模型部署
Enterprise Feature
模型部署应用程序可在ClearML企业计划下使用。
模型部署应用程序使用户能够通过安全端点快速将LLM模型部署为网络服务。该应用程序支持各种模型配置和自定义,以优化性能和资源使用。模型部署应用程序在您选择的机器上为您的模型提供服务。一旦应用程序实例运行,它通过一个安全的、可公开访问的网络端点为您的模型提供服务。应用程序监控端点活动,并在模型在指定的最大空闲时间内保持不活动时关闭。
AI Application Gateway
模型部署应用程序使用了ClearML流量路由器,它为模型实现了一个安全的、经过身份验证的网络端点。
如果ClearML AI应用程序网关不可用,模型端点可能无法访问。
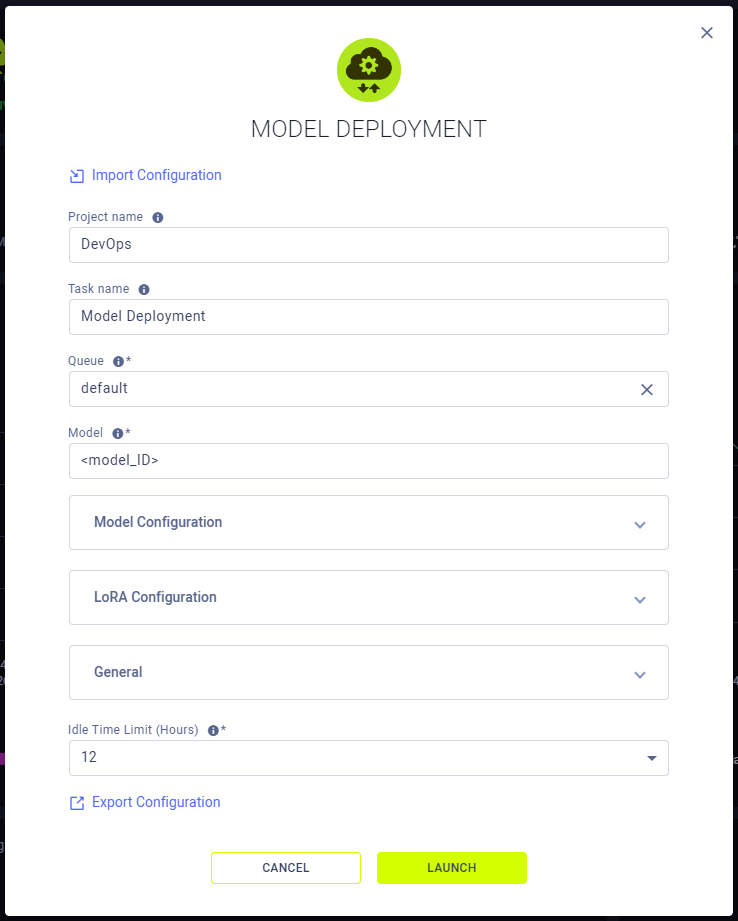
一旦你启动了一个模型部署实例,你可以在其仪表板上查看以下信息:
- 状态指示器
 - 应用程序实例正在运行并且正在积极使用
- 应用程序实例正在运行并且正在积极使用- - 应用程序实例正在设置中
- - 应用程序实例处于空闲状态
- - 应用程序实例已停止
- 空闲时间 - 自上次活动以来经过的时间
- 端点 - 模型端点的公开可访问URL。活跃的模型端点也可以在 模型端点表中找到,该表允许您查看和比较端点详细信息并 随时间监控状态
- API 基础 - 模型端点的基本 URL
- API key - 模型端点的认证密钥
- 测试命令 - 用于测试已部署模型的示例命令行
- 请求 - 随时间变化的请求数量
- 延迟 - 请求响应时间(毫秒)随时间变化
- Endpoint resource monitoring metrics over time
- CPU 使用率
- 网络吞吐量
- 磁盘性能
- 内存性能
- GPU 利用率
- GPU 内存使用率
- GPU 温度
- 控制台日志 - 控制台日志显示应用程序实例的控制台输出:设置进度、状态更改、错误消息等。
模型部署实例配置
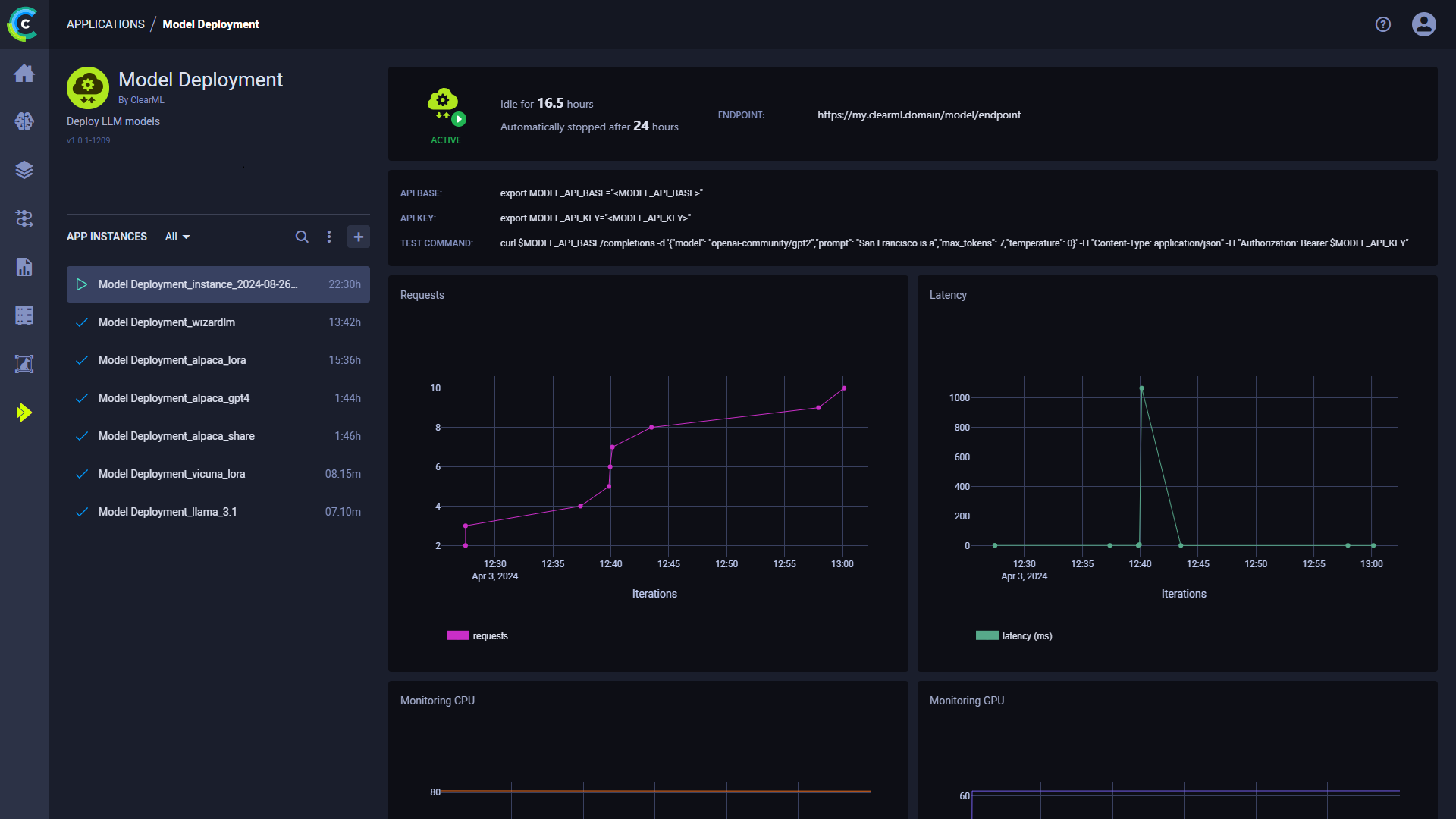
在配置新的模型部署实例时,您可以填写所需的参数或重用之前启动实例的配置。
使用以下选项之一启动一个应用程序实例,配置与之前启动的实例相同:
- 克隆先前启动的应用程序实例将打开实例启动表单,其中预填充了原始实例的配置。
- 导入应用程序配置文件。您可以在查看其配置时,将先前启动的实例的配置导出为JSON文件。
在启动新的应用程序实例之前,可以编辑预填充的配置表单。
要配置一个新的应用程序实例,请点击Launch New ![]() 以打开应用程序的配置表单。
以打开应用程序的配置表单。
配置选项
- 导入配置 - 导入一个应用实例配置文件。这将用文件中的值填充实例启动表单,可以在启动应用实例之前进行修改。
- 项目名称 - ClearML 项目名称
- 任务名称 - 您的模型部署应用程序实例的ClearML任务名称
- 队列 - ClearML 队列,Model Deployment 应用程序实例任务将被加入该队列(确保有代理分配给该队列)
- 模型 - 一个ClearML模型ID或HuggingFace模型名称(例如
openai-community/gpt2) - 模型配置
- 信任远程代码 - 选择以设置 Hugging Face
trust_remote_code为true。 - 版本 - 您想要使用的模型的特定 Hugging Face 版本(即权重)。您
可以使用特定的提交 ID 或分支,如
refs/pr/2。 - 代码版本 - 用于 HuggingFace Hub 上模型代码的特定版本。可以是分支名称、标签 名称或提交 ID。如果未指定,将使用默认版本。
- 最大模型长度 - 模型上下文长度。如果未指定,将自动从模型中派生
