k均值#
- scipy.cluster.vq.kmeans(obs, k_or_guess, iter=20, thresh=1e-05, check_finite=True, *, seed=None)[源代码][源代码]#
对一组观测向量执行 k-means 聚类,形成 k 个簇。
k-means 算法通过调整观察值到聚类的分类并更新聚类中心,直到中心的位置在连续迭代中保持稳定。在此算法的实现中,中心点的稳定性是通过比较观察值与其对应中心点之间的平均欧几里得距离变化的绝对值与阈值来确定的。这产生了一个代码本,将中心点映射到代码,反之亦然。
- 参数:
- obsndarray
M by N 数组的每一行是一个观测向量。列是每次观测时看到的特征。特征必须首先使用
whiten函数进行白化处理。- k_or_guessint 或 ndarray
要生成的质心数量。每个质心被分配一个代码,该代码也是生成的 code_book 矩阵中质心的行索引。
最初的 k 个质心是通过从观测矩阵中随机选择观测值来选择的。或者,传递一个 k 行 N 列的数组可以指定最初的 k 个质心。
- iterint, 可选
运行 k-means 的次数,返回具有最低失真的码本。如果使用
k_or_guess参数的数组指定了初始中心点,则忽略此参数。此参数不代表 k-means 算法的迭代次数。- threshfloat, 可选
如果自上次k-means迭代以来失真的变化小于或等于阈值,则终止k-means算法。
- check_finitebool, 可选
是否检查输入矩阵是否仅包含有限数值。禁用可能会提高性能,但如果输入包含无穷大或NaN,可能会导致问题(崩溃、非终止)。默认值:True
- seed : {None, int,
numpy.random.Generator,numpy.random.RandomState}, 可选{None, int,} 用于初始化伪随机数生成器的种子。如果 seed 为 None(或
numpy.random),则使用numpy.random.RandomState单例。如果 seed 是整数,则使用新的RandomState实例,并以 seed 为种子。如果 seed 已经是Generator或RandomState实例,则使用该实例。默认值为 None。
- 返回:
- 代码簿ndarray
一个 k 乘 N 的质心数组。第 i 个质心 codebook[i] 用代码 i 表示。生成的质心和代码代表了所见到的最低失真,不一定是全局最小失真。注意,质心的数量不一定与
k_or_guess参数相同,因为在迭代过程中,分配给无观察值的质心会被移除。- 失真浮动
观测值与生成的质心之间的平均(非平方)欧几里得距离。注意这与k-means算法上下文中失真的标准定义的区别,后者是平方距离的总和。
注释
为了更多功能或最佳性能,您可以使用 sklearn.cluster.KMeans。这个 是几个实现的基准测试结果。
示例
>>> import numpy as np >>> from scipy.cluster.vq import vq, kmeans, whiten >>> import matplotlib.pyplot as plt >>> features = np.array([[ 1.9,2.3], ... [ 1.5,2.5], ... [ 0.8,0.6], ... [ 0.4,1.8], ... [ 0.1,0.1], ... [ 0.2,1.8], ... [ 2.0,0.5], ... [ 0.3,1.5], ... [ 1.0,1.0]]) >>> whitened = whiten(features) >>> book = np.array((whitened[0],whitened[2])) >>> kmeans(whitened,book) (array([[ 2.3110306 , 2.86287398], # random [ 0.93218041, 1.24398691]]), 0.85684700941625547)
>>> codes = 3 >>> kmeans(whitened,codes) (array([[ 2.3110306 , 2.86287398], # random [ 1.32544402, 0.65607529], [ 0.40782893, 2.02786907]]), 0.5196582527686241)
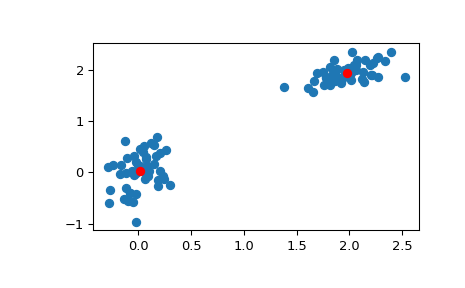
>>> # Create 50 datapoints in two clusters a and b >>> pts = 50 >>> rng = np.random.default_rng() >>> a = rng.multivariate_normal([0, 0], [[4, 1], [1, 4]], size=pts) >>> b = rng.multivariate_normal([30, 10], ... [[10, 2], [2, 1]], ... size=pts) >>> features = np.concatenate((a, b)) >>> # Whiten data >>> whitened = whiten(features) >>> # Find 2 clusters in the data >>> codebook, distortion = kmeans(whitened, 2) >>> # Plot whitened data and cluster centers in red >>> plt.scatter(whitened[:, 0], whitened[:, 1]) >>> plt.scatter(codebook[:, 0], codebook[:, 1], c='r') >>> plt.show()