PyTorch 分布式
pytorch_distributed_example.py
脚本展示了如何将ClearML集成到使用PyTorch分布式通信包
(torch.distributed)的代码中。
脚本初始化一个主任务并生成子进程,每个子进程对应该任务的一个实例。 每个子进程中的任务在分区数据集(torchvision内置的MNIST数据集)上训练神经网络,并向主任务报告(上传)以下内容:
- 工件 - 包含不同键值对的字典。
- 标量 - 在子进程中每个任务训练期间报告的损失作为标量。
- 超参数 - 在每个任务中创建的超参数会被添加到主任务的超参数中。
子流程中的每个任务通过调用Task.current_task()来引用主任务,该函数始终返回主任务。
当脚本运行时,它会在examples项目中创建一个名为test torch distributed的实验。
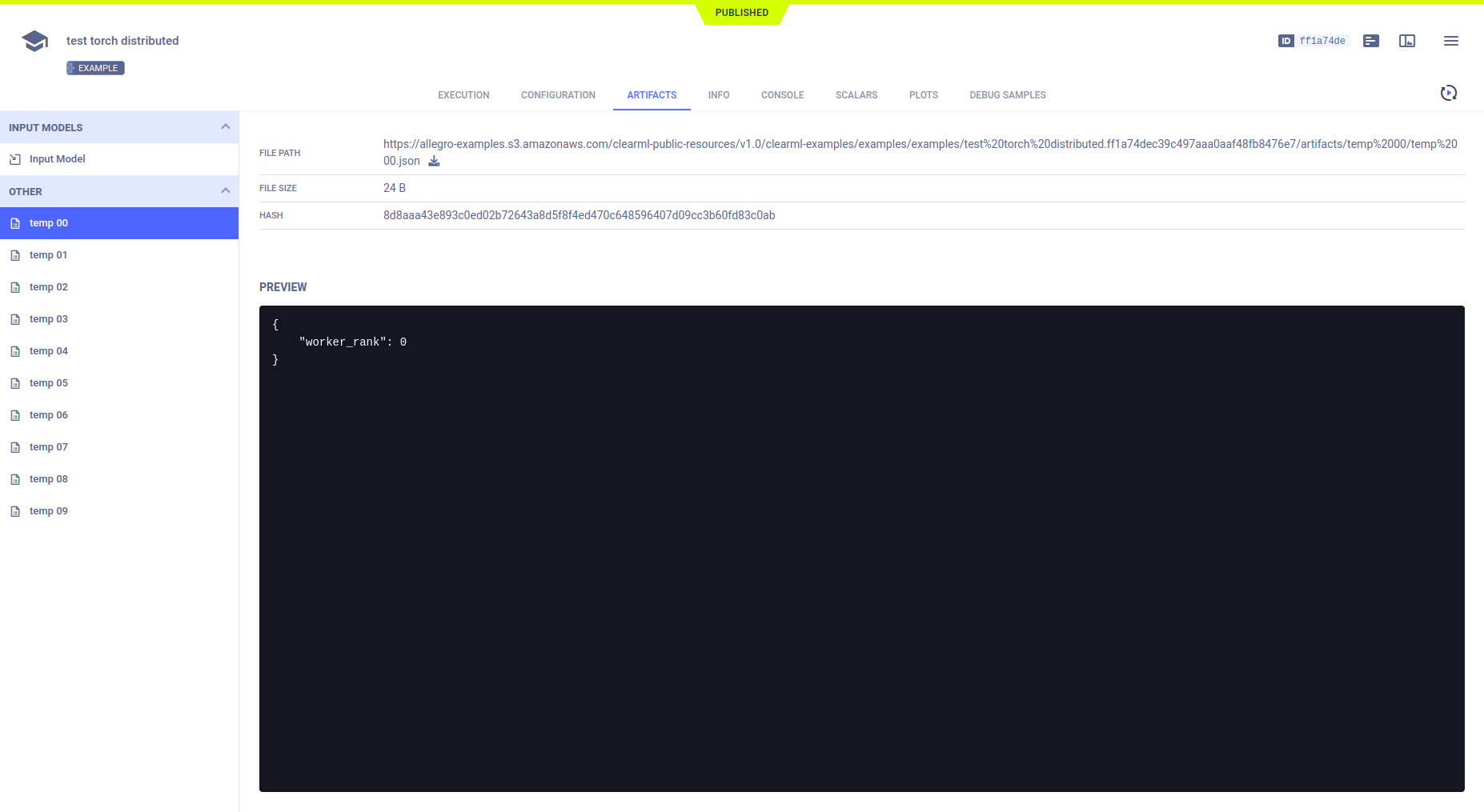
工件
该示例通过调用Task.upload_artifact()在主任务中上传一个字典作为工件。该字典包含dist.rank的子进程,使每个子进程唯一。
Task.current_task().upload_artifact(
name='temp {:02d}'.format(dist.get_rank()),
artifact_object={'worker_rank': dist.get_rank()}
)
所有这些工件都出现在主任务中的ARTIFACTS > OTHER下。
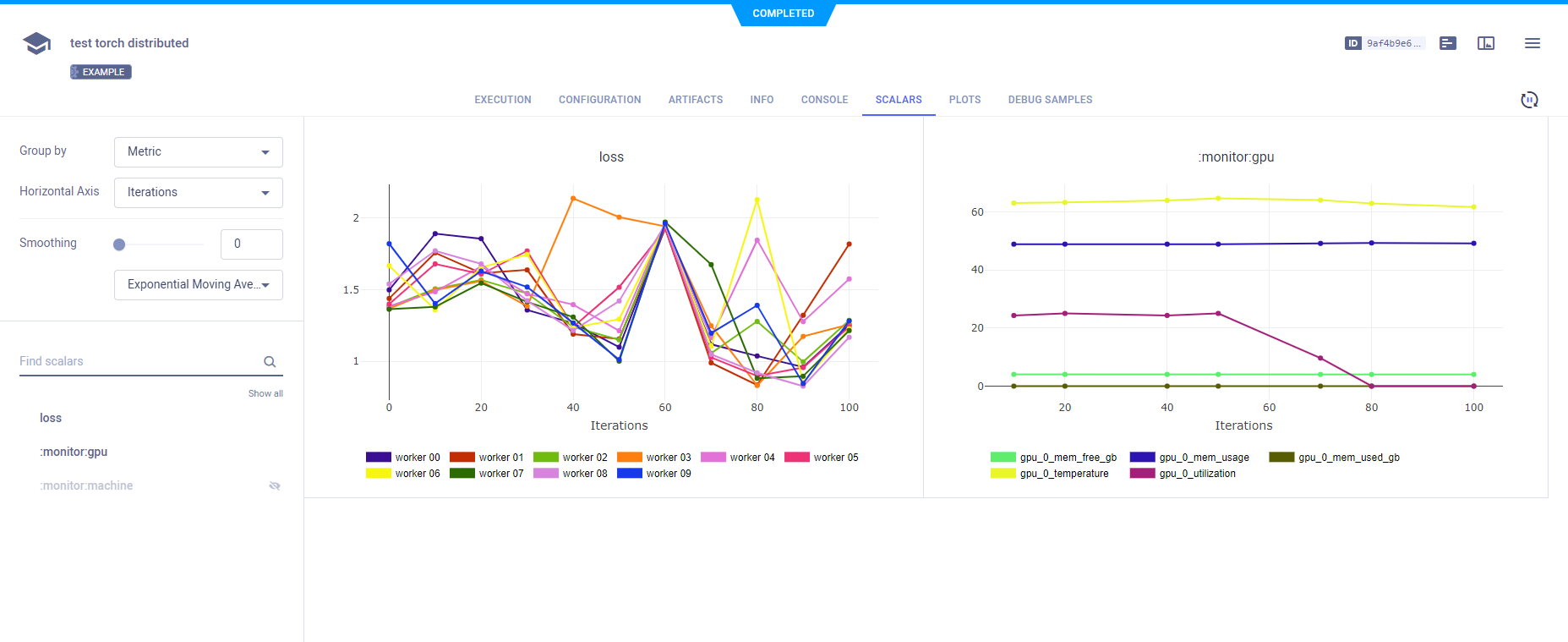
标量
