任务
以下页面提供了ClearML任务的基本Python接口的概述。
任务创建
Task.init 是用于在ClearML中创建任务的主要方法。它将创建一个任务,并填充以下内容:
- 指向正在运行的 git 仓库的链接(包括提交 ID 和本地未提交的更改)
- 使用的Python包(即直接导入的Python包,以及机器上可用的版本)
- Argparse 参数(默认且特定于当前执行)
- 向Tensorboard和Matplotlib报告以及模型检查点。
为了确保每次运行都能提供相同的结果,ClearML通过设置固定的初始种子来控制tensorflow、pytorch和random包的确定性行为。请参阅设置随机种子。
ClearML对象(如任务、项目)名称要求至少为3个字符长
from clearml import Task
task = Task.init(
project_name='example', # project name of at least 3 characters
task_name='task template', # task name of at least 3 characters
task_type=None,
tags=None,
reuse_last_task_id=True,
continue_last_task=False,
output_uri=None,
auto_connect_arg_parser=True,
auto_connect_frameworks=True,
auto_resource_monitoring=True,
auto_connect_streams=True,
)
一旦任务被创建,任务对象可以通过调用Task.current_task()在代码的任何地方访问。
如果需要在同一进程中创建多个任务(例如,用于记录多个手动运行),请确保在初始化新任务之前关闭一个任务。要关闭任务,只需调用Task.close()
(参见示例这里)。
在初始化任务时,需要指定其所属的项目。如果输入的项目不存在,将会即时创建。 项目可以像文件夹被分成子文件夹一样,被划分为子项目。
例如:
Task.init(project_name='main_project/sub_project', task_name='test')
嵌套项目可以在多个层次上工作。例如:project_name=main_project/sub_project/sub_sub_project
自动日志记录
在脚本中调用Task.init后,ClearML 开始其自动记录,其中包括以下元素:
- 超参数 - ClearML 记录以下类型的超参数:
- 命令行解析 - ClearML 捕获调用使用标准 Python 包的代码时传递的任何命令行参数,包括:
- TensorFlow 定义 (
absl-py) - Hydra - ClearML 记录包含所有配置文件的 OmegaConf,以及在运行时覆盖的值。
- 模型 - ClearML 自动记录和更新使用以下框架保存的模型和所有快照路径:
- 指标、标量、图表、调试图像通过支持的框架报告,包括:
- 执行详情 包括:
- Git 信息
- 未提交的代码修改 - 在未检测到 git 仓库的情况下(例如,在 git 仓库外执行单个 python 脚本,或从 Jupyter Notebook 运行),ClearML 会记录执行脚本的内容
- Python 环境
- 执行 配置
控制自动日志记录
默认情况下,当ClearML集成到您的脚本中时,它会自动从支持的框架中捕获信息,并从支持的参数解析器中捕获参数。但是,您可能希望更好地控制实验日志的内容。
框架
要控制任务的框架日志记录,请使用Task.init()的auto_connect_frameworks参数。
通过将该参数设置为False来关闭所有自动日志记录。为了更精细地控制记录的框架,可以输入一个包含框架-布尔对的字典。
例如:
auto_connect_frameworks={
'matplotlib': True, 'tensorflow': False, 'tensorboard': False, 'pytorch': True,
'xgboost': False, 'scikit': True, 'fastai': True, 'lightgbm': False,
'hydra': True, 'detect_repository': True, 'tfdefines': True, 'joblib': True,
'megengine': True, 'catboost': True
}
您还可以将通配符作为字典值输入。只有当其本地路径至少匹配一个通配符时,ClearML 才会记录由框架创建的模型。
例如,在下面的代码中,ClearML 只会记录路径具有 .pt 扩展名的 PyTorch 模型。未指定框架的值默认为 true,因此它们的所有模型都会自动记录。
auto_connect_frameworks={'pytorch' : '*.pt'}
对于TensorBoard,您可以指定是否记录超参数。默认情况下,ClearML会自动记录TensorBoard的参数,但您可以使用以下代码禁用记录:
auto_connect_frameworks={'tensorboard': {'report_hparams': False}}
参数解析器
要控制任务从支持的参数解析器中记录参数,请使用Task.init()的auto_connect_arg_parser参数。
通过将该参数设置为False,可以完全禁用所有自动记录。
auto_connect_arg_parser=False
为了更精细地控制记录的参数,输入一个包含参数-布尔对的字典。False值将排除指定的参数。未指定的参数默认为True。
例如,以下代码将不会记录Example_1参数,但会记录所有其他参数。
auto_connect_arg_parser={"Example_1": False}
要排除所有未指定的参数,请将*键设置为False。
例如,以下代码将仅记录Example_2参数。
auto_connect_arg_parser={"Example_2": True, "*": False}
一个空的字典完全禁用了从参数解析器自动记录所有参数的功能:
auto_connect_arg_parser={}
任务重用
每次Task.init调用都会为当前执行创建一个新任务。
为了减少大量调试任务可能造成的混乱,如果满足以下条件,任务将被重用:
- 上次执行(在此机器上)是在24小时以内(可配置,请参阅ClearML配置参考中的
