Flan
有什么新内容?
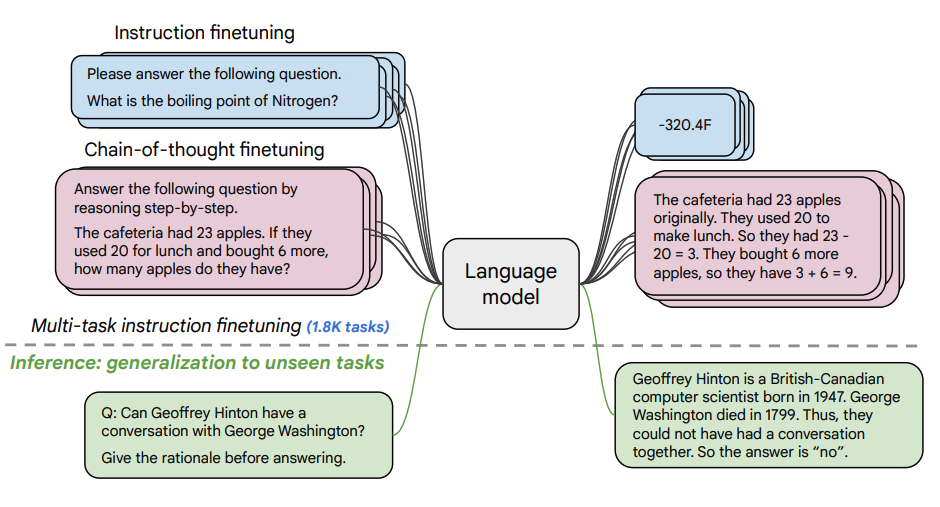 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
本文探讨了缩放指导微调的好处,以及它如何提高各种模型(PaLM,T5)、提示设置(零短,少短,CoT)和基准(MMLU,TyDiQA)上的性能。这是通过以下方面探讨的:扩展任务数量(1.8K 任务)、扩展模型大小,以及在思维链数据上微调(使用了 9 个数据集)。
微调过程:
- 1.8K 任务被表述为指导,并用于微调模型
- 同时使用有和无范例,以及有和无 CoT
微调任务和保留任务如下所示:
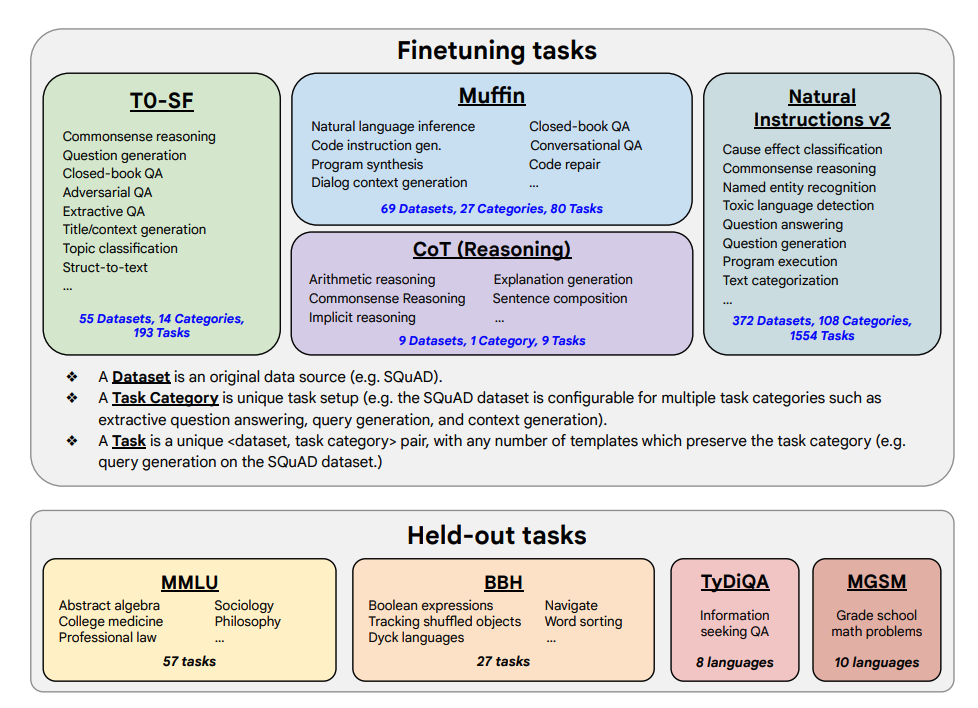
能力和关键结果
- 指导微调随着任务数量和模型大小的增加而扩展良好;这表明需要进一步扩展任务数量和模型大小
