下一步
所以,你已经安装了ClearML的python包并运行了你的第一个实验!
现在,您将学习如何跟踪超参数、工件和指标!
访问实验
每个之前执行的实验都存储为一个任务。 任务的项目和名称可以在实验执行后更改。 任务还会自动分配一个自动生成的唯一标识符(UUID字符串),该标识符无法更改,并且始终在系统中定位相同的任务。
通过基于任务ID或项目和名称组合查询系统,以编程方式检索任务对象。您还可以根据任务的属性(如标签)查询任务(参见查询任务)。
prev_task = Task.get_task(task_id='123456deadbeef')
一旦你有了一个Task对象,你就可以查询Task的状态,获取它的模型、标量、参数等。
记录超参数
为了完全的可重复性,保存每个实验的超参数至关重要。由于超参数对模型性能有重大影响,保存并比较这些参数有时是理解模型行为的关键。
ClearML 支持开箱即用地记录 argparse 模块的参数,因此一旦 ClearML 集成到代码中,它会自动记录提供给参数解析器的所有参数。
您还可以记录参数字典(在解析外部配置文件并将其存储为字典对象时非常有用)、整个配置文件,甚至是自定义对象或Hydra配置!
params_dictionary = {'epochs': 3, 'lr': 0.4}
task.connect(params_dictionary)
查看配置以获取所有超参数记录选项。
记录工件
ClearML 让您可以轻松存储实验的输出产品 - 模型快照/权重文件、数据的预处理、数据的特征表示等等!
本质上,工件是从脚本上传的文件(或Python对象),并与任务一起存储。 这些工件可以通过Web界面轻松访问,也可以通过编程方式访问。
工件可以存储在任何地方,无论是在ClearML服务器上,还是任何对象存储解决方案或共享文件夹中。 查看所有存储功能。
添加工件
上传一个包含数据预处理结果的本地文件:
task.upload_artifact(name='data', artifact_object='/path/to/preprocess_data.csv')
您还可以通过传递文件夹来上传整个文件夹及其所有内容(文件夹将被压缩并作为单个zip文件上传)。
task.upload_artifact(name='folder', artifact_object='/path/to/folder/')
最后,您可以上传一个对象的实例;Numpy/Pandas/PIL 图像支持 npz/csv.gz/jpg 格式。
如果对象类型未知,ClearML 会将其序列化并上传序列化文件。
numpy_object = np.eye(100, 100)
task.upload_artifact(name='features', artifact_object=numpy_object)
有关更多工件记录选项,请参阅Artifacts。
使用工件
记录的工件可以被其他任务使用,无论是预训练的模型还是处理过的数据。 要使用一个工件,首先你需要获取最初创建它的任务的实例, 然后你可以下载它并获取其路径,或者直接获取工件对象。
例如,使用先前生成的预处理数据。
preprocess_task = Task.get_task(task_id='preprocessing_task_id')
local_csv = preprocess_task.artifacts['data'].get_local_copy()
task.artifacts 是一个字典,其中键是工件名称,返回的对象是工件对象。
调用 get_local_copy() 返回工件的本地缓存副本。因此,下次执行代码时,您不需要再次下载工件。
调用 get() 获取反序列化的pickle对象。
查看artifacts retrieval示例代码。
模型
模型是一种特殊的工件。 由流行框架(如PyTorch、TensorFlow、Scikit-learn)创建的模型会被ClearML自动记录。 所有快照都会自动记录。为了确保您也能自动上传模型快照(而不是保存其本地路径),请为要上传的模型文件传递一个存储位置。
例如,将所有快照上传到S3存储桶:
task = Task.init(
project_name='examples',
task_name='storing model',
output_uri='s3://my_models/'
)
现在,每当框架(TensorFlow/Keras/PyTorch 等)存储快照时,模型文件会自动上传到存储桶中的特定实验文件夹。
系统还会记录通过框架加载模型的过程;这些模型会出现在实验的工件标签下的“输入模型”部分。
查看模型快照示例,适用于 TensorFlow, PyTorch, Keras, scikit-learn.
加载模型
加载先前训练的模型与加载工件非常相似。
prev_task = Task.get_task(task_id='the_training_task')
last_snapshot = prev_task.models['output'][-1]
local_weights_path = last_snapshot.get_local_copy()
和之前一样,您必须获取训练原始权重文件的任务实例,然后您可以查询该任务以获取其输出模型(一系列快照),并获取最新的快照。
使用 TensorFlow,快照存储在文件夹中,这意味着 local_weights_path 将指向包含您请求的快照的文件夹。
与工件一样,所有模型都被缓存,这意味着下次运行此代码时,无需下载任何模型。 一旦其中一个框架加载了权重文件,运行的任务将自动更新,其中“输入模型”直接指向原始训练任务的模型。 此功能使您可以轻松获取系统训练和使用的每个模型的完整谱系!
