llama
LLaMA:开放高效的基础语言模型
有什么新内容?
本文介绍了一系列参数从7B到65B不等的基础语言模型。
这些模型是在公开可用的数据集上训练的,总共训练了数万亿个标记。
(Hoffman等人,2022) 的研究表明,在给定较小的计算预算的情况下,训练在更多数据上的较小模型可以比较大的模型获得更好的性能。该研究建议在200B标记上训练10B模型。然而,LLaMA论文发现,即使在1T标记之后,7B模型的性能仍在持续提升。
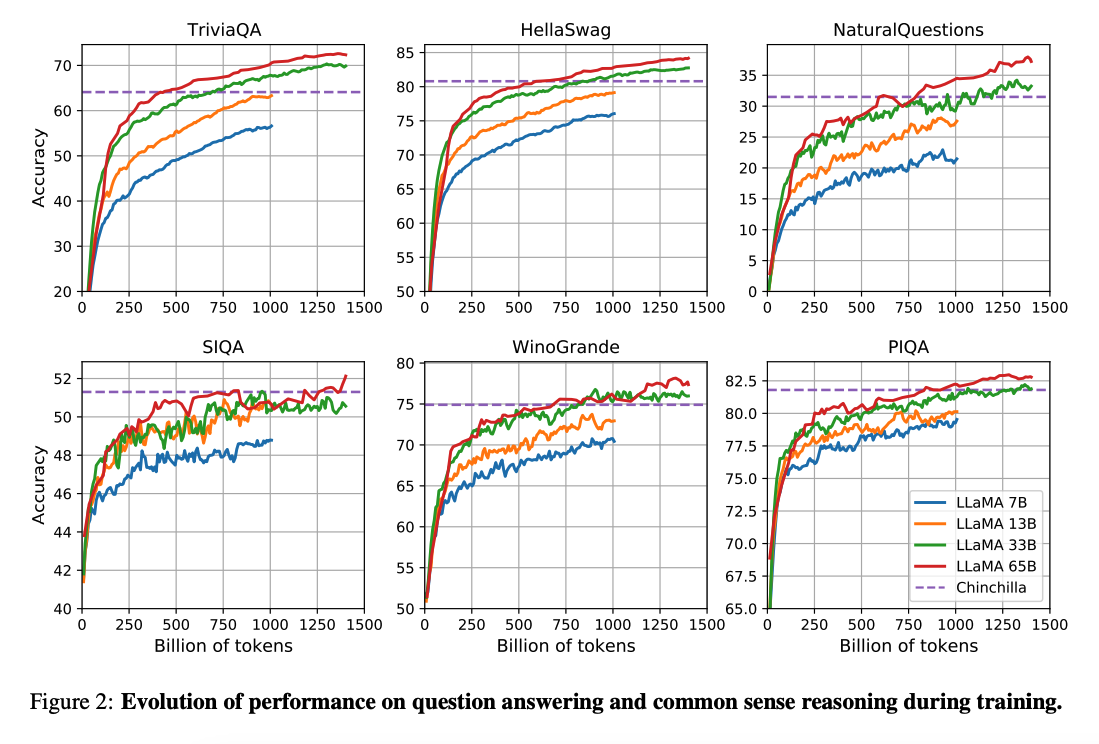
本研究专注于训练模型(LLaMA),通过在更多标记上训练,实现在各种推理预算下获得最佳性能。
能力与关键结果
总体而言,LLaMA-13B在许多基准测试中表现优于GPT-3(175B),尽管体积小了10倍,而且可以在单个GPU上运行。LLaMA 65B与Chinchilla-70B和PaLM-540B等模型竞争力相当。
代码: https://github.com/facebookresearch/llama
参考文献
- Koala:用于学术研究的对话模型(2023年4月)
- Baize:一种在自我对话数据上进行参数高效调整的开源聊天模型(2023年4月)
- Vicuna:一款印象深刻的开源聊天机器人,以90%*的ChatGPT质量打动了GPT-4(2023年3月)
- LLaMA-Adapter:使用零初始化注意力进行语言模型的高效微调(2023年3月)
- GPT4All(2023年3月)
- ChatDoctor:一种在LLaMA模型上使用医学领域知识进行微调的医学聊天模型(2023年3月)
- Stanford Alpaca(2023年3月)