变形金刚
HuggingFace的Transformers是一个流行的深度学习框架。你可以
无缝地将ClearML集成到你的Transformer的PyTorch Trainer
代码中,使用内置的ClearMLCallback。
ClearML会自动记录Transformer的模型、参数、标量等。
你只需要安装并设置ClearML:
-
安装
clearmlpython 包:pip install clearml -
为了跟踪您的实验和/或数据,ClearML 需要与服务器通信。您有2种服务器选项:
- 免费注册ClearML 托管服务
- 设置您自己的服务器,请参见这里。
-
通过创建凭证将ClearML SDK连接到服务器(在UI的右上角转到设置 > 工作区 > 创建新凭证),然后执行以下命令并按照说明操作:
clearml-init
就是这样!从现在开始的每一次训练运行中,ClearML实验管理器将捕获:
- Source code and uncommitted changes
- 超参数 - PyTorch 训练器 parameters 和 TensorFlow 定义
- Installed packages
- 模型文件(确保
CLEARML_LOG_MODEL环境变量设置为True) - 标量(损失,学习率)
- Console Output
- 一般详细信息,如机器详细信息、运行时间、创建日期等。
- 还有更多
所有这些都被捕获到一个ClearML任务中。默认情况下,会在HuggingFace Transformers项目中创建一个名为Trainer的任务。要更改任务的名称或项目,请使用CLEARML_PROJECT和CLEARML_TASK环境变量。