日志指标
完整的指标记录是找到最佳性能模型的关键! 默认情况下,ClearML 自动捕获并记录所有报告给 TensorBoard 和 Matplotlib 的内容。
由于并非所有指标都以这种方式跟踪,您还可以使用Logger对象手动报告指标。
你可以记录一切,从时间序列数据和混淆矩阵到HTML、音频和视频,再到自定义的plotly图表!一切都可以记录!
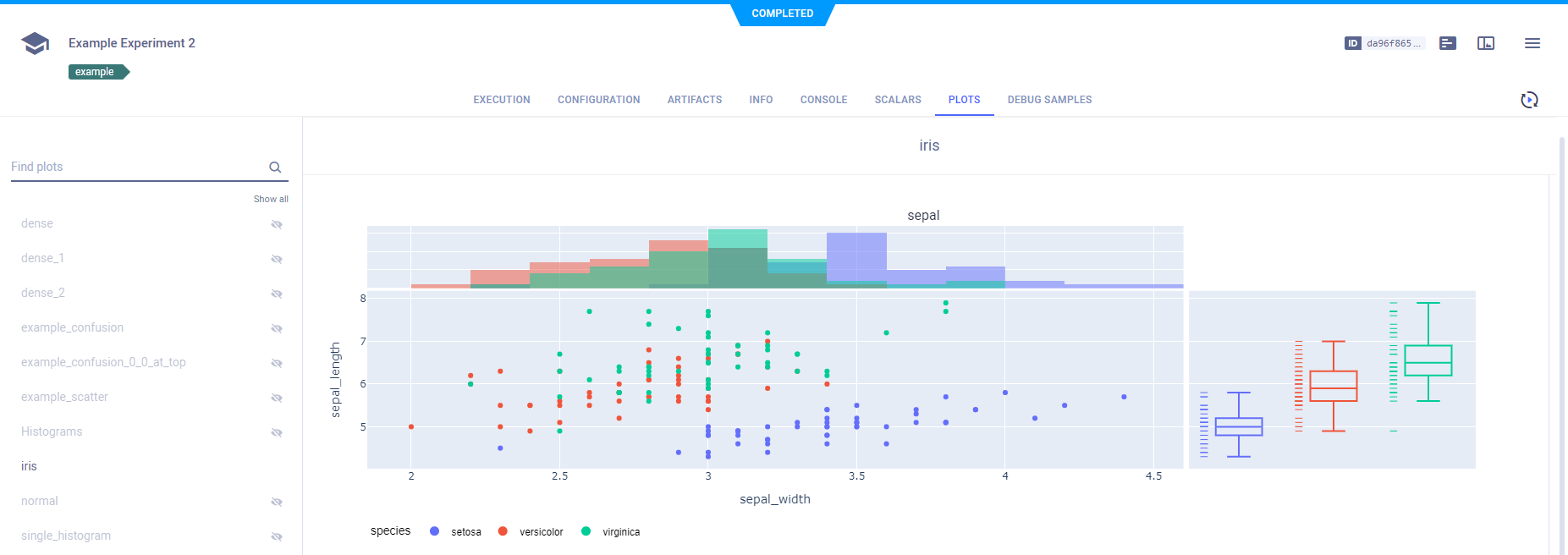
一旦所有内容都被整齐地记录和显示,使用比较工具来找到最佳配置!