- 将 CoT 数据集添加到微调中可在推理任务上获得良好表现
- Flan-PaLM 提高了多语言能力;在一次性 TyDiQA 上提高了 14.9%;在代表性较低的语言中的算术推理上提高了 8.1%
- Plan-PaLM 在开放式生成问题上表现良好,这是改进可用性的良好指标
- 改进了负责任 AI(RAI)基准上的性能
- Flan-T5 指导微调模型展现出强大的少短能力,并优于 T5 等公共检查点
当扩展微调任务数量和模型大小时的结果: 预计扩展模型大小和微调任务数量将继续改善性能,尽管扩展任务数量的效益递减。
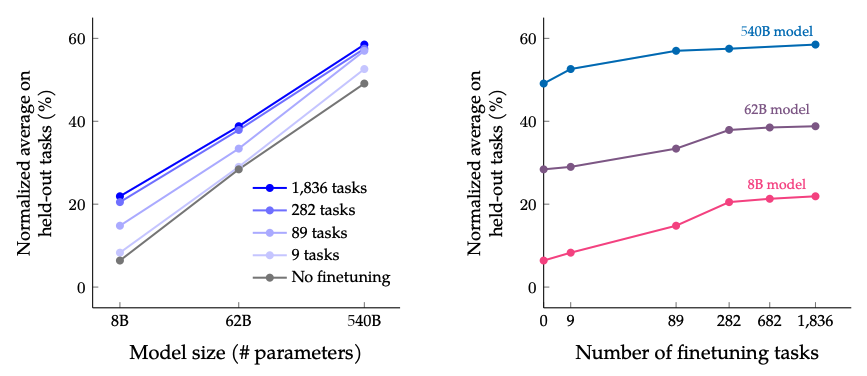 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