ClearML 使用 / 作为子项目的分隔符:使用 example/sample 作为名称将在 example 项目中创建 sample 任务。
为了记录训练期间创建的模型,将CLEARML_LOG_MODEL环境变量设置为True。
您可以在ClearML的WebApp任务页面查看所有捕获的数据。
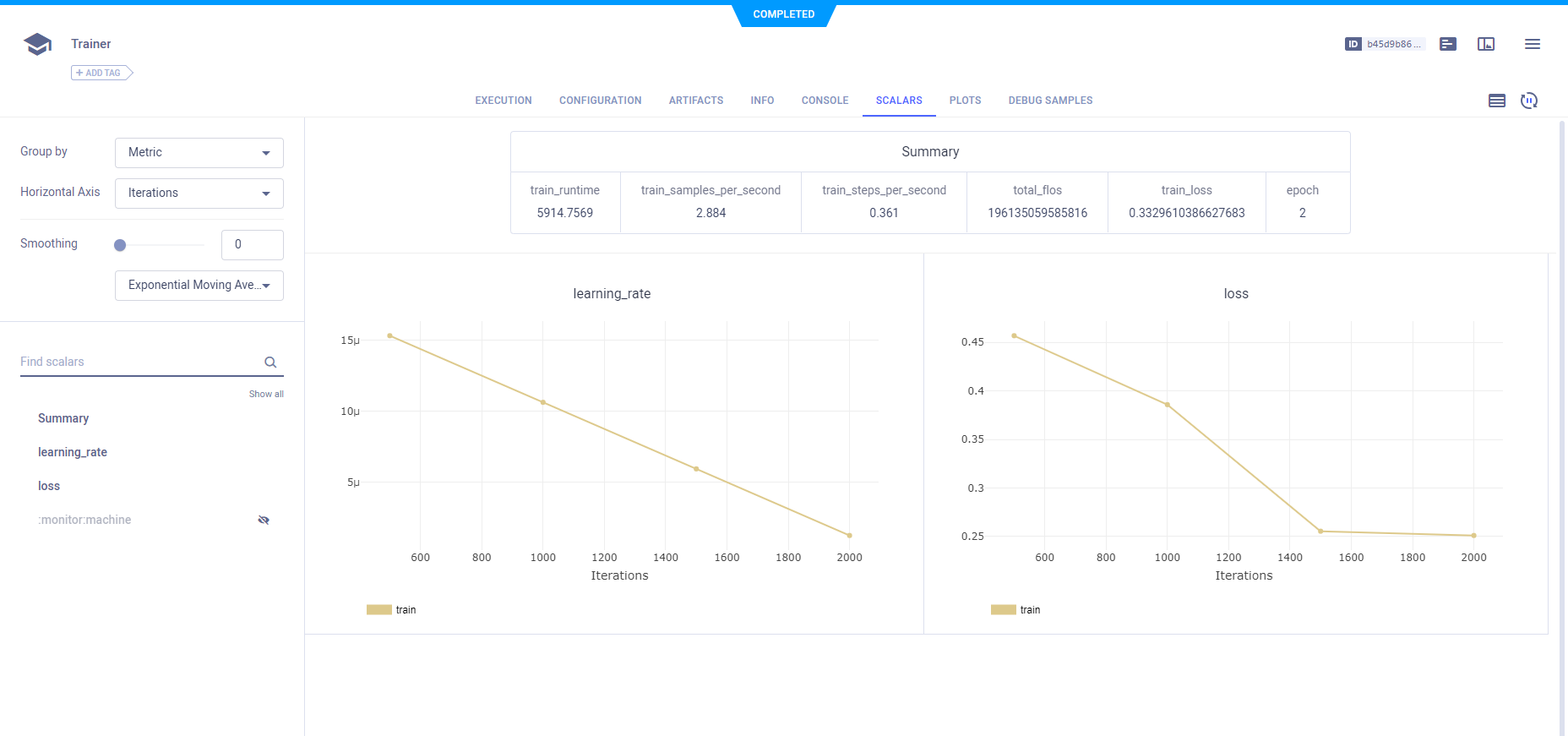
此外,您可以在实验表中查看由ClearML跟踪的所有Transformers运行。 在表格中添加自定义列,例如mAP值,以便您可以轻松排序并查看性能最佳的模型。 您还可以选择多个实验并直接比较它们。
查看Transformers和ClearML的实际应用示例这里。
远程执行
