Gemini 1.5 Pro
谷歌推出了 Gemini 1.5 Pro,这是一款高效的计算多模式专家混合模型。这款人工智能模型专注于长篇内容的回忆和推理能力。Gemini 1.5 Pro 能够推理处理可能包含数百万标记的长篇文档,包括数小时的视频和音频。Gemini 1.5 Pro 在长篇问答、长视频问答和长上下文自动语音识别方面提升了最新技术水平。Gemini 1.5 Pro 在标准基准测试中与 Gemini 1.0 Ultra 相匹配或表现更好,并且在至少 1000 万标记的情况下实现了接近完美的检索(>99%),相较于其他长上下文语言模型,这是一项重大进展 [20]。
作为此次发布的一部分,谷歌还推出了一个新的实验性的 100 万标记上下文窗口模��型,用户可以在 Google AI Studio 中尝试使用。以 200K 为例,这是迄今为止任何可用语言模型的最大上下文窗口。有了 100 万标记的上下文窗口,Gemini 1.5 Pro 旨在解锁各种用例,包括对大型 PDF、代码库甚至冗长视频的问答。它支持在同一输入序列中混合音频、视觉、文本和代码输入。
架构
Gemini 1.5 Pro 是基于 Gemini 1.0 多模式能力的稀疏专家混合(MoE)Transformer 模型。MoE 的好处在于模型的总参数可以增长,同时保持被激活的参数数量恒定。技术报告中并没有太多细节,但报告称 Gemini 1.5 Pro 使用的训练计算量显著较少,提供更高的服务效率,并且通过架构变化实现了长上下文理解(最多 1000 万标记)。该模型在包括不同模态和经过多模态数据调整的指导的数据上进行了预训练,并且根据人类偏好数据进行了进一步调整。