在非 CoT 和 CoT 数据上微调时的结果: 在非 CoT 和 CoT 数据上联合微调可以改善两者的评估表现,相较于只微调其中一个。
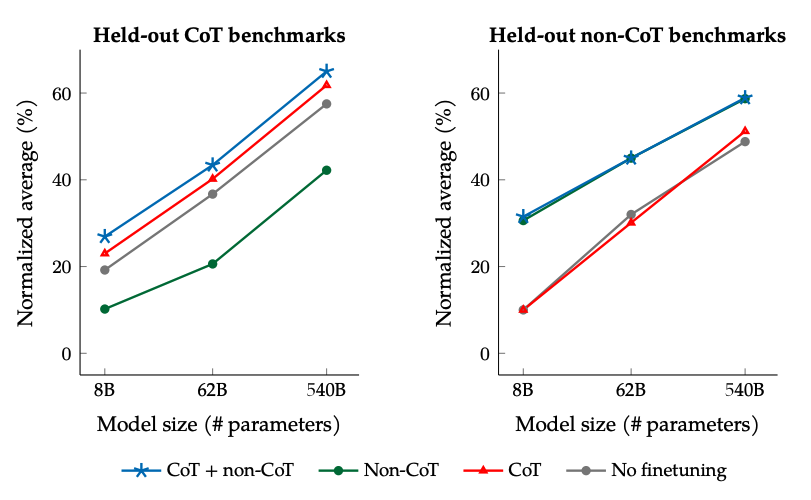 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
此外,自一致性结合 CoT 在几个基准上取得了最先进的结果。CoT + 自一致性还显著改善了涉及数学问题的基准结果(例如 MGSM,GSM8K)。
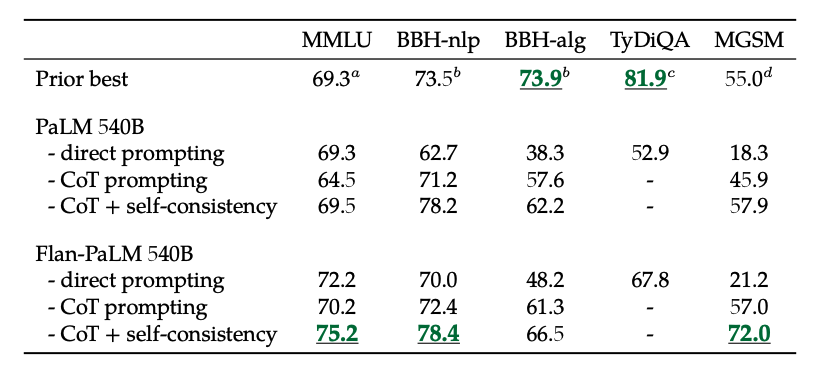 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
CoT 微调在 BIG-Bench 任务上通过短语“让我们逐步思考”激活了零短推理。总体而言,零短 CoT Flan-PaLM 在没有微调的情况下优于零短 CoT PaLM。