- 分词器 - 一个 ClearML 模型 ID 或 Hugging Face 分词器
- 分词器版本 - 要使用的特定分词器 Hugging Face 版本。可以是分支名称、标签名称或 提交 ID。如果未指定,将使用默认版本。
- 分词器模式 - 选择分词器模式:
auto- 如果可用,使用快速分词器slow- 使用慢速分词器。
- 信任远程代码 - 选择以设置 Hugging Face
- LoRA 配置
- 启用 LoRA - 如果勾选,启用对 LoRA 适配器 的处理。
- LoRA 模块 - LoRA 模块配置的格式为
name=path。可以指定多个模块。 - 最大 LoRA 数量 - 单个批次中的最大 LoRA 数量。
- 最大 LoRA 等级
- LoRA 额外词汇量 - LoRA 适配器中可以存在的额外词汇的最大大小(添加到基础模型词汇中)。
- LoRA 数据类型 - 选择 LoRA 的数据类型。选择以下之一:
auto- 如果选择,将默认为基础模型的数据类型。float16bfloat16float32
- 最大 CPU LoRA 数量 - 存储在 CPU 内存中的最大 LoRA 数量。必须大于或等于下面常规部分中的
最大序列数字段。默认为最大序列数。
- General
- Disable Log Stats - Disable logging statistics
- Enforce Eager - Always use eager-mode PyTorch. If False, a hybrid of eager mode and CUDA graph will be used for maximal performance and flexibility.
- Disable Custom All Reduce - See vllm ParallelConfig
- Disable Logging Requests
- Fixed API Access Key - Key to use for authenticating API access. Set a fixed API key if you've set up the server to be accessible without authentication. Setting an API key ensures that only authorized users can access the endpoint.
- HuggingFace Token - Token for accessing HuggingFace models that require authentication
- Load Format - Select the model weights format to load:
auto- Load the weights in the safetensors format and fall back to the pytorch bin format if safetensors format is not available.pt- Load the weights in the pytorch bin format.safetensors- Load the weights in the safetensors format.npcache- Load the weights in pytorch format and store a numpy cache to speed up the loading.dummyInitialize the weights with random values. Mainly used for profiling.