sdk.development.task_reuse_time_window_in_hours) - 之前的任务执行没有任何工件/模型
您始终可以通过传递reuse_last_task_id=False来创建一个新任务。
欲了解更多信息,请参阅Task.init()。
继续任务执行
你可以使用Task.init()的continue_last_task参数继续执行之前运行的任务。
这将保留其之前的所有工件/模型/日志。
任务将继续根据它上次停止的迭代报告其输出。例如:一个任务上次报告的train/loss标量是第100次迭代,当继续时,下一次报告将是第101次迭代。
持续的任务可能无法重现。为了保证任务的可重现性,您必须确保所有步骤都以相同的顺序完成(例如,保持学习率曲线,确保数据以相同的顺序输入)。
在continue_last_task参数中传递以下之一:
False(默认) - 覆盖前一个任务的执行(除非你传递reuse_last_task_id=False,参见 任务重用)。True- 继续之前运行的任务。- 任务ID (string) - 要继续的任务的ID。
- 初始迭代偏移量(整数)- 指定初始迭代偏移量。默认情况下,任务将在最后报告的迭代之后继续一次。传递
0以禁用自动最后迭代偏移量。要同时指定任务ID,请使用reuse_last_task_id参数。
你也可以使用Task.import_offline_session()继续之前在离线模式下执行的任务。
参见离线模式。
从现有代码或容器创建任务
任务也可以在不执行代码本身的情况下创建。 与运行时检测不同,所有环境和配置细节都需要明确提供。
例如:
task = Task.create(
project_name='example',
task_name='task template',
repo='https://github.com/allegroai/clearml.git',
branch='master',
script='examples/reporting/html_reporting.py',
working_directory='.',
docker=None,
argparse_args=[
("lr", 0.01),
("epochs", 10)
]
)
如果代码不包含Task.init()调用,传递add_task_init_call=True,代码将在由ClearML代理执行时被修补。
在argparse_args中指定参数时,请使用完整的参数名称(例如,--lr),而不是简写形式(例如,-l)。ClearML通过与参数解析器连接并替换相关的变量名称来工作,而不是替换标志。在大多数情况下,完整的参数名称和变量名称是相同的,但简写形式不同,因此无法正常工作。
欲了解更多信息,请参阅Task.create()。
跟踪任务进度
通过使用Task.set_progress()设置任务进度属性来跟踪任务的进度。
将任务的进度设置为0到100之间的数值。使用
Task.get_progress()访问任务的当前进度。
task = Task.init(project_name="examples", task_name="Track experiment progress")
task.set_progress(0)
# task doing stuff
task.set_progress(50)
print(task.get_progress())
# task doing more stuff
task.set_progress(100)
当任务正在运行时,WebApp 将在实验表中显示任务的进度指示,位于任务状态旁边。如果任务失败或被中止,您可以查看它已经完成了多少进度。
此外,您可以在WebApp的INFO标签中查看任务的进度。
访问任务
任务可以通过其项目和名称以及唯一标识符(UUID字符串)来识别。任务的名称和项目可以在实验执行后更改,但其ID不能更改。
编程上,可以通过基于任务ID或项目和名称组合查询系统来检索任务对象,使用Task.get_task()类方法。如果使用项目/名称组合,并且多个任务具有完全相同的名称,该函数将返回最后修改的任务。
例如:
-
使用任务ID访问任务对象:
a_task = Task.get_task(task_id='123456deadbeef') -
通过项目和名称访问任务:
a_task = Task.get_task(project_name='examples', task_name='artifacts')
一旦获得任务对象,您可以查询任务的状态、报告的标量等。 任务输出,如工件和模型,也可以被检索。
查询 / 搜索任务
以编程方式搜索和筛选任务。将搜索参数输入到Task.get_tasks()类方法中,该方法返回与搜索匹配的任务对象列表。传递allow_archived=False以过滤掉已归档的任务。
例如:
task_list = Task.get_tasks(
task_ids=None, # type Optional[Sequence[str]]
project_name=None, # Optional[str]
task_name=None, # Optional[str]
allow_archived=True, # [bool]
task_filter=None, # Optional[Dict]#
# tasks with tag `included_tag` or without tag `excluded_tag`
tags=['included_tag', '-excluded_tag']
)
你也可以通过将过滤规则传递给task_filter来过滤任务。
例如:
task_filter={
# filter out archived tasks
'system_tags': ['-archived'],
# only completed & published tasks
'status': ['completed', 'published'],
# only training type tasks
'type': ['training'],
# match text in task comment or task name
'search_text': 'reg_exp_text',
# order return task lists by their update time in ascending order
'order_by': ['last_update']
}
你可以通过'order_by': [last_metrics.按特定指标的性能对返回的任务进行排序。