跟踪实验
实验表是一个强大的工具,用于创建您自己的项目、团队项目或整个开发的仪表板和视图。
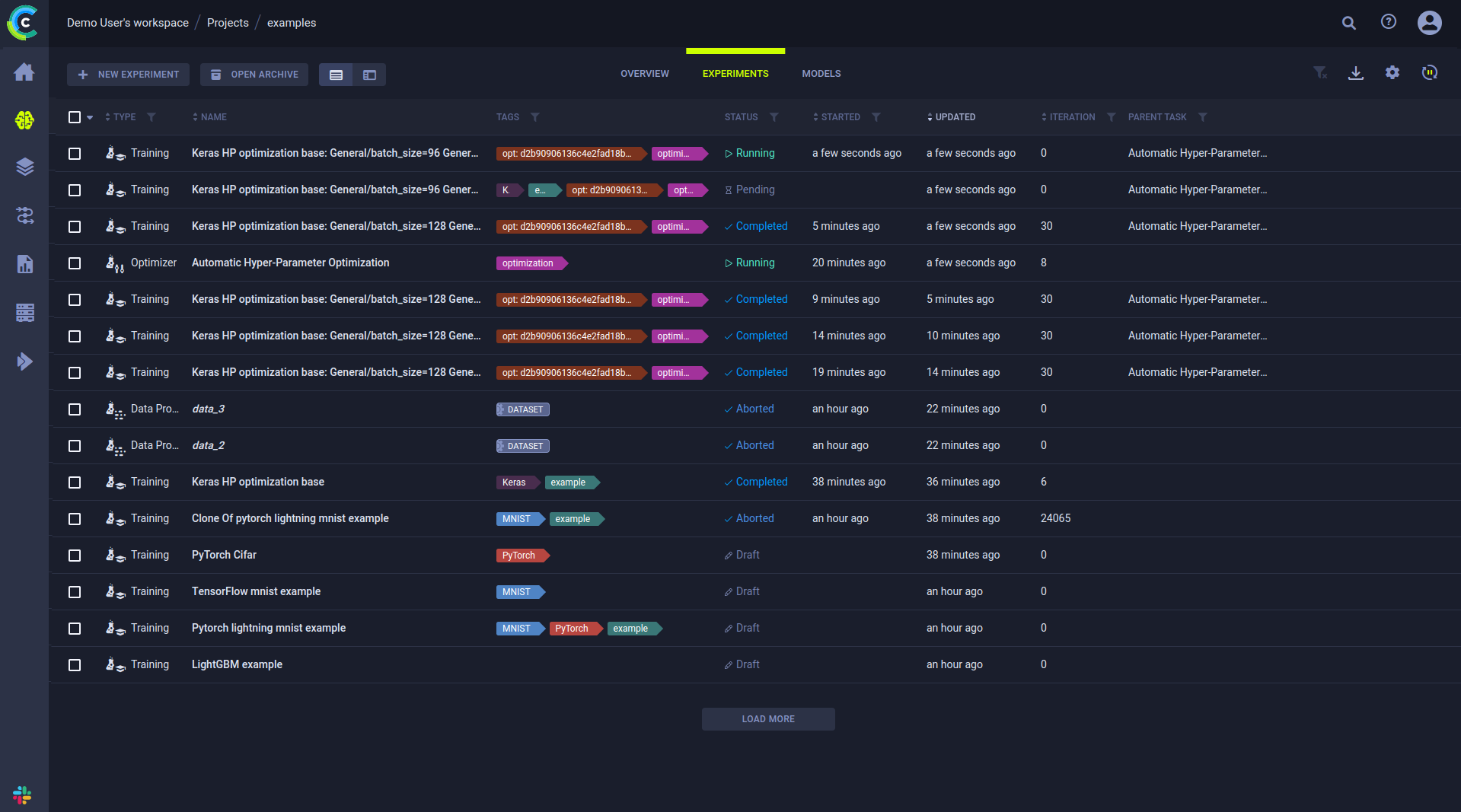
创建排行榜
自定义实验表以满足您的需求,添加所需的参数、指标和标签视图。 您可以根据参数和指标进行过滤和排序,因此创建自定义视图既简单又灵活。
为项目创建一个仪表板,展示最新的模型及其准确率分数,以便立即获得洞察。
它也可以用作实时排行榜,显示表现最佳实验的状态,实时更新。 这对于监控项目的进度并在组织内共享非常有帮助。
任何页面都可以通过从地址栏复制URL来分享,允许您将排行榜或特定实验或比较页面的精确视图加入书签或发送。
您还可以为任务添加标签以便于可见性和过滤,这样您可以在实验执行过程中添加更多信息。 之后,您可以在搜索栏中根据任务名称进行搜索,并根据标签、参数、状态等过滤实验。
接下来是什么?
这涵盖了ClearML的基础知识!通过本指南,您已经学会了如何记录参数、工件和指标!
如果你想了解更多,请查看我们在最佳实践页面中如何看待数据科学过程, 或者查看这些页面:
- 扩展您的工作并部署 ClearML 代理
- 在远程机器上使用ClearML 会话进行开发
- 构建你的工作并将其放入Pipelines
- 通过超参数优化改进您的实验
- 查看 ClearML 与您喜欢的 ML 框架的集成,如 TensorFlow、PyTorch、Keras 等
YouTube 播放列表
所有这些技巧和窍门也都在ClearML的入门系列视频中有所涵盖。快去看看吧 :)