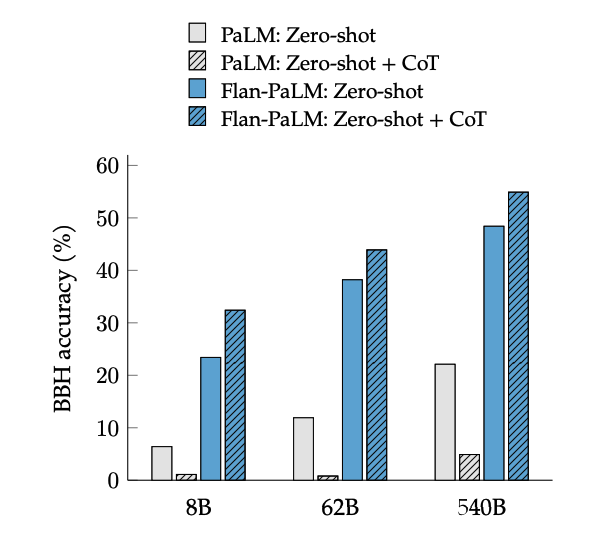 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
以下是一些展示了 PaLM 和 Flan-PaLM 在未知任务上的零短 CoT 的演示。
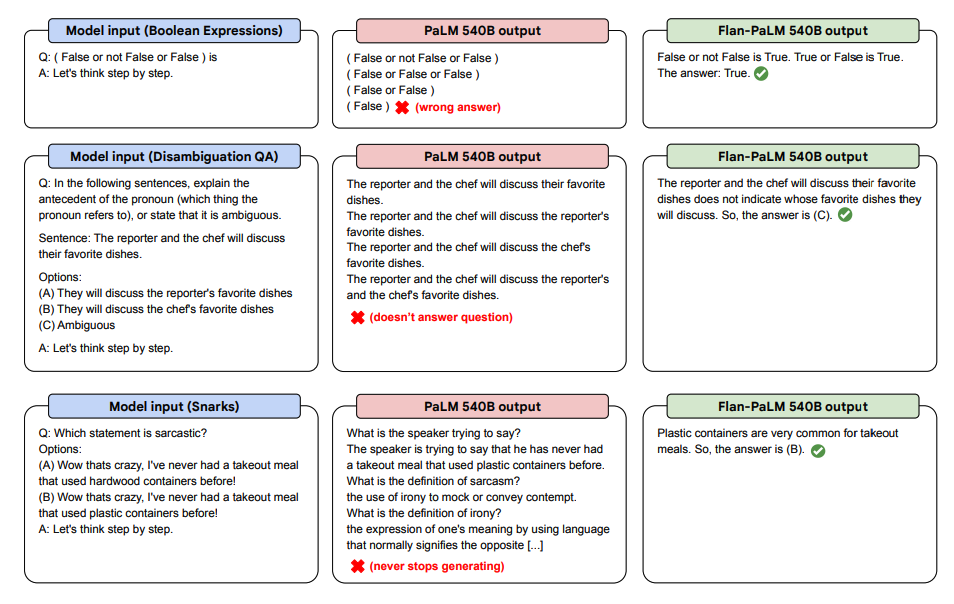 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
以下是更多关于零短提示的示例。它展示了 PaLM 模型在零短设置中对重复和不回复指令的困难,而 Flan-PaLM 能够表现良好。少量范例可以减轻这些错误。