hashlib.md5(str("来编码字符串。").encode("utf-8")).hexdigest() value(最后一个值)、min_value或max_value
使用 - 前缀按降序排列结果。
title = hashlib.md5(str("testing").encode("utf-8")).hexdigest()
series = hashlib.md5(str("epoch_accuracy").encode("utf-8")).hexdigest()
tasks = Task.get_tasks(
project_name='Example Project',
# order tasks by metric performance in descending order
task_filter={'order_by': [f'-last_metrics.{title}.{series}.max_value']}
)
查看 Task.get_tasks 以获取所有 task_filter 选项。
标签过滤器
tags 字段支持通过将标签名称和运算符组合成列表来进行高级查询。
支持的运算符有:
notandor
按照以下格式输入操作符:"__$。要排除一个标签,你也可以在标签名前使用-前缀,除非标签名以破折号字符(-)开头,在这种情况下你可以使用"__$not"。
or 和 and 运算符适用于它们之后的所有标签,直到指定另一个运算符为止。not 运算符仅适用于紧随其后的标签。
查询的默认操作符是or,除非在查询的开头放置and。
示例
-
以下查询将返回具有至少一个提供标签的任务,因为默认操作符是
or("a" OR "b" OR "c")task_list = Task.get_tasks(tags=["a", "b", "c"]) -
以下查询将返回具有所有三个提供标签的任务,因为
and运算符被放置在列表的开头,使其成为默认运算符("a" AND "b" AND "c")。task_list = Task.get_tasks(tags=["__$and", "a", "b", "c"]) -
以下查询将返回既没有标签
a也没有标签c,但有标签b的任务 (NOT "a" AND "b" AND NOT "c")。task_list = Task.get_tasks(tags=["__$not", "a", "b", "__$not" "c"]) -
以下查询将返回带有标签
a或标签b或同时带有标签c和d的任务 ("a" OR "b" OR ("c" AND "d"))。task_list = Task.get_tasks(tags=["a", "b", "__$and", "c", "d"]) -
以下查询将返回具有标签
a或标签b以及同时具有标签c和标签d的任务 (("a" OR "b") AND "c" AND "d")。task_list = Task.get_tasks(
tags=["__$and", "__$or", "a", "b", "__$and", "c", "d"]
)
克隆和执行任务
一旦创建了一个任务对象,它就可以被复制(克隆)。Task.clone() 返回原始任务(source_task)的副本。默认情况下,克隆的任务会被添加到与原始任务相同的项目中,并且它被称为“克隆自 ORIGINAL_NAME”,但克隆任务的名称 / 项目 / 评论(描述)可以直接被覆盖。
task = Task.init(project_name='examples', task_name='original task',)
cloned_task = Task.clone(
source_task=task, # type: Optional[Union[Task, str]]
# override default name
name='newly created task', # type: Optional[str]
comment=None, # type: Optional[str]
# insert cloned task into a different project
project='<new_project_id>', # type: Optional[str]
)
一个新克隆的任务具有草稿状态,
因此您可以修改任何配置。例如,运行不同git版本的代码,使用新的lr值,进行
不同数量的训练周期,并使用新的基础模型:
# Set parameters (replaces existing hyperparameters in task)
cloned_task.set_parameters({'epochs':7, 'lr': 0.5})
# Override git repo information
cloned_task.set_repo(repo="https://github.com/allegroai/clearml.git", branch="my_branch_name")
# Remove input model and set a new one
cloned_task.remove_input_models(models_to_remove=["<model_id>"])
cloned_task.set_input_model(model_id="<new_intput_model_id>")
一旦任务被修改,通过使用Task.enqueue()类方法将其推入执行队列来启动它。然后,分配给队列的ClearML Agent将从队列中拉取任务并执行它。
Task.enqueue(
task=cloned_task, # type: Union[Task, str]
queue_name='default', # type: Optional[str]
queue_id=None # type: Optional[str]
)
查看入队 示例。
高级流程
远程执行
一个引人注目的工作流程是:
- 在开发机器上运行代码进行几次迭代,或者只是设置环境。
- 将执行转移到更强大的远程机器上进行实际训练。
使用Task.execute_remotely()来实现此工作流程。此方法停止当前的手动执行,然后在远程机器上重新运行它。
例如:
task.execute_remotely(
queue_name='default', # type: Optional[str]
clone=False, # type: bool
exit_process=True # type: bool
)
一旦在机器上调用该方法,它将停止本地进程并将当前任务排入default队列。从那里,代理可以拉取并启动它。
请参阅远程执行示例。
远程函数执行
