peak_prominences#
- scipy.signal.peak_prominences(x, peaks, wlen=None)[源代码][源代码]#
计算信号中每个峰值的突出度。
山峰的显著性衡量了山峰从信号的周围基线中脱颖而出的程度,并定义为山峰与其最低等高线之间的垂直距离。
- 参数:
- x序列
一个带有峰值的信号。
- 峰序列
x 中峰值的索引。
- wlenint, 可选
一个以样本为单位的窗口长度,可选地限制每个峰值的评估区域为 x 的子集。峰值总是位于窗口的中间,因此给定的长度向上舍入到下一个奇数整数。此参数可以加快计算速度(参见注释)。
- 返回:
- 突出部分ndarray
peaks 中每个峰的计算突出度。
- 左基, 右基ndarray
在 x 中,每个峰值左右两侧的峰值基底作为索引。每对基底中较高的那个是峰值的最低等高线。
- Raises:
- ValueError
如果 peaks 中的值是 x 的一个无效索引。
- 警告:
- PeakPropertyWarning
对于 peaks 中未指向 x 中有效局部最大值的索引,返回的突出度将为 0,并会引发此警告。如果 wlen 小于峰值的平坦区域大小,也会发生这种情况。
警告
对于包含 NaN 的数据,此函数可能会返回意外结果。为了避免这种情况,应删除或替换 NaN。
参见
find_peaks根据峰值属性在信号内寻找峰值。
peak_widths计算峰的宽度。
注释
计算峰突出度的策略:
从当前峰值向左和向右延伸一条水平线,直到该线到达窗口边界(参见 wlen)或在与更高峰值的斜率处再次与信号相交。与相同高度的峰值的交点将被忽略。
在上述定义的区间内,找到每一侧的最小信号值。这些点是峰值的基点。
两个基点中较高的一个标记了山峰的最低等高线。然后,突出度可以计算为山峰本身高度与其最低等高线之间的垂直差异。
对于具有周期行为的大型 x,寻找峰值基底可能会很慢,因为在算法的第一个步骤中需要评估大块甚至整个信号。可以通过参数 wlen 限制评估区域,该参数将算法限制在当前峰值周围的窗口内,如果窗口长度相对于 x 较短,则可以缩短计算时间。然而,如果峰值的真实基底在此窗口之外,这可能会阻止算法找到真正的全局等高线,而是在受限窗口内找到更高的等高线,从而导致计算出的突出度较小。在实践中,这仅对 x 中最高的一组峰值相关。这种行为甚至可以有意用于计算“局部”突出度。
Added in version 1.1.0.
参考文献
[1]维基百科关于地形突出的文章:https://en.wikipedia.org/wiki/Topographic_prominence
示例
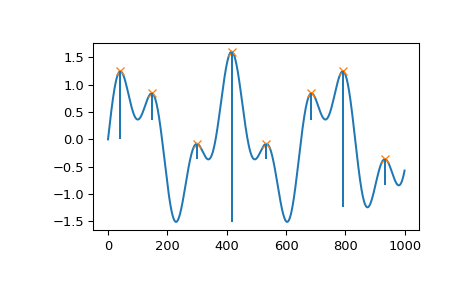
>>> import numpy as np >>> from scipy.signal import find_peaks, peak_prominences >>> import matplotlib.pyplot as plt
创建一个包含两个叠加谐波的测试信号
>>> x = np.linspace(0, 6 * np.pi, 1000) >>> x = np.sin(x) + 0.6 * np.sin(2.6 * x)
查找所有峰值并计算突出度
>>> peaks, _ = find_peaks(x) >>> prominences = peak_prominences(x, peaks)[0] >>> prominences array([1.24159486, 0.47840168, 0.28470524, 3.10716793, 0.284603 , 0.47822491, 2.48340261, 0.47822491])
计算每个峰值的等高线高度并绘制结果
>>> contour_heights = x[peaks] - prominences >>> plt.plot(x) >>> plt.plot(peaks, x[peaks], "x") >>> plt.vlines(x=peaks, ymin=contour_heights, ymax=x[peaks]) >>> plt.show()
让我们评估第二个示例,该示例展示了索引5处一个峰值的几个边缘情况。
>>> x = np.array([0, 1, 0, 3, 1, 3, 0, 4, 0]) >>> peaks = np.array([5]) >>> plt.plot(x) >>> plt.plot(peaks, x[peaks], "x") >>> plt.show()
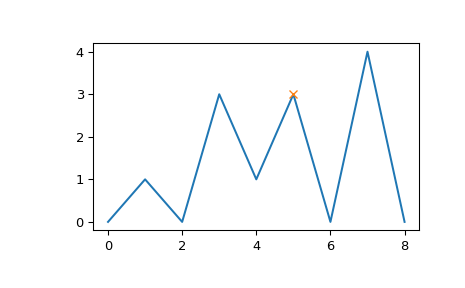
>>> peak_prominences(x, peaks) # -> (prominences, left_bases, right_bases) (array([3.]), array([2]), array([6]))
注意在搜索左基线时,索引3处相同高度的峰值不被视为边界。相反,找到了两个最小值0和2,在这种情况下,总是选择离评估峰值更近的那个。然而,在右侧,基线必须放在6处,因为更高的峰值代表了评估区域的右边界。
>>> peak_prominences(x, peaks, wlen=3.1) (array([2.]), array([4]), array([6]))
在这里,我们将算法限制在3到7的窗口内(长度为5个样本,因为`wlen`被向上取整到下一个奇数)。因此,评估区域内只有两个相邻样本是候选者,并且计算出的突出度较小。