scipy.stats.
gzscore#
- scipy.stats.gzscore(a, *, axis=0, ddof=0, nan_policy='propagate')[源代码][源代码]#
计算几何标准分数。
计算样本中每个严格正值的几何z分数,相对于几何平均值和标准差。从数学上讲,几何z分数可以评估为:
gzscore = log(a/gmu) / log(gsigma)
其中
gmu``(对应 ``gsigma)是几何平均值(对应标准差)。- 参数:
- aarray_like
示例数据。
- 轴int 或 None, 可选
操作所沿的轴。默认值为0。如果为None,则在整个数组 a 上进行计算。
- ddofint, 可选
在计算标准差时对自由度的修正。默认值为 0。
- nan_policy{‘propagate’, ‘raise’, ‘omit’}, 可选
定义了当输入包含 nan 时的处理方式。’propagate’ 返回 nan,’raise’ 抛出错误,’omit’ 忽略 nan 值进行计算。默认是 ‘propagate’。注意,当值为 ‘omit’ 时,输入中的 nan 也会传播到输出中,但它们不会影响为非 nan 值计算的几何 z 分数。
- 返回:
- gzscorearray_like
几何Z分数,由输入数组 a 的几何平均值和几何标准差标准化。
注释
此函数保留了 ndarray 子类,并且也适用于矩阵和掩码数组(它使用
asanyarray而不是asarray作为参数)。Added in version 1.8.
参考文献
示例
从对数正态分布中抽取样本:
>>> import numpy as np >>> from scipy.stats import zscore, gzscore >>> import matplotlib.pyplot as plt
>>> rng = np.random.default_rng() >>> mu, sigma = 3., 1. # mean and standard deviation >>> x = rng.lognormal(mu, sigma, size=500)
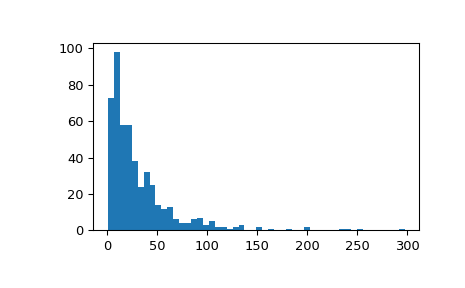
显示样本的直方图:
>>> fig, ax = plt.subplots() >>> ax.hist(x, 50) >>> plt.show()
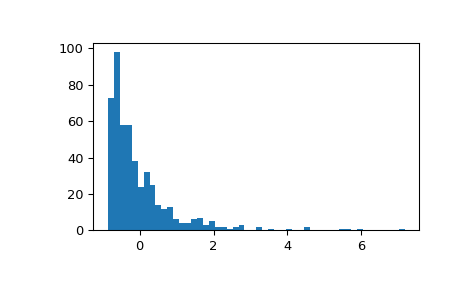
显示通过经典 zscore 标准化的样本的直方图。分布被重新缩放,但其形状保持不变。
>>> fig, ax = plt.subplots() >>> ax.hist(zscore(x), 50) >>> plt.show()
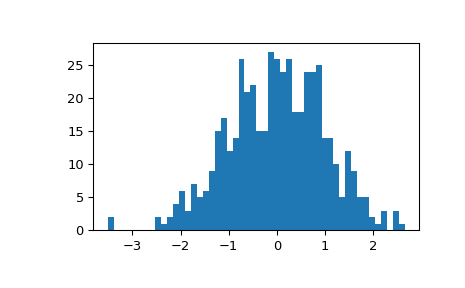
展示几何z分数的分布被重新调整并接近正态分布:
>>> fig, ax = plt.subplots() >>> ax.hist(gzscore(x), 50) >>> plt.show()