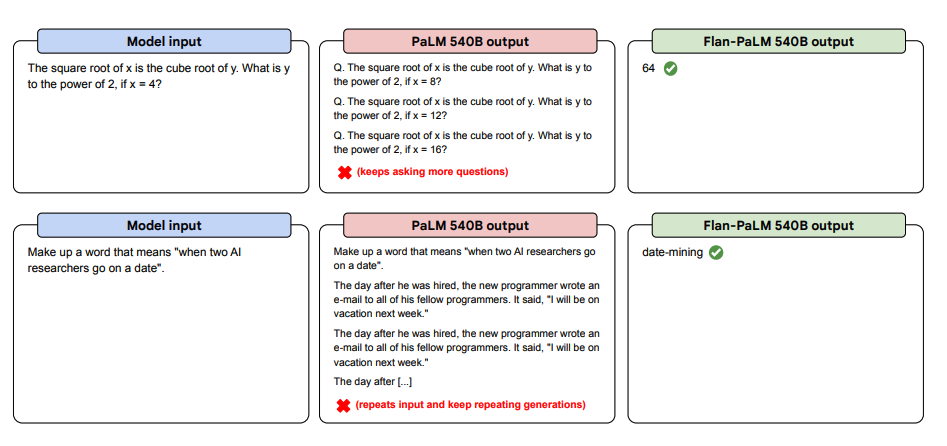 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
以下是一些展示了 Flan-PALM 模型在几种不同类型具有挑战性的开放式问题上的零短能力的示例:
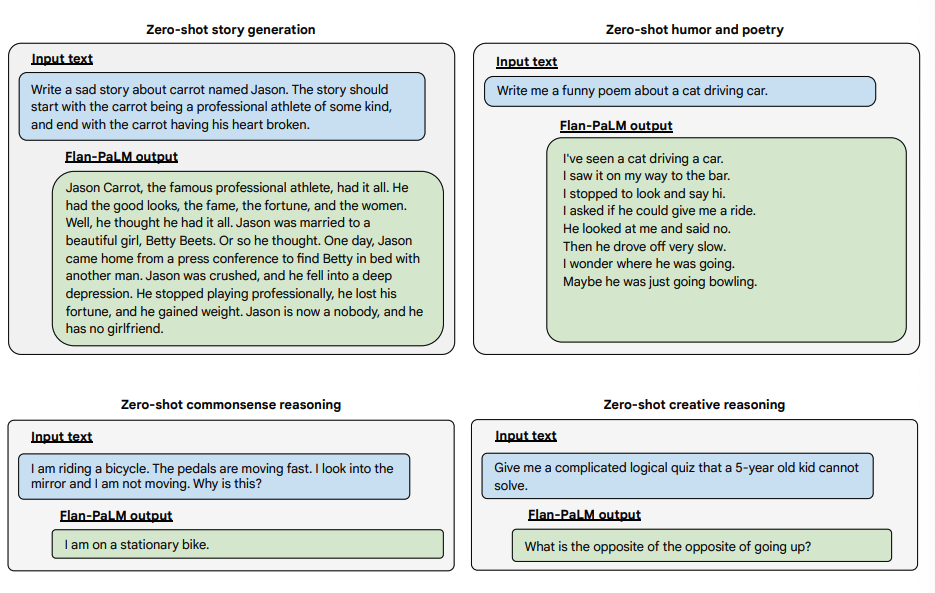 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
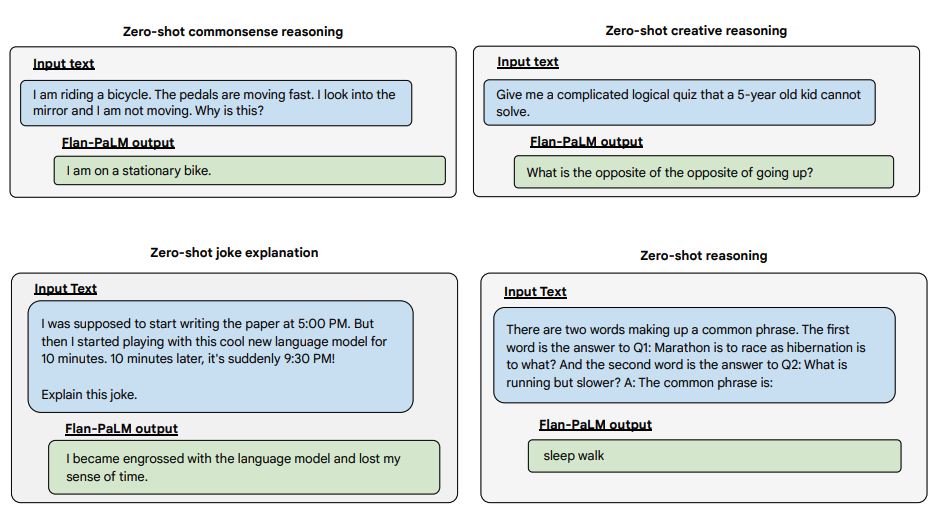 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型
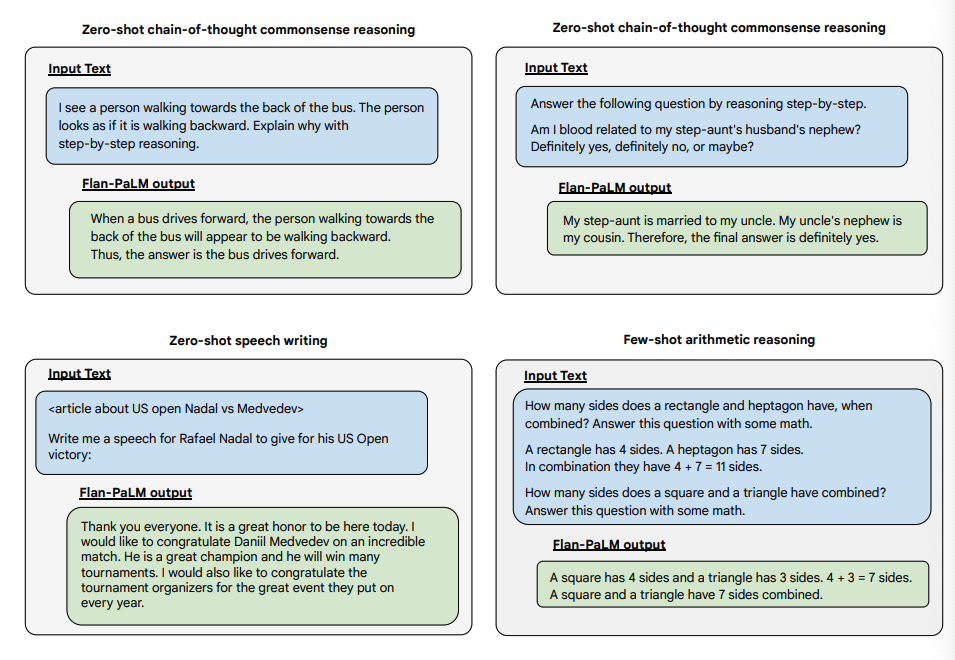 图片来源:缩放指导微调语言模型
图片来源:缩放指导微调语言模型