- Dtype - Select the data type for model weights and activations:
auto- if selected, will use FP16 precision for FP32 and FP16 models, and BF16 precision for BF16 models.halffloat16bfloat16floatfloat32
- KV Cache Type - Select data type for kv cache storage:
auto- If selected, will use the model data type. Note FP8 is not supported when cuda version is lower than 11.8.fp8_e5m2
- Pipeline Parallel Size - Number of pipeline stages
- Tensor Parallel Size - Number of tensor parallel replicas
- Max Parallel Loading Workers - Load model sequentially in multiple batches, to avoid RAM OOM when using tensor parallel and large models
- Token Block Size
- Random Seed
- Swap Space - CPU swap space size (GiB) per GPU
- GPU Memory Utilization - The fraction of GPU memory to be used for the model executor, which can range from 0 to 1
- Max Number of Batched Tokens - Maximum number of batched tokens per iteration
- Max Number of Sequences - Maximum number of sequences per iteration
- Max Number of Paddings - Maximum number of paddings in a batch
- Quantization - Method used to quantize the weights. If None, we first check the
quantization_configattribute in the model config file. If that is None, we assume the model weights are not quantized and usedtypeto determine the data type of the weights. - Max Context Length to Capture - Maximum context length covered by CUDA graphs. When a sequence has context length larger than this, we fall back to eager mode.
- Max Log Length - Max number of prompt characters or prompt ID numbers being printed in log. Default: unlimited
- 空闲时间限制(小时) - 应用实例在达到最大空闲时间后将关闭
- 导出配置 - 将应用程序实例配置导出为JSON文件,稍后可以导入以创建具有相同配置的新实例