ClearML 记录了在不同机器上重现实验所需的所有信息(已安装的包、未提交的更改等)。ClearML Agent 监听指定的队列,当任务入队时,代理会拉取它,重新创建其执行环境并运行它,将其标量、图表等报告给实验管理器。
通过在任何机器上(例如云虚拟机、本地GPU机器、您自己的笔记本电脑)运行以下命令来部署ClearML代理:
clearml-agent daemon --queue <queues_to_listen_to> [--docker]
使用ClearML的自动扩展器来帮助您管理所选云(AWS、GCP、Azure)中的云工作负载,并自动部署ClearML代理:自动扩展器会根据您设置的资源预算,根据需要自动启动和关闭实例。
克隆、编辑和入队
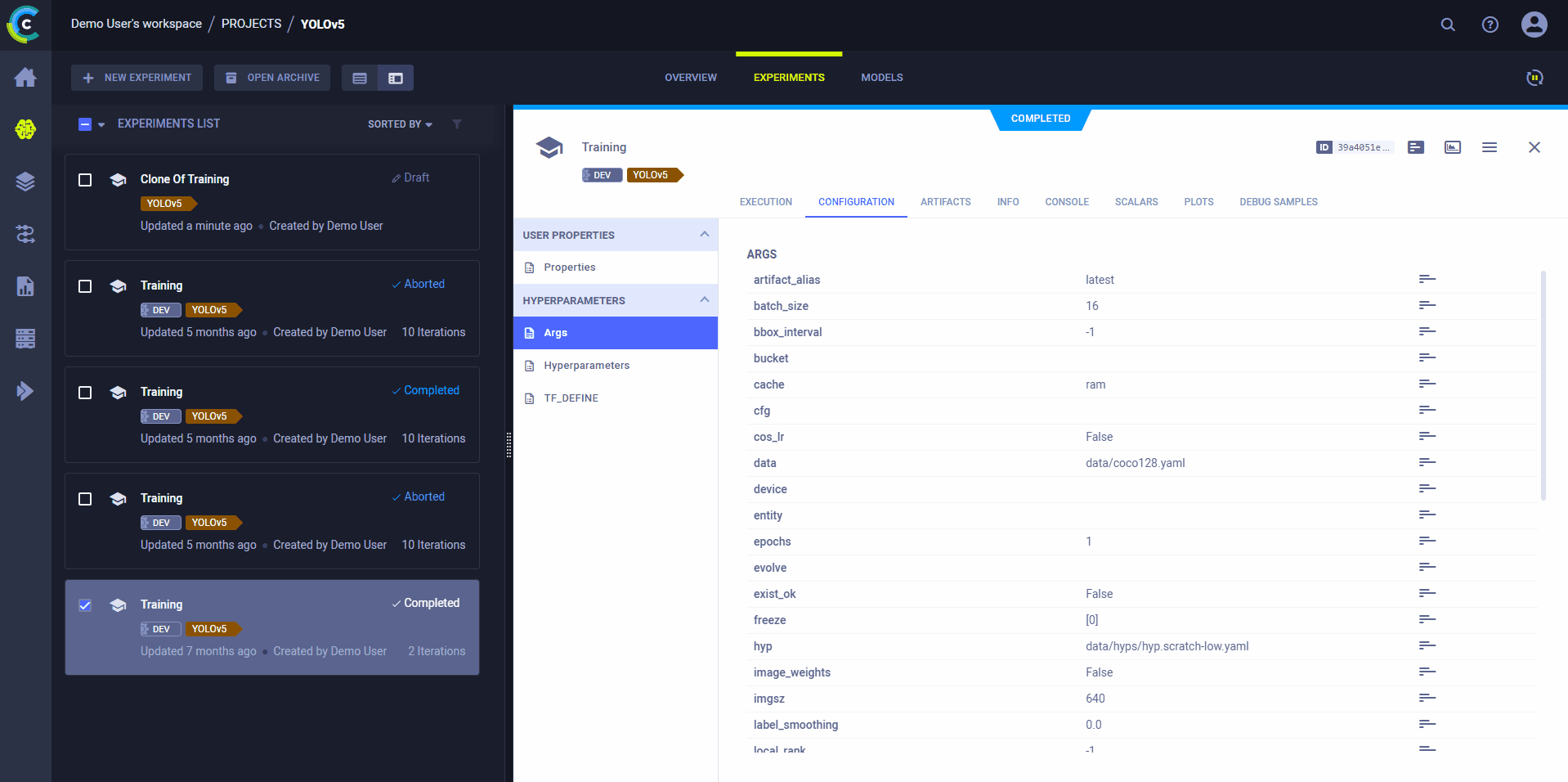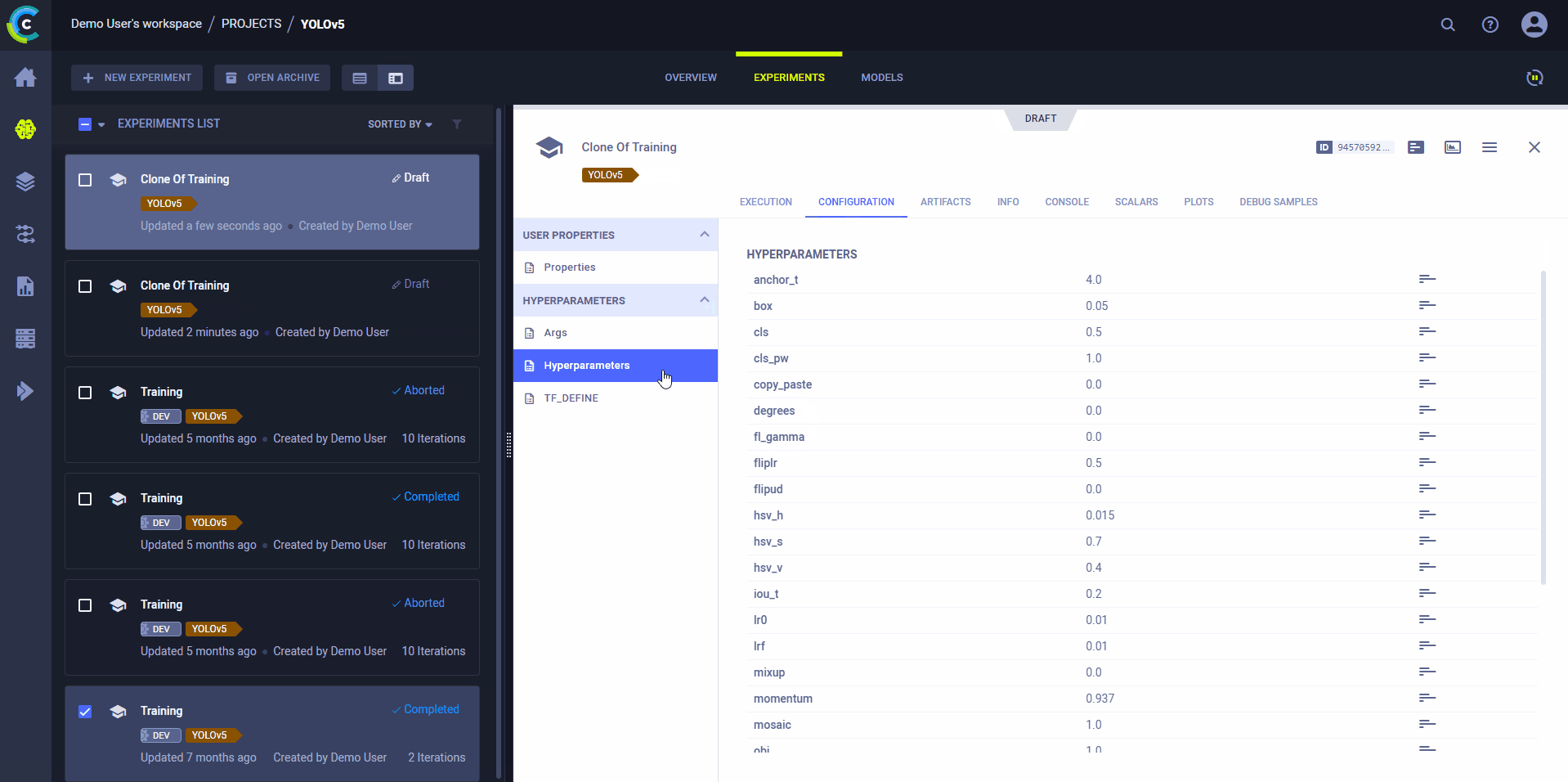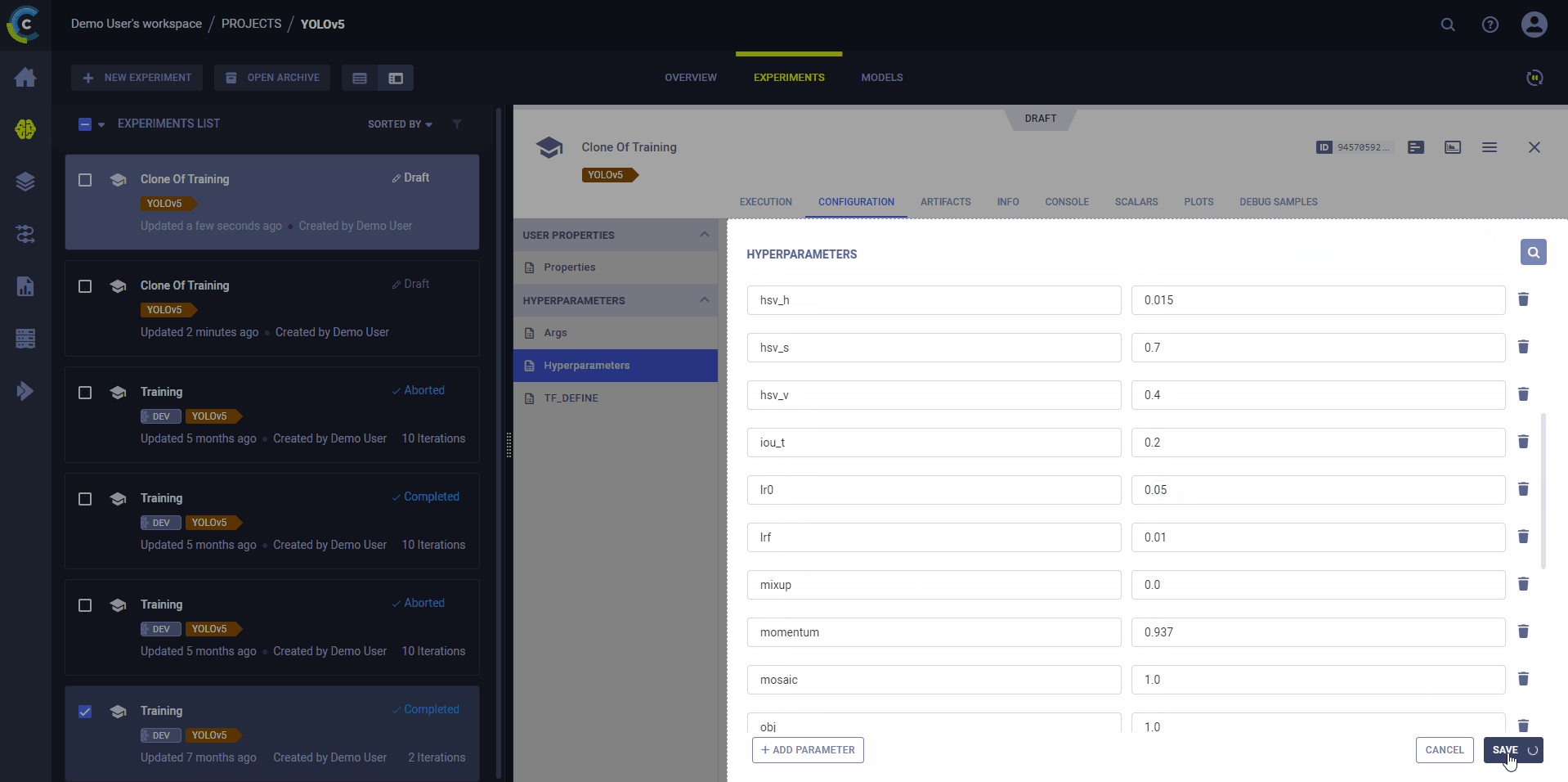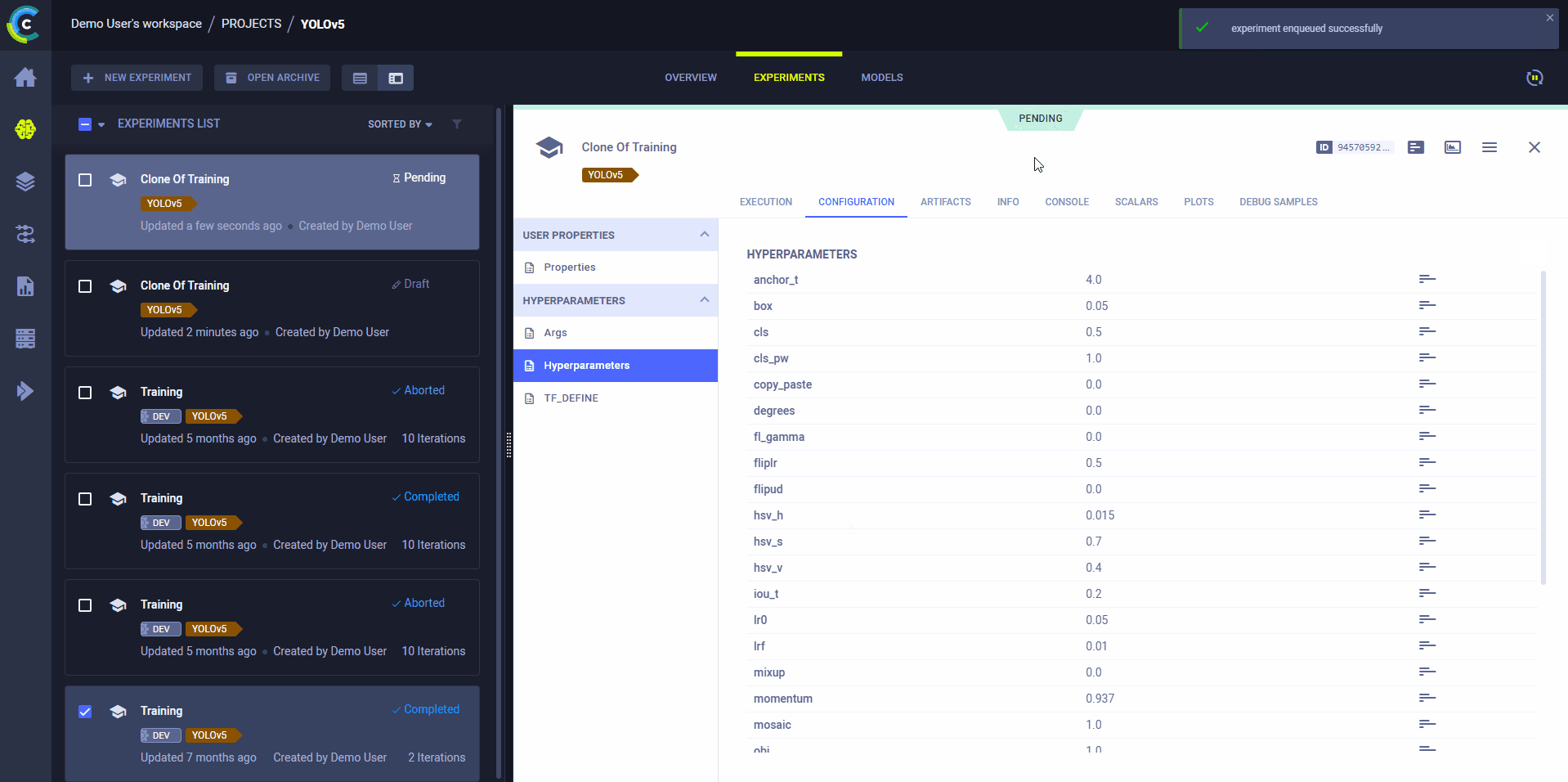
使用ClearML的网页界面编辑任务详情,如配置参数或输入模型,然后在远程机器上使用新配置执行任务:
- Clone Experiment
- Edit hyperparameters and/or other details
- 将任务加入队列
执行任务的ClearML代理将使用新值来覆盖任何硬编码的值。
超参数优化
使用ClearML的HyperParameterOptimizer类来找到产生最佳性能模型的超参数值。有关更多信息,请参阅超参数优化。