通过调用Logger.report_scalar()将损失报告给主任务,这是在Task.current_task().get_logger()上进行的,这是主任务的日志记录器。由于Logger.report_scalar使用相同的标题(loss)但不同的系列名称(包含子进程的rank)调用,所有损失标量系列都被记录在一起。
Task.current_task().get_logger().report_scalar(
title='loss',
series='worker {:02d}'.format(dist.get_rank()),
value=loss.item(),
iteration=i
)
损失的单标量图出现在SCALARS中。
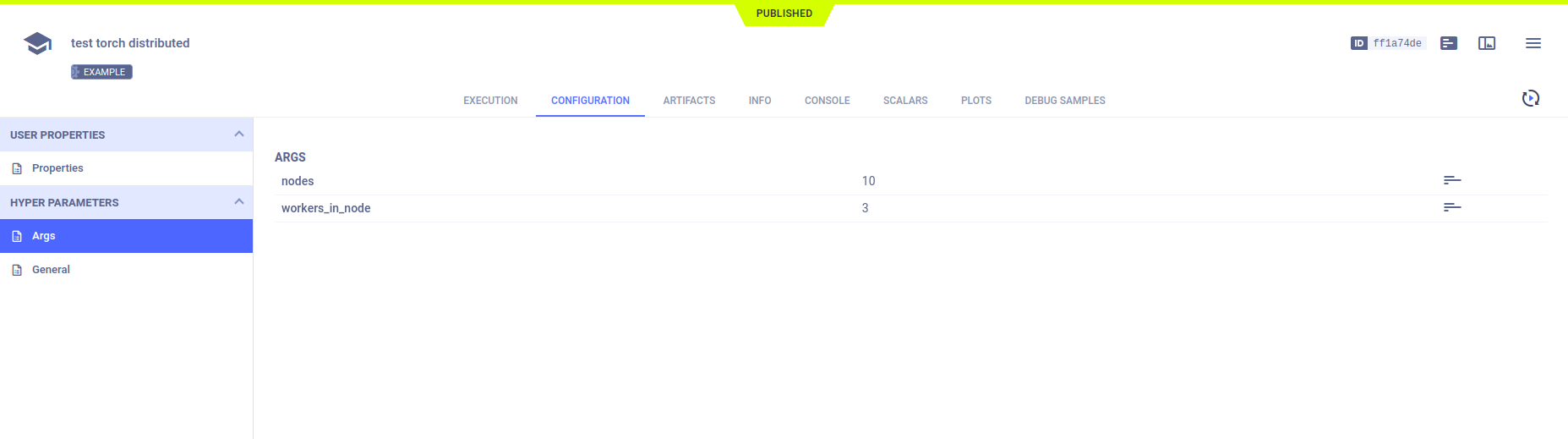