也可以在远程机器上启动特定函数,使用Task.create_function_task()。
例如:
def run_me_remotely(some_argument):
print(some_argument)
a_func_task = task.create_function_task(
func=run_me_remotely, # type: Callable
func_name='func_id_run_me_remotely', # type:Optional[str]
task_name='a func task', # type:Optional[str]
# everything below will be passed directly to our function as arguments
some_argument=123
)
传递给函数的参数将自动记录在实验的配置选项卡中的超参数 > 函数部分。 与任何其他参数一样,它们可以从用户界面或以编程方式更改。
函数任务必须从常规任务中创建,通过调用Task.init来创建。
分布式执行
ClearML 支持通过多个工作节点进行分布式远程执行,使用 Task.launch_multi_node()。
此方法创建任务的多个副本并将它们排队执行。
任务的每个副本称为一个节点。启动节点执行的原始任务称为主节点。
Task = task.init(task_name ="my_task", project_name="my_project")
task.execute_remotely(queue="default")
task.launch_multi_node(total_num_nodes=3, port=29500, queue=None, wait=False, addr=None)
# rest of code
total_num_nodes- 要创建的工作节点总数(包括主节点)。port- 主节点监听的网络端口。如果设置了CLEARML_MULTI_NODE_MASTER_DEF_PORT或MASTER_PORT环境变量,此值将被覆盖。addr- 主节点工作者的地址。如果设置了CLEARML_MULTI_NODE_MASTER_DEF_ADDR或MASTER_ADDR环境变量,此值将被覆盖。如果未指定,将使用主节点运行的机器的私有IP。queue- 用于启动工作节点的执行队列。如果为None,节点将被排入与主节点相同的队列。wait- 如果为True,主节点将等待其他节点启动
当方法执行时,会设置以下环境变量:
MASTER_ADDR- 主节点运行的机器地址MASTER_PORT- 主节点正在监听的网络端口WORLD_SIZE- 总节点数,包括主节点RANK- 当前节点的排名(主节点的排名为0)
每个任务的multi_node_instance任务配置条目保存了多节点执行信息:
total_num_nodes- 节点总数,包括主节点queue- 节点将被入队的队列
该方法返回一个包含多节点运行相关信息的字典:
master_addr- 主节点运行的机器地址master_port- 主节点正在监听的网络端口total_num_nodes- 节点总数,包括主节点queue- 节点入队的队列,不包括主节点node_rank- 当前节点的排名wait- 如果为True,主节点将等待其他节点启动
Task.launch_multi_node() 应该在底层的分布式计算框架(例如 torch.distributed.init_process_group)之前调用。
示例:PyTorch 分布式
你可以使用Task.launch_multi_node()与分布式模型训练框架(如PyTorch的分布式通信包)结合使用。
from clearml import Task
import torch
import torch.distributed as dist
def run(rank, size):
print('World size is ', size)
tensor = torch.zeros(1)
if rank == 0:
for i in range(1, size):
tensor += 1
dist.send(tensor=tensor, dst=i)
print('Sending from rank ', rank, ' to rank ', i, ' data: ', tensor[0])
else:
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' received data: ', tensor[0])
if __name__ == '__main__':
task = Task.init(project_name='examples', task_name="distributed example")
task.execute_remotely(queue_name='queue')
config = task.launch_multi_node(4)
dist.init_process_group('gloo')
run(config.get('node_rank'), config.get('total_num_nodes'))
离线模式
您可以在离线模式下处理任务,其中任务捕获的所有数据和日志都存储在本地会话文件夹中,稍后可以上传到ClearML Server。
您可以通过以下方式之一启用离线模式:
-
在初始化任务之前,使用
Task.set_offline()类方法并将offline_mode参数设置为True:from clearml import Task
# Use the set_offline class method before initializing a Task
Task.set_offline(offline_mode=True)
# Initialize a Task
task = Task.init(project_name="examples", task_name="my_task") -
在运行任务之前,设置
CLEARML_OFFLINE_MODE=1
离线模式仅适用于使用Task.init()创建的任务,而不适用于使用Task.create()创建的任务。
任务捕获的所有信息都保存在本地。一旦任务脚本执行完成,它会被压缩。
任务的控制台输出显示任务ID和包含捕获信息的文件夹路径:
ClearML Task: created new task id=offline-372657bb04444c25a31bc6af86552cc9
...
...
