PipelineController
PipelineController 类
创建PipelineController,您将在其中定义管道的执行逻辑:
from clearml import PipelineController
pipe = PipelineController(
name="Pipeline Controller", project="Pipeline example", version="1.0.0"
)
name- 管道控制器任务的名称project- 将在其中创建管道任务的ClearML项目。version- 编号版本字符串(例如,1.2.3)。如果未设置,则查找管道的最新版本并递增。如果未找到此类版本,则默认为1.0.0
查看 PipelineController 以获取所有参数。
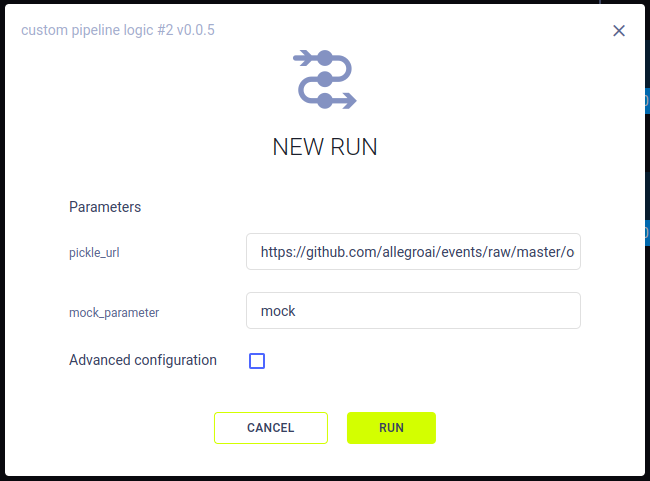
管道参数
您可以定义参数来控制不同的流水线运行:
pipe.add_parameter(
name='pickle_url',
description='url to pickle file',
default='https://github.com/allegroai/events/raw/master/odsc20-east/generic/iris_dataset.pkl'
)
name- 参数名称default- 参数的默认值(此值稍后可以在UI中更改)description- 参数的字符串描述及其在管道中的使用情况
这些参数可以使用以下格式以编程方式注入到步骤的配置中:"${pipeline.。
当从UI启动新的管道运行时,您可以修改新运行的值。
附加配置
您可以通过提供配置对象或文件路径,使用
PipelineController.connect_configuration()
将配置字典或文件连接到管道控制器。
对于文件,在读取配置文件之前调用connect_configuration()。如果是本地文件,输入相对路径。
config_file = pipe.connect_configuration(
configuration=config_file_path,
name="My Configuration",
description="configuration for pipeline"
)
my_params = json.load(open(config_file,'rt'))
您可以在流水线任务页面的配置选项卡中查看配置,具体位置在name参数指定的部分。
管道步骤
一旦你有了一个PipelineController对象,就可以向其中添加步骤。这些步骤可以是现有的ClearML任务或代码中的函数。当管道运行时,控制器将根据指定的结构启动这些步骤。
任务中的步骤
从现有的ClearML任务创建管道步骤意味着当步骤运行时,任务将被克隆,并通过配置的执行队列启动一个新任务(原始任务不会被修改)。新任务的参数可以指定。
任务步骤是通过使用PipelineController.add_step()添加的:
pipe.add_step(
name='stage_process',
parents=['stage_data', ],
base_task_project='examples',
base_task_name='pipeline step 2 process dataset',
parameter_override={
'General/dataset_url': '${stage_data.artifacts.dataset.url}',
'General/test_size': 0.25},
pre_execute_callback=pre_execute_callback_example,
post_execute_callback=post_execute_callback_example
)
name- 步骤的唯一名称。管道中的任何后续步骤都可以使用其名称引用此步骤。- 以下之一:
base_task_project和base_task_name- 要克隆的基础任务的项目和名称base_task_id- 要克隆的基础任务的ID
cache_executed_step– 如果为True,控制器将检查是否已经执行了具有相同代码(包括设置,例如所需的包、docker镜像等)和输入参数的相同任务。如果找到,则使用缓存的步骤输出,而不是启动新任务。execution_queue(可选)- 用于执行此特定步骤的队列。如果未提供,任务将被发送到默认的执行队列,如类中所定义。parents(可选)- 管道中父步骤的列表。只有在所有父步骤成功执行后,管道中的当前步骤才会被发送执行。parameter_override- 在当前步骤中覆盖参数和值的字典。参见 parameter_override。configuration_overrides- 在当前步骤中覆盖的配置对象和值的字典。参见 configuration_overrides。monitor_models,monitor_metrics,monitor_artifacts- 参见 这里.
