NumericalInverseHermite#
- class scipy.stats.sampling.NumericalInverseHermite(dist, *, domain=None, order=3, u_resolution=1e-12, construction_points=None, random_state=None)#
基于Hermite插值的CDF逆变换(HINV)。
HINV 是数值反演的一种变体,其中逆CDF通过Hermite插值近似,即区间[0,1]被分割成若干区间,并且在每个区间内,逆CDF通过在区间边界上的CDF和PDF值构造的多项式来近似。这使得通过分割特定区间来提高精度成为可能,而无需重新计算不受影响的区间。实现了三种类型的样条:线性、三次和五次插值。对于线性插值,仅需要CDF。三次插值还需要PDF,五次插值则需要PDF及其导数。
这些样条必须在设置步骤中计算。然而,它仅适用于具有有界域的分布;对于具有无界域的分布,尾部会被截断,使得尾部区域的概率与给定的u分辨率相比很小。
该方法并不精确,因为它仅生成近似分布的随机变量。尽管如此,在“u方向”上的最大数值误差(即
|U - CDF(X)|,其中X是与分位数U对应的近似百分位数,即X = approx_ppf(U))可以设置为所需的分辨率(在机器精度范围内)。请注意,非常小的 u-分辨率值是可能的,但可能会增加设置步骤的成本。- 参数:
- dist对象
一个具有
cdf方法的类实例,以及可选的pdf和dpdf方法。cdf: 分布的累积分布函数(CDF)。CDF 的签名应为:def cdf(self, x: float) -> float。即,CDF 应接受一个 Python float 并返回一个 Python float。pdf: 分布的PDF。当order=1时,此方法是可选的。必须具有与PDF相同的签名。dpdf: 相对于变量(即x)的 PDF 导数。此方法是可选的,当order=1或order=3时。必须具有与 CDF 相同的签名。
- 领域长度为2的列表或元组,可选
对分布的支持。默认是
None。当None时:如果分布对象 dist 提供了
support方法,它将用于设置分布的域。否则,支持集被假定为 \((-\infty, \infty)\)。
- order : int, 默认值:
3int, 默认值: 设置Hermite插值的顺序。有效的顺序是1、3和5。请注意,大于1的顺序需要分布的密度,而大于3的顺序甚至需要密度的导数。使用顺序1会导致大多数分布的区间数量巨大,因此不推荐。如果u方向的最大误差非常小(例如小于1.e-10),建议使用顺序5,因为它会显著减少设计点的数量,只要没有极点或重尾。
- u_resolution : float, 默认值:
1e-12浮点数,默认值: 设置最大容忍的 u 误差。注意,大多数均匀随机数源的分辨率为 2-32= 2.3e-10。因此,1.e-10 的值会导致一个可以称为精确的反演算法。对于大多数模拟,稍微大一点的值对于最大误差也是足够的。默认值为 1e-12。
- 建设点类似数组, 可选
设置Hermite插值的起始构造点(节点)。由于在设置中只能估计最大可能误差,因此可能需要为计算Hermite插值设置一些特殊的设计点,以确保最大u误差不会超过预期。这些点是密度不可微或具有局部极值的点。
- random_state{None, int,}
用于生成均匀随机数流的底层 NumPy 随机数生成器的 NumPy 随机数生成器或种子。如果 random_state 是 None(或 np.random),则使用
numpy.random.RandomState单例。如果 random_state 是整数,则使用一个新的RandomState实例,并以 random_state 为种子。如果 random_state 已经是Generator或RandomState实例,则使用该实例。
- 属性:
intervals获取生成器对象中用于Hermite插值的节点(设计点)数量。
- 中点误差
方法
ppf(u)给定分布的近似PPF。
qrvs([size, d, qmc_engine])给定随机变量的拟随机变量。
rvs([size, random_state])来自发行版的示例。
set_random_state([random_state])设置底层均匀随机数生成器。
u_error([sample_size])使用蒙特卡罗模拟估计近似的u误差。
注释
NumericalInverseHermite使用 Hermite 样条近似连续统计分布的 CDF 的逆。Hermite 样条的阶数可以通过传递 order 参数来指定。如 [1] 所述,它首先在分布的支持范围内对一组分位数
x处的分布的 PDF 和 CDF 进行评估。它使用这些结果来拟合一个 Hermite 样条H,使得H(p) == x,其中p是与分位数x对应的分位数数组。因此,样条在分位数p处近似于分布的 CDF 的逆函数,达到机器精度,但在分位数点之间的中点处,样条通常不会那么精确:p_mid = (p[:-1] + p[1:])/2
因此,根据需要细化分位数网格以减少最大“u-误差”:
u_error = np.max(np.abs(dist.cdf(H(p_mid)) - p_mid))
在指定的容差 u_resolution 以下。当达到所需的容差或下一次细化后的网格间隔数可能超过允许的最大间隔数(即100000)时,细化停止。
参考文献
[1]Hörmann, Wolfgang, 和 Josef Leydold. “通过快速数值反演生成连续随机变量.” ACM 建模与计算机模拟交易 (TOMACS) 13.4 (2003): 347-362.