结果
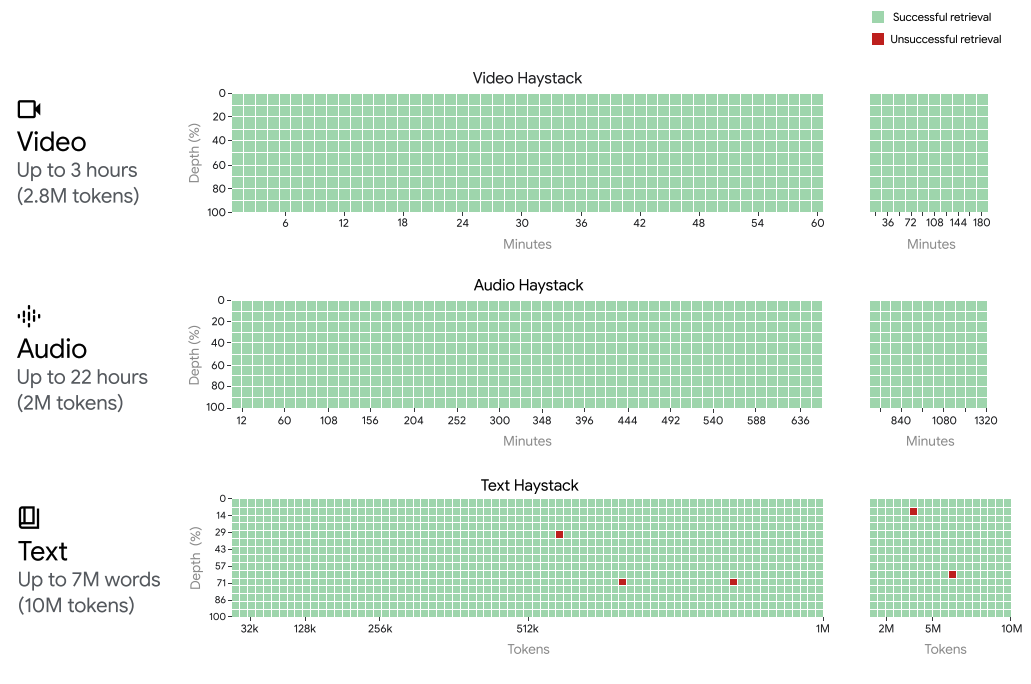
Gemini 1.5 Pro 在所有模态(文本、视频和音频)中实现了高达 100 万标记的“针”式回忆,即接近完美的回忆表现。为了说明 Gemini 1.5 Pro 的上下文窗口支持,当扩展到以下情况时,Gemini 1.5 Pro 仍能保持回忆性能:
- 约 22 小时的录音
- 10 x 1440 页的书籍
- 整个代码库
- 以 1 帧每秒的速度播放的 3 小时视频
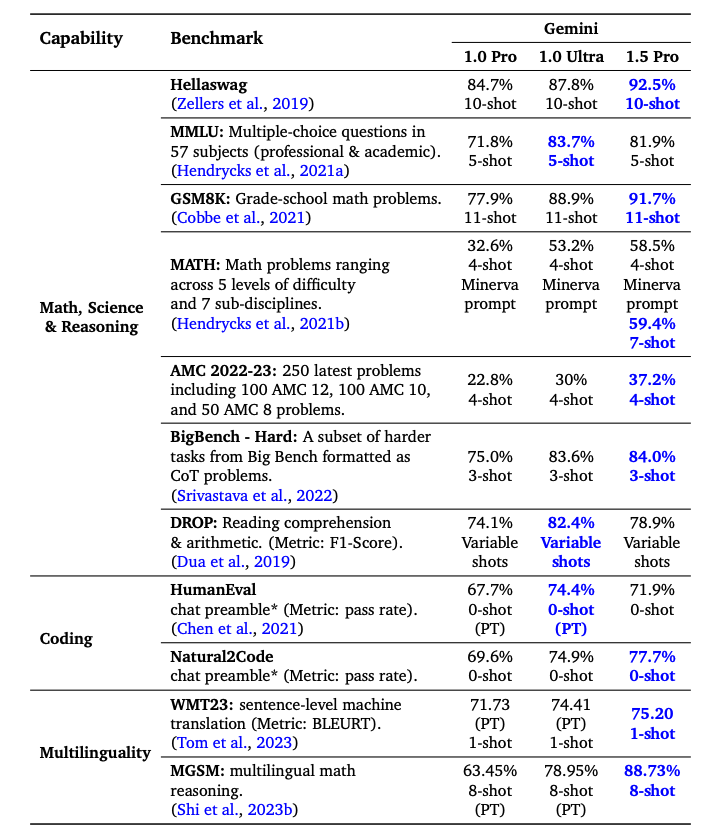
Gemini 1.5 Pro 在大多数基准测试中超越 Gemini 1.0 Pro,在数学、科学、推理、多语言、视频理解和代码方面表现显著。下表总结了不同 Gemini 模型的结果。尽管使用的训练计算量显著较少,Gemini 1.5 Pro 也在一半的基准测试中胜过 Gemini 1.0 Ultra。
能力
其余的小节突出了 Gemini 1.5 Pro 的一系列能力,从分析大量数据到长上下文多模态推理。一些能力已在论文、社区和我们的实验中得到报道。
长文档分析