请参阅 PipelineController.add_step 以获取所有参数。
参数覆盖
使用parameter_override参数来修改步骤的参数值。parameter_override字典的键是任务参数的完整路径,包括参数部分的名称和参数名称,用斜杠分隔(例如,'General/dataset_url')。在参数值中传递"${}"可以让你引用其他管道步骤的输入/输出配置。例如:"${将被转换为引用管道步骤的任务ID。
示例:
- 工件URL访问:
'${.artifacts. .url}' - 模型访问URL访问:
'${.models.output.-1.url}' - 不同的步骤参数访问:
'${.parameters.Args/input_file}' - 管道参数(请参阅添加管道参数):
'${pipeline.}'
配置覆盖
您可以通过传递配置对象内容的字符串表示或配置字典来覆盖步骤的配置对象。
示例:
- 配置字典:
configuration_overrides={"my_config": {"key": "value"}} - 配置文件:
configuration_overrides={"my_config": open("config.txt", "rt").read()}
函数中的步骤
从函数创建管道步骤意味着当调用该函数时,它将被转换为ClearML任务,将其参数转换为参数,并将返回值转换为工件。
在PipelineController的skip_global_imports参数设置为False的情况下,所有全局导入将在每个步骤执行开始时自动导入。否则,如果设置为True,请确保构成管道步骤的每个函数都包含包导入,这些导入将自动记录为管道执行步骤所需的包。
使用PipelineController.add_function_step()添加功能步骤:
pipe.add_function_step(
name='step_one',
function=step_one,
function_kwargs=dict(pickle_data_url='${pipeline.url}'),
function_return=['data_frame'],
cache_executed_step=True,
)
pipe.add_function_step(
name='step_two',
# parents=['step_one'], # the pipeline will automatically detect the dependencies based on the kwargs inputs
function=step_two,
function_kwargs=dict(data_frame='${step_one.data_frame}'),
function_return=['processed_data'],
cache_executed_step=True,
)
name- 管道步骤的名称。此名称可以在后续步骤中引用function- 一个全局函数,用作管道步骤,将被转换为独立任务function_kwargs(可选)- 一个函数参数和默认值的字典,这些参数和默认值会被转换为任务超参数。如果没有提供,所有函数参数都会被转换为超参数。function_return- 用于将流水线步骤返回的对象作为工件存储在其ClearML任务中的名称。cache_executed_step- 如果为True,控制器将检查是否已经执行了具有相同代码(包括设置,参见任务执行部分)和输入参数的相同任务。如果找到,则使用缓存的步骤输出,而不是启动新任务。parents(可选)- 管道中父步骤的列表。只有在所有父步骤成功执行后,管道中的当前步骤才会被发送执行。pre_execute_callback和post_execute_callback- 使用回调函数控制管道流程,这些回调函数可以在步骤执行之前和/或之后调用。参见这里。monitor_models,monitor_metrics,monitor_artifacts- 参见 这里.
请参阅 PipelineController.add_function_step 获取所有参数。
重要参数
pre_execute_callback 和 post_execute_callback
回调可以用来控制管道执行流程。
当步骤被创建时,并且在发送执行之前,会调用一个pre_execute_callback函数。这允许用户在启动前修改任务。使用node.job来访问ClearmlJob对象,或者使用node.job.task直接访问Task对象。参数是传递给ClearmlJob的配置参数。
如果回调返回值为False,则跳过该步骤,并且依赖于该步骤的管道中的任何步骤也会被跳过。
注意参数已经被解析(例如,${step1.parameters.Args/param} 被替换为相关值)。
def step_created_callback(
pipeline, # type: PipelineController,
node, # type: PipelineController.Node,
parameters, # type: dict
):
pass
当步骤完成时,会调用post_execute_callback函数。它允许您在完成后修改步骤的状态。
def step_completed_callback(
pipeline, # type: PipelineController,
node, # type: PipelineController.Node,
):
pass
模型、工件和指标
您可以使用以下参数启用步骤的指标/工件/模型到管道任务的自动记录:
monitor_metrics(可选)- 自动将步骤报告的指标也记录在管道任务上。预期的格式是以下之一:- 要记录的指标(标题,系列)对列表:[(step_metric_title,step_metric_series),]。示例:
[('test', 'accuracy'), ] - 元组对列表,用于指定在管道任务上使用的不同目标指标:[((step_metric_title,step_metric_series),(target_metric_title,target_metric_series)),]。示例:
[[('test', 'accuracy'), ('model', 'accuracy')], ]
- 要记录的指标(标题,系列)对列表:[(step_metric_title,step_metric_series),]。示例:
monitor_artifacts(可选)- 自动记录管道任务上的步骤工件。- 提供了由步骤函数创建的工件名称列表,这些工件也将自动记录在管道任务本身上。示例:
['processed_data', ](管道任务上的目标工件名称将与原始工件名称相同)。 - 或者,提供一对(source_artifact_name, target_artifact_name)的列表,其中第一个字符串是步骤任务上显示的工件名称,第二个是要放在管道任务上的目标工件名称。示例:
[('processed_data', 'final_processed_data'), ]
- 提供了由步骤函数创建的工件名称列表,这些工件也将自动记录在管道任务本身上。示例:
monitor_models(可选)- 自动记录管道任务中步骤的输出模型。- 提供由步骤任务创建的模型名称列表,它们也将出现在管道本身上。示例:
['model_weights', ] - 要选择最新的(字典序)模型,请使用
model_*,或使用*选择最后创建的模型。示例:['model_weights_*', ] - 或者,提供一对(source_model_name, target_model_name)的列表,其中第一个字符串是步骤任务上显示的模型名称,第二个是要放在管道任务上的目标模型名称。示例:
[('model_weights', 'final_model_weights'), ]
- 提供由步骤任务创建的模型名称列表,它们也将出现在管道本身上。示例:
你也可以直接从步骤上传模型或工件到管道控制器,使用
PipelineController.upload_model
和 PipelineController.upload_artifact
方法分别。
控制管道执行
默认执行队列
PipelineController.set_default_execution_queue
方法允许您设置一个默认队列,所有管道步骤都将通过该队列执行。一旦设置,可以通过PipelineController.add_step
或PipelineController.add_function_step
方法的execution_queue指定特定步骤的覆盖。
运行管道
使用以下方法之一运行管道:
PipelineController.start- 通过services队列启动管道控制器,除非另有指定。管道步骤会被排入它们各自的队列或默认的执行队列中。PipelineController.start_locally- 在本地启动管道控制器。要在本地运行管道步骤,请传递run_pipeline_steps_locally=True。