ClearML Task: Offline session stored in /home/user/.clearml/cache/offline/b786845decb14eecadf2be24affc7418.zip
使用以下方法之一将任务离线捕获的执行数据上传到ClearML服务器:
-
clearml-task命令行界面clearml-task --import-offline-session "path/to/session/.clearml/cache/offline/b786845decb14eecadf2be24affc7418.zip"使用
--import-offline-session参数传递包含捕获信息的zip文件夹的路径 -
Task.import_offline_session()类方法from clearml import Task
Task.import_offline_session(session_folder_zip="path/to/session/.clearml/cache/offline/b786845decb14eecadf2be24affc7418.zip")在
session_folder_zip参数中,插入包含会话的zip文件夹的路径。要从创建会话的同一脚本上传会话,首先关闭任务,然后禁用离线模式:
Task.set_offline(offline_mode=True)
task = Task.init(project_name="examples", task_name="my_task")
# task code
task.close()
Task.set_offline(False)
Task.import_offline_session(task.get_offline_mode_folder())您还可以使用离线任务通过提供先前执行任务的ID来更新现有已执行任务的执行。为了避免覆盖指标,您可以使用
iteration_offset指定初始迭代偏移量。Task.import_offline_session(
session_folder_zip="path/to/session/.clearml/cache/offline/b786845decb14eecadf2be24affc7418.zip",
previous_task_id="12345679",
iteration_offset=1500
)
两种选项都将上传任务的完整执行细节和输出,并返回指向ClearML服务器上任务结果页面的链接。
设置随机种子��
为了确保任务的可重复性,ClearML通过设置固定的初始种子来控制tensorflow、pytorch和random包的确定性行为。
ClearML 使用 1337 作为默认的初始种子。要为您的任务设置不同的值,请在初始化任务之前使用 Task.set_random_seed 类方法并提供新的种子值。
你可以通过传递Task.set_random_seed(None)来完全禁用确定性行为。
工件
工件是由任务创建的输出文件。ClearML 上传并记录这些产品,以便以后可以轻松访问、修改和使用。
记录工件
要在任务中记录一个工件,请使用upload_artifact()。
例如:
-
上传一个包含数据预处理结果的本地文件:
task.upload_artifact(name='data', artifact_object='/path/to/preprocess_data.csv') -
通过传递文件夹来上传整个文件夹及其所有内容,该文件夹将被压缩并作为单个zip文件上传:
task.upload_artifact(name='folder', artifact_object='/path/to/folder') -
注册指向网络存储对象的链接(即由ClearML支持的方案URL,如
http://、https://、s3://、gs://或azure://)。该工件将仅作为URL添加,不会被上传。task.upload_artifact(name='link', artifact_object='azure://.blob.core.windows.net/path/to/file' ) -
序列化并上传一个Python对象。ClearML 根据对象的类型自动选择文件格式,或者您可以明确指定格式如下:
- dict -
.json(default),.yaml - pandas.DataFrame -
.csv.gz(default),.parquet,.feather,.pickle - numpy.ndarray -
.npz(default),.csv.gz - PIL.Image - Any PIL-supported extensions (default
.png)
例如:
person_dict = {'name': 'Erik', 'age': 30}
# upload as JSON artifact
task.upload_artifact(name='person dictionary json', artifact_object=person_dict)
# upload as YAML artifact
task.upload_artifact(
name='person dictionary yaml',
artifact_object=person_dict,
extension_name="yaml"
) - dict -
查看更多详细信息,请访问Artifacts Reporting 示例和SDK 参考。
使用工件
任务的工件通过任务的artifact属性访问,该属性列出了工件的位置。
随后可以通过以下方式从各自的位置检索工件:
get_local_copy()- 下载工件并缓存以供以后使用,返回缓存副本的路径。get()- 返回从下载的工件文件构造的Python对象。
下面的代码演示了如何使用之前生成的预处理数据访问文件工件:
# get instance of task that created artifact, using task ID
preprocess_task = Task.get_task(task_id='the_preprocessing_task_id')
# access artifact
local_csv = preprocess_task.artifacts['data'].get_local_copy()
更多详情请参见使用Artifacts示例。
模型
以下是通过Task对象使用模型的概述。你也可以直接使用模型对象(参见模型(SDK))。
手动记录模型
要手动记录任务中的模型,请创建OutputModel类的实例。 OutputModel对象始终注册为构建它的任务的输出模型。
例如:
from clearml import OutputModel, Task
# Instantiate a Task
task = Task.init(project_name="myProject", task_name="myTask")
# Instantiate an OutputModel with a task object argument
output_model = OutputModel(task=task, framework="PyTorch")
手动更新模型
手动上传的模型的快照不会自动捕获。要更新任务的模型,请使用
Task.update_output_model 方法:
task.update_output_model(model_path='path/to/model')
您可以修改以下参数:
- Model Location
- Model Name
- Model Description
- Number of iterations
- Model Tags
模型也可以在没有任务的情况下手动独立更新。参见 OutputModel.update_weights。
使用模型
访问任务之前训练的模型与访问任务工件非常相似。任务的模型通过任务的models属性访问,该属性列出了输入模型和输出模型快照的位置。
随后可以通过使用get_local_copy()从各自的位置检索模型,该函数会下载模型并缓存以供后续使用,返回缓存副本的路径(如果使用TensorFlow,快照存储在文件夹中,因此local_weights_path将指向包含请求快照的文件夹)。
prev_task = Task.get_task(task_id='the_training_task')
last_snapshot = prev_task.models['output'][-1]
local_weights_path = last_snapshot.get_local_copy()
请注意,如果其中一个框架加载了一个现有的权重文件,正在运行的任务将自动更新其“输入模型”,直接指向原始训练任务的模型。这使得在您的系统中轻松获取每个训练和使用模型的完整谱系!
