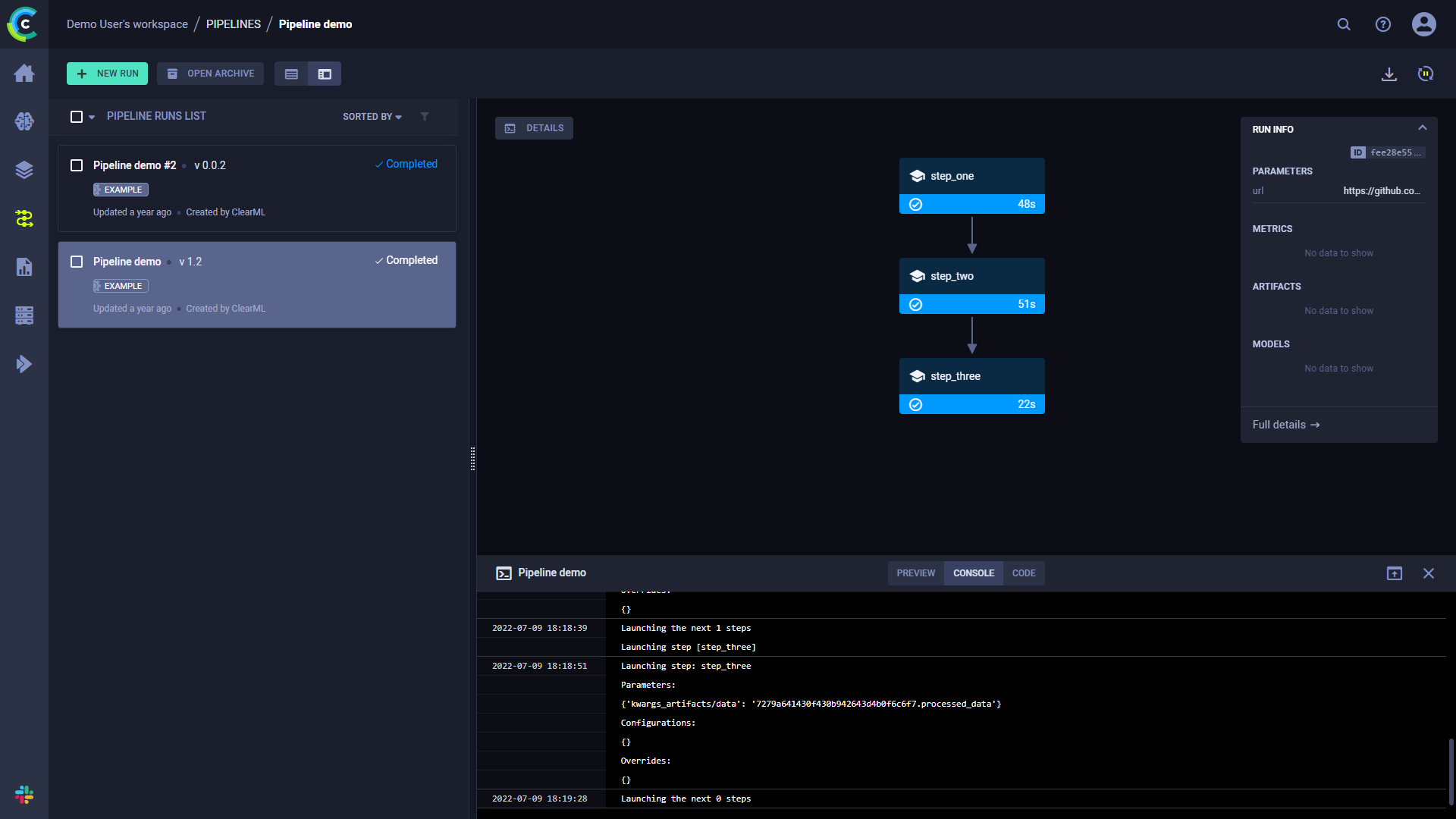
点击一个步骤以查看其控制台输出。