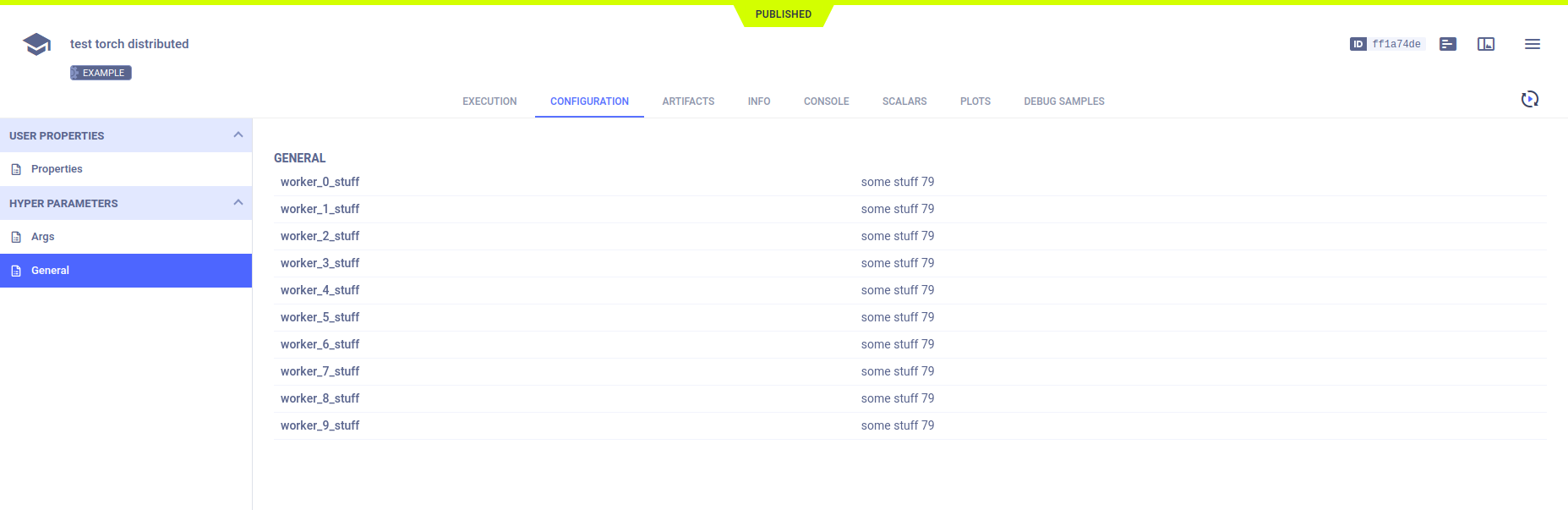
超参数
ClearML 自动记录 argparse 命令行选项。由于在 Task.connect 方法上调用 Task.current_task,它们被记录在主任务中。每个子进程使用不同的超参数键,因此它们不会在主任务中相互覆盖。
param = {'worker_{}_stuff'.format(dist.get_rank()): 'some stuff ' + str(randint(0, 100))}
Task.current_task().connect(param)
所有超参数出现在配置 > 超参数中。
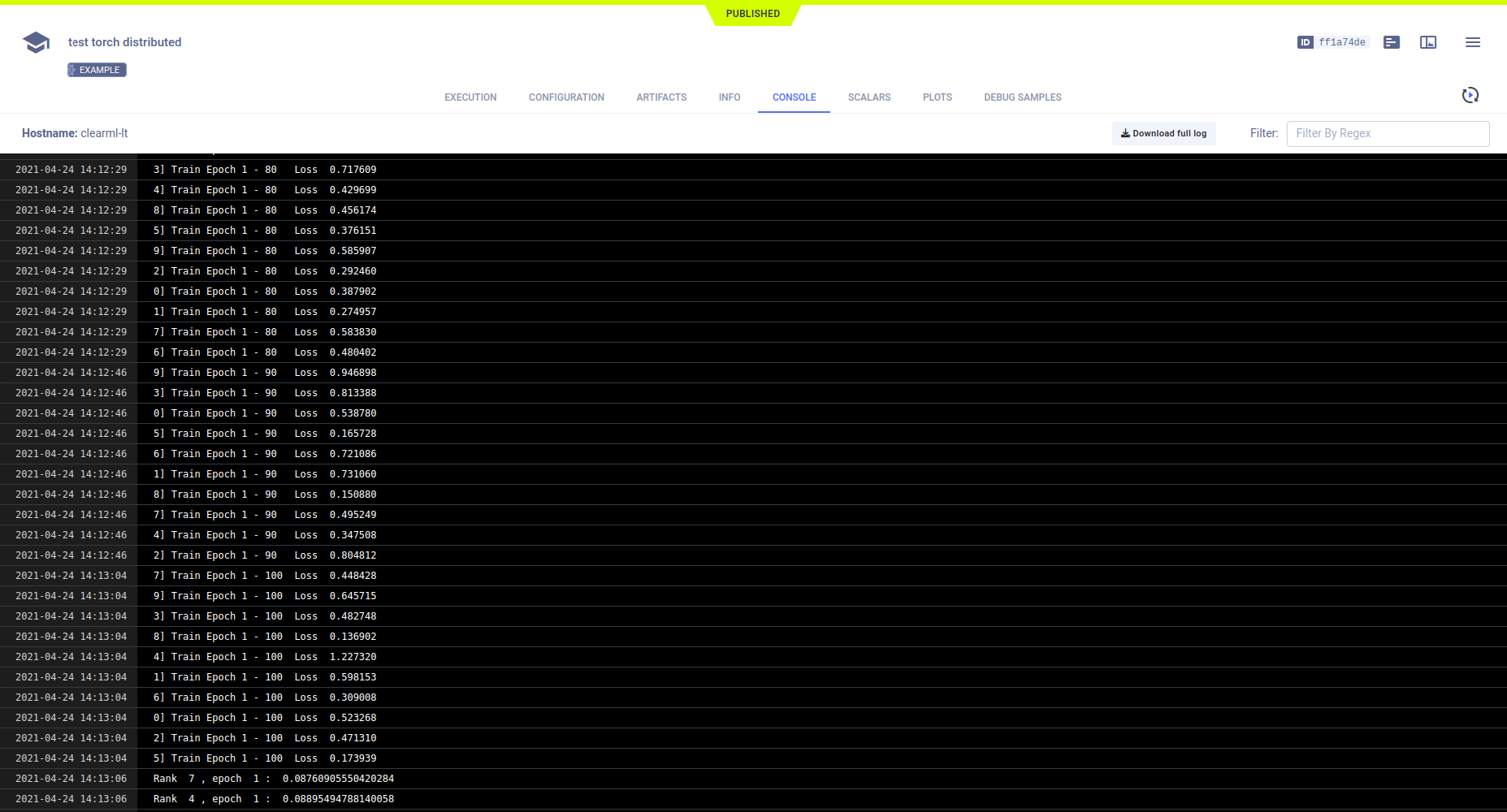
控制台
输出到控制台,包括从主任务对象和每个子进程打印的文本消息显示在控制台中。