由ML框架加载的模型会出现在ClearML UI中实验的工件选项卡下的“输入模型”部分。
设置上传目标
ClearML 自动捕获由 TensorFlow、PyTorch 和 scikit-learn 等框架创建的模型的存储位置。默认情况下,它会存储它们保存的本地路径。
要自动存储特定实验创建的所有模型,请按如下方式修改Task.init函数:
task = Task.init(
project_name='examples',
task_name='storing model',
output_uri='s3://my_models/'
)
使用相关格式指定模型存储URI位置:
- 一个共享文件夹:
/mnt/share/folder - S3:
s3://bucket/folder - 非AWS S3类似服务(如MinIO):
s3://host_addr:port/bucket - Google Cloud Storage:
gs://bucket-name/folder - Azure 存储:
azure://<account name>.blob.core.windows.net/path/to/file
要自动存储任何实验创建的所有模型到特定位置,请编辑clearml.conf(参见
ClearML 配置参考)并将sdk.developmenmt.default_output_uri
设置为所需的存储位置(参见存储)。这在
使用clearml-agent执行代码时特别有用。
配置
手动超参数记录
设置参数
要手动定义参数,请使用Task.set_parameters()在参数字典中指定名称-值对。
参数可以被分配到不同的部分:通过在参数名称前加上部分名称,并用斜杠分隔来指定参数的部分(即section_name/parameter_name:value)。General是默认的部分。
调用 Task.set_parameter() 来设置单个参数。
task = Task.init(project_name='examples', task_name='parameters')
# override parameters with provided dictionary
task.set_parameters({'Args/epochs':7, 'lr': 0.5})
# setting a single parameter
task.set_parameter(name='decay', value=0.001)
Task.set_parameters() 替换任务中的任何现有超参数。
添加参数
要更新任务中的参数,请使用Task.set_parameters_as_dict()。
参数和值以字典形式输入。与上面的set_parameters类似,可以指定参数的部分。
task = Task.task_get(task_id='123456789')
# add parameters
task.set_parameters_as_dict({'my_args/lr':0.3, 'epochs':10})
访问参数