[2]UNU.RAN 参考手册, 第5.3.5节, “HINV - 基于Hermite插值的CDF反演”, https://statmath.wu.ac.at/software/unuran/doc/unuran.html#HINV
示例
>>> from scipy.stats.sampling import NumericalInverseHermite >>> from scipy.stats import norm, genexpon >>> from scipy.special import ndtr >>> import numpy as np
要创建一个从标准正态分布中采样的生成器,请执行以下操作:
>>> class StandardNormal: ... def pdf(self, x): ... return 1/np.sqrt(2*np.pi) * np.exp(-x**2 / 2) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInverseHermite(dist, random_state=urng)
NumericalInverseHermite有一个方法可以近似分布的分位点函数(PPF)。>>> rng = NumericalInverseHermite(dist) >>> p = np.linspace(0.01, 0.99, 99) # percentiles from 1% to 99% >>> np.allclose(rng.ppf(p), norm.ppf(p)) True
根据分布的随机抽样方法的实现,在相同的随机状态下,生成的随机变量可能几乎相同。
>>> dist = genexpon(9, 16, 3) >>> rng = NumericalInverseHermite(dist) >>> # `seed` ensures identical random streams are used by each `rvs` method >>> seed = 500072020 >>> rvs1 = dist.rvs(size=100, random_state=np.random.default_rng(seed)) >>> rvs2 = rng.rvs(size=100, random_state=np.random.default_rng(seed)) >>> np.allclose(rvs1, rvs2) True
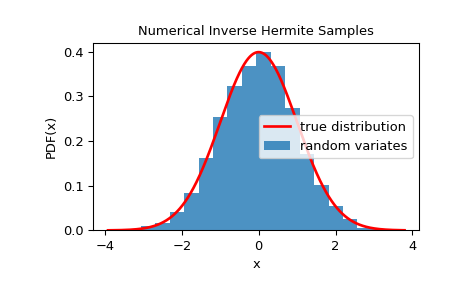
为了检查随机变量是否紧密遵循给定的分布,我们可以查看其直方图:
>>> import matplotlib.pyplot as plt >>> dist = StandardNormal() >>> rng = NumericalInverseHermite(dist) >>> rvs = rng.rvs(10000) >>> x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, 1000) >>> fx = norm.pdf(x) >>> plt.plot(x, fx, 'r-', lw=2, label='true distribution') >>> plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates') >>> plt.xlabel('x') >>> plt.ylabel('PDF(x)') >>> plt.title('Numerical Inverse Hermite Samples') >>> plt.legend() >>> plt.show()
给定关于变量(即
x)的PDF的导数,我们可以通过传递 order 参数使用五次Hermite插值来近似PPF:>>> class StandardNormal: ... def pdf(self, x): ... return 1/np.sqrt(2*np.pi) * np.exp(-x**2 / 2) ... def dpdf(self, x): ... return -1/np.sqrt(2*np.pi) * x * np.exp(-x**2 / 2) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInverseHermite(dist, order=5, random_state=urng)
高阶结果导致更少的区间数:
>>> rng3 = NumericalInverseHermite(dist, order=3) >>> rng5 = NumericalInverseHermite(dist, order=5) >>> rng3.intervals, rng5.intervals (3000, 522)
可以通过调用 u_error 方法来估计 u-error。它运行一个小型的蒙特卡罗模拟来估计 u-error。默认情况下,使用 100,000 个样本。这可以通过传递 sample_size 参数来更改:
>>> rng1 = NumericalInverseHermite(dist, u_resolution=1e-10) >>> rng1.u_error(sample_size=1000000) # uses one million samples UError(max_error=9.53167544892608e-11, mean_absolute_error=2.2450136432146864e-11)
这将返回一个包含最大 u-误差和平均绝对 u-误差的命名元组。
通过降低 u-resolution(最大允许的 u-error)可以减少 u-error。
>>> rng2 = NumericalInverseHermite(dist, u_resolution=1e-13) >>> rng2.u_error(sample_size=1000000) UError(max_error=9.32027892364129e-14, mean_absolute_error=1.5194172675685075e-14)
请注意,这会增加设置时间和间隔数量。
>>> rng1.intervals 1022 >>> rng2.intervals 5687 >>> from timeit import timeit >>> f = lambda: NumericalInverseHermite(dist, u_resolution=1e-10) >>> timeit(f, number=1) 0.017409582000254886 # may vary >>> f = lambda: NumericalInverseHermite(dist, u_resolution=1e-13) >>> timeit(f, number=1) 0.08671202100003939 # may vary
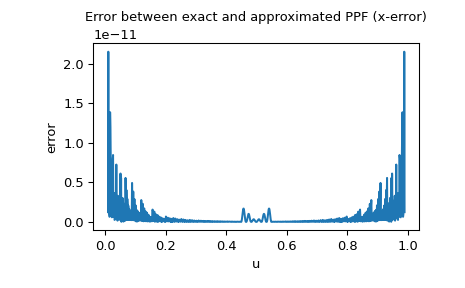
由于正态分布的PPF(百分点函数)可以作为特殊函数使用,我们也可以检查x误差,即近似PPF与精确PPF之间的差异:
>>> import matplotlib.pyplot as plt >>> u = np.linspace(0.01, 0.99, 1000) >>> approxppf = rng.ppf(u) >>> exactppf = norm.ppf(u) >>> error = np.abs(exactppf - approxppf) >>> plt.plot(u, error) >>> plt.xlabel('u') >>> plt.ylabel('error') >>> plt.title('Error between exact and approximated PPF (x-error)') >>> plt.show()