为了展示 Gemini 1.5 Pro 处理和分析文档的能力,我们从一个非常基本的问答任务开始。在 Google AI Studio 中,Gemini 1.5 Pro 模型支持高达 100 万标记,因此我们能够上传整个 PDF。下面的示例显示了上传了一个单个 PDF,以及一个简单的提示“这篇论文是关于什么的?”:
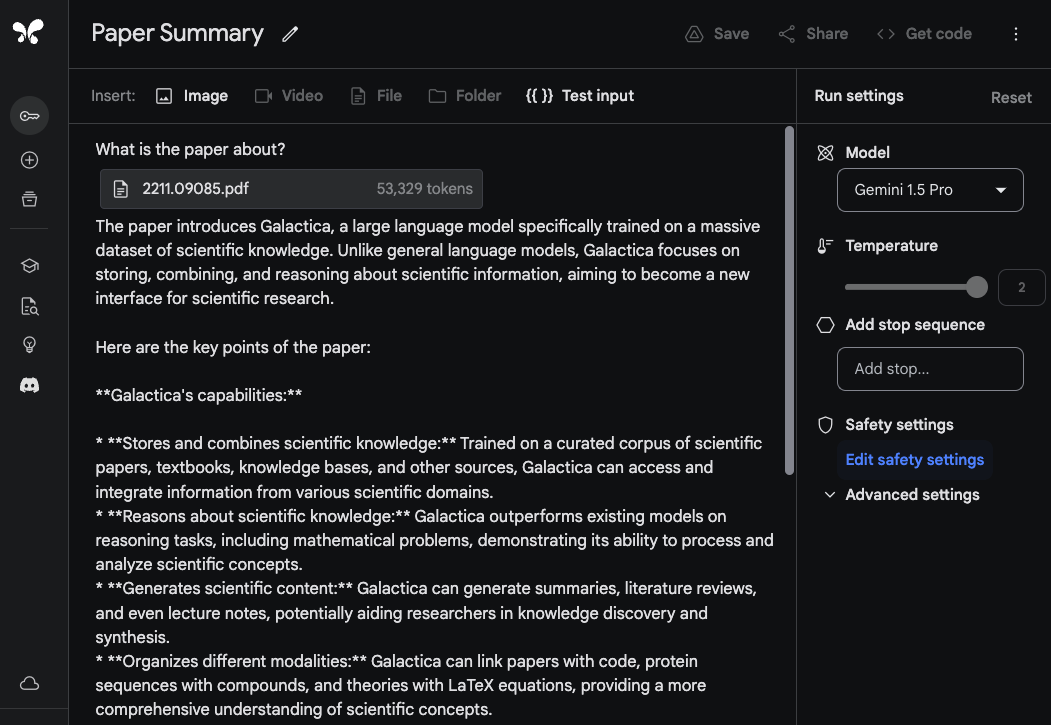
模型的回答准确而简洁,提供了对 Galactica 论文 的可接受摘要。上面的示例使用了 Google AI Studio 中的自由格式提示,但您也可以使用聊天格式与上传的 PDF 进行交互。如果您有许多问题希望从提供的文档中得到答案,这是一个有用的功能。
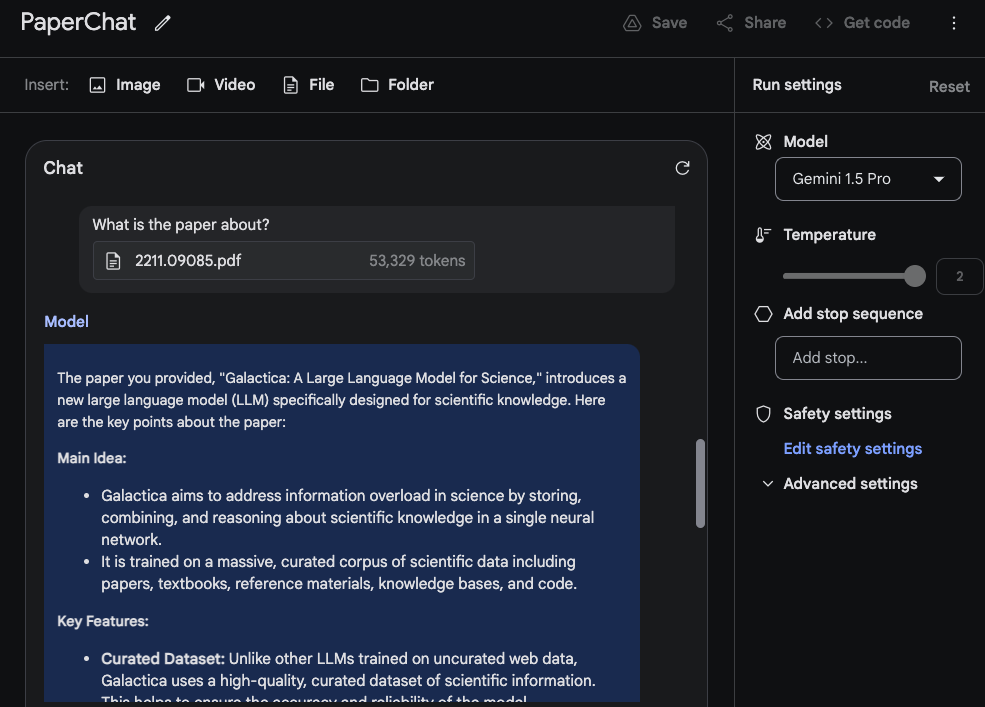
为了利用长上下文窗口,现在让我们上传两个 PDF,并提出一个跨两个 PDF 的问题。
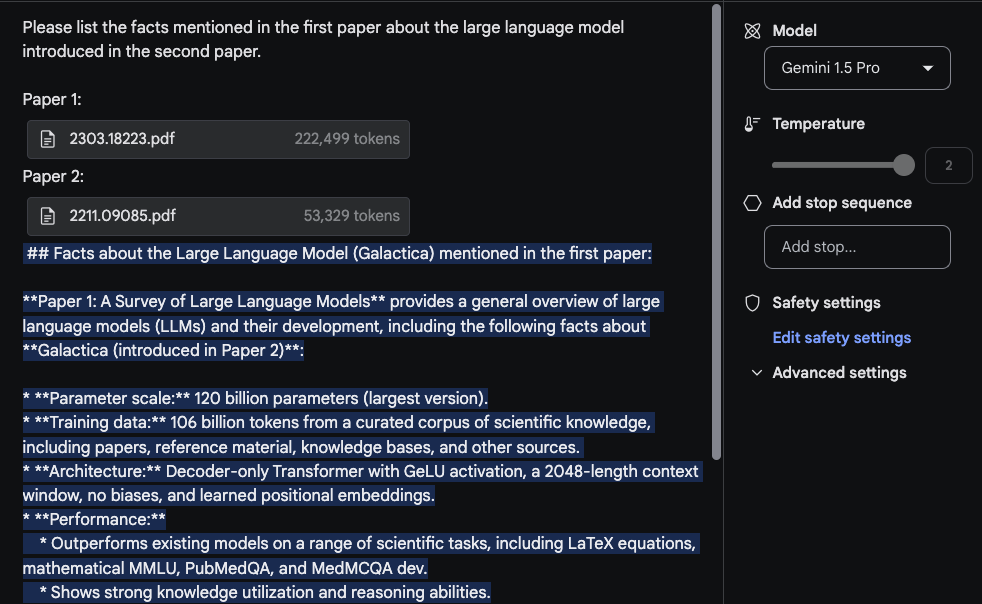 在这个任务中,最合理的回应是从第一篇论文中提取的信息,这篇关于LLM的综述论文中的信息来自一张表格。"架构"信息看起来也是正确的。然而,“性能”部分不应该出现在这里,因为在第一篇论文中找不到这部分内容。对于这个任务,重要的是在顶部放置提示语
在这个任务中,最合理的回应是从第一篇论文中提取的信息,这篇关于LLM的综述论文中的信息来自一张表格。"架构"信息看起来也是正确的。然而,“性能”部分不应该出现在这里,因为在第一篇论文中找不到这部分内容。对于这个任务,重要的是在顶部放置提示语请列出第一篇论文中关于第二篇论文介绍的大型语言模型的事实。并使用标签标记论文,如论文1和论文2。这个实验的另一个相关后续任务是通过上传一组论文和摘要总结的方法来撰写相关工作部分。另一个有趣的任务是要求模型将更新的LLM论文纳入调查中。