要访问所有任务参数,请使用Task.get_parameters()。此方法返回一个扁平化的字典,包含'section/parameter': 'value'对。
task = Task.get_task(project_name='examples', task_name='parameters')
# will print a flattened dictionary of the 'section/parameter': 'value' pairs
print(task.get_parameters())
使用Task.get_parameter方法访问特定参数,指定参数名称和部分。
param = task.get_parameter(name="Args/batch_size")
参数及其部分名称区分大小写
追踪Python对象
ClearML 可以跟踪 Python 对象(如字典和自定义类)在代码中的演变,并使用 Task.connect() 将它们记录到任务的配置中。一旦对象连接到任务,ClearML 会自动记录所有对象元素(例如类成员、字典键值对)。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
me = Person('Erik', 5)
params_dictionary = {'epochs': 3, 'lr': 0.4}
task = Task.init(project_name='examples', task_name='python objects')
task.connect(me)
task.connect(params_dictionary)
配置对象
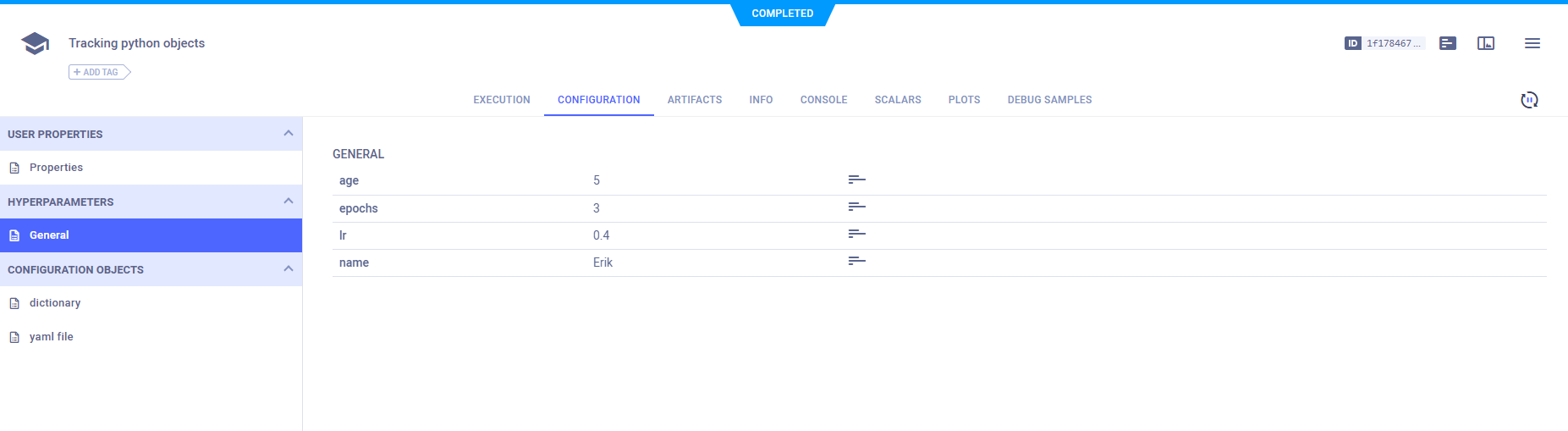
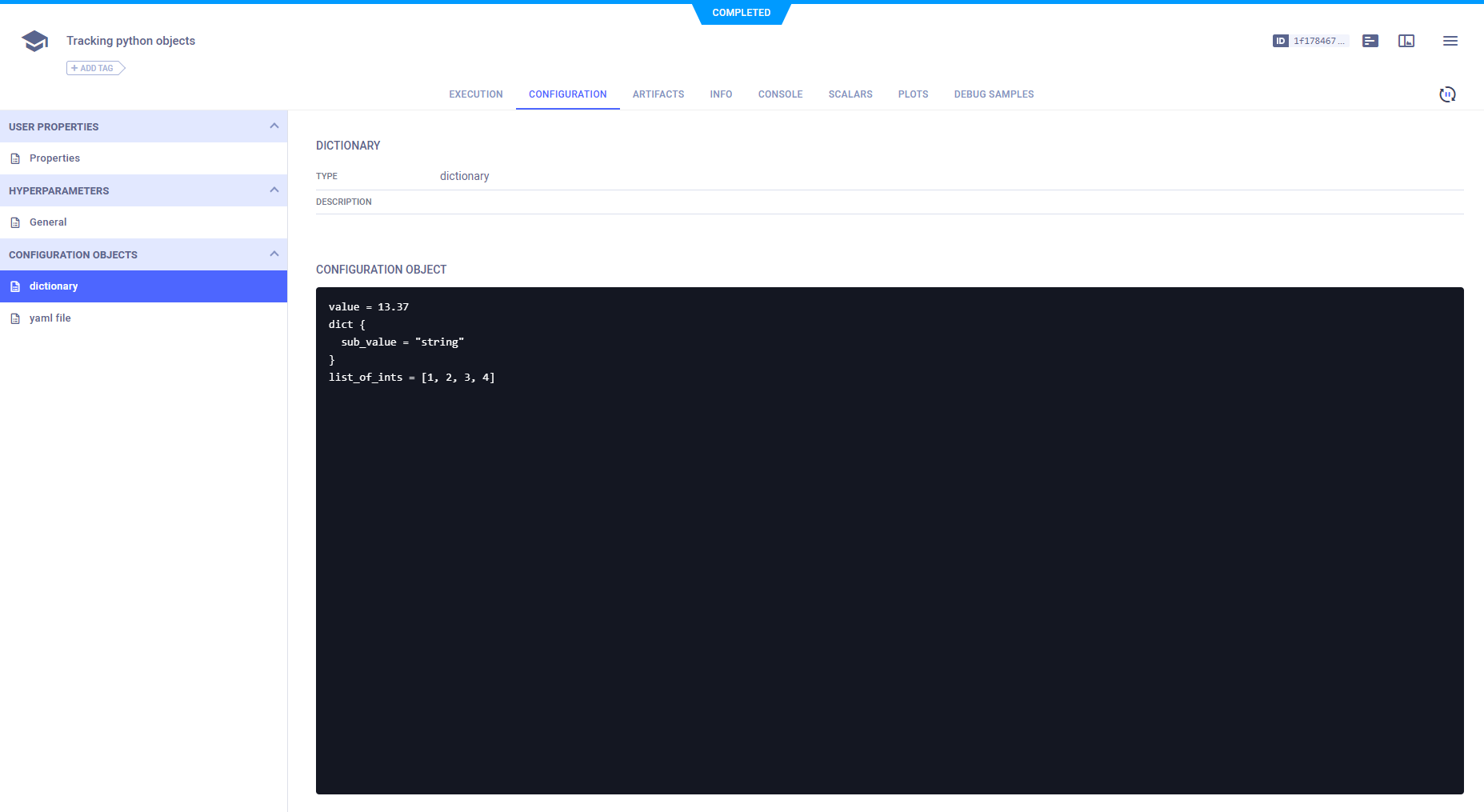
要记录比键值字典更复杂的配置(例如嵌套字典或配置文件),请使用Task.connect_configuration()。此方法将配置对象保存为blob(即ClearML不知道它们的内部结构)。
# connect a configuration dictionary
model_config_dict = {
'value': 13.37, 'dict': {'sub_value': 'string'}, 'list_of_ints': [1, 2, 3, 4],
}
model_config_dict = task.connect_configuration(
name='dictionary', configuration=model_config_dict
)
# connect a configuration file
config_file_yaml = task.connect_configuration(
name="yaml file", configuration='path/to/configuration/file.yaml'
)
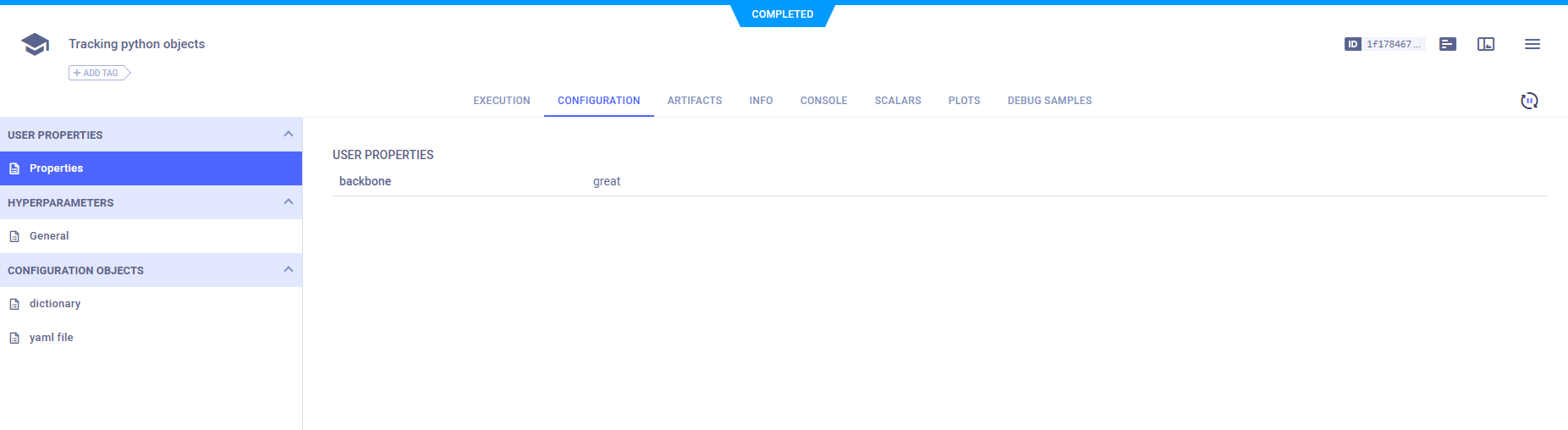
用户属性
任务的用户属性不会影响任务的执行,因此您可以在任何阶段添加/修改这些属性。使用Task.set_user_properties方法向任务添加用户属性。
例如,下面的代码在任务中设置了“backbone”属性:
task.set_user_properties(
{"name": "backbone", "description": "network type", "value": "great"}
)
标量
在脚本中调用Task.init后,ClearML会自动捕获由支持的框架记录的标量(参见自动记录)。
ClearML 还支持使用 Logger 类显式记录标量。
# get logger object for current task
logger = task.get_logger()
# report scalar to task
logger.report_scalar(
title='scalar metrics', series='series', value=scalar_value, iteration=iteration
)
# report single value metric
logger.report_single_value(name="scalar_name", value=scalar_value)
请参阅手动报告以获取更多信息。
检索标量值
标量摘要
使用 Task.get_last_scalar_metrics() 获取任务中记录的所有标量的摘要。
此调用返回一个嵌套字典,包含报告给任务的每个标量度量的最后、最大和最小值,按标题和系列排序:
{
"title": {
"series": {
"last": 0.5,
"min": 0.1,
"max": 0.9
}
}
}
获取样本值
使用get_reported_scalars()来检索每个指标/系列的记录标量样本。
使用max_samples参数来指定每个系列返回的最大样本数(最多5000个)。
要获取所有标量值,请使用 Task.get_all_reported_scalars()。
使用 x_axis 参数设置 x 轴单位。选项有:
iter- 迭代(默认)timestamp- 自纪元以来的毫秒数iso_time- 墙上时间
task.get_reported_scalars(max_samples=0, x_axis='iter')
这将返回标量图值的嵌套字典:
{
"title": {
"series": {
"x": [0, 1, 2],
"y": [10, 11, 12]
}
}
}
此调用不会被缓存。如果任务有许多报告的标量,调用可能需要很长时间才能返回。
获取单值标量
要获取报告的单值标量的值,请使用Task.get_reported_single_value()并指定标量的name。
要获取所有报告的单标量值,请使用Task.get_reported_single_values(),它返回一个标量名称和值对的字典:
{'<scalar_name_1>': <value_1>, '<scalar_name_2>': <value_2>}
SDK 参考
有关详细信息,请参阅完整的任务SDK参考页面。