视频理解
Gemini 1.5 Pro从头开始具有多模态能力,并展示了视频理解能力。我们使用Andrej Karpathy最近关于LLM的一堂讲座测试了一��些提示。
在这个简短的演示中,我们创建了一个聊天提示,并上传了包含Karpathy讲座的YouTube视频。第一个问题是讲座内容是关于什么的?。这里没有太多花哨的东西,但回应是可以接受的,因为它准确地总结了讲座内容。
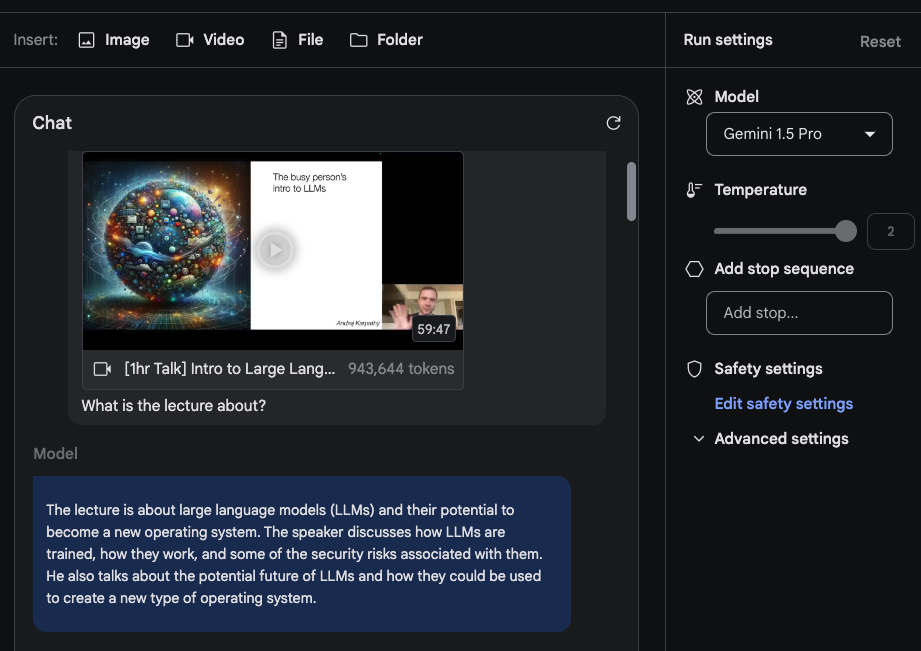
我们提示模型执行的第二个任务是提供讲座的简明概要(一页长度)。回应如下(为简洁起见进行了编辑):
## 大型语言模型:一个新的操作系统?
简介:
- LLMs是在大量文本数据上训练的,可以生成人类质量的文本。
- 它们变得越来越强大,并被用于各种任务,如写作、翻译和编码。
LLMs的工作原理:
- LLMs是预测序列中下一个词的神经网络。
- 它们通过迭代调整参数来进行学习,以做出更好的预测。
- 尽管我们可以衡量它们的性能,但我们并不完全理解数十亿参数是如何协同工作实现的。
训练LLMs:
- 需要大量的数据和计算能力。
- 可以被看作是将"互联网压缩"成一个单一文件。
- 例如,训练LLaMA 2 70B需要6000个GPU,持续12天,成本约为200万美元。
LLM安全性:
- LLM安全性是一个新兴且快速发展的领域。
- 一些关键的安全风险包括:
- 越狱:绕过安全机制生成有害内容。
- 提示注入:将恶意代码注入提示中以控制LLM的输出。
- 数据毒化/后门攻击:向训练数据中插入精心制作的文本以影响LLM的行为。
...
这个摘要非常简洁,代表了讲座的良好概要以及关键要点。我们没有评估整个输出的准确性,但看到模型输出了像"训练LLaMA 2 70B需要6000个GPU,持续12天,成本约为200万美元。"这样的信息是很有趣的。
当具体细节很重要时,要记住模型有时可能会"产生幻觉"或因各种原因检索错误的信息。例如,当我们提示模型讲座中报告了Llama 2的FLOPs是多少?时,它回答说讲座报告称训练Llama 2 70B需要大约1万亿FLOPs。这是不准确的。正确的回答应该是~1e24 FLOPs。技术报告中有许多这样的例子,说明了当被问及视频的具体问题时,这些长上下文模型失败的情况。
下一个任务涉及从视频中提取表格信息。示例显示了提示和回应。我们可以观察到模型生成了一个表格,它有一些正确的细节和一些错误的细节。例如,表格的列是正确的,但其中一个行标签是错误的(即概念分辨率应该是共指分辨率)。我们用其他表格和其他不同元素(如文本框)测试了几个这样的提取任务,发现了类似的不一致性。
技术报告中记录的一个有趣例子是模型根据特定场景或时间戳从视频中检索细节的能力。在第一个例子中,我们提示模型回答特定部分从哪里开始。
提示:
LLM操作系统部分从哪个时间戳开始?
输出:
LLM操作系统部分从42:17开始。
回应是正确的。
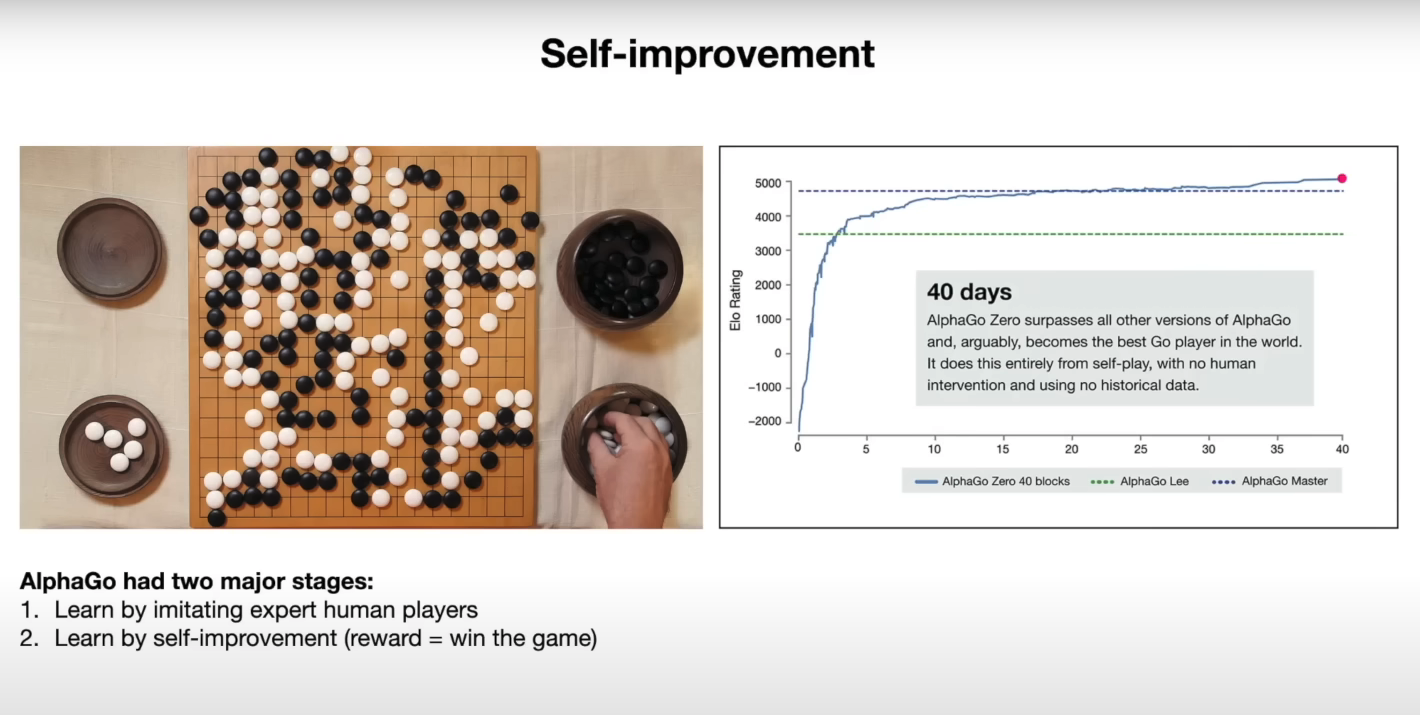
在下一个例子中,我们要求模型解释幻灯片上的图表。
提示:
你能解释一下(右侧)自我提升幻灯片上的图表吗?
输出:
这张图展示了 AlphaGo Zero 随时间的表现,以其 Elo 评分来衡量。Elo 评分是衡量玩家在游戏中技能水平的指标,较高的评分表示更强的玩家。图表显示,AlphaGo Zero 的表现在 40 天内迅速提升,最终超过了所有其他版本的 AlphaGo,包括那个击败世界冠军围棋选手李世石的版本。这种改进完全是通过自我对弈实现的,没有人类干预或历史数据的参与。
这个模型似乎很好地利用了提供的信息来解释图表中的结果。以下是对应幻灯片的快照:
代码推理
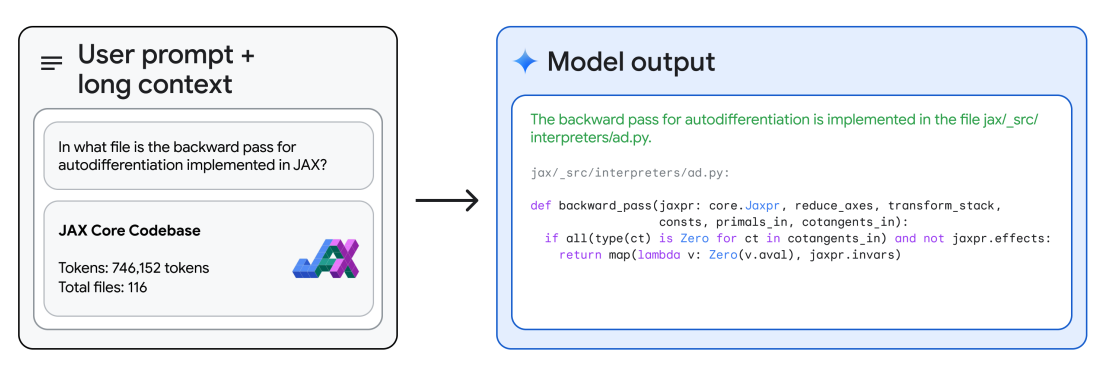
通过其长上下文推理,Gemini 1.5 Pro 能够回答关于代码库的问题。使用 Google AI Studio,Gemini 1.5 Pro 允许最多使用 100 万个标记,因此我们可以上传整个代码库,并提示它回答不同的问题或与代码相关的任务。技术报告提供了一个示例,其中模型被提供了整个 JAX 代码库的上下文(约 746K 个标记),并被要求识别核心自动微分方法的位置。
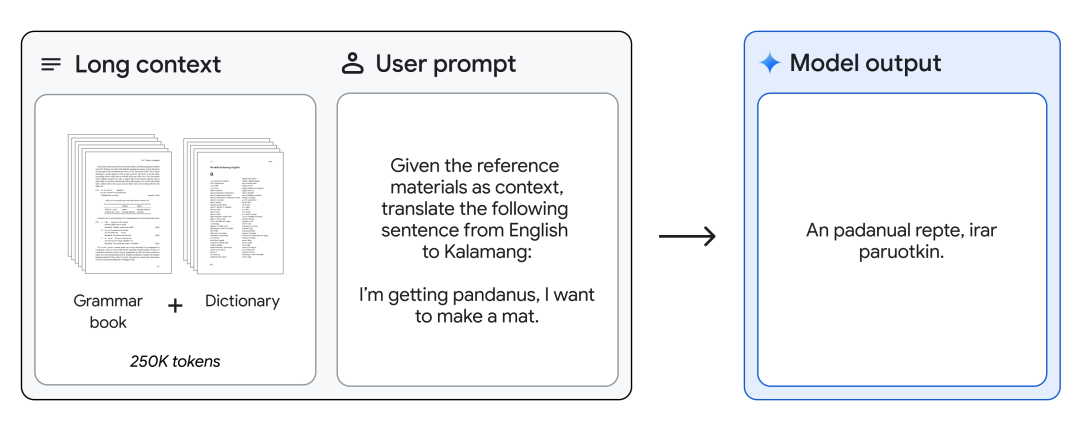
英语到 Kalamang 语翻译
Gemini 1.5 Pro 可以提供 Kalamang 语法手册(500 页的语言文档,一个词典和约 400 个平行句子)给 Kalamang 语的少于全球 200 位使用者的语言,并将英语翻译成 Kalamang 语,达到与从相同内容学习的人的水平。这展示了通过长上下文实现的 Gemini 1.5 Pro 的现场学习能力。